网易传媒基于 Arctic 的低成本准实时计算实践
网易传媒大数据实际业务中,存在着大量的准实时计算需求场景,业务方对于数据的实效性要求一般是分钟级;这种场景下,用传统的离线数仓方案不能满足用户在实效性方面的要求,而使用全链路的实时计算方案又会带来较高的资源占用。
基于对开源数据湖方案的调研,我们注意到了网易数帆开源的基于 Apache Iceberg 构建的 Arctic 数据湖解决方案。Arctic 能相对较好地支持与服务于流批混用的场景,其开放的叠加式架构,可以帮助我们非常平滑地过渡与实现 Hive 到数据湖的升级改造,且由于传媒离线数仓已接入有数,通过 Arctic 来改造现有业务的成本较低,于是我们准备通过引入 Arctic ,尝试解决 push 业务场景下的痛点。
1 项目背景
以传媒 push 实时数仓为例,新闻推送在地域、时间、频次等因素上有较高的不确定性,非常容易出现偶发的流量洪峰,尤其是在出现突发性社会热点新闻的时候。如果采用全链路的实时计算方案来处理,则需要预留出较多的资源 buffer 来应对。
由于推送时机的不确定性,push 业务的数据指标一般不是增量型的,而是以当天截止到当前的各种累计型指标为主,计算窗口通常为十五分钟到半小时不等,统计维度区分发送类型、内容分类、发送票数、发送厂商、首启方式、用户活跃度、AB 实验等,具有流量波动大和数据口径繁多等特点。

此前采用的全链路 Flink 实时计算方案中,主要遇到以下问题:
(1)资源占用成本高
为应对流量洪峰,需要为实时任务分配预留出较高的资源,且多个聚合任务需要消费同一个上游数据,存在读放大问题。push 相关的实时计算流程占到了实时任务总量的 18+%,而资源使用量占到了实时资源总使用量的近 25%。
(2)大状态带来的任务稳定性下降
push 业务场景下进行窗口计算时,大流量会带来大状态的问题,而大状态的维护在造成资源开支的同时比较容易影响任务的稳定性。
(3)任务异常时难以及时的进行数据修复
实时任务出现异常时,以实时方式来回溯数据时效慢且流程复杂;而以离线流程来修正,则会带来双倍的人力和存储成本。
2 项目思路和方案
2.1 项目思路
我们通过对数据湖的调研,期望利用数据实时入湖的特点,同时使用 Spark 等离线资源完成计算,用较低的成本满足业务上对准实时计算场景的需求。我们以 push 业务场景作为试点进行方案的探索落地,再逐渐将方案推广至更多类似业务场景。
基于对开源数据湖方案的调研,我们注意到了网易数帆开源的基于 Apache Iceberg 构建的 Arctic 数据湖解决方案。Arctic 能相对较好地支持与服务于流批混用的场景,其开放的叠加式架构,可以帮助我们非常平滑地过渡与实现 Hive 到数据湖的升级改造,且由于传媒离线数仓已接入有数,通过 Arctic 来改造现有业务的成本较低,于是我们准备通过引入 Arctic ,尝试解决 push 业务场景下的痛点。
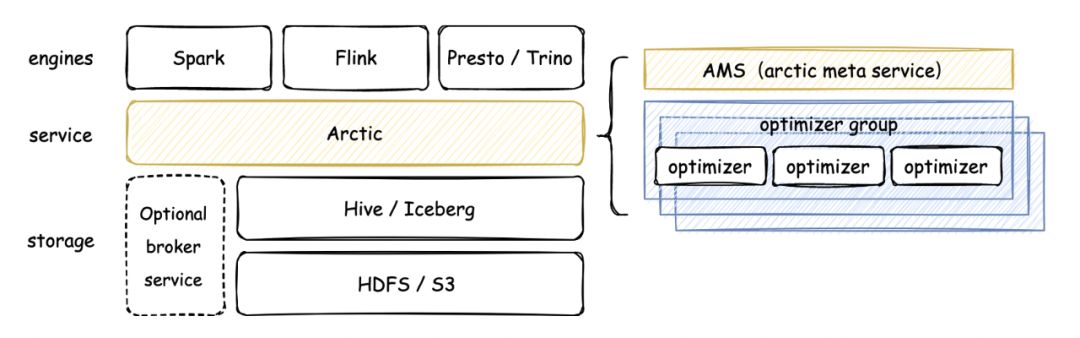
Arctic 是由网易数帆开源的流式湖仓系统,在 Iceberg 和 Hive 之上添加了更多实时场景的能力。通过 Arctic,用户可以在 Flink、Spark、Trino、Impala 等引擎上实现更加优化的 CDC、流式更新、OLAP 等功能。
实现 push 业务场景下的数据湖改造,只需要使用 Arctic 提供的 Flink Connector,便可快速地实现 push 明细数据的实时入湖。
