Flink 1.13,面向流批一体的运行时与 DataStream API 优化
简介: 在 1.13 中,针对流批一体的目标,Flink 优化了大规模作业调度以及批执行模式下网络 Shuffle 的性能,以及在 DataStream API 方面完善有限流作业的退出语义。
本文由社区志愿者苗文婷整理,内容来源自阿里巴巴技术专家高赟(云骞) 在 5 月 22 日北京站 Flink Meetup 分享的《面向流批一体的 Flink 运行时与 DataStream API 优化》。文章主要分为 4 个部分:
- 回顾 Flink 流批一体的设计
- 介绍针对运行时的优化点
- 介绍针对 DataStream API 的优化点
- 总结以及后续的一些规划。
1. 流批一体的 Flink
1.1 架构介绍
首先看下 Flink 流批一体的整体逻辑。Flink 在早期的时候,虽然是一个可以同时支持流处理和批处理的框架,但是它的流处理和批处理的实现,不管是在 API 层,还是在底下的 Shuffle、调度、算子层,都是单独的两套。这两套实现是完全独立的,没有特别紧密的关联。

在流批一体这一目标的引导下,Flink 现在已经对底层的算子、调度、Shuffle 进行了统一的抽象,以统一的方式向上支持 DataStream API 和 Table API 两套接口。DataStream API 是一种比较偏物理层的接口,Table API 是一种 Declearetive 的接口,这两套接口对流和批来说都是统一的。

1.2 优点
- 代码复用
基于 DataStream API 和 Table API,用户可以写同一套代码来同时处理历史的数据和实时的数据,例如数据回流的场景。
- 易于开发
统一的 Connector 和算子实现,减少开发和维护的成本。
- 易于学习
减少学习成本,避免学习两套相似接口。
- 易于维护
使用同一系统支持流作业和批作业,减少维护成本。
1.3 数据处理过程
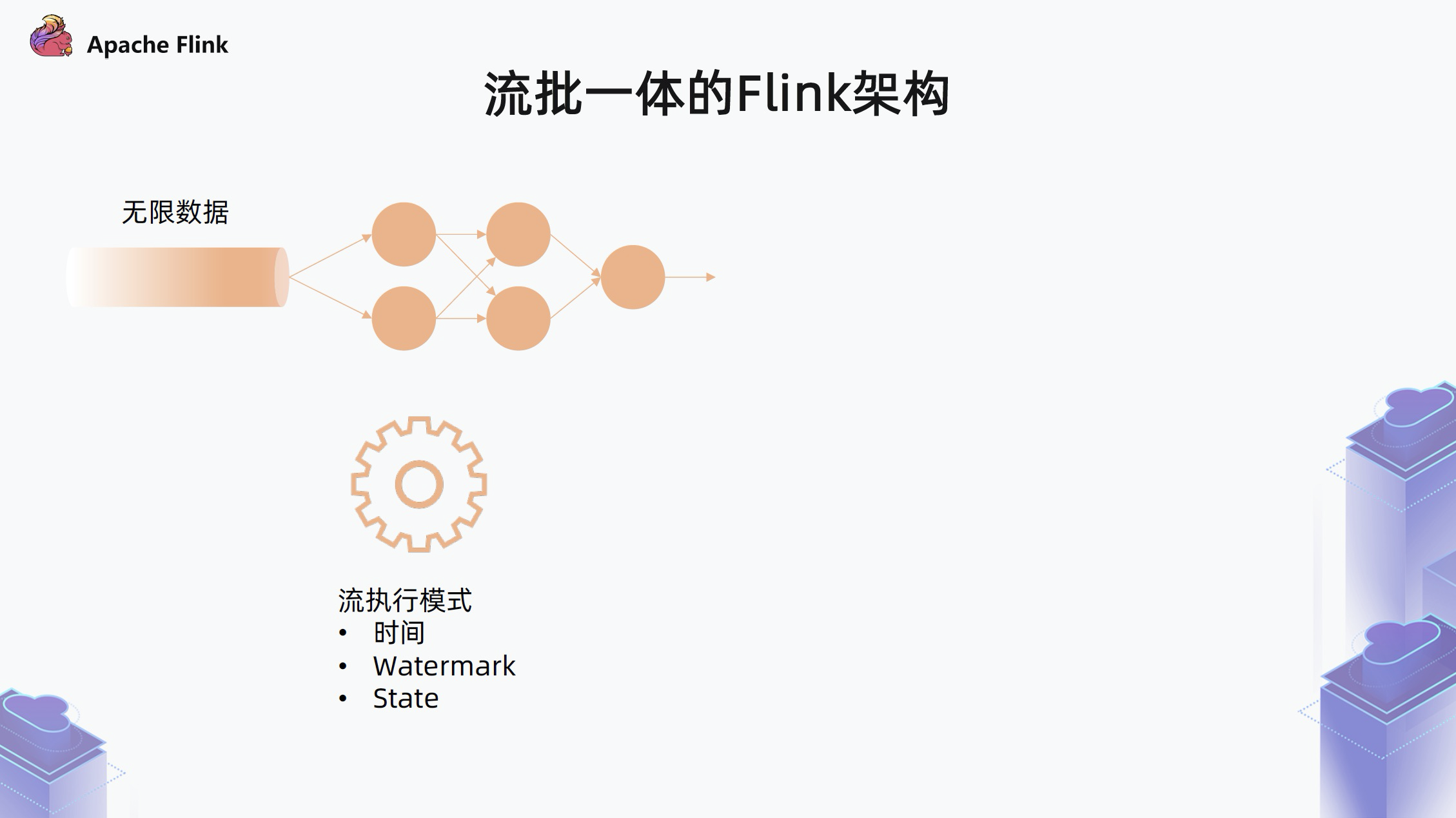
下面简单介绍 Flink 是怎么抽象流批一体的,Flink 把作业拆成了两种:
- 第一种类型的作业是处理无限数据的无限流的作业
这种作业就是我们平时所认知的流作业,对于这种作业,Flink 采用一个标准流的执行模式,需要考虑记录的时间,通过 Watermark 对齐的方式推进整个系统的时间以达到一些数据聚合和输出的目的,中间通过 State 来维护中间状态。
- 第二种类型的作业是处理有限数据集的作业
