xpath语法与lxml库详解
xpath语法与lxml库
摘要:本文详细介绍了xpath语法,lxml库的使用以及两者的结合使用
注:平常爬虫运用的Xpath不是来自element中通过Chrome插件XPath Helper写出来的,而是通过Network中的source响应来写Xpath,只有当source和element中Xpath一致时才可以使用element来写
什么是XPath?
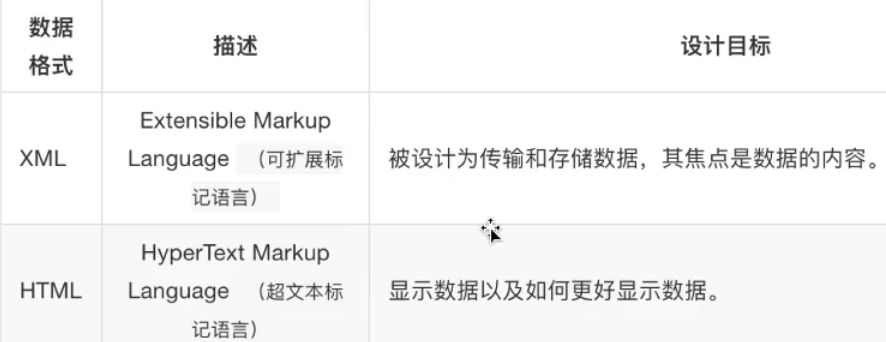
xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历。
XPath开发工具
- Chrome插件XPath Helper。
- Firefox插件Try XPath。
XPath语法

选取节点:
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
| 表达式 | 描述 | 示例 | 结果 |
|---|---|---|---|
| nodename | 选取此节点的所有子节点 | bookstore | 选取bookstore下所有的子节点 |
| / | 如果是在最前面,代表从根节点选取。否则选择某节点下的某个节点 | /bookstore | 选取根元素下所有的bookstore节点 |
| // | 从全局节点中选择节点,随便在哪个位置 | //book | 从全局节点中找到所有的book节点 |
| @ | 选取某个节点的属性 | //book[@price] | 选择所有拥有price属性的book节点 |
| ./.. | 当前节点/上一级 | ./a或../a | 选取当前节点下的a标签 |
谓语:
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 描述 |
|---|---|
| /bookstore/book[1] | 选取bookstore下的第一个子元素 |
| /bookstore/book[last()] | 选取bookstore下的倒数第二个book元素。 |
| bookstore/book[position() < 3] | 选取bookstore下前面两个子元素。 |
| //book[@price] | 选取拥有price属性的book元素 |
| //book[@price=10] | 选取所有属性price等于10的book元素 |
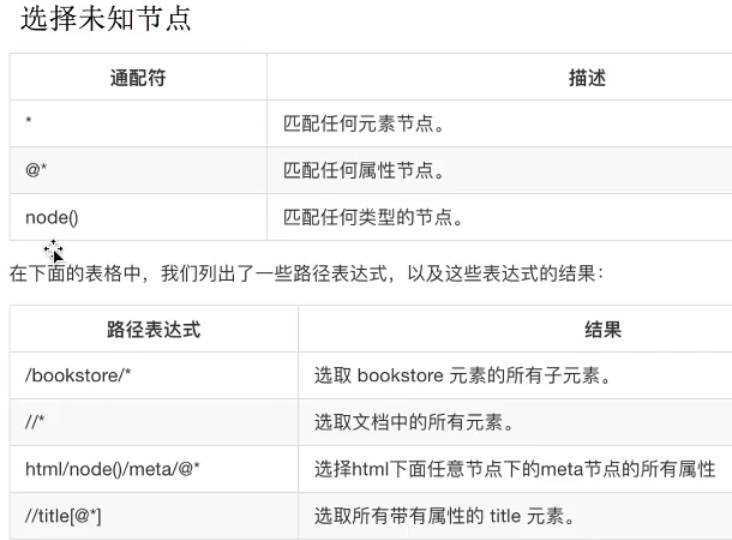
通配符
*表示通配符。
| 通配符 | 描述 | 示例 | 结果 |
|---|---|---|---|
| * | 匹配任意节点 | /bookstore/* | 选取bookstore下的所有子元素。 |
| @* | 匹配节点中的任何属性 | //book[@*] | 选取所有带有属性的book元素。 |
选取多个路径:
通过在路径表达式中使用“|”运算符,可以选取若干个路径。
示例如下:
//bookstore/book | //book/title
# 选取所有book元素以及book元素下所有的title元素
运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| | | 计算两个节点集 | //book | //cd | 返回所有拥有 book 和 cd 元素的节点集 |
| + | 加法 | 6 + 4 | 10 |
| - | 减法 | 6 - 4 | 2 |
| * | 乘法 | 6 * 4 | 24 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
| != | 不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| < | 小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| <= | 小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
| > | 大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
| >= | 大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
| or | 或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
| and | 与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
| mod | 计算除法的余数 | 5 mod 2 | 1 |


lxml库
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:pip install lxml
基本使用:

我们可以利用他来解析HTML代码,并且在解析HTML代码的时候,如果HTML代码不规范,他会自动的进行补全。示例代码如下:
# 使用 lxml 的 etree 库
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a> # 注意,此处缺少一个 </li> 闭合标签
</ul>
</div>
'''
#利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text)
# 按字符串序列化HTML文档
result = etree.tostring(html)
print(result)
输入结果如下:
<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>
可以看到。lxml会自动修改HTML代码。例子中不仅补全了li标签,还添加了body,html标签。
从文件中读取html代码:
除了直接使用字符串进行解析,lxml还支持从文件中读取内容。我们新建一个hello.html文件:
<!-- hello.html -->
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
然后利用etree.parse()方法来读取文件。示例代码如下:
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
输入结果和之前是相同的。
在lxml中使用XPath语法:
获取所有li标签:
