[转帖]TiKV 缩容不掉如何解决?
TiKV节点缩容不掉,通常遇到的情况:
1、经常遇到的情况是:3个节点的tikv集群缩容肯定会一直卡着,因为没有新节点接受要下线kv的region peer。
2、另外就是除缩容tikv外,剩下的KV硬盘使用情况比较高,到达schedule.high-space-ratio=0.6的限制,导致该tikv的region无法迁移。
但是今天要讨论的是:我先执行了扩容,然后再进行的缩容,仍然卡着就说不过去了。
问题现场
版本:TiDB v5.2.1 情况说明:这个tidb是有tiflash节点的,并且这个集群是一路从3.X升级到5.2.1版本 问题现场:为了下线一个3kv集群中的一个kv,我们在24号扩容了一个新kv,然后扩容完毕后,下线某个kv,都过了2天,该kv还是处于pending offline的状态,看监控leader+reigon已经切走了,为啥该kv的状态仍然没有tombstone?
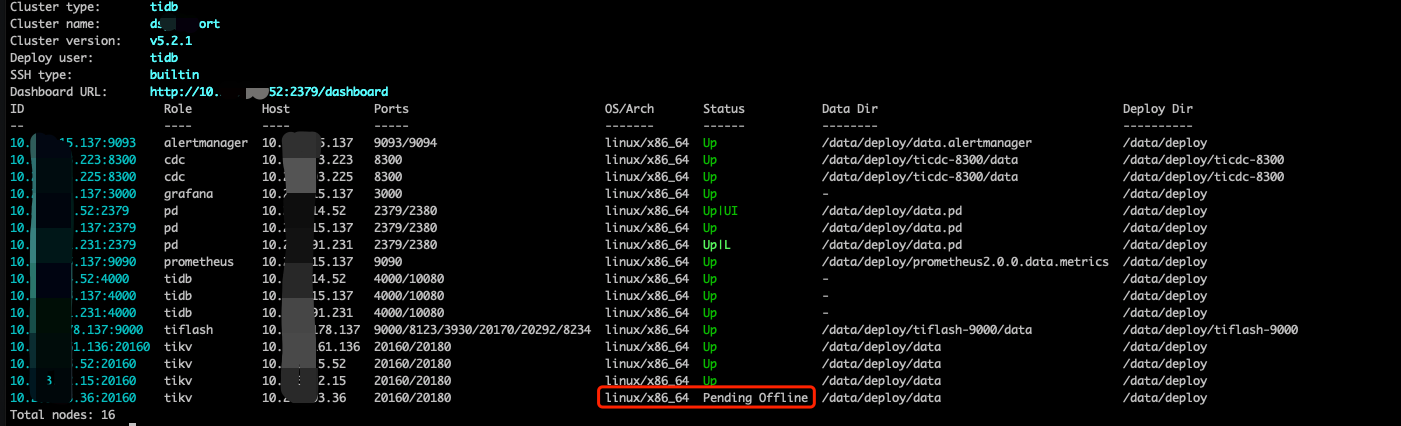
下图是扩容和缩容tikv的监控,从下图可以发现扩容和缩容都已经完毕了。

问题排查
(1)先看看有缩容问题的TIKV节点日志
查看日志发现有:KvService::batch_raft send response fail报错,查了下asktug,发现这些报错指向一个4.X的bug:raft 大小限制的过大,超过 gRPC 传输通信限制导致 raft message 卡住的问题,所以影响了 region 的调度。将 TiKV 集群的 raft-max-size-per-msg 这个配置调小,降低 raft message 大小来看是否能恢复 region 调度。
如果其他人的4.X版本遇到这个问题可以通过上面方式搞定,但是目前我已经升级到了5.2.1,所以上面方法不适合解决我的这个问题。相关的报错日志如下:
-
$ grep 'ERROR' tikv.log
-
[2022/03/28 09:34:38.062 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
-
[2022/03/28 09:34:38.062 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
-
[2022/03/28 09:34:38.227 +08:00] [ERROR] [pd.rs:83] ["Failed to send read flow statistics"] [err="channel has been closed"]
-
[2022/03/28 09:34:38.261 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
-
[2022/03/28 09:34:38.261 +08:00] [ERROR] [kv.rs:729] ["KvService::batch_raft send response fail"] [err=RemoteStopped]
-
[2022/03/28 09:34:55.711 +08:00] [ERROR] [server.rs:1030] ["failed to init io snooper"] [err_code=KV:Unknown] [err="\"IO snooper is not started due to not compiling with BCC\""]
(2)查看节点情况,发现该节点除了状态为Offline外,leader_count/region_count都为0,为啥都为0了,等了2天还是pending offline?没有变tombstone?