数据可能是保存在文件中,或者是以其他方式提前保留下来的一个有限数据集。此时可以把有限数据集看作是无限数据集的一个特例,所以它可以自然的跑在之前的流处理模式之上,无需经过代码修改,可以直接支持。
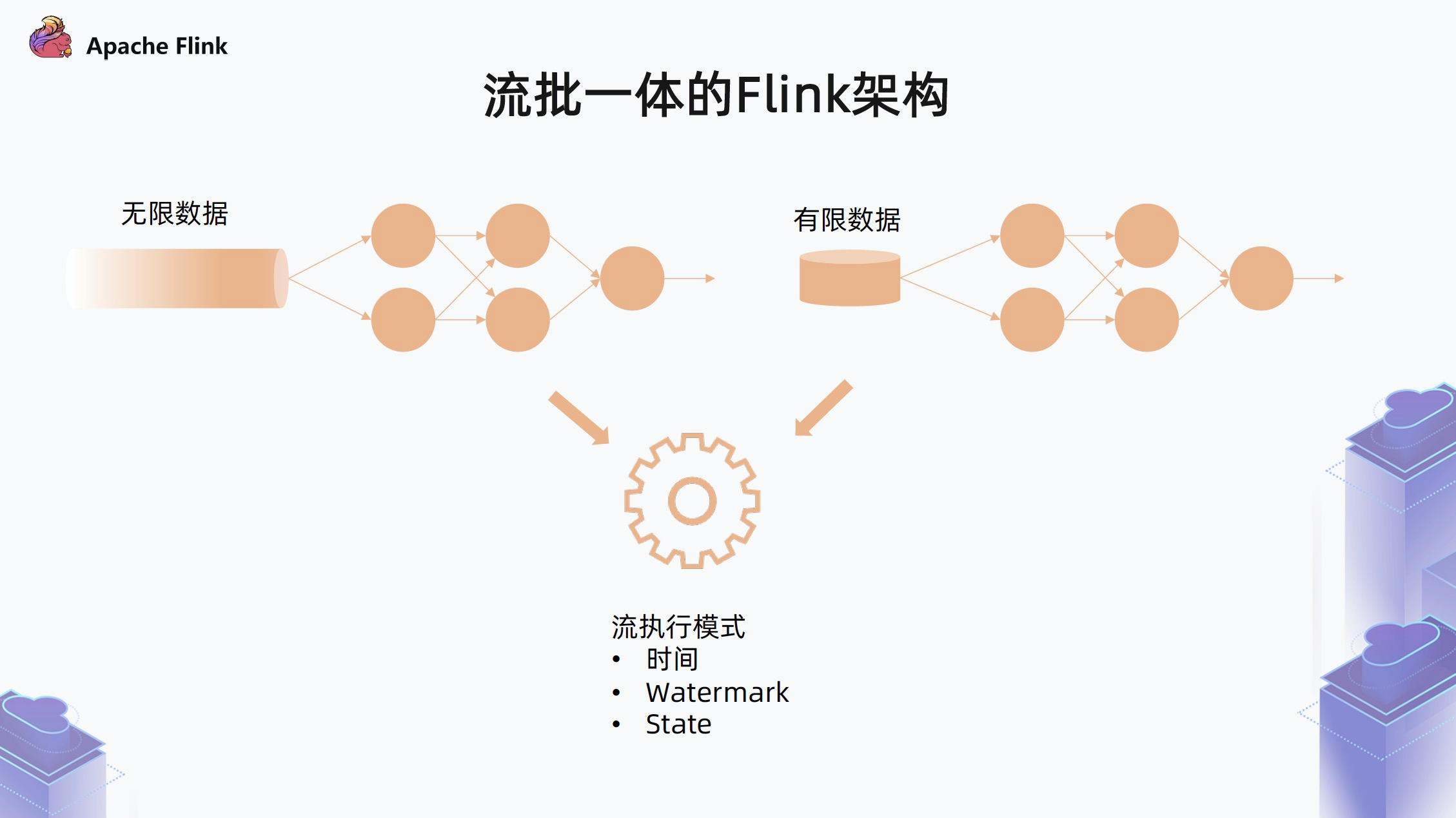
但这里可能会忽略掉有限数据集数据有限的特点,在接口上还需要处理更细粒度的时间、Watermark 等语义,可能会引入额外的复杂性。另外,在性能方面,因为是按流的方式处理,在一开始就需要把所有的任务拉起来,可能需要占用更多的资源,如果采用的是 RocksDB backend,相当于是一个大的 Hash 表,在 key 比较多的情况下,可能会有随机 IO 访问的问题。
但是在批执行模式下,可以通过排序的方式,用一种 IO 更加友好的方式来实现整个数据处理的流程。所以说,批处理模式在考虑数据有限的前提下,在调度、Shuffle、算子的实现上都给我们提供了更大的选择空间。
最后,针对有限数据流,不管是采用哪种处理模式,我们希望最终的处理结果都是一致的。

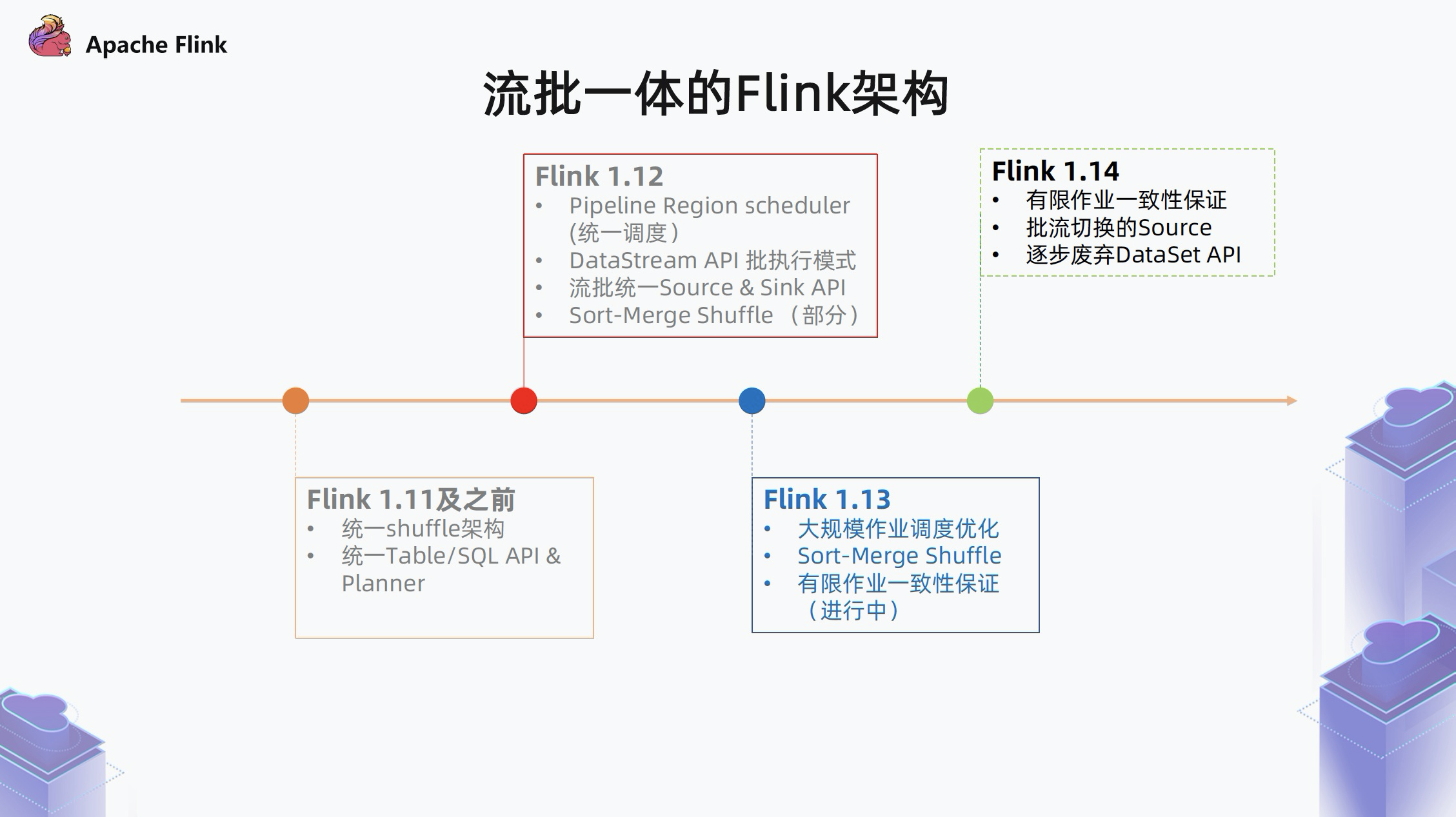
1.4 近期演进
Flink 在最近的几个版本中,在 API 和实现层都朝着流批一体的目标做了很多的努力。
- 在 Flink 1.11 及之前:
Flink 统一了 Table/SQL API,并引入了统一的 blink planner,blink planner 对流和批都会翻译到 DataStream 算子之上。此外,对流和批还引入了统一的 shuffle 架构。
- 在 Flink 1.12 中:
针对批的 shuffle 引入了一种新的基于 Sort-Merge 的 shuffle 模式,相对于之前 Flink 内置的 Hash shuffle,性能会有很大提升。在调度方面,Flink 引入了一种基于 Pipeline Region 的流批一体的调度器。
- 在 Flink 1.13 中:
完善了 Sort-Merge Shuffle,并对 Pipeline Region scheduler 在大规模作业下进行了性能优化。另外,前面提到过,对于有限流的两种执行模式,我们预期它的执行结果应该是一致的。但是现在 Flink 在作业执行结束的时候还有一些问题,导致它并不能完全达到一致。
所以在 1.13 中,还有一部分的工作是针对有限数据集作业,怎么在流批,尤其是在流的模式下,使它的结果和预期的结果保持一致。
- 未来的 Flink 1.14:
