MRS HetuEgine的数据虚拟化实践
摘要:华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。
本文分享自华为云社区《基于华为云原生数据湖MRS HetuEgine的数据虚拟化实践》,作者: 前锋 。
数据虚拟化是指一种数据管理方式,允许应用在不关心数据源的数据格式及物理存储位置的情况下以一种统一的方式获取和使用整个组织中所有的数据。与数据虚拟化方式对应的一种方式是传统的ETL方式,数据经过抽取、转换和装载的过程,将不同系统的数据收集到一个统一的物理系统中,并经过标准化处理进行格式的统一。数据虚拟化的特点是不改变数据存储位置,实时访问。根据Gartner发布的数据管理技术成熟度曲线,数据虚拟化技术已经进入了生产成熟期,相关理论和技术也已经成熟,如果企业正在受困于各系统或者各部门数据无法高效打通的问题,可以考虑采用数据虚拟化技术。
早期的一种数据虚拟化实践是数据库联邦,在不同的数据库之间建立JDBC/ODBC连接的方式,以标准SQL的方式跨数据库进行数据实时访问。这种方式在传统数据库模式下一定程度上解决了跨数据源实时数据访问的问题。但是在大数据时代,数据的存储和访问方式已经完全不同,每种数据处理组件只解决一个特定的场景问题,具有不同的数据存储方式、组织方式和访问方式。如Hdoop用于解决大规模数据的批量计算,Hbase用于海量数据的实时精确检索,ElasticSearch用于海量数据的综合检索,还有MPP数据库、图数据库、内存数据库、时序数据库等等,百花齐放,百家争鸣,共同形成了大数据时代的数据处理技术栈,解决各个场景下的大规模数据处理问题。在实际的应用中,为了满足业务不同维度的需求,往往在同一个业务中同时使用了不同的处理组件,甚至是分布在不同地域的不同数据处理组件,造成了业务复杂度高,数据冗余,访问效率低等问题。
大数据时代的数据虚拟化技术就是要解决这种跨源跨域场景下的数据高效访问问题,以一种统一的接口,接近原生系统的性能,跨地域的方式进行数据访问。而要满足上述要求,一个数据虚拟化产品需要具备下面的四个功能:
- 统一元数据管理。具备全局数据的统一视图,包括数据承载的组件、数据的Schema、数据存储的格式、存储位置等。
- 抽象数据访问层。提供数据访问的抽象层,屏蔽不同数据源的接口差异,在访问层以一种统一的接口面向应用层。
- 统一的安全管控。全局统一安全管控策略,所有数据的访问在安全管控的框架下进行,避免数据越权访问。
- 多源结果集合并。来自不同集群,不同组件的结果数据可以关联、合并,以一个完整的结果集返回给应用层。
华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。如下图是MRS云原生数据湖平台基于HetuEngine构建的逻辑数据湖平台架构。HetuEngine可以跨Hadoop平台、MPP数据库、数据集市(包括Hbase、ElasticSearch、Clickhouse等)进行跨源访问,并提供统一的SQL接口供上层应用进行数据访问。HetuEngine还支持跨集群数据访问,实现高性能的跨数据湖、数据仓库、数据集市的分析查询。适用多个数据湖或者数据平台联合分析,支持用户间资源隔离,支持全局数据权限管理。
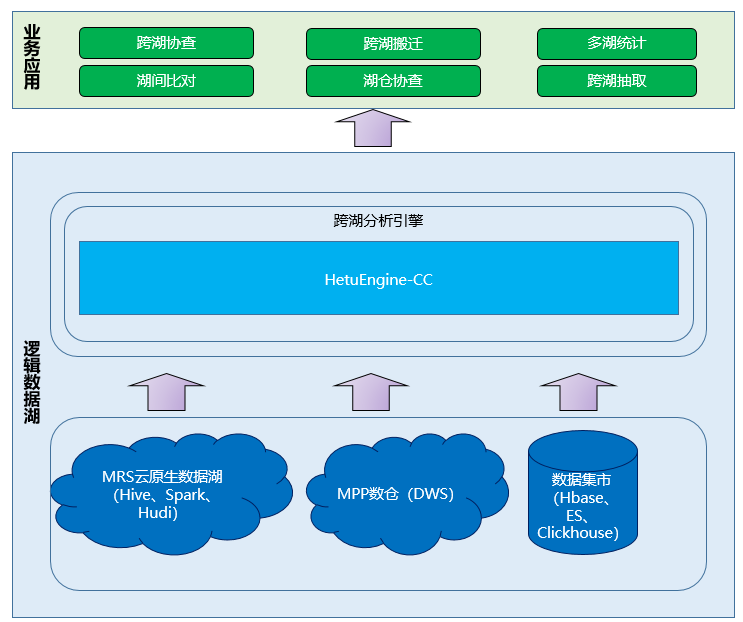
现在,HetuEngine已经帮助众多政企客户解决了在大数据场景下面临的用数难,取数难的问题。某大型国企就利用了HetuEngine的跨域分析能力解决了困扰其很长时间的全域数据实时访问的问题。