此时需要我们关注的重点是,数据产出需要满足分钟级业务需求。数据产出延迟由两部分组成:
- 数据就绪延迟,取决于 Flink 实时任务的 Commit 间隔,一般为分钟级别;
- 数据计算耗时,取决于计算引擎和业务逻辑:数据产出延迟 = 数据就绪延迟 + 数据计算耗时
2.2 解决方案
2.2.1 数据实时入湖
Arctic 能够兼容已有的存储介质(如 HDFS)和表结构(如 Hive、Iceberg),并在之上提供透明的流批一体表服务。存储结构上主要为 Basestore 和 Changestore 两部分:
(1)Basestore 中存储了表的存量数据。它通常由 Spark/Flink 等引擎完成第一次写入,再之后则通过自动的结构优化过程将 Changestore 中的数据转化之后写入。
(2)Changestore 中存储了表上最近的变更数据。Changestore 中存储了表上最近的变更数据。它通常由 Apache Flink 任务实时写入,并用于下游 Flink 任务进行准实时的流式消费。同时也可以对它直接进行批量计算或联合 Basestore 里的数据一起通过 Merge-On-Read(以下简称为MOR) 的查询方式提供分钟级延迟的批量查询能力。

Arctic 表支持实时数据的流式写入,数据写入过程中为了保证数据的实效性,写入侧需要频繁的进行数据提交,但因此会产生大量的小文件,积压的小文件一方面会影响数据的查询性能,另一方面也会对文件系统带来压力。这方面,Arctic 支持基于主键的行级更新,提供了 Optimizer 来进行数据 Update 和自动的结构优化,以帮助用户解决数据湖常见的小文件、读放大、写放大等问题。
以传媒 push 数仓场景为例,push 发送、送达、点击、展示等明细数据需要通过 Flink 作业实时写入到 Arctic 中。由于上游已经做了 ETL 清洗,此阶段只需要通过 FlinkSQL 即可方便地将上游数据写入 Changestore。Changestore 内包含了存储插入数据的 insert 文件和存储删除数据的 equality delete 文件,更新数据会被拆分为更新前项和更新后项分别存储在 delete 文件与 insert 文件中。
具体的,对于有主键场景,insert/update_after 消息会写入 Changestore 的 insert 文件,delete/update_before 会写入 Arctic 的 delete 文件。当进行 Optimize 的时候,会先把 delete 文件读到内存中形成一个 delete map, map 的 key 是记录的主键,value 是 record_lsn。然后 再读取 Basestore 和 Changestore 中的 insert 文件, 对主键相同的 row 进行 record_lsn 的对比,如果 insert 记录中 record_lsn 比 deletemap 中相同主键的 record_lsn 小,则认为这条记录已经被删除了,不会再追加到 base 里;否则把数据写入到新文件里,最终实现了行级的更新。
2.2.2 湖水位感知
