【爬虫案例】用Python爬取抖音热榜数据!
一、爬取目标
您好,我是@马哥python说,一名10年程序猿。
本次爬取的目标是:抖音热榜
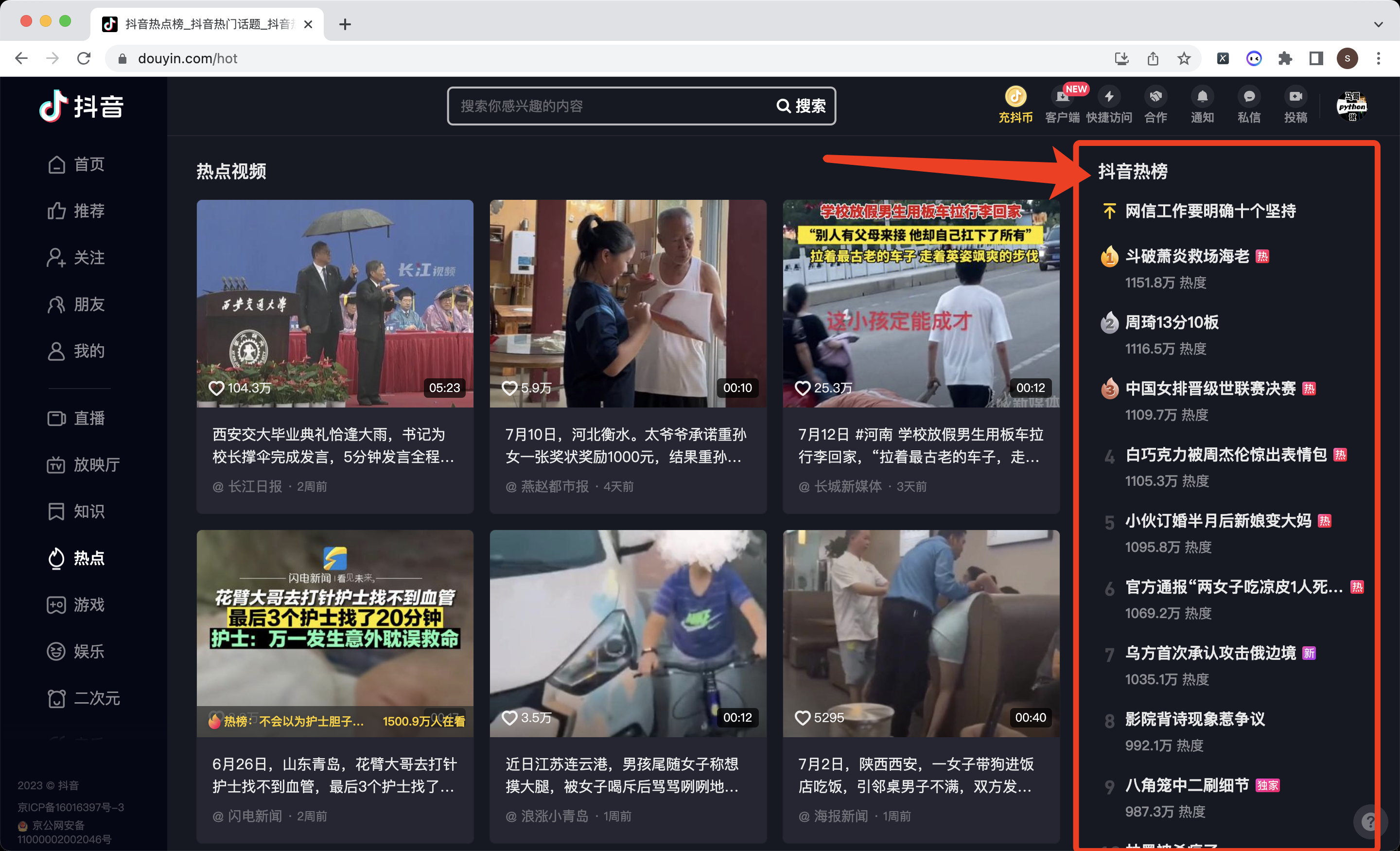
共爬取到50条数据,对应TOP50热榜。含5个字段,分别是:
热榜排名,热榜标题,热榜时间,热度值,热榜标签。
用Chrome浏览器,右键打开开发者模式,选择:网络->XHR这个选项,重新刷新一下页面。
操作过程,如下图所示:
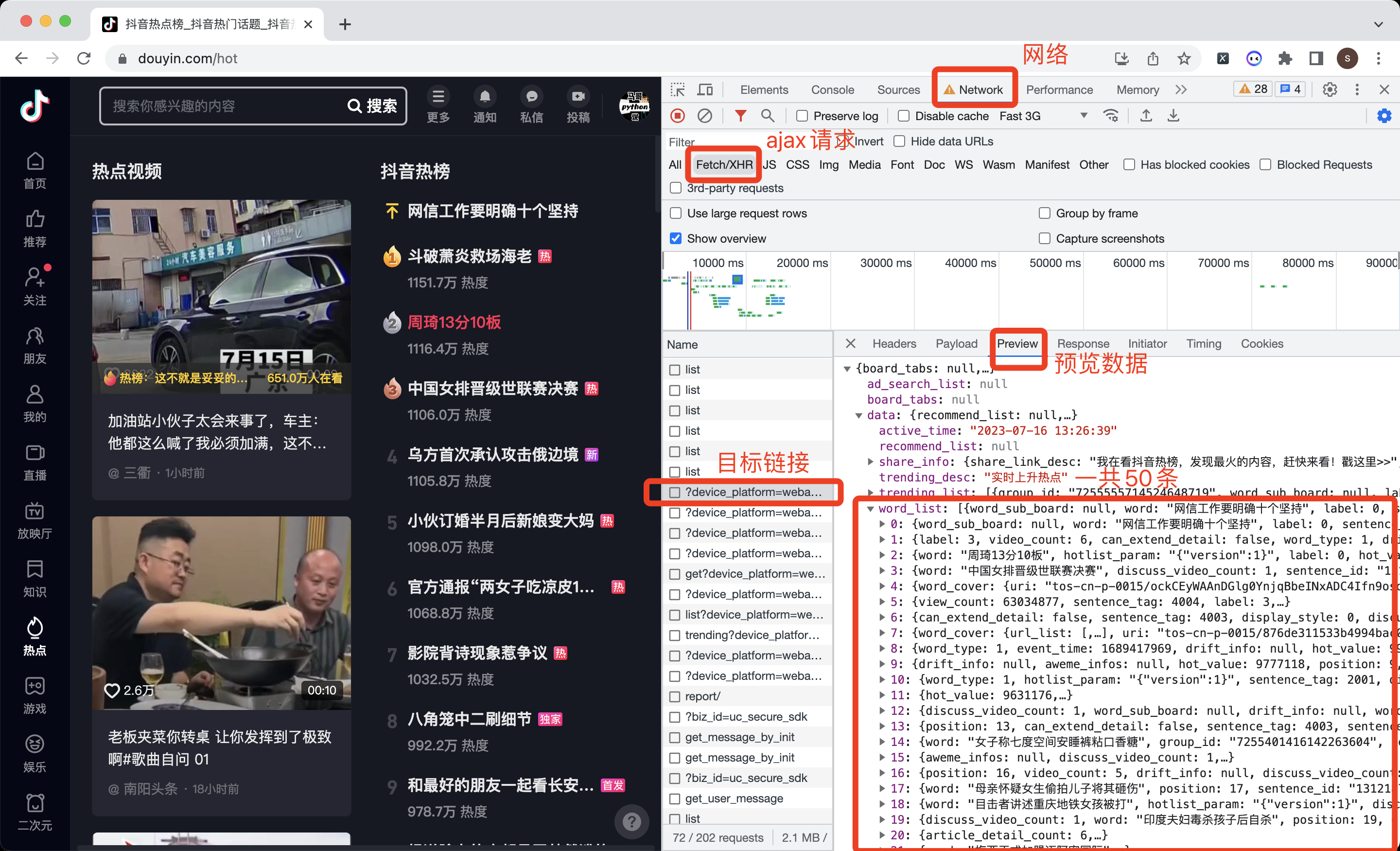
成功找到了50条热榜数据。
下面,开始编码爬虫代码。
二、编写爬虫代码
首先,导入需要用到的库:
import requests
import pandas as pd
import time
定义一个请求地址,即上图中的目标链接地址:
# 接口地址
url = 'https://www.douyin.com/aweme/v1/web/hot/search/list/?device_platform=webapp&aid=6383&channel=channel_pc_web&detail_list=1&source=6&pc_client