该大型国企有众多下属省公司,分布在全国各地,每个省公司都建设有自己的数据湖平台,用于支撑省公司内部的数字业务。各省公司每天要将自己的数据上报给集团公司,集团公司再对全国数据进行统一汇总加工处理,用于支撑集团层面的业务决策。这种方式面临以下几个问题:(1)数据上报不完整。由于带宽限制,只能上报部分结果数据,无法将全部的明细数据上报,部分需要明细数据的业务无法在集团层面开展。(2)数据上报延迟。子公司将数据加工后,分批上报集团公司,数据延迟在小时级别,无法支撑集团实时业务的开展。(3)资源投入太大。随着业务的发展,集团需要的数据越来越多,资源池原来越大,投入和产出无法匹配。(4)数据需求响应不及时。新的数据需求只能通过对分公司提数据需求,重新开发数据流程上报的方式满足,效率太低,无法支撑业务的时效性需求。
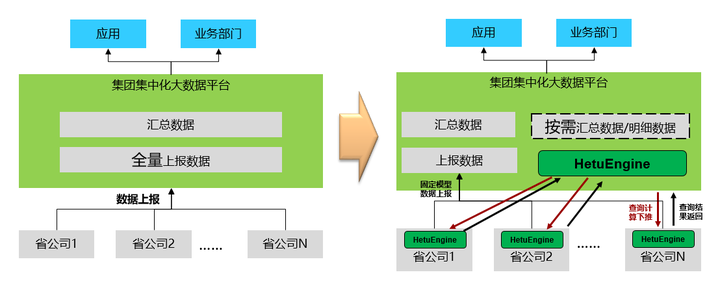
如上图所示,在旧模式下,所有的数据只能通过定时上报的方式收集到集团集中化大数据平台,再进行分析,供上层业务使用。引入HetuEngine后,上报的数据只是每天固定模型加工的数据,明细数据和临时汇总数据均可以通过HetuEngine进行实时的查询。通过HetuEngine不仅实现了高效的实时数据查询,还可以通过HetuEngine进行跨省公司的数据关联分析,打破了省公司之间的数据墙,大大提高了跨域数据分析的效率。
HetuEgine通过自己的跨域查询引擎,可以将一个复杂的跨域查询任务根据数据所在的位置将查询下发到数据所在的集群执行,充分利用边缘集群的算力,提高数据分析的效率和整体的资源利用率。如下图的一个场景,要统计年龄为35岁,在两个省同时开户的用户。可以通过一个SQL同时查询两个省公司的数据。HetuEngine将这个SQL下推到两个省公司集群执行,并将执行结果返回给集团公司进行统一汇总,直接向业务层返回最终的汇总结果。整个过程都是自动实时的进行,并且充分利用了边缘集群的算力,集团公司只需要消耗少量的带宽和算力就完成了整个计算过程。

HetuEngine在跨域场景下也充分考虑了整个计算过程的可靠性和安全性。数据访问遵循统一的安全管控模型,对远程数据访问进行细粒度的管控。数据传输过程采用加密传输,保障数据传输过程中的安全。考虑到跨地域的查询通常是传输带宽受限的场景,HetuEngine支持流量管控,防止由于查询结果集过大导致占满传输带宽,影响其他业务。此外,HetuEngine还综合采用了抗网络抖动、断点续传、压缩传输、级联查询等手段提高跨域查询的稳定性和效率。
最终,借助HetuEngine提供的数据虚拟化能力,该集团公司打造了一套高效的全域数据统一查询分析平台。首先,实现了全域数据在集团层面真正的统一,利用HetuEngine可随时访问集团所有省公司的数据。其次,减少了集团公司集群的压力,将大量的数据分析任务下发给省公司集群完成,充分利用省公司边缘集群的算力。然后,提高端到端的数据访问时延,数据由之前的小时级的延迟到现在可以秒级查询省公司集群数据。最后,借助HetuEgine跨源跨域查询能力,可以直接将分布在不同省不同存储组件中的数据在HetuEngine中进行关联分析,打破了数据之间的隔离,带来了很多新的数据应用场景,进一步挖掘了数据的价值。
MRS HetuEgine的数据虚拟化实践的更多相关文章
- Silverlight 中datagrid控件-- 通过设置数据虚拟化加速显示
定义依赖属性作为datagrid的数据源 protected static readonly DependencyProperty ViewLogsProperty = DependencyPrope ...