需要继续完成有限作业一致性保证、批流切换 Source、逐步废弃 DataSet API 等工作。
2. 运行时优化
2.1 大规模作业调度优化
2.1.1 边的时间复杂度问题
Flink 提交作业时会生成一个作业的 DAG 图,由多个顶点组成,顶点对应着我们实际的处理节点,如 Map。每个处理节点都会有并发度,此前 Flink 的实现里,当我们把作业提交到 JM 之后,JM 会对作业展开,生成一个 Execution Graph。
如下图,作业有两个节点,并发度分别为 2 和 3。在 JM 中实际维护的数据结构里,会分别维护 2 个 task 和 3 个 task,并由 6 条执行边组成,Flink 基于此数据结构来维护整个作业的拓扑信息。在这个拓扑信息的基础上,Flink 可以单独维护每个 task 的状态,当任务挂了之后以识别需要拉起的 task。
如果以这种 all-to-all 的通信,也就是每两个上下游 task 之间都有边的情况下,上游并发 下游并发,将出现 O(N^2) 的数据结构。这种情况下,内存的占用是非常惊人的,如果是 10k 10k 的边,JM 的内存占用将达到 4.18G。此外,作业很多的计算复杂度都是和边的数量相关的,此时的空间复杂度为 O(N^2) 或 O(N^3),如果是 10k * 10k 的边,作业初次调度时间将达到 62s。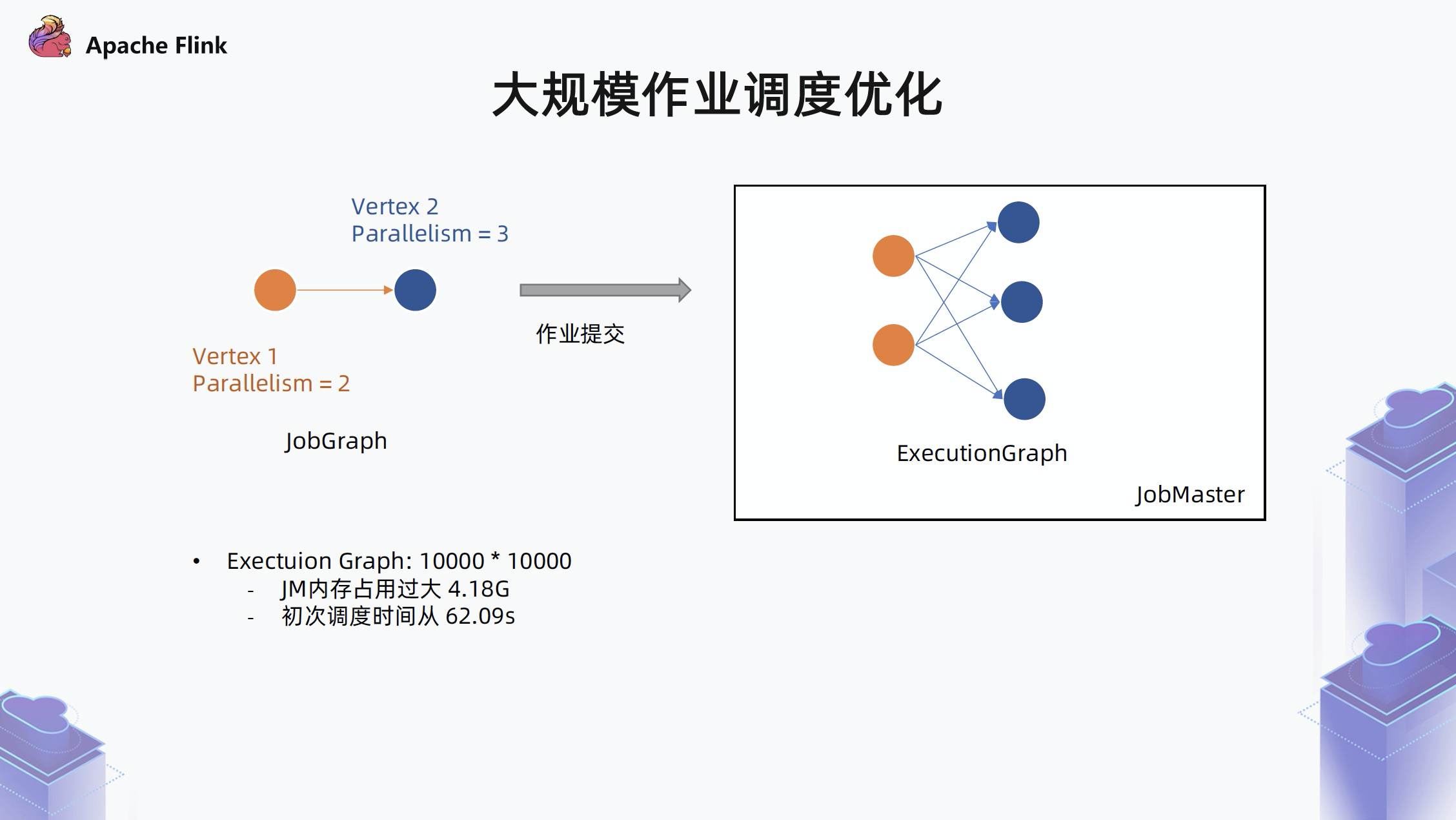
可以看出,除了初始调度之外,对于批作业来说,有可能是上游执行完之后继续执行下游,中间的调度复杂度都是 O(N^2) 或 O(N^3),这样就会导致很大的性能开销。另外,内存占用很大的话,GC 的性能也不会特别好。
2.1.2 Execution Graph 的对称性
针对 Flink 在大规模作业下内存和性能方面存在的一些问题,经过一些深入分析,可以看出上述例子中上下游节点之间是有一定对称性的。
Flink 中 “边” 的类型可以分为两种:
- 一种是 Pointwise 型,上游和下游是一一对应的,或者上游一个对应下游几个,不是全部相连的,这种情况下,边的数量基本是线性的 O(N), 和算子数在同一个量级。
- 另一种是 All-to-all 型,上游每一个 task 都要和下游的每一个 task 相连,在这种情况下可以看出,每一个上游的 task 产生的数据集都要被下游所有的 task 消费,实际上是一个对称的关系。只要记住上游的数据集会被下游的所有 task 来消费,就不用再单独存中间的边了。