传统的离线计算在调度方面需要有一个触发机制,一般由作业调度系统按照任务之间的依赖关系来处理,当上游任务全部成功后自动调起下游的任务。但在实时入湖的场景下,下游任务缺乏一个感知数据是否就绪的途径。以 push 场景为例,需要产出的指标主要为按照指定的时间粒度来计算一次当天累计的各种统计值,此时下游如果没法感知当前湖表水位的话,要么需要留出一个较冗余的缓冲时间来保证数据就绪,要么则有漏数据的可能,毕竟 push 场景的流量变化是非常起伏不定的。
传媒大数据团队和 Arctic 团队借鉴了 Flink Watermark 的处理机制和 Iceberg 社区讨论的方案,将 Watermark 信息写入到 Iceberg 表的 metadata 文件里,然后由 Arctic 通过消息队列或者 API 暴露出来,从而做到下游任务的主动感知,尽可能地降低了启动延迟。具体方案如下:
(1)Arctic 表水位感知
当前只考虑 Flink 写入的场景,业务在 Flink 的 source 定义事件时间和 Watermark。ArcticSinkConnector 包含两个算子,一个是负责写文件的多并发的 ArcticWriter, 一个是负责提交文件的的单并发的 ArcticFileCommitter。当执行 checkpoint 时,ArcticFileCommitter 算子会进行 Watermark 对齐之后取最小的 Watermark。会新建一个类似于 Iceberg 事务的 AMS Transaction,在这个事务里除了 AppendFiles 到 Iceberg,同时把 TransactionID,以及 Watermark 通过 AMS 的 thrift 接口上报给 AMS。

(2)Hive 表水位感知
Hive表里可见的数据是经过 Optimize 过后的数据,Optimize 由 AMS 来调度,Flink 任务异常执行文件的读写合并,并且把 Metric 上报给 AMS, 由 AMS 来把这一次 Optimize 执行的结果 Commit,AMS 天然知道这一次 Optimize 推进到了哪次 Transaction, 并且 AMS 本身也存储了 Transaction 对应的 Watermark,也就知道 Hive 表水位推进到了哪里。
2.2.3 数据湖查询
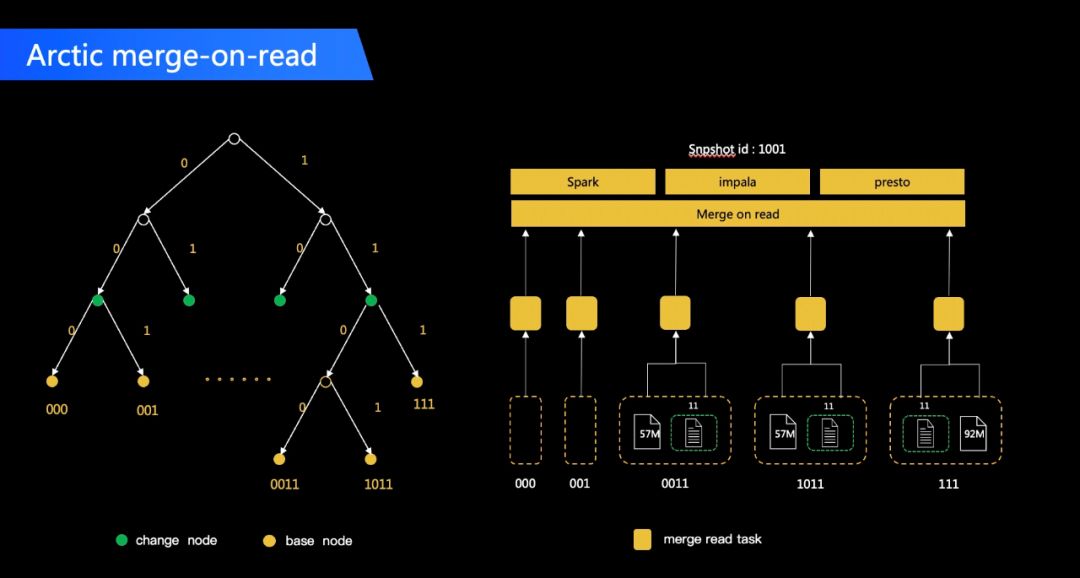
Arctic 提供了 Spark/Flink/Trino/Impala 等计算引擎的 Connector 支持。通过使用Arctic数据源,各计算引擎都可以实时读取到已经 Commit 的文件,Commit 的间隔按照业务的需求一般为分钟级别。下面以 push 业务为例介绍几种场景下的查询方案和相应成本:
(1)Arctic + Trino/Impala 满足秒级 OLAP 查询
OLAP 场景下,用户一般更关注计算上的耗时,对数据就绪的敏感度相对不高。针对中小规模数据量的 Arctic 表或较简单的查询,通过 Trino/Impala 进行 OLAP 查询是一个相对高效的方案,基本上可以做到秒级 MOR 查询耗时。成本上,需要搭建 Trino/Impala 集群,如果团队中已有在使用的话,则可以根据负载情况考虑复用。

Arctic 在开源发布会上发布了自己的 benchmark 数据,在数据库 CDC 持续流式摄取的场景下,对比各个数据湖 Format 的 OLAP benchmark 性能, 整体上带 Optimize 的 Arctic 的性能优于 Hudi,这主要得益于 Arctic 内部有一套高效的文件索引 Arctic Tree,在 MOR 场景下可以做到更细粒度、精确地 merge。详细的对比报告可以参考:https://arctic.netease.com/ch/benchmark/。