(3)查看有问题tikv节点的region信息。
结果发现不得了的结果,这个不能成功下线的tikv store 5,竟然还有一个id为434317的region,这个region没有leader,有3个voter(在store 5 、1 、 4上)和2个Learner(在tiflash store 390553和390554上),并且这2个tiflash store还是集群升级前4.0.9版本的store id,并且之前对tikv/tiflash节点执行过scale-in --force等暴力下线的操作,至于该region为啥没有选出leader,一则可能是bug,二则可能是暴力下线tikv/tiflash导致。
也就是说:这个没有leader的region:434317,因为他在store_id:5 上还有记录,这个问题成为了阻碍该tikv一直卡到offline状态无法成功下线的原因。
(4)查看下该region对应的库表信息,看是否对业务有影响,执行后发现是个空region:
-
$ curl http://tidb-server-ip:10080/regions/434317
-
{
-
"start_key": "dIAAAAAAAC25X3I=",
-
"end_key": "dIAAAAAAAC25X3KAAAAAAz8WmQ==",
-
"start_key_hex": "748000000000002db95f72",
-
"end_key_hex": "748000000000002db95f7280000000033f1699",
-
"region_id": 434317,
-
"frames": null
-
}
问题已经定位,下面是如何解决了
问题解决
(1)使用pd-ctl,看看是否能让434317选出leader,或者通过添加peer,删除peer等方式解决问题。
执行尝试如下
-
// 把 Region 434317 的 leader 调度到 store 4
-
$tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add transfer-leader 434317 4
-
Failed! [500] "cannot build operator for region with no leader"
-
-
// 在 store 1094772 上新增 Region 434317 的副本
-
$tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add add-peer 434317 1094772
-
Failed! [500] "cannot build operator for region with no leader"
-
-
// 移除要下线 store 5 上的 Region 434317 的副本
-
$ tiup ctl:v5.2.1 pd -u http://pd-ip:2379 operator add remove-peer 434317 5
-
Failed! [500] "cannot build operator for region with no leader"
发现通过pd-ctl折腾的这条路走不通,因为要想实现上述操作,需要在region有leader的情况下才能操作。
(2)那我使用pd-ctl去把这个store delete如何?
-
tiup ctl:v5.2.1 pd -u http://pd-ip:2379 store delete 5
-
Success!
看到Sucess很激动,但是pd-ctl store一看,store 5还是在记录里面。发现这一招也不管用。
(3)tiup scale-in --force强制/暴力下线该tikv如何?
tiup cluster scale-in dsp_report -N 10.203.93.36:20160 --force
执行完毕,tiup里面确实没了。虽然说眼不见心不烦,但是pd-ctl store查看tikv信息还是有,崩溃!