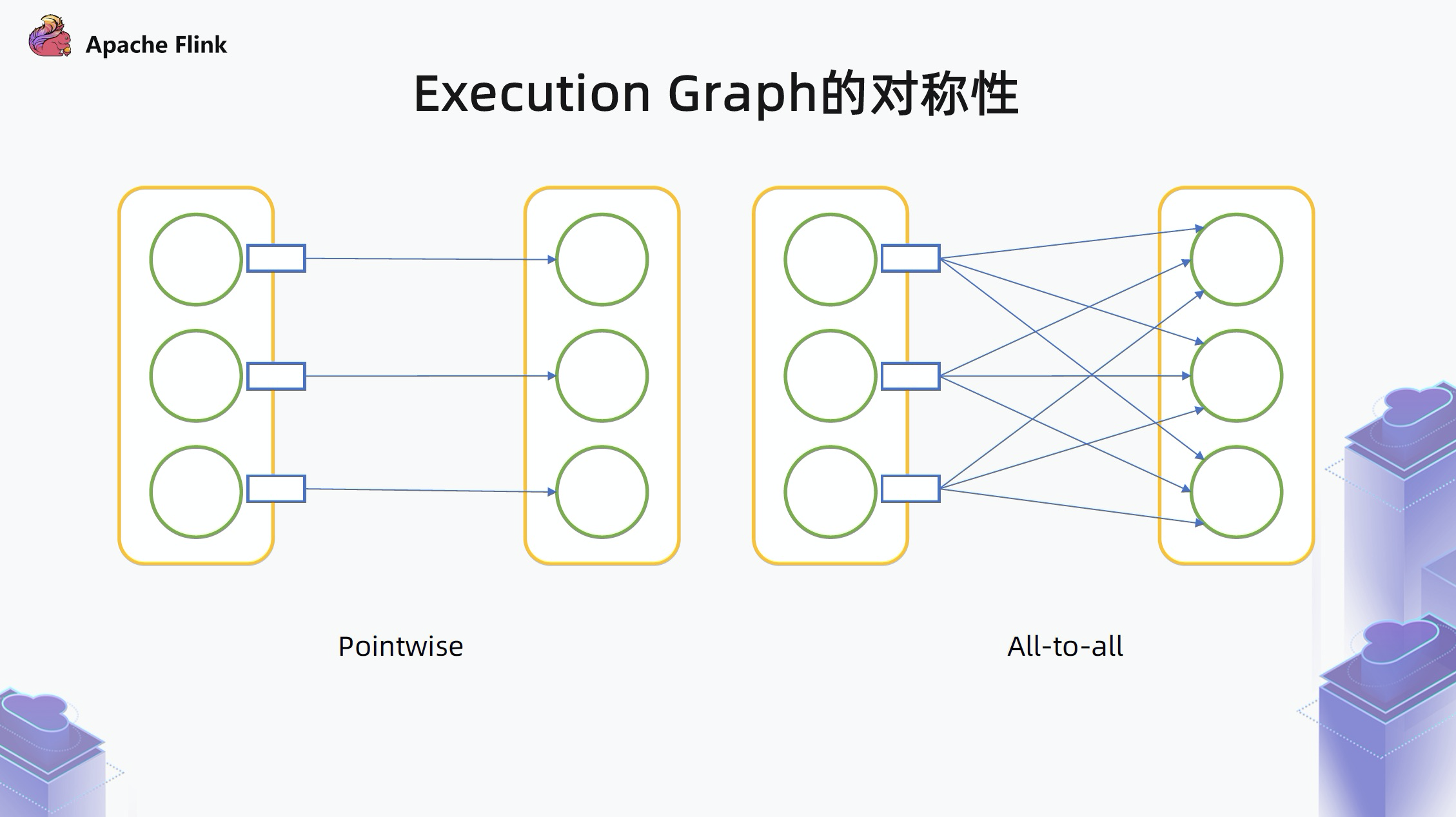
所以,Flink 在 1.13 中对上游的数据集和下游的节点分别引入了 ResultPartitionGroup 和 VertexGroup 的概念。尤其是对于 All-to-all 的边,因为上下游之间是对称的,可以把所有上游产生的数据集放到一个 Group 里,把下游所有的节点也放到一个 Group 里,在实际维护时不需要存中间的边的关系,只需要知道上游的哪个数据集是被下游的哪个 Group 消费,或下游的哪个顶点是消费上游哪个 Group 的数据集。
通过这种方式,减少了内存的占用。

另外,在实际做一些调度相关计算的时候,比如在批处理里,假如所有的边都是 blocking 边的情况下,每个节点都属于一个单独的 region。之前计算 region 之间的上下游关系,对上游的每个顶点,都需要遍历其下游的所有顶点,所以是一个 O(N^2) 的操作。
而引入 ConsumerGroup 之后,就会变成一个 O(N) 的线性操作。

2.1.3 优化结果
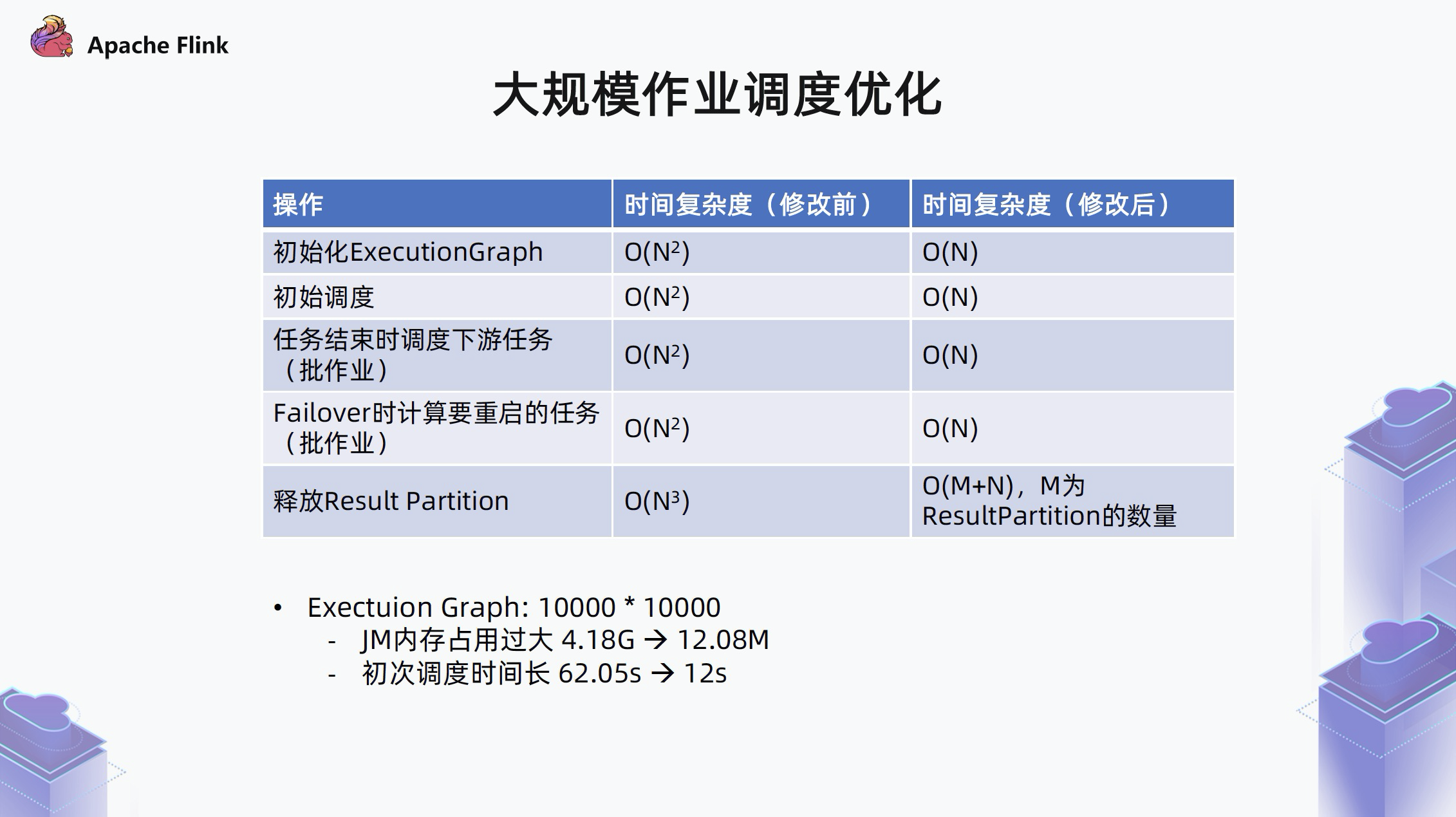
经过以上数据结构的优化,在 10k * 10k 边的情况下,可以将 JM 内存占用从 4.18G 缩小到 12.08M, 初次调度时间长从 62s 缩减到 12s。这个优化其实是非常显著的,对用户来说,只要升级到 Flink 1.13 就可以获得收益,不需要做任何额外的配置。
2.2 Sort-Merge Shuffle
另外一个优化,是针对批的作业在数据 shuffle 方面做的优化。一般情况下,批的作业是在上游跑完之后,会先把结果写到一个中间文件里,然后下游再从中间文件里拉取数据进行处理。
这种方式的好处就是可以节省资源,不需要上游和下游同时起来,在失败的情况下,也不需要从头执行。这是批处理的常用执行方式。
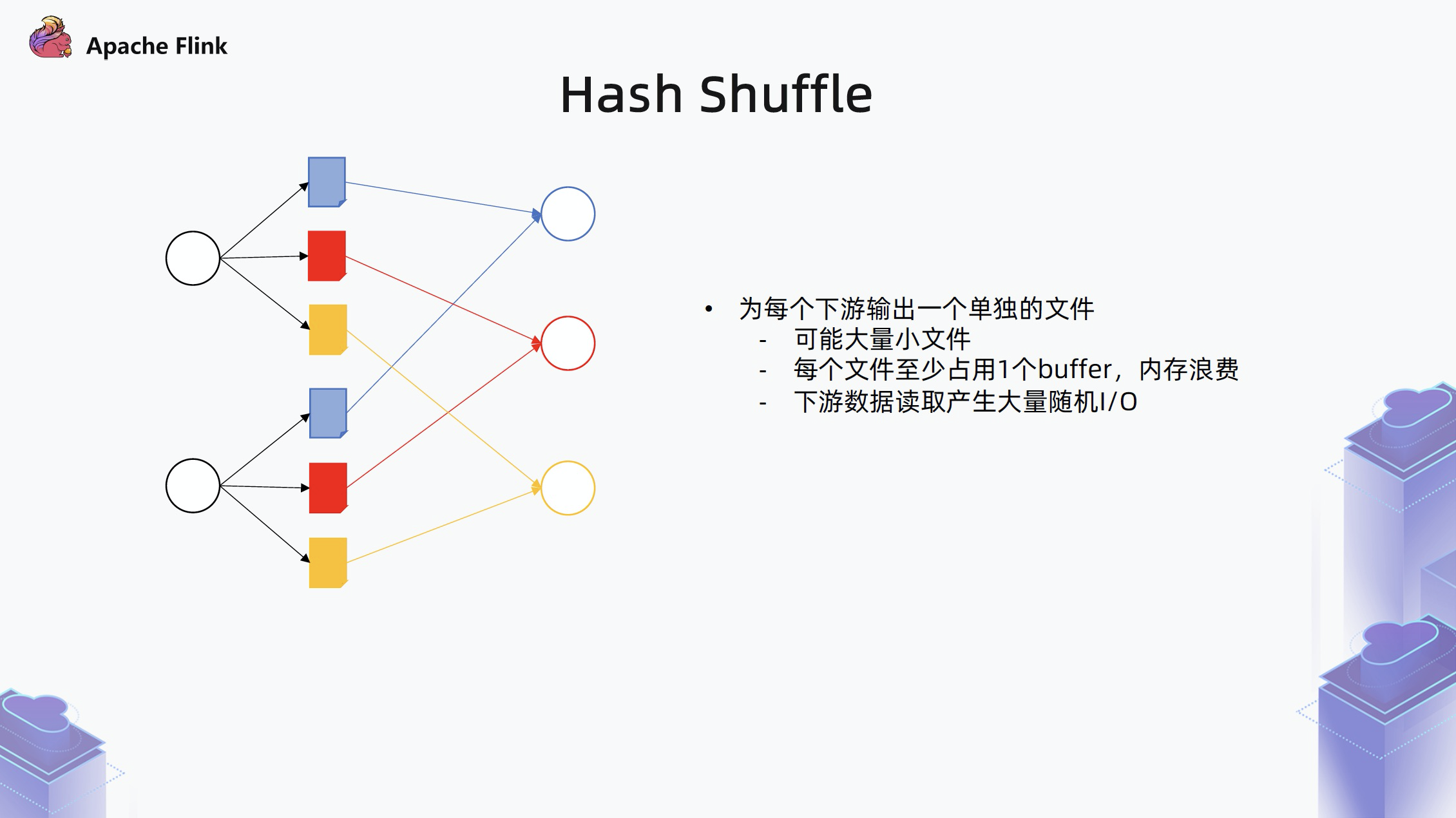
2.2.1 Hash Shuffle
那么,shuffle 过程中,中间结果是如何保存到中间文件,下游再拉取的?
之前 Flink 引入的是 Hash shuffle,再以 All-to-all 的边举例,上游 task 产生的数据集,会给下游的每个 task 写一个单独的文件,这样系统可能会产生大量的小文件。并且不管是使用文件 IO 还是 mmap 的方式,写每个文件都至少使用一块缓冲区,会造成内存浪费。下游 task 随机读取的上游数据文件,也会产生大量随机 IO。
