PyFlink 开发环境利器:Zeppelin Notebook
简介: 在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中。
PyFlink 作为 Flink 的 Python 语言入口,其 Python 语言的确很简单易学,但是 PyFlink 的开发环境却不容易搭建,稍有不慎,PyFlink 环境就会乱掉,而且很难排查原因。今天给大家介绍一款能够帮你解决这些问题的 PyFlink 开发环境利器:Zeppelin Notebook。主要内容为:
- 准备工作
- 搭建 PyFlink 环境
- 总结与未来
也许你早就听说过 Zeppelin,但是之前的文章都偏重讲述如何在 Zeppelin 里开发 Flink SQL,今天则来介绍下如何在 Zeppelin 里高效的开发 PyFlink Job,特别是解决 PyFlink 的环境问题。
一句来总结这篇文章的主题,就是在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中,你无需手动在集群上去安装任何 PyFlink 的包,并且你可以在一个 Yarn 集群里同时使用互相隔离的多个版本的 PyFlink。最后你能看到的效果就是这样:
1. 能够在 PyFlink 客户端使用第三方 Python 库,比如 matplotlib:
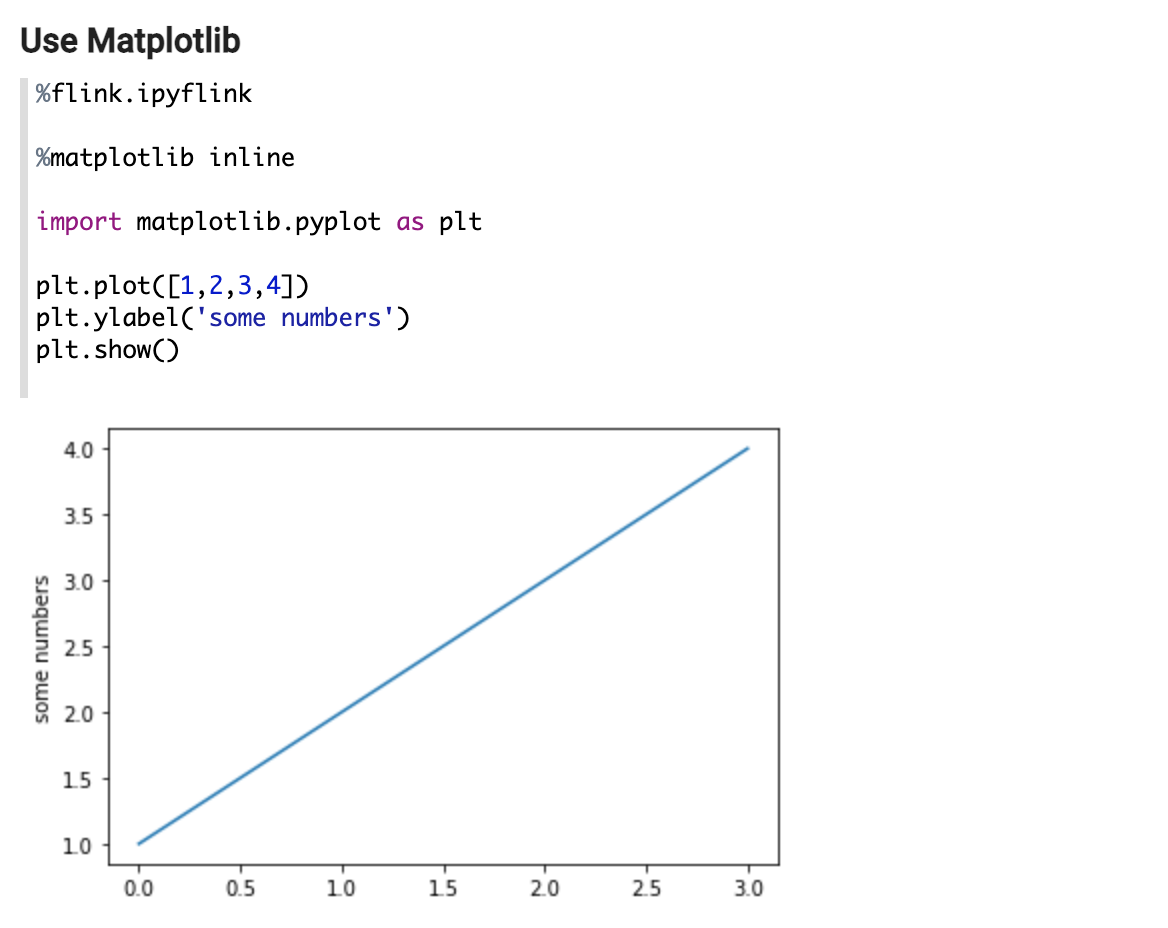
2. 可以在 PyFlink UDF 里使用第三方 Python 库,如:
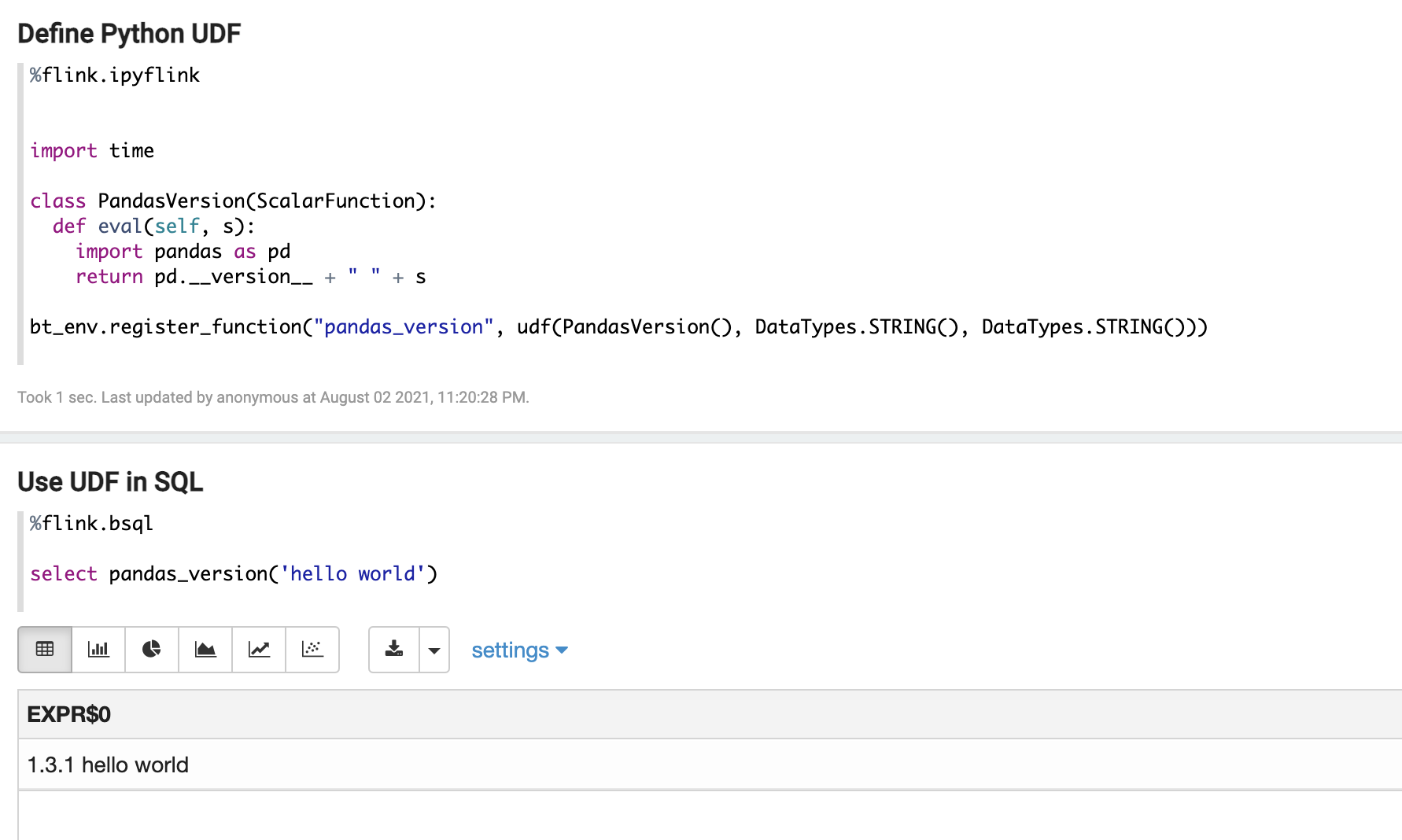
接下来看看如何来实现。
一、准备工作
Step 1.