(4)最后只能祭出tikv-ctl工具,来删除这个region,因为我上文提到了这个region本是空reigon,删除也不影响业务。具体tikv-ctl的使用和介绍就不详细说明了,可以参见我之前的公众号文章:TiDB集群恢复之TiKV集群不可用
./tikv-ctl --db /data/deploy/data/db tombstone -r 434317 --force
这么操作后,整个世界安静了,我的“强迫症”也得到满足,这个region终于“干净”了。
PS:其他人遇到类似的问题,该排查方案可以参考;也可以先停止下线操作,先升级到高阶版本后再尝试缩容的,这里告诉大家一个小妙招:我如何收回正在执行的scale-in呢?看下面:
curl -X POST http://${pd_ip}:2379/pd/api/v1/store/${store_id}/state?state=Up
store的状态转换
最后这个小结讲讲Store状态,TiKV Store 的状态具体分为 Up,Disconnect,Offline,Down,Tombstone。各状态的关系如下:
Up:表示当前的 TiKV Store 处于提供服务的状态。
Disconnect:当 PD 和 TiKV Store 的心跳信息丢失超过 20 秒后,该 Store 的状态会变为 Disconnect 状态,当时间超过 max-store-down-time 指定的时间后,该 Store 会变为 Down 状态。
Down:表示该 TiKV Store 与集群失去连接的时间已经超过了 max-store-down-time 指定的时间,默认 30 分钟。超过该时间后,对应的 Store 会变为 Down,并且开始在存活的 Store 上补足各个 Region 的副本。
Offline:当对某个 TiKV Store 通过 PD Control 进行手动下线操作,该 Store 会变为 Offline 状态。该状态只是 Store 下线的中间状态,处于该状态的 Store 会将其上的所有 Region 搬离至其它满足搬迁条件的 Up 状态 Store。当该 Store 的 leadercount 和 regioncount (在 PD Control 中获取) 均显示为 0 后,该 Store 会由 Offline 状态变为 Tombstone 状态。在 Offline 状态下,禁止关闭该 Store 服务以及其所在的物理服务器。下线过程中,如果集群里不存在满足搬迁条件的其它目标 Store(例如没有足够的 Store 能够继续满足集群的副本数量要求),该 Store 将一直处于 Offline 状态。