所以,之前 Flink 的 Hash shuffle 应用在批处理中,只能在规模比较小或者在用 SSD 的时候,在生产上才能比较 work。在规模比较大或者 SATA 盘上是有较大的问题的。
2.2.2 Sort Shuffle
所以,在 Flink 1.12 和 Flink 1.13 中,经过两个版本,引入了一种新的基于 Sort Merge 的 shuffle。这个 Sort 并不是指对数据进行 Sort,而是对下游所写的 task 目标进行 Sort。
大致的原理是,上游在输出数据时,会使用一个固定大小的缓冲区,避免缓冲区的大小随着规模的增大而增大,所有的数据都写到缓冲区里,当缓冲区满时,会做一次排序并写到一个单独文件里,后面的数据还是基于此缓存区继续写,续写的一段会拼到原来的文件后面。最后单个的上游任务会产生一个中间文件,由很多段组成,每个段都是有序的结构。

和其他的批处理的框架不太一样,这边并不是基于普通的外排序。一般的外排序是指会把这些段再做一次单独的 merge,形成一个整体有序的文件,这样下游来读的时候会有更好的 IO 连续性,防止每一段每一个 task 要读取的数据段都很小。但是,这种 merge 本身也是要消耗大量的 IO 资源的,有可能 merge 的时间带来的开销会远超过下游顺序读带来的收益。
所以,这里采用了另外一种方式:在下游来请求数据的时候,比如下图中的 3 个下游都要来读上游的中间文件,会有一个调度器对下游请求要读取的文件位置做一个排序,通过在上层增加 IO 调度的方式,来实现整个文件 IO 读取的连续性,防止在 SATA 盘上产生大量的随机 IO。
在 SATA 盘上,相对于 Hash shuffle,Sort shuffle 的 IO 性能可以提高 2~8 倍。通过 Sort shuffle,使得 Flink 批处理基本达到了生产可用的状态,在 SATA 盘上 IO 性能可以把磁盘打到 100 多M,而 SATA 盘最高也就能达到 200M 的读写速度。

为了保持兼容性,Sort shuffle 并不是默认启用的,用户可以控制下游并发达到多少来启用 Sort Merge Shuffle。并且可以通过启用压缩来进一步提高批处理的性能。Sort Merge shuffle 并没有额外占用内存,现在占用的上游读写的缓存区,是从 framework.off-heap 中抽出的一块。

3. DataStream API 优化
3.1 2PC & 端到端一致性
