ElasticSearch7.3学习(十七)----搜索结果字段解析及time_out字段解析
1、搜索结果字段解析
首先插入一条测试数据
PUT /my_index/_doc/1
{
"title": "2019-09-10"
}
然后无条件搜索所有
GET my_index/_search得到的结果
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "2019-09-10"
}
}
]
}
}
解释
took:took表示Elasticsearch执行搜索所用的时间,单位是毫秒。这里0毫秒代表特别快,实际上一般都在几十毫秒以上。
timed_out:是否超时,这里是没有
_shards:指示搜索了多少分片,成功几个,跳过几个,失败几个。
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的所有详细数据
2、time_out字段解析
例如下图所示:存在一个book索引,2个分片,0副本。
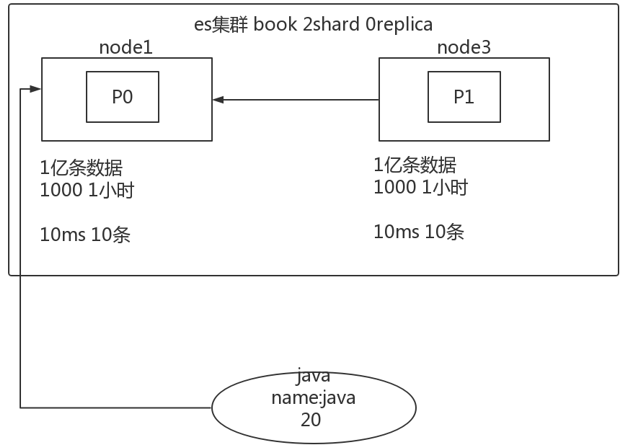
两个节点上都存在1亿条数据,假如说搜索10条,只需要10ms,这样对前端没啥影响,但是数据量太大时,搜索1个分片都需要10分钟的话,而且ES搜索的请求是每个主分片都要进行搜索,那么这个时间还得加长。这样情况下,用户肯定是受不了的。
于是引出time_out机制。指定每个shard只能在给定时间内查询数据,能有几条就返回几条。这样至少能搜索出来结果,用户也能好受一点。
ElasticSearch7.3学习(十七)----搜索结果字段解析及time_out字段解析的更多相关文章
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- ElasticSearch7.3学习(二十五)----Doc value、query phase、fetch phase解析
1.Doc value 搜索的时候,要依靠倒排索引: 排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序. 所谓的正排索引,其实就是doc values. 在建立索引 ...
- 狂神说Elasticsearch7.X学习笔记整理
Elasticsearch概述 一.什么是Elasticsearch? Lucene简介 Lucene是一套用于全文检索和搜寻的开源程序库,由Apache软件基金会支持和提供 Lucene提供了一个简 ...
- ElasticSearch7.3学习(三十二)----logstash三大插件(input、filter、output)及其综合示例
1. Logstash输入插件 1.1 input介绍 logstash支持很多数据源,比如说file,http,jdbc,s3等等 图片上面只是一少部分.详情见网址:https://www.elas ...
- Solr系列五:solr搜索详解(solr搜索流程介绍、查询语法及解析器详解)
一.solr搜索流程介绍 1. 前面我们已经学习过Lucene搜索的流程,让我们再来回顾一下 流程说明: 首先获取用户输入的查询串,使用查询解析器QueryParser解析查询串生成查询对象Query ...
- 重磅 | Elasticsearch7.X学习路线图
原文:重磅 | Elasticsearch7.X学习路线图 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.c ...
- Elasticsearch7.6学习笔记1 Getting start with Elasticsearch
Elasticsearch7.6学习笔记1 Getting start with Elasticsearch 前言 权威指南中文只有2.x, 但现在es已经到7.6. 就安装最新的来学下. 安装 这里 ...
- [Elasticsearch] 多字段搜索 (三) - multi_match查询和多数字段 <译>
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在“了解你的数据”一节中提 ...
- [Elasticsearch] 多字段搜索 (三) - multi_match查询和多数字段
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在"了解你的数据 ...
- [Elasticsearch2.x] 多字段搜索 (三) - multi_match查询和多数字段 <译>
multi_match查询 multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询. NOTE 存在几种类型的multi_match查询,其中的3种正好和在“了解你的数据”一节中提 ...
随机推荐
- 函数计算 FC 3.0 发布,全面降价,最高幅度达93%,阶梯计费越用越便宜
作为国内最早布局 Serverless 的云厂商之一,阿里云在 2017 年推出函数计算 FC,开发者只需编写代码并上传,函数计算就会自动准备好相应的计算资源,大幅简化开发运维过程.阿里云函数计算持续 ...
- [译] kubernetes:kube-scheduler 调度器代码结构概述
本文翻译自 https://github.com/kubernetes/community/blob/master/contributors/devel/sig-scheduling/scheduli ...
- 【SI】source insight4 添加指定类型的文件
Options->File Type Options 红框可选择是否将指定类型的文件添加到工程 绿框可添加自定义文件类型,如汇编*.s;*.S 蓝框可新增文件类别,用于自定义文件类型 如不需将t ...
- redis-持久化-RDB-AOF.png
- MySQL重建表统计信息
MySQL重建表统计信息 背景 最近一段时间遇到了一些性能问题 发现很多其实都是由于 数据库的索引/统计信息不准确导致的问题. Oracle和SQLServer都遇到了很多类似的问题. 我这边联想到 ...
- [转帖]SkyWalking告警使用
SkyWalking告警 SkyWalking提供了强大的监控告警功能,在监控到应用出现问题的时候,会调用webhook或者gRPC hook或者Wechat DingDing等工具报告警告信息 而且 ...
- [转帖]自动清理_详解centos7和centos6系统的/tmp目录自动清理规则及区别
概述 分享最近应用碰到的一个奇怪bug,一开始以为是代码上的问题,找了一段时间发现居然是因为系统的一个自动清理规则导致,下面一起来看看吧~ 一.应用报错: logwire.core.exception ...
- [转帖]ORACLE恢复神器之ODU/AUL/DUL
https://www.cnblogs.com/oracle-dba/p/3873870.html 分享ORACLE数据库恢复神器之ODU.DUL和AUL工具. ODU:ORACLE DATABASE ...
- [转帖]Kafka-LEO和HW概念及更新流程
https://www.cnblogs.com/youngchaolin/p/12641463.html 目录 LEO&HW基本概念 LEO&HW更新流程 LEO HW 更新流程示例分 ...
- OpenEuler2203安装Redislabs的简单记录
OpenEuler2203安装Redislabs的简单记录 背景 操作系统国产化的需求下 想着都转型到openEuler上面来. 应用和容器都没什么问题了,现在考虑一下一些企业软件 最近一直在想研究一 ...