Tombstone:表示该 TiKV Store 已处于完全下线状态,可以使用 remove-tombstone 接口安全地清理该状态的 TiKV。
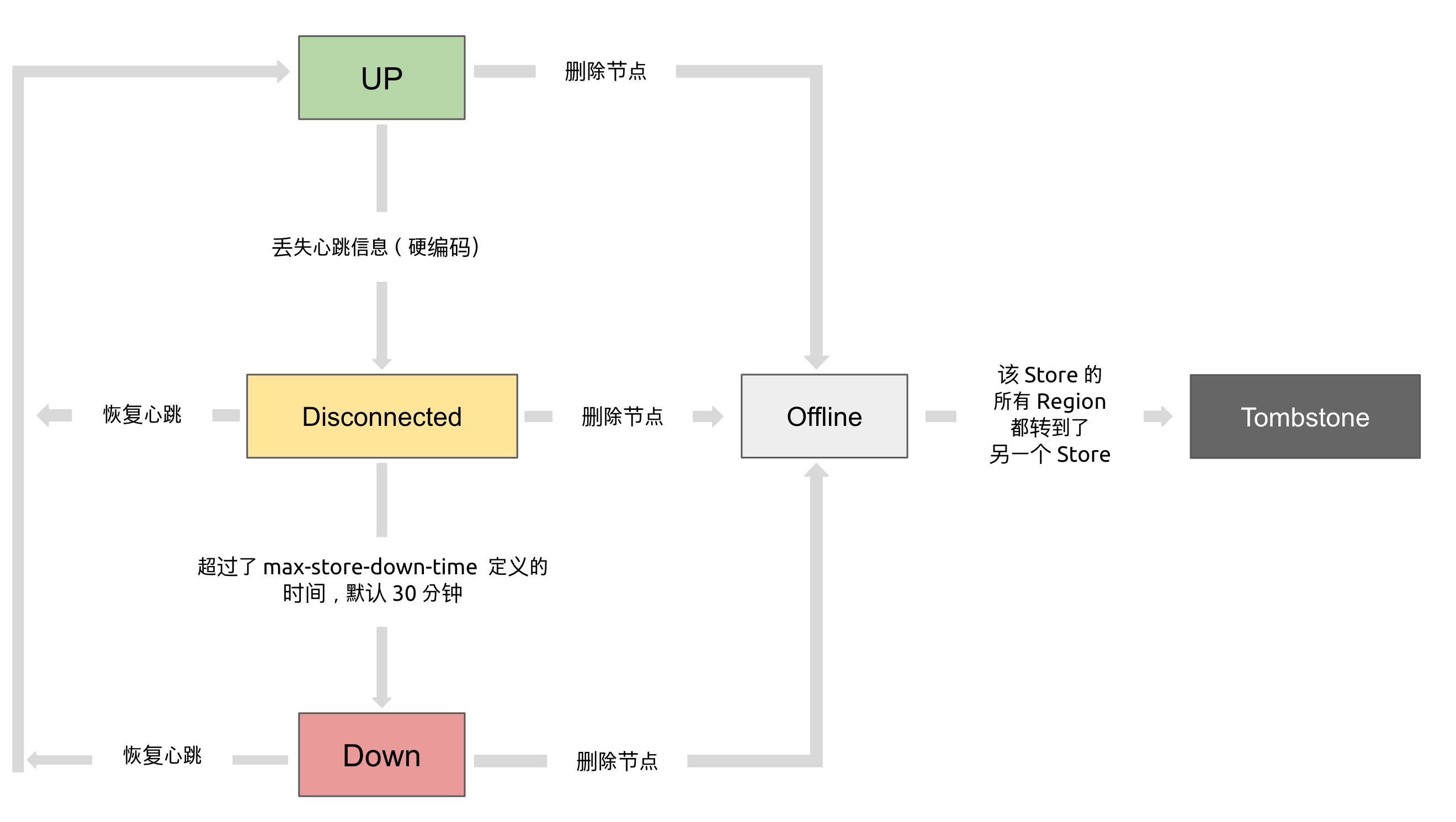
本小节来自官网:https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling#%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86
本人作者:@代晓磊_360
发表时间:2022/4/25 原文链接:https://tidb.net/blog/ec7009ac
[转帖]TiKV 缩容不掉如何解决?的更多相关文章
- Mycat节点扩缩容及高可用集群方案
数据迁移与扩容实践: 工具目前从 mycat1.6,准备工作:1.mycat 所在环境安装 mysql 客户端程序. 2.mycat 的 lib 目录下添加 mysql 的 jdbc 驱动包. 3.对 ...
- docker微服务部署之:七、Rancher进行微服务扩容和缩容
docker微服务部署之:六.Rancher管理部署微服务 Rancher有两个特色用起来很方便,那就是扩容和缩容. 一.扩容前的准备工作 为了能直观的查看效果,需要修改下demo_article项目 ...
- Knative 基本功能深入剖析:Knative Serving 自动扩缩容 Autoscaler
Knative Serving 默认情况下,提供了开箱即用的快速.基于请求的自动扩缩容功能 - Knative Pod Autoscaler(KPA).下面带你体验如何在 Knative 中玩转 Au ...
- 基于Ambari的WebUI实现服务缩容
基于Ambari的WebUI实现服务缩容 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.实现服务的扩容 1>.进入到主机的管理界面 2>.查看主机的信息概览 3&g ...
- 如何根据不同业务场景调节 HPA 扩缩容灵敏度
背景 在 K8s 1.18 之前,HPA 扩容是无法调整灵敏度的: 对于缩容,由 kube-controller-manager 的 --horizontal-pod-autoscaler-downs ...
- kubernetes中有状态应用的优雅缩容
将有状态的应用程序部署到Kubernetes是棘手的. StatefulSet使它变得容易得多,但是它们仍然不能解决所有问题.最大的挑战之一是如何缩小StatefulSet而不将数据留在断开连接的Pe ...
- 怎么做 HDFS 的原地平滑缩容?