为了保证端到端的一致性,对于 Flink 流作业来说,是通过两阶段提交的机制来实现的,结合了 Flink 的 checkpoint、failover 机制和外部系统的一些特性。
大概的逻辑是,当我想做端到端的一致性,比如读取 Kafka 再写到 Kafka,在正常处理时会把数据先写到一个 Kafka 的事务里,当做 checkpoint 时进行 preCommit,这样数据就不会再丢了。
如果 checkpoint 成功的话,会进行一次正式的 commit。这样就保证了外部系统的事务和 Flink 内部的 failover 是一致的,比如 Flink 发生了 failover 需要回滚到上一个 checkpoint , 外部系统中跟这一部分对应的事务也会被 abort 掉,如果 checkpoint 成功了,外部事务的 commit 也会成功。
Flink 端到端的一致性依赖于 checkpoint 机制。但是,在遇到有限流时,就会有一些问题:
- 具有有限流的作业,task 结束之后,Flink 是不支持做 checkpoint 的,比如流批混合的作业,其中有一部分会结束,之后 Flink 就没办法再做 checkpoint,数据也就不会再提交了。
- 在有限流数据结束时,因为 checkpoint 是定时执行的,不能保证最后一个 checkpoint 一定能在处理完所有数据后执行,可能导致最后一部分数据无法提交。
以上就会导致在流模式下,有限流作业流/批执行模式结果不一致。

3.2 支持部分 Task 结束后的 Checkpoint (进行中)
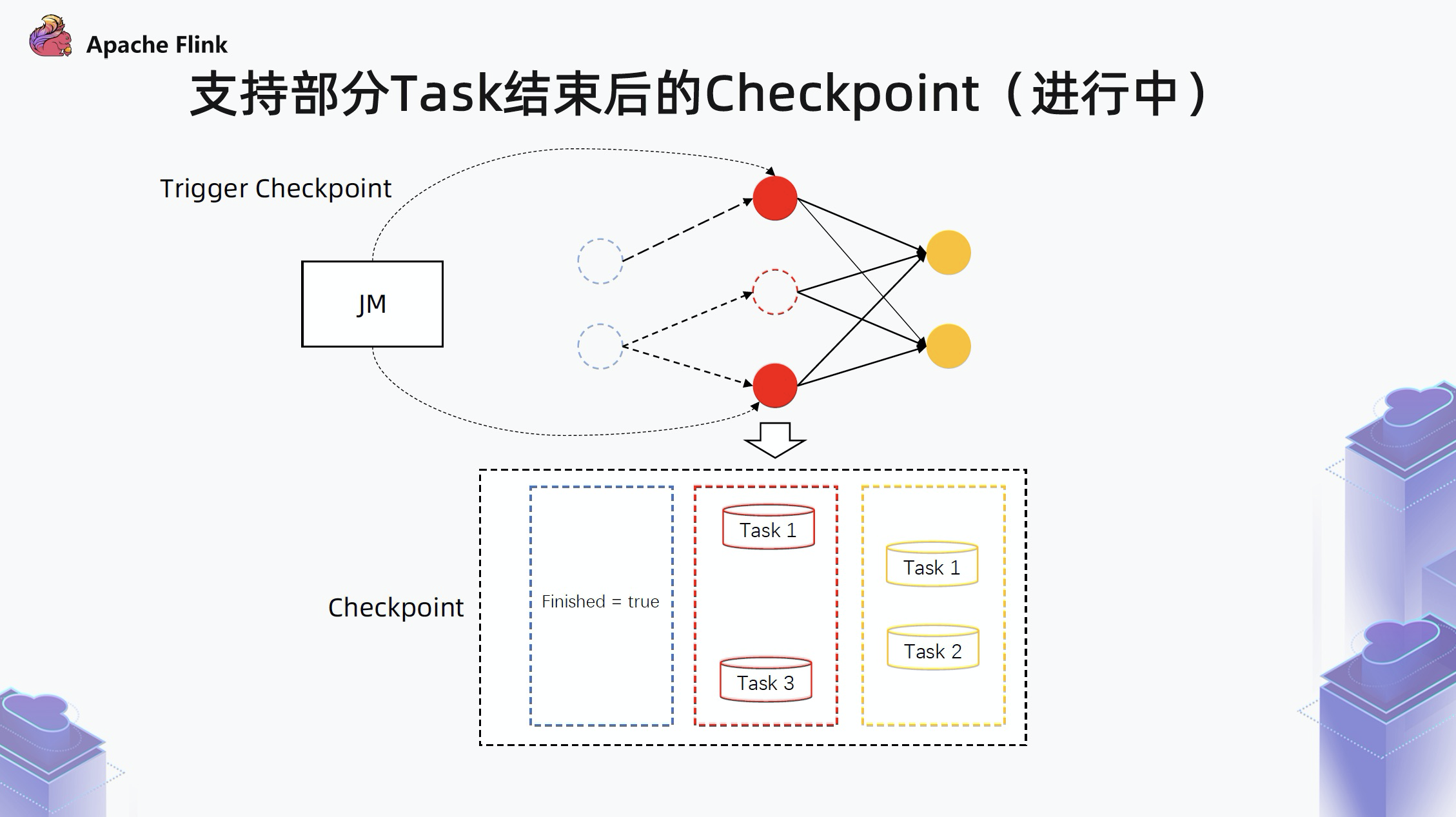
从 Flink 1.13 开始,支持在一部分 task 结束之后,也能做 checkpoint。checkpoint 实际上是维护了每个算子的所有 task 的状态列表。

在有一部分 task 结束之后,如下图的虚线部分。Flink 会把结束的 task 分为两种:
- 如果一个算子的所有 subtask 都已经结束了,就会为这个算子存一个 finished 标记。
- 如果一个算子只有部分 task 结束,就只存储未结束的 task 状态。
基于这个 checkpoint ,当 failover 之后还是会拉起所有算子,如果识别到算子的上一次执行已经结束,即 finsihed = true,就会跳过这个算子的执行。尤其是针对 Source 算子来说,如果已经结束,后面就不会再重新执行发送数据了。通过上述方式就可以保证整个状态的一致性,即使有一部分 task 结束,还是照样走 checkpoint。