- 利用Kettle进行SQLServer与Oracle之间的数据迁移实践
Kettle简介 Kettle(网地址为http://kettle.pentaho.org/)是一款国外开源的ETL工具,纯java编写,可以在Windows.Linux.Unix上运行,数据抽取高效 ...
- Windows phone UI虚拟化和数据虚拟化(二)
书接上回的Windows phone UI虚拟化和数据虚拟化(一)我们学习了wp的ui虚拟化.今天来和大家分享一下wp的数据虚拟化. 并同时感谢我的同事dgwutao在编写此文时给我的巨大帮助,3ks ...
- Windows phone UI虚拟化和数据虚拟化(一)
今天和大家分享一些关于windows phone ui虚拟化和数据虚拟化的一些知识. 也顺便回答我上一篇[LongListSelector 控件 在 wp7 和wp8中的不同之处]里,留下的那个问题, ...
- SSIS数据同步实践
SSIS数据同步实践 背景 在已初步验证不同实例下同构表数据同步方案之后,为了实现数据持续同步,需使用SSIS把之前的生成脚本和执行脚本的两个步骤组合在一起部署成包之后,通过JOB定时去执行: 测 ...
- 阿里HBase的数据管道设施实践与演进
摘要:第九届中国数据库技术大会,阿里巴巴技术专家孟庆义对阿里HBase的数据管道设施实践与演进进行了讲解.主要从数据导入场景. HBase Bulkload功能.HImporter系统.数据导出场景. ...
- 基于 DolphinScheduler 的数据质量检查实践
今天给大家带来的分享是基于 Apache DolphinScheduler 的数据质量检查实践,分享的内容主要为以下四点: " 为什么要做数据质量检查? 为什么要基于 DolphinSche ...
- 即兴小探华为开源行业领先大数据虚拟化引擎openLooKeng
@ 目录 概述 定义 背景 特点 架构 关键技术 应用场景 安装 单台部署 集群部署 命令行接口 连接器 MySQL连接器 ClickHouse连接器 概述 定义 openLooKeng 官网地址 h ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- Appboy 基于 MongoDB 的数据密集型实践
摘要:Appboy 正在过手机等新兴渠道尝试一种新的方法,让机构可以与顾客建立更好的关系,可以说是市场自动化产业的一个前沿探索者.在移动端探索上,该公司已经取得了一定的成功,知名产品有 iHeartM ...
随机推荐
- 让物体动起来,Unity的几种移动方式
一.前言 在大部分的Unity游戏开发中,移动是极其重要的一部分,移动的手感决定着游戏的成败,一个优秀的移动手感无疑可以给游戏带来非常舒服的体验.而Unity中有多种移动方法,使用Transform, ...
- go实现一个切片迭代器
go实现一个简单的切片迭代器 package main import "fmt" type iterator struct { data []int index int // 索引 ...
- pkg-config手册
定义 pkg-config是一款用于返回已安装库元信息的工具: (语法)概要 pkg-config [--modversion] [--help] [--print-errors] [--silenc ...
- 手把手教你如何扩展(破解)mybatisplus的sql生成
mybatisplus 的常用CRUD方法 众所周知,mybatisplus提供了强大的代码生成能力,他默认生成的常用的CRUD方法(例如插入.更新.删除.查询等)的定义,能够帮助我们节省很多体力劳动 ...
- 使用DocumentBuilderFactory解析XML浅谈
背景: 当使用Java解析XML时,可以使用javax.xml.parsers.DocumentBuilderFactory类.这个类提供了一种创建解析XML的文档对象的方式.DocumentBuil ...
- 基础练习:FJ的字符串
问题描述 FJ在沙盘上写了这样一些字符串: A1 = "A" A2 = "ABA" A3 = "ABACABA" A4 = "AB ...
- 每天5分钟复习OpenStack(十一)Ceph部署
在之前的章节中,我们介绍了Ceph集群的组件,一个最小的Ceph集群包括Mon.Mgr和Osd三个部分.为了更好地理解Ceph,我建议在进行部署时采取手动方式,这样方便我们深入了解Ceph的底层.今天 ...
- String.trim()含义
就是去除两端空格,目前只用到了这个.
- windows下tomcat开机自启动
在Windows下,可以通过以下步骤将Tomcat设置为开机自启动: 1. 打开Tomcat安装目录:通常情况下,Tomcat的安装目录位于`C:\Program Files\Apache Softw ...
- python简介和基本数据类型
今天是2018年12月7日,开始python的学习,现在将知识点总结如下: 1 python语言有2个版本分别是 python2 .python3 区别还是很大的,例如 python2 中 1 ...