准备好最新版本的 Zeppelin 的搭建,这个就不在这边展开了,如果有问题可以加入 Flink on Zeppelin 钉钉群 (34517043) 咨询。另外需要注意的是,Zeppelin 部署集群需要是 Linux,如果是 Mac 的话,会导致在 Mac 机器上打的 Conda 环境无法在 Yarn 集群里使用 (因为 Conda 包在不同系统间是不兼容的)。
Step 2.
下载 Flink 1.13, 需要注意的是,本文的功能只能用在 Flink 1.13 以上版本,然后:
- 把 flink-Python-*.jar 这个 jar 包 copy 到 Flink 的 lib 文件夹下;
- 把 opt/Python 这个文件夹 copy 到 Flink 的 lib 文件夹下。
Step 3.
安装以下软件 (这些软件是用于创建 Conda env 的):
- miniconda:https://docs.conda.io/en/latest/miniconda.html
- conda pack:https://conda.github.io/conda-pack/
- mamba:https://github.com/mamba-org/mamba
二、搭建 PyFlink 环境
接下来就可以在 Zeppelin 里搭建并且使用 PyFlink 了。
Step 1. 制作 JobManager 上的 PyFlink Conda 环境
因为 Zeppelin 天生支持 Shell,所以可以在 Zeppelin 里用 Shell 来制作 PyFlink 环境。注意这里的 Python 第三方包是在 PyFlink 客户端 (JobManager) 需要的包,比如 Matplotlib 这些,并且确保至少安装了下面这些包:
- 某个版本的 Python (这里用的是 3.7)
- apache-flink (这里用的是 1.13.1)
- jupyter,grpcio,protobuf (这三个包是 Zeppelin 需要的)
剩下的包可以根据需要来指定:
%sh
# make sure you have conda and momba installed.
# install miniconda: https://docs.conda.io/en/latest/miniconda.html
# install mamba: https://github.com/mamba-org/mamba
echo "name: pyflink_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- jupyter
- grpcio
- protobuf
- matplotlib
- pandasql
- pandas
- scipy
- seaborn
- plotnine
" > pyflink_env.yml
mamba env remove -n pyflink_env
mamba env create -f pyflink_env.yml运行下面的代码打包 PyFlink 的 Conda 环境并且上传到 HDFS (注意这里打包出来的文件格式是 tar.gz):
%sh
rm -rf pyflink_env.tar.gz
conda pack --ignore-missing-files -n pyflink_env -o pyflink_env.tar.gz
hadoop fs -rmr /tmp/pyflink_env.tar.gz
hadoop fs -put pyflink_env.tar.gz /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_env.tar.gzStep 2. 制作 TaskManager 上的 PyFlink Conda 环境
运行下面的代码来创建 TaskManager 上的 PyFlink Conda 环境,TaskManager 上的 PyFlink 环境至少包含以下 2 个包:
- 某个版本的 Python (这里用的是 3.7)
- apache-flink (这里用的是 1.13.1)
剩下的包是 Python UDF 需要依赖的包,比如这里指定了 pandas:
echo "name: pyflink_tm_env
channels:
- conda-forge
- defaults
dependencies:
- Python=3.7
- pip
- pip:
- apache-flink==1.13.1
- pandas
" > pyflink_tm_env.yml
mamba env remove -n pyflink_tm_env
mamba env create -f pyflink_tm_env.yml运行下面的代码打包 PyFlink 的 conda 环境并且上传到 HDFS (注意这里使用的是 zip 格式)
%sh
rm -rf pyflink_tm_env.zip
conda pack --ignore-missing-files --zip-symlinks -n pyflink_tm_env -o pyflink_tm_env.zip