Flink 也重新整理了结束语义。现在 Flink 作业结束有几种可能:
- 作业结束:数据是有限的,有限流作业正常结束;
- stop-with-savepoint ,采一个 savepoint 结束;
- stop-with-savepoint --drain ,采一个 savepoint 结束,并会将 watermark 推进到正无穷大。
之前这边是两种不同的实现逻辑,并且都有最后一部分数据无法提交的问题。
- 对作业结束和 stop-with-savepoint --drain 两种语义,预期作业是不会再重启的,都会对算子调 endOfInput() , 通知算子通过一套统一的方式做 checkpoint 。
- 对 stop-with-savepoint 语义,预期作业是会继续 savepoint 重启的,此时就不会对算子调 endOfInput()。后续会再做一个 checkpoint , 这样对于一定会结束并不再重启的作业,可以保证最后一部分数据一定可以被提交到外部系统中。

4. 总结
在 Flink 的整个目标里,其中有一点是期望做一个对有限数据集和无限数据集高效处理的统一平台。目前基本上已经有了一个初步的雏形,不管是在 API 方面,还是在 runtime 方面。下面来举个例子说明流批一体的好处。
针对用户的回流作业,平时是处理无限流的作业,如果某一天想改个逻辑,用 stop-with-savepoint 方式把流停掉,但是这个变更逻辑还需要追回到前两个月之内的数据来保证结果的一致性。此时,就可以启一个批的作业:作业不加修改,跑到提前缓存下来的输入数据上,用批的模式可以尽快地订正前两个月的数据。另外,基于新的逻辑,使用前面保存的 savepoint,可以重启一个新的流作业。
可以看出,在上述整个流程中,如果是之前流批分开的情况,是需要单独开发作业进行数据订正的。但在流批一体的情况下,可以基于流的作业自然的进行数据订正,不需要用户再做额外的开发。
在 Flink 后续的版本中,还会进一步考虑更多流批结合的场景,比如用户先做一个批的处理,对状态进行初始化之后,再切到无限流上的场景。当然,在流和批单独的功能上,也会做进一步的优化和完善,使得 Flink 在流批方面都是具有竞争力的计算框架。

原文链接
本文为阿里云原创内容,未经允许不得转载。
Flink 1.13,面向流批一体的运行时与 DataStream API 优化的更多相关文章
- 官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行!