from lxml import etree html = etree.parse('hello.html')
print type(html) # 显示etree.parse() 返回类型 result = html.xpath('//li') print(result) # 打印<li>标签的元素集合
获取所有li元素下的所有class属性的值:
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li/@class') print(result)
获取li标签下href为
www.baidu.com的a标签:from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="www.baidu.com"]') print(result)
获取li标签下所有span标签:
from lxml import etree html = etree.parse('hello.html') #result = html.xpath('//li/span')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠 result = html.xpath('//li//span') print(result)
获取li标签下的a标签里的所有class:
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li/a//@class') print(result)
获取最后一个li的a的href属性对应的值:
from lxml import etree html = etree.parse('hello.html') result = html.xpath('//li[last()]/a/@href')
# 谓语 [last()] 可以找到最后一个元素 print(result)
获取倒数第二个li元素的内容:
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a') # text 方法可以获取元素内容
print(result[0].text)
获取倒数第二个li元素的内容的第二种方式:
from lxml import etree html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a/text()') print(result)
使用requests和xpath爬取电影天堂
示例代码如下:
import requests
from lxml import etree
BASE_DOMAIN = 'http://www.dytt8.net'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36',
'Referer': 'http://www.dytt8.net/html/gndy/dyzz/list_23_2.html'
}
def spider():
url = 'http://www.dytt8.net/html/gndy/dyzz/list_23_1.html'
resp = requests.get(url,headers=HEADERS)
# resp.content:经过编码后的字符串
# resp.text:没有经过编码,也就是unicode字符串
# text:相当于是网页中的源代码了
text = resp.content.decode('gbk')
# tree:经过lxml解析后的一个对象,以后使用这个对象的xpath方法,就可以
# 提取一些想要的数据了
tree = etree.HTML(text)
# xpath/beautifulsou4
all_a = tree.xpath("//div[@class='co_content8']//a")
for a in all_a:
title = a.xpath("text()")[0]
href = a.xpath("@href")[0]
if href.startswith('/'):
detail_url = BASE_DOMAIN + href
crawl_detail(detail_url)
break
#清洗数据
def crawl_detail(url):
resp = requests.get(url,headers=HEADERS)
text = resp.content.decode('gbk')
tree = etree.HTML(text)
create_time = tree.xpath("//div[@class='co_content8']/ul/text()")[0].strip()
imgs = tree.xpath("//div[@id='Zoom']//img/@src")
# 电影海报
cover = imgs[0]
# 电影截图
screenshoot = imgs[1]
# 获取span标签下所有的文本
infos = tree.xpath("//div[@id='Zoom']//text()")
#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
for index,info in enumerate(infos):
if info.startswith("◎年 代"):
year = info.replace("◎年 代","").strip()
if info.startswith("◎豆瓣评分"):
douban_rating = info.replace("◎豆瓣评分",'').strip()
print(douban_rating)
if info.startswith("◎主 演"):
# 从当前位置,一直往下面遍历
actors = [info]
for x in range(index+1,len(infos)):
actor = infos[x]
if actor.startswith("◎"):
break
actors.append(actor.strip())
print(",".join(actors))
if __name__ == '__main__':
spider()
xpath语法与lxml库详解的更多相关文章
- 12.Python爬虫利器三之Xpath语法与lxml库的用法
LXML解析库使用的是Xpath语法: XPath 是一门语言 XPath可以在XML文档中查找信息 XPath支持HTML XPath通过元素和属性进行导航 XPath可以用来提取信息 XPath比 ...