_type=1&version_code=170400&version_name=17.4.0&cookie_enabled=true&screen_width=1440&screen_height=900&browser_language=en-US&browser_platform=MacIntel&browser_name=Chrome&browser_version=114.0.0.0&browser_online=true&engine_name=Blink&engine_version=114.0.0.0&os_name=Mac+OS&os_version=10.15.7&cpu_core_num=4&device_memory=8&platform=PC&downlink=1.5&effective_type=3g&round_trip_time=600&webid=7246602757481154103&msToken=A-dVF1R3L6t6yeYNVsnPA7YMBkohetjMSING0Q3C3UGXBq7B_lhuJVv6N1hF8Yum9qxQMMVa_GiSsER1Yf595bF5Q_O3-JY1hQ8s-ZPB21PCVYL5C7PEjQiPAMGtGg==&X-Bogus=DFSzswVOXn0ANcrmtjl2YN7TlqSE'
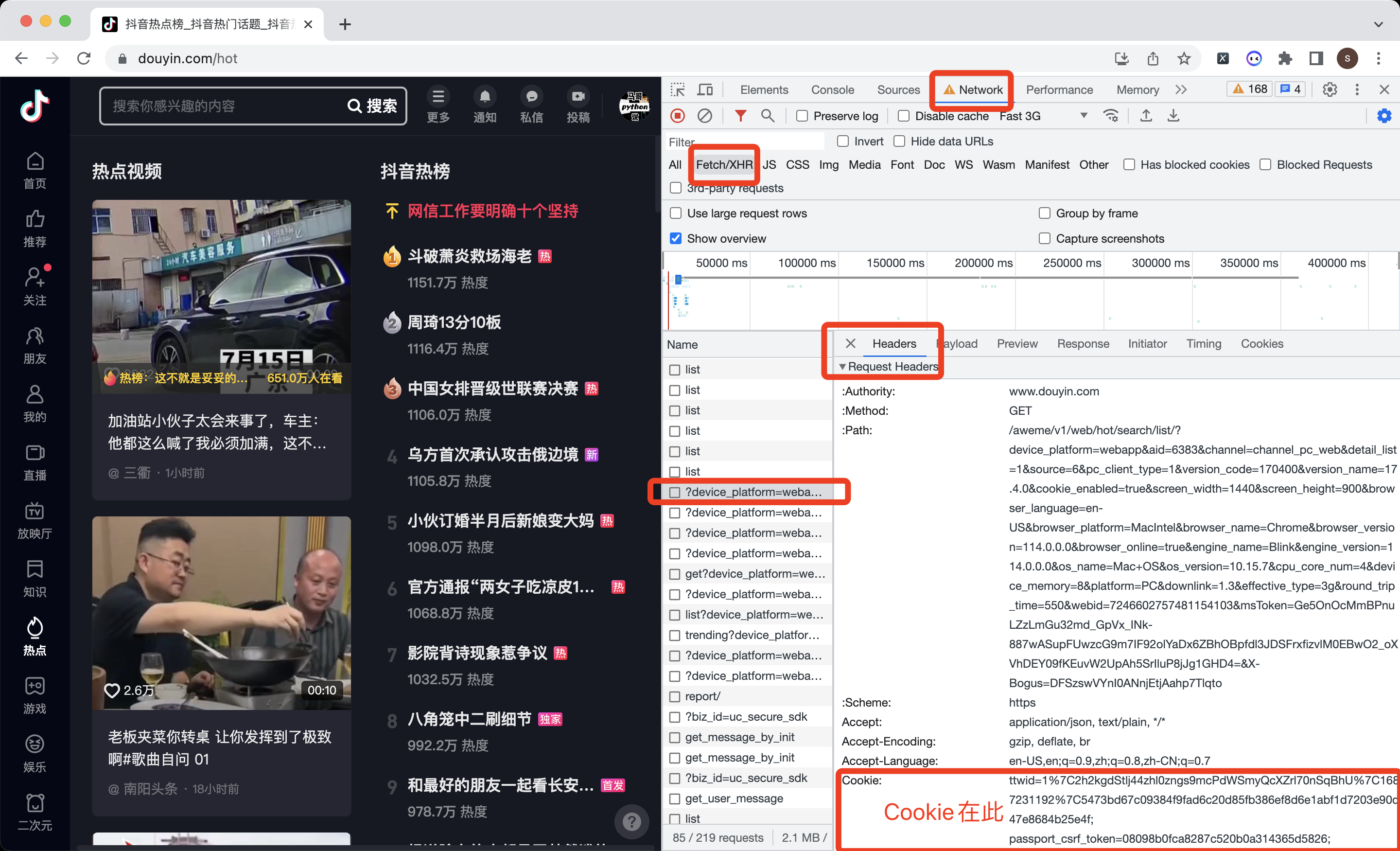
定义一个请求头,从开发者模式中的Headers->Request Headers中复制下来:
# 构造请求头
h1 = {
'Cookie': '换成自己的cookie值',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Host': 'www.douyin.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Referer': 'https://www.douyin.com/hot',
'Connection': 'keep-alive'
}
不知如何获取Cookie?参考下图:
向目标地址发送请求(带上请求头),并用json格式接收返回数据:
# 发送请求
r = requests.get(url, headers=h1)
# 用json接收请求数据
json_data = r.json()
定义一些空列表,用于存储数据:
position_list = [] # 热榜排名