官宣 | Apache Flink 1.12.0 正式发布,流批一体真正统一运行! 原创 Apache 博客 [Flink 中文社区](javascript:void(0) 翻译 | 付典 Revie ...
- 带你玩转Flink流批一体分布式实时处理引擎
摘要:Apache Flink是为分布式.高性能的流处理应用程序打造的开源流处理框架. 本文分享自华为云社区<[云驻共创]手把手教你玩转Flink流批一体分布式实时处理引擎>,作者: 萌兔 ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
- Arctic 基于 Hive 的流批一体实践
背景 随着大数据业务的发展,基于 Hive 的数仓体系逐渐难以满足日益增长的业务需求,一方面已有很大体量的用户,但是在实时性,功能性上严重缺失:另一方面 Hudi,Iceberg 这类系统在事务性,快 ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- Apache Flink 1.12.0 正式发布,DataSet API 将被弃用,真正的流批一体
Apache Flink 1.12.0 正式发布 Apache Flink 社区很荣幸地宣布 Flink 1.12.0 版本正式发布!近 300 位贡献者参与了 Flink 1.12.0 的开发,提交 ...
- Flink Program Guide (7) -- 容错 Fault Tolerance(DataStream API编程指导 -- For Java)
false false false false EN-US ZH-CN X-NONE /* Style Definitions */ table.MsoNormalTable {mso-style-n ...
- Flink 另外一个分布式流式和批量数据处理的开源平台
Apache Flink是一个分布式流式和批量数据处理的开源平台. Flink的核心是一个流式数据流动引擎,它为数据流上面的分布式计算提供数据分发.通讯.容错.Flink包括几个使用 Flink引擎创 ...
- Flink Application Development DataStream API Execution Mode (Batch/Streaming)- Flink应用程序开发DataStream API执行模式(批/流)
目录 什么时候可以/应该使用BATCH执行模式? 配置BATCH执行模式 执行行为 任务调度和网络随机shuffle 流执行模式 批处理执行模式 状态后端/状态 处理顺序 Event Time/水印( ...
- Java基础学习总结(13)——流IO
一.JAVA流式输入/输出原理 流是用来读写数据的,java有一个类叫File,它封装的是文件的文件名,只是内存里面的一个对象,真正的文件是在硬盘上的一块空间,在这个文件里面存放着各种各样的数据,我们 ...
随机推荐
- 29_SDL多线程与锁机制
目录 一.简介 二.代码实现: 2.1.声明 2.2.创建锁.消费者 2.3.销毁 2.4.实现生产者逻辑 2.5.实现销毁者逻辑 2.6.创建生产者 三.分装SDL锁机制 condmutex.h c ...
- 记录--为什么 export 导出一个字面量会报错,而使用 export default 就不会报错?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 核心 其实总的来说就是 export 导出的是变量的句柄(或者说符号绑定.近似于 C 语言里面的指针,C++里面的变量别名),而 expo ...
- C#的播放资源文件里的音频例子 - 开源研究系列文章
今天无聊,想起原来开发的待办列表TodoList里还缺个提醒声音,于是就添加了提供声音模块代码.然后想着记录一下,让更多的读者能够复用这个模块代码,于是就有了此博文.这个例子只是用于播放资源文件里的w ...
- Python 从MySQL数据库中把查询结果集写入到Excel
import xlwt # 引入pymysql包 import pymysql # 连接数据库并打开library数据库 sql="SELECT * FROM\ user1;" c ...
- python批量发邮箱
1.首先登录邮箱中开启服务 2.获取到授权码后复制下来,放入如下含授权码的引号中: 1 smtp_obj.login("**********@qq.com", "授权码& ...
- IPv4地址的结构体与网络字节序
IPv4地址的结构体 /* Fixed-size types, underlying types depend on word size and compiler. */ typedef signed ...
- 关于 ThreadLocal 你需要知道的几点
一.ThreadLocal是什么? 一个类对象类型,提供属线程本地变量,也就是同一个变量对不同线程保存了不同的值,但是和线程自身定义的自属变量不同. 通常以私有静态类型定义,用以保存特定线程特定状态属 ...
- #线段树#洛谷 2221 [HAOI2012]高速公路
题目 分析 首先把收费站之间化为点,那这样即是区间加和区间查询, 考虑求的应该是 \[\frac{\sum a[i]*(r-i+1)*(i-l+1)}{C(r-l+2,2)} \] 分子可以拆成 \[ ...
- Numpy线性计算
Numpy内置方法以及numpy.linalg模块可实现矩阵乘法.矩阵分解.矩阵行列式等线性代数的计算. In [1]: import numpy as np In [2]: x = np.arang ...
- Java处理关键字进行脱敏操作
1.通过表头获取需要处理的下标列 注:此处导出表格时对关键字进行脱敏处理 /** * . * 对表头进行过滤判断 * * @param headers 表头 * @return 对应的下标列及方法名 ...