hadoop fs -rmr /tmp/pyflink_tm_env.zip
hadoop fs -put pyflink_tm_env.zip /tmp
# The Python conda tar should be public accessible, so need to change permission here.
hadoop fs -chmod 644 /tmp/pyflink_tm_env.zipStep 3. 在 PyFlink 中使用 Conda 环境
接下来就可以在 Zeppelin 中使用上面创建的 Conda 环境了,首先需要在 Zeppelin 里配置 Flink,主要配置的选项有:
- flink.execution.mode 为 yarn-application, 本文所讲的方法只适用于 yarn-application 模式;
- 指定 yarn.ship-archives,zeppelin.pyflink.Python 以及 zeppelin.interpreter.conda.env.name 来配置 JobManager 侧的 PyFlink Conda 环境;
- 指定 Python.archives 以及 Python.executable 来指定 TaskManager 侧的 PyFlink Conda 环境;
- 指定其他可选的 Flink 配置,比如这里的 flink.jm.memory 和 flink.tm.memory。
%flink.conf
flink.execution.mode yarn-application
yarn.ship-archives /mnt/disk1/jzhang/zeppelin/pyflink_env.tar.gz
zeppelin.pyflink.Python pyflink_env.tar.gz/bin/Python
zeppelin.interpreter.conda.env.name pyflink_env.tar.gz
Python.archives hdfs:///tmp/pyflink_tm_env.zip
Python.executable pyflink_tm_env.zip/bin/Python3.7
flink.jm.memory 2048
flink.tm.memory 2048接下来就可以如一开始所说的那样在 Zeppelin 里使用 PyFlink 以及指定的 Conda 环境了。有 2 种场景:
- 下面的例子里,可以在 PyFlink 客户端 (JobManager 侧) 使用上面创建的 JobManager 侧的 Conda 环境,比如下边使用了 Matplotlib。

- 下面的例子是在 PyFlink UDF 里使用上面创建的 TaskManager 侧 Conda 环境里的库,比如下面在 UDF 里使用 Pandas。

三、总结与未来
本文内容就是在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中,无需手动在集群上去安装任何 Pyflink 的包,并且可以在一个 Yarn 集群里同时使用多个版本的 PyFlink。
每个 PyFlink 的环境都是隔离的,而且可以随时定制更改 Conda 环境。可以下载下面这个 note 并导入到 Zeppelin,就可以复现今天讲的内容:http://23.254.161.240/#/notebook/2G8N1WTTS
此外还有很多可以改进的地方:
- 目前我们需要创建 2 个 conda env ,原因是 Zeppelin 支持 tar.gz 格式,而 Flink 只支持 zip 格式。等后期两边统一之后,只要创建一个 conda env 就可以;
- apache-flink 现在包含了 Flink 的 jar 包,这就导致打出来的 conda env 特别大,yarn container 在初始化的时候耗时会比较长,这个需要 Flink 社区提供一个轻量级的 Python 包 (不包含 Flink jar 包),就可以大大减小 conda env 的大小。
本文为阿里云原创内容,未经允许不得转载。
PyFlink 开发环境利器:Zeppelin Notebook的更多相关文章
- 如何基于Jupyter notebook搭建Spark集群开发环境
摘要:本文介绍如何基于Jupyter notebook搭建Spark集群开发环境. 本文分享自华为云社区<基于Jupyter Notebook 搭建Spark集群开发环境>,作者:apr鹏 ...
- ORM 开发环境之利器:MVC 中间件 FreeSql.AdminLTE
前言 这是一篇纯技术干货的分享文章,FreeSql 已经基本完成 .NETCore 最方便的 ORM 使命,我们正在筹备生态的建立,比如 ABP 中如何使用 FreeSql 的实现,需要各种各样的扩展 ...
- 打造TypeScript的Visual Studio Code开发环境
打造TypeScript的Visual Studio Code开发环境 本文转自:https://zhuanlan.zhihu.com/p/21611724 作者: 2gua TypeScript是由 ...
- windows和linux中搭建python集成开发环境IDE——如何设置多个python环境
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- 老司机学新平台 - Xamarin开发环境及开发框架初探
随着被微软收购,最近一年间,Xamarin的火爆程度与日俱增.免费.更好的VS2015集成.更好的模拟器,甚至,在windows上运行和调试iOS平台程序,让我这样接触了十几年.NET平台的老司机,即 ...