title_list = [] # 热榜标题
time_list = [] # 热榜时间
hot_value_list = [] # 热度值
label_list = [] # 热榜标签
以“热榜标题”为例,解析数据:
for data in data_list:
# 热榜标题
title = data['word']
print('热榜标题:', position, title)
title_list.append(title)
其他字段同理,不再赘述。
最后,把解析到的数据,存储到Dataframe中,并保存到csv文件里:
# 拼装爬取到的数据为DataFrame
df = pd.DataFrame(
{
'热榜排名': position_list,
'热榜标题': title_list,
'热榜时间': time_list,
'热度值': hot_value_list,
'热榜标签': label_list,
}
)
# 保存结果到csv文件
df.to_csv('抖音热榜.csv', index=False, encoding='utf_8_sig')
这里需要注意的是,to_csv要加上encoding='utf_8_sig'参数,防止保存到csv文件产生乱码数据。
查看部分爬取结果:
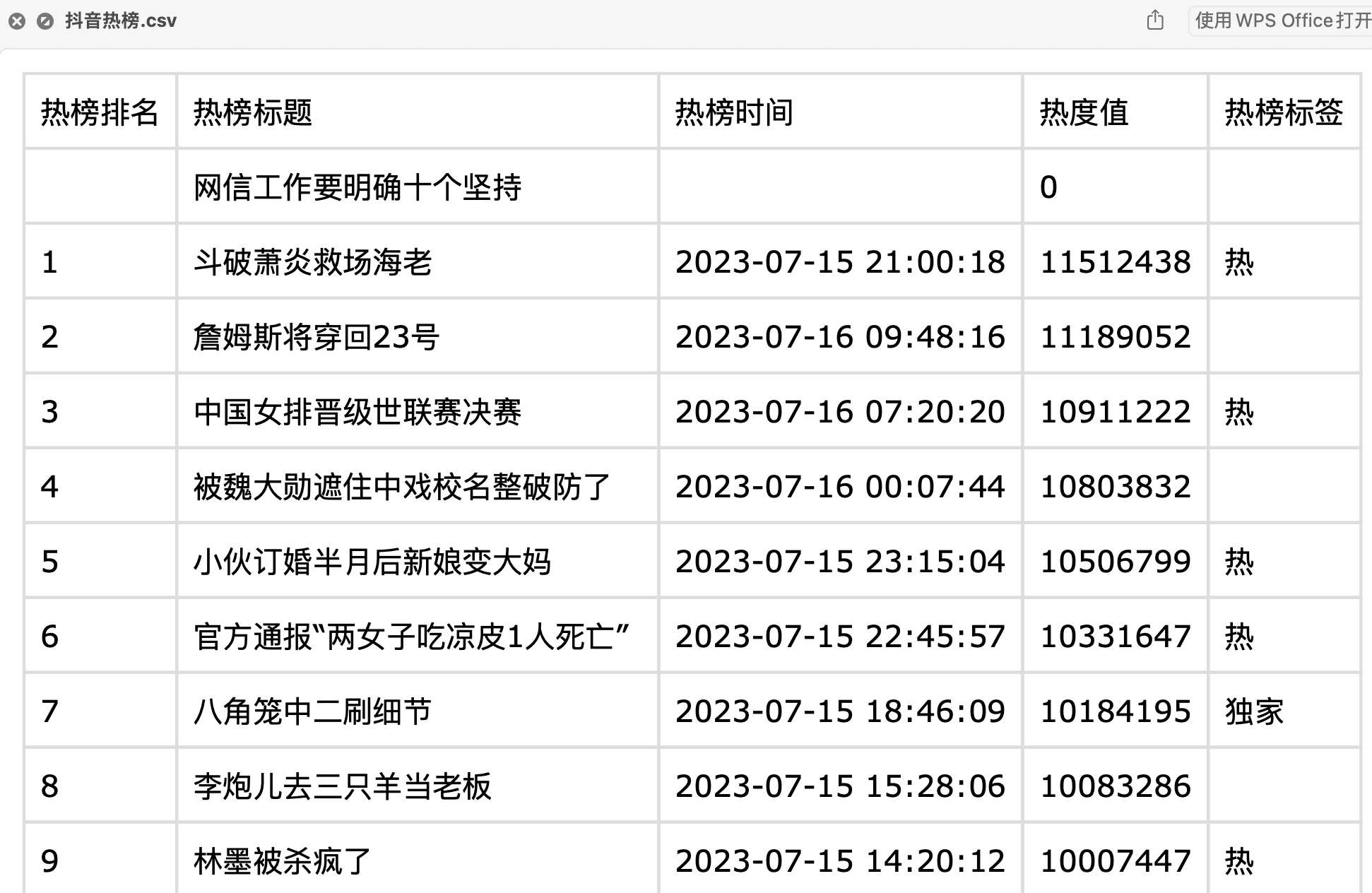
共51条数据(含1条置顶热搜),对应热榜TOP50排名。
每条数据含5个字段:热榜排名,热榜标题,热榜时间,热度值,热榜标签。。
三、同步讲解视频
3.1 代码演示视频
代码演示: 【Python爬虫演示】用Python爬抖音热榜数据
四、获取完整源码
get完整源码:【爬虫案例】用Python爬取抖音热榜数据!
我是@马哥python说 ,持续分享python源码干货中!
【爬虫案例】用Python爬取抖音热榜数据!的更多相关文章
- python爬取抖音APP视频教程
本文讲述爬取抖音APP视频数据(本文未完,后面还有很多地方优化总结) 公众号回复:抖音 即可获取源码 1.APP抓包教程,需要用到fiddler fiddler配置和使用查看>>王者荣耀盒 ...
- 教你用python爬取抖音app视频
记录一下如何用python爬取app数据,本文以爬取抖音视频app为例. 编程工具:pycharm app抓包工具:mitmproxy app自动化工具:appium 运行环境:windows10 思 ...