(2)Arctic + Spark 满足分钟级预聚合查询
针对提供下游数据报表展示的场景,一般需要走预计算的流程将结果持久化下来,对数据就绪和计算耗时的敏感度都较高,而且查询逻辑相对复杂,Trino/Impala 集群规模相对较小,执行容易失败,导致稳定性欠佳。这个场景下我们使用了集群部署规模最大的 Spark 引擎来处理,在不引入新的资源成本的情况下,做到了离线计算资源的复用。
数据就绪方面,通过 Arctic 表水位感知方案,可以做到较低的分钟级就绪延迟。
计算方面,Arctic 对 Spark Connector 提供了一些读取优化,用户可以通过配置 Arctic 表的 read.split.planning-parallelism 和 read.split.planning-parallelism-factor 这两个参数值,来调整 Arctic Combine Task 的数量,进而控制计算任务的并发度。由于 Spark 离线计算的资源相对灵活和充足,我们可以通过上述调整并发度的方式来保证在 2~3 分钟内完成业务的计算需求。

(3)Hive + Spark 满足传统离线数仓生产链路的调度
Arctic 支持将 Hive 表作为 Basestore,Full Optimize 时会将文件写入到 Hive 数据目录下,以达到更新 Hive 原生读取内容的目的,通过存储架构上的流批一体来降低成本。因此传统的离线数仓生产链路,可以直接使用对应的 Hive 表来作为离线数仓链路的一部分,时效性上相较于 Arctic 表虽缺少了 MOR,但通过 Hive 表水位感知方案,可以做到业务能接受的就绪延迟,从而满足传统离线数仓生产链路的调度。

3 项目影响力与产出价值
3.1 项目影响力
通过 Arctic + X 方案在传媒的探索和落地,为传媒准实时计算场景提供了一个新的解决思路。该思路不但减轻了全链路 Flink 实时计算方案所带来的实时资源压力和开发运维负担,而且还能较好地复用现有的 HDFS 和 Spark 等存储计算资源,做到了降本增效。
此外 Arctic 在音乐、有道等多个 BU 也有落地,比如在音乐公技,用于 ES 冷数据的存储,降低了用户 ES 的存储成本;而有道精品课研发团队也在积极探索和使用 Arctic 作为其部分业务场景下的解决方案。
目前 Arctic 已经在 github 上开源,受到了开源社区与外部用户的持续关注,在 Arctic 的建设与发展中,也收到了不少外部用户提交的高质量 PR 。
3.2 项目产出价值
通过上述方案我们将 push ETL 明细数据通过 Flink 实时入湖到 Arctic,然后在调度平台上配置分钟级的调度任务,按照不同交叉维度进行计算后将累计型指标后写入关系数据库,最后通过有数直连进行数据展示,做到了业务方要求的分钟级时效数据产出。改造后的方案,同原来的全链路 Flink 实时计算方案相比:
(1)充分复用离线空闲算力,降低了实时计算资源开支
方案利用了空闲状态下的离线计算资源,且基本不会带来新的资源开支。离线计算业务场景注定了资源使用的高峰在凌晨,而新闻 push 推送及热点新闻产生的场景大多为非凌晨时段,在满足准实时计算时效的前提下,通过复用提升了离线计算集群的综合利用率。另外,该方案能帮我们释放大约 2.4T 左右的实时计算内存资源。