- 使用IntelliJ IDEA 13搭建Android集成开发环境(图文教程)
[声明] 欢迎转载,但请保留文章原始出处→_→ 生命壹号:http://www.cnblogs.com/smyhvae/ 文章来源:http://www.cnblogs.com/smyhvae/p/ ...
- 【转】windows和linux中搭建python集成开发环境IDE
本系列分为两篇: 1.[转]windows和linux中搭建python集成开发环境IDE 2.[转]linux和windows下安装python集成开发环境及其python包 3.windows和l ...
- Android开发环境配置
由于公司项目需要,最近转做Android开发,这里我来介绍一下Android开发环境的配置过程. 首先,需要下载所需要的软件工具,如下所示: 1.Java:开发基础环境,JDK和JRE这两个都要下载的 ...
- 【Yeoman】热部署web前端开发环境
本文来自 “简时空”:<[Yeoman]热部署web前端开发环境>(自动同步导入到博客园) 1.序言 记得去年的暑假看RequireJS的时候,曾少不更事般地惊为前端利器,写了<Sp ...
- 在Ubuntu下配置舒服的Python开发环境
Ubuntu 提供了一个良好的 Python 开发环境,但如果想使我们的开发效率最大化,还需要进行很多定制化的安装和配置.下面的是我们团队开发人员推荐的一个安装和配置步骤,基于 Ubuntu 12.0 ...
随机推荐
- 项目性能优化—使用JMeter压测SpringBoot项目
项目性能优化-使用JMeter压测SpringBoot项目 我们的压力测试架构图如下: 配置JMeter 在JMeter的bin目录,双击jmeter.bat 新建一个测试计划,并右键添加线程组: 进 ...
- KingbaseES角色和权限介绍
KingbaseES 使用角色的概念管理数据库访问权限.为了方便权限管理,用户可以建立多个角色,对角色进行授权和权限回收,并把角色授予其他用户. 数据库初始化时,会创建一个超级用户的角色:system ...
- KingbaseES V8R3集群运维案例之---主库数据库服务down后failover切换详解
案例说明: 对KingbaseES V8R3集群,主库数据库服务down后,failover切换进行分析,详解其执行切换的过程,本案例可用于对KingbaseES V8R3集群failover故障的分 ...
- 鸿蒙HarmonyOS实战-ArkUI组件(Swiper)
一.Swiper 1.概述 Swiper可以实现手机.平板等移动端设备上的图片轮播效果,支持无缝轮播.自动播放.响应式布局等功能.Swiper轮播图具有使用简单.样式可定制.功能丰富.兼容性好等优点, ...
- #最大公约数#CF346A Alice and Bob
题目传送门 CF346A 分析 可以发现其所能表示的数就是能被最大公约数整除的数,且这些数不能超过最大值, 于是判断一下取数的奇偶性即可 代码 #include <cstdio> #inc ...
- #单位根反演,二项式定理#LOJ 6485 LJJ 学二项式定理
题目 \[\large\sum_{i=0}^nC(n,i)S^ia_{i\bmod 4} \] \(n\leq 10^{18},S,a\leq 10^8\) 分析 前面这一坨看起来就像是二项式定理,考 ...
- #子序列自动机,vector#洛谷 3500 [POI2010]TES-Intelligence Test
题目 多组询问查询某个串是否为模式串的子序列 分析 考虑用子序列自动机做,匹配的时候显然选择靠前的,用个vector查询最近的就行了 代码 #include <cstdio> #inclu ...
- OHOS IDE和SDK的安装方法
参照OpenHarmony应用开发环境安装流程,下载安装OHOS的IDE,过程中需要全程联网. IDE,安装至D:\Tools\Huawei\DevEcoStudio. IDE安装成功之后,按照提示下 ...
- AVX512加速矩阵乘法
最近打PKU的HPCGAME用的代码,这里只用上了20个zmm寄存器,改变block的大小应该还能优化一下速度. 代码只考虑了方阵,其他非2^n次方阵要自己改代码.具体原理很简单,看看代码就差不多知道 ...
- centos环境tomcat配置SSL
环境: centos7.9 tomcat9 jdk1.8 一.阿里云申请 免费SSL 按照官网的方法并未成功启动! 443 80端口加入安全组 阿里云申请免费ssl 下载后解压将localhost-r ...