背景 当数据规模越来越大,存储成本也水涨船高.随着时间推移,数据热度分布往往呈 2⁄8 原则,即 80% 的访问集中在 20% 的数据上.对于那不经常访问的 80% 数据来说,使用多个 SSD 来存储 ...
- Redis Cluster 集群搭建与扩容、缩容
说明:仍然是伪集群,所有的Redis节点,都在一个服务器上,采用不同配置文件,不同端口的形式实现 前提:已经安装好了Redis,本文的redis的版本是redis-6.2.3 Redis的下载.安装参 ...
- Kubernetes 监控:Prometheus Adpater =》自定义指标扩缩容
使用 Kubernetes 进行容器编排的主要优点之一是,它可以非常轻松地对我们的应用程序进行水平扩展.Pod 水平自动缩放(HPA)可以根据 CPU 和内存使用量来扩展应用,前面讲解的 HPA 章节 ...
- 三十三、HPA实现自动扩缩容
通过HPA实现业务应用的动态扩缩容 HPA控制器介绍 当系统资源过高的时候,我们可以使用如下命令来实现 Pod 的扩缩容功能 $ kubectl -n luffy scale deployment m ...
随机推荐
- Pikachu漏洞靶场 Unsafe Filedownload(不安全的文件下载)
不安全的文件下载 概述 文件下载功能在很多web系统上都会出现,一般我们当点击下载链接,便会向后台发送一个下载请求,一般这个请求会包含一个需要下载的文件名称,后台在收到请求后会开始执行下载代码,将该文 ...
- Ubuntu20.04 安装shutter
1 sudo add-apt-repository ppa:linuxuprising/shutter 2 3 sudo apt install shutter 4 5 卸载 6 sudo apt-g ...
- 电商业务容器化遇瓶颈,公有云Docker镜像P2P加速很安全
当前,电商平台会采用基于Docker的容器技术来承载618大促期间的一些关键业务版块,包括最简单的商品图片展示.订单详情页面等等. 通过容器化改造,电商平台的每个业务版块解耦,可以独立开发.部署和上线 ...
- 华为API战略:规范、组织和流程驱动企业大循环
摘要:构建一套完善的API规范流程体系变得至关重要,用方法论驱动整个API变革,用API变革驱动共享经济模式,以共享模式反推数字化转型. 本文分享自华为云社区<API战略--华为在数字化浪潮下的 ...
- 超详细的jQuery的 DOM操作,一篇就足够!
摘要:今天来和大家分享有关jQuery框架中DOM操作的相关技术,又是一个堪称DOM"全家桶"系列的讲解,建议收藏关注认真学习! 本文分享自华为云社区<[JQuery框架]超 ...
- 顶会VLDB‘22论文解读:CAE-ENSEMBLE算法
摘要:针对时间序列离群点检测问题,提出了基于CNN-AutoEncoder和集成学习的CAE-ENSEMBLE深度神经网络算法,并通过大量的实验证明CAE-ENSEMBLE算法能有效提高时间序列离群点 ...
- 火山引擎数智平台的这款产品,正在帮助 APP 提升用户活跃度
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 你有没有关注过 APP 给你推送的消息? 出于提升用户活跃度的考虑,APP 会定期在应用内面向用户进行内通推送,推 ...
- Sublime Ctrl+B 编译输出乱码
1.输入乱码如图 2.Preferences -> Browse Packages.. 3.加入 "env": { "PYTHONIOENCODING" ...
- Spring 学习笔记(4)依赖注入 DI
本篇文章主要对 Spring 框架中的核心功能之一依赖注入 (DI,Dependency Injection) 进行介绍,也是采用 理论+实战 的方式给大家阐述其中的原理以及明确需要注意的地方. 相关 ...
- Codeforces Round #727 (Div. 2) A~D题题解
比赛链接:Here 1539A. Contest Start 让我们找出哪些参与者会干扰参与者i.这些是数字在 \(i+1\) 和 \(i+min(t/x,n)\)之间的参与者.所以第一个最大值 \( ...