(2)降低任务维护成本,提升任务稳定性
Arctic + Spark 水位感知触发调度的方案可减少 17+ 实时任务的维护成本,减少了 Flink 实时计算任务大状态所带来的稳定性问题。通过 Spark 离线调度任务可充分利用离线资源池调整计算并行度,有效提升了应对突发热点新闻流量洪峰时的健壮性。
(3)提升数据异常时的修复能力,降低数据修复时间开支
通过流批一体的 Arctic 数据湖存储架构,当数据出现异常需要修正时,可灵活地对异常数据进行修复,降低修正成本;而如果通过实时计算链路回溯数据或通过额外的离线流程来修正,则需要重新进行状态累计或复杂的 ETL 流程。
4 项目未来规划和展望
当前还有一些场景 Arctic 不能做到较好的支持,传媒大数据团队将和 Arctic 团队继续对以下场景下的解决方案进行探索和落地:
(1)当前入湖前的 push 明细数据是通过上游多条数据流 join 生成的,也同样会存在大状态的问题。而 Arctic 当前只能支持行级的更新能力,如果能落地有主键表的部分列更新能力,则可以帮助业务在入湖的时候,以较低的成本直接实现多流 join。
(2)进一步完善 Arctic 表和 Hive 表的水位定义和感知方案,提升时效,并推广到更多的业务场景中。当前的方案只支持单 Spark/Flink 任务写入的场景,对于多个任务并发写表的场景,还需要再完善。
本次的分享就到这里,谢谢大家。
作者:鲁成祥 马一帆

网易传媒基于 Arctic 的低成本准实时计算实践的更多相关文章
- Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)
摘要:如何基于 Flink 搭建大规模准实时数据分析平台?在 Flink Forward Asia 2019 上,来自 Lyft 公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了 Lyft 基 ...
- 携程实时计算平台架构与实践丨DataPipeline
文 | 潘国庆 携程大数据平台实时计算平台负责人 本文主要从携程大数据平台概况.架构设计及实现.在实现当中踩坑及填坑的过程.实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实 ...
- 基于OGG的Oracle与Hadoop集群准实时同步介绍
版权声明:本文由王亮原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/220 来源:腾云阁 https://www.qclou ...
- 基于 Hudi 和 Kylin 构建准实时高性能数据仓库
在近期的 Apache Kylin × Apache Hudi Meetup直播上,Apache Kylin PMC Chair 史少锋和 Kyligence 解决方案工程师刘永恒就 Hudi + K ...
- 原 荐 使用Spring Boot Actuator、Jolokia和Grafana实现准实时监控
原 荐 使用Spring Boot Actuator.Jolokia和[可视化]Grafana实现准实时监控. 监控系统: 日志- 基础处理 - 表格 - 可视化一体化解决方案. ...
- 如何利用.NETCore向Azure EventHubs准实时批量发送数据?