- 一篇文章教会你用Python抓取抖音app热点数据
今天给大家分享一篇简单的安卓app数据分析及抓取方法.以抖音为例,我们想要抓取抖音的热点榜数据. 要知道,这个数据是没有网页版的,只能从手机端下手. 首先我们要安装charles抓包APP数据,它是一 ...
- Python爬取抖音视频
最近在研究Python爬虫,顺便爬了一下抖音上的视频,找到了哥们喜欢的小姐姐居多,咱们给他爬下来吧. 最终爬取结果 好了废话补多说了,上代码! #https://www.iesdouyin.com/a ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
抖音很火,楼主使用python随机爬取抖音视频,并且无水印下载,人家都说天下没有爬不到的数据,so,楼主决定试试水,纯属技术爱好,分享给大家.. 1.楼主首先使用Fiddler4来抓取手机抖音app这 ...
- Python爬虫---爬取抖音短视频
目录 前言 抖音爬虫制作 选定网页 分析网页 提取id构造网址 拼接数据包链接 获取视频地址 下载视频 全部代码 实现结果 待解决的问题 前言 最近一直想要写一个抖音爬虫来批量下载抖音的短视频,但是经 ...
- python网络爬虫第三弹(<爬取get请求的页面数据>)
一.urllib库 urllib是python自带的一个用于爬虫的库,其主要作用就是通过代码模拟浏览器发送请求,其常被用到的子模块在 python3中的为urllib.request 和 urllib ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
随机推荐
- -bash: jps:未找到命令 CentOS7
yum install java-1.8.0-openjdk-devel.x86_64
- KingbaseES V8R6 集群运维案例--备库timeline not contain minimum recovery point故障
案例现象: KingbaseES V8R6集群备库启动后,加入集群失败,sys_log日志信息提示,如下图所示: 适用版本: kingbaseES V8R6 一.问题分析 在timeline对应的 ...
- Notion笔记汉化
Notion笔记汉化 参考:https://github.com/Reamd7/notion-zh_CN 关注我的订阅号[靠谱杨阅读人生]回复[Notion]获取中文包 1.进入notion的安装路径 ...
- 在idea/webstorm等terminal运行命令报错:Command rejected by the operating system没有权限【已解决】
在idea/webstorm等编译器terminal窗口运行命令报错:Command rejected by the operating system没有权限[已解决] 1.修改terminal窗口 ...
- #线性dp#洛谷 5999 [CEOI2016]kangaroo
题目 问有多少个长度为 \(n\) 的排列满足首项为 \(st\),末项为 \(ed\), 并且 \(\forall i\in (1,n),\left[a_{i-1}<a_i \oplus a_ ...
- TVM 代码生成—TIR to LLVM IR
本文地址:https://www.cnblogs.com/wanger-sjtu/p/17573212.html TVM在编译过程中,经历了 graph LR A[3rd IR] --> B[R ...
- Spring内存马分析
环境搭建 踩了很多坑....,不过还好最后还是成功了 IDEA直接新建javaEE项目,然后记得把index.jsp删了,不然DispatcherServlet会失效 导入依赖: <depend ...
- mybatis 查询一对多子表只能查出一条数据
mybatis 插叙一对多子表只能查出一条数据 环境 ssm 持久层 mybatis 关联查询一对多<collection> 原因 主表id 和子表id 一样 处理方式: select ...
- OOM异常类型总结
OOM是什么?英文全称为 OutOfMemoryError(内存溢出错误).当程序发生OOM时,如何去定位导致异常的代码还是挺麻烦的. 要检查OOM发生的原因,首先需要了解各种OOM情况下会报的异常信 ...
- HDC2021技术分论坛:鸿蒙智联设备开发,这五大法宝你应该拥有
作者:zhaowenguang,dinglu, 华为高级工程师 Huawei LiteOS是轻量级的开源物联网操作系统.智能硬件使能平台,可广泛应用于智能家居.穿戴式.车联网.制造业等领域,使物联网终 ...