- Xpath语法与lxml库
1. Xpath 1 )什么是XPath? xpath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,可用来在XML和HTML文档中对元素和属性进行遍历. 2) X ...
- Python爬虫利器三之Xpath语法与lxml库的用法
前面我们介绍了 BeautifulSoup 的用法,这个已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法.如果大家对 Beau ...
- 芝麻HTTP:Python爬虫利器之Xpath语法与lxml库的用法
安装 pip install lxml 利用 pip 安装即可 XPath语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPat ...
- Xpath语法与lxml库的用法
BeautifulSoup 已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的是 Xpath 语法,同样是效率比较高的解析方法. 1.安装 pip install lxml 2 ...
- python爬虫(8)--Xpath语法与lxml库
1.XPath语法 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XML 文档中对元素和属性进行遍历.XPath 是 W3C XSLT 标准的主要元素,并且 XQuery ...
- 请求数据分析 xpath语法 与lxml库
前情提要: 上节学过从网上获取请求,获取返回内容,带理 获取内容之后,第二部就是获取请求的数据分析 一:xpath 语法 浏览器一般会自带xpatn 解析 这里大概讲述一下xpath 的基本操作 二: ...
- xpath教程 2 - lxml库
xpath教程 2 - lxml库 这些就是XPath的语法内容,在运用到Python抓取时要先转换为xml. lxml库 lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HT ...
- 最强常用开发库总结 - JSON库详解
最强常用开发库总结 - JSON库详解 JSON应用非常广泛,对于Java常用的JSON库要完全掌握.@pdai JSON简介 JSON是什么 JSON 指的是 JavaScript 对象表示法(Ja ...
- 常用开发库 - MapStruct工具库详解
常用开发库 - MapStruct工具库详解 MapStruct是一款非常实用Java工具,主要用于解决对象之间的拷贝问题,比如PO/DTO/VO/QueryParam之间的转换问题.区别于BeanU ...
随机推荐
- PXC集群脑裂导致节点是无法加入无主的集群
一套2节点的MySQL PXC集群,第1节点作为主用节点长时间的dml操作,导致大量的事务阻塞,出现异常,此时查看第2节点显示是primary状态,但无事务阻塞情况. 此时第1节点无法正常提供服务,于 ...
- 算法解析:LeetCode——机器人碰撞和最低票价
摘要:本文由葡萄城技术团队原创.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 机器人碰撞 问题: 现有 n 个机器人,编号从 1 开始,每个机器人包含在路 ...
- C#计数排序算法
前言 计数排序是一种非比较性的排序算法,适用于排序一定范围内的整数.它的基本思想是通过统计每个元素的出现次数,然后根据元素的大小依次输出排序结果. 实现原理 首先找出待排序数组中的最大值max和最小值 ...
- windows平板的开发和选型
今天谈一个老话题,windows系统的选型和开发.问题的起因是我们一个客户说,用安卓平板不安全,苹果系统不考虑,于是他们要用自认为安全的WIN7系统. 提到WINDOWS平台下的的平板系统,此事说来话 ...
- C#桶排序算法
前言 桶排序是一种线性时间复杂度的排序算法,它将待排序的数据分到有限数量的桶中,每个桶再进行单独排序,最后将所有桶中的数据按顺序依次取出,即可得到排序结果. 实现原理 首先根据待排序数据,确定需要的桶 ...
- Atcoder Regular Contest 166
只打了半场. A. Replace C or Swap AB 首先如果存在某个 \(i\),使得 \(Y_i\) 是 C 且 \(X_i\) 不是,那么显然是不合法的,可以直接判掉. 那么除去上述情况 ...
- CF1707B [Difference Array]
Problem 题目简述 设序列 \(a\) ,并且是单调递增的.设 \(a\) 当前长度为 \(l\),你要对 \(a\) 作差分,即令 \(b_i = a_{i+1} - a_i(1\le i & ...
- Pandas 分组聚合操作详解
Pandas 是 Python 中用于数据分析的重要工具,它提供了丰富的数据操作方法.在数据分析过程中,经常需要对数据进行分组聚合操作.本文将介绍 Pandas 中的数据分组方法以及不同的聚合操作,并 ...
- Hive的使用以及如何利用echarts实现可视化在前端页面展示(四)---连接idea使用echarts可视化界面
说来惭愧,我的javaweb烂得一批,其他步骤我还是很顺利地,这个最简单的,我遇到了一系列问题.只能说,有时候失败也是一种成功吧 这一步其实就是正常的jdbc,没什么可说明的,但是关于使用echart ...
- 掌握这些,轻松管理BusyBox:inittab文件的配置和作用解析
BusyBox 是一个轻量级的开源工具箱,其中包含了许多标准的 Unix 工具,例如 sh.ls.cp.sed.awk.grep 等,同时它也支持大多数关键的系统功能,例如自启动.进程管理.启动脚本等 ...