最近在做一个基于Azure云的物联网分析项目: .netcore采集程序向Azure事件中心(EventHubs)发送数据,通过Azure EventHubs Capture转储到Azure Blog ...
- 【Elasticsearch 技术分享】—— 十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!
前言 说到 Elasticsearch ,其中最明显的一个特点就是 near real-time 准实时 -- 当文档存储在Elasticsearch中时,将在1秒内以几乎实时的方式对其进行索引和完全 ...
- Pomelo:网易开源基于 Node.js 的游戏服务端框架
Pomelo:网易开源基于 Node.js 的游戏服务端框架 https://github.com/NetEase/pomelo/wiki/Home-in-Chinese
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- sersync基于rsync+inotify实现数据实时同步
一.环境描述 需求:服务器A与服务器B为主备服务模式,需要保持文件一致性,现采用sersync基于rsync+inotify实现数据实时同步 主服务器A:192.168.1.23 从服务器B:192. ...
随机推荐
- (二)Redis 数据类型与结构
1.值的数据类型 Redis "快"取决于两方面,一方面,它是内存数据库,另一方面,则是高效的数据结构.Redis 键值对中值的数据类型,也就是数据的保存形式有5种:String( ...
- Java的深浅拷贝认识
目录 浅拷贝 深拷贝 分辨代码里的深浅拷贝 在Java中,深拷贝和浅拷贝是对象复制的两种方式,主要区别在于对对象内部的引用类型的处理上. 浅拷贝 定义: 浅拷贝是指创建一个新的对象,但这个新对象的属性 ...
- 【c#】JavaScriptSerializer 不序列化null值
首先引用dll :System.Web.Extensions. 再自定义转换器代码如下: public class JavaScriptSerilizeConvert : JavaScriptConv ...
- TS码流解析(二)PSI PAT PMT
TS码流有PSI和PES两种负载,这一节主要来了解PSI是如何解析的. 1.PSI PSI(Program Specific Information)节目专用信息,用来描述TS码流的节目组成等信息.P ...
- 【分享】FFmpeg桌面神器,集多种功能于一身,超级好用,不用命令行!
在媒体处理上,市面上有很多软件可以选择,在众多软件里面 FFmpeg 是比较独特的一款,直接选择 FFmpeg 硬核命令行工具的朋友相对较少,大多时候只是被集成在各样的软件里,如果单独拿出来使用,不少 ...
- NOIP模拟59
T1 柱状图 解题思路 二分答案+线段树check 显然对于最后的限制,我们希望向上移的和向下移的柱子数尽量接近. 因此枚举每一个柱子当做最高的一个的时刻,二分找到一个当前最优解更新答案. 开两棵线段 ...
- ABC347题解
省流:输+赢 D 按位分析. 既然两个数异或后的结果是 \(C\),那就考虑 \(C\) 中为 \(1\) 的数中有几个是在 \(X\) 当中的. 假如 \(\text{a - popcnt(X) = ...
- WIN8 WIN10 WIN11离线安装 .NET 3.5
WIN8 WIN10 WIN11离线安装 .NET 3.5 以WIN10为例: 1.双击WIN10 ISO 镜像,看挂载的是哪个盘符.我这边是E:. 2.使用 WIN + X 快捷键,打开 Windo ...
- 开源的Datadog?可观测性平台SigNoz是否名副其实?
SigNoz号称自己是开源领域的Datadog,基于OpenTelemetry做了一套可观测性方案.夜莺从V6版本开始,也希望做全栈可观测性方案,巧了,大家目标一致,今天我们一起来对SigNoz做个初 ...
- 牛客网在线编程-语法篇-基础语法——C 语言解题集
前言 牛客网在线编程-语法篇-基础语法--C 语言解题集. 点击下方超链接跳转至对应编程题目,文章包含解析及源码. 01-基础语法 简单输出 BC1-Hello Nowcoder BC2-小飞机 基本 ...