SVM三则
硬间隔SVM
SVM被提出来, 解决模式识别中, 数据的分类问题,属于有监督算法中的一种,
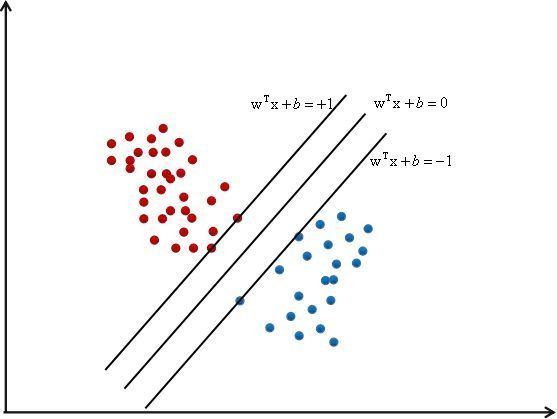
如上图所示, 于其他的线性回归方式不同, SVM企图去寻找一个最完美的超平面, 因为能正确分类样本的线, 它有很多条, 有时候, 像LR一样的模型, 当数据有噪声的时候,很容易越过分类边界, 造成误分类. 而SVM就是确保在分类正确的前提下, 使得数据点与分类之间的间隔最大化,所以, 目的也很明确了, 第一是要寻找这个最大间隔, 也就是这两条边界线到底是多少,其次是保证样本分类正确.
SVM被表示为参数和数据的线性组合,即
\]
其中\(w^Tx+b=0\),就是中间的那条线
最大化间隔
前面我们提到, 要最大化样本点与分界线之间的间隔, 其实就是寻找点到直线的最大距离, 而这些点在哪?有很多的点,就是很多的样本, 起作用的点就是关乎分界线位置的点, 我们定义间隔为1, 那么对于这两条线,我们定义为
w^Tx+b=1, y=1\\
w^Tx+b=-1, y=-1
\end{cases}\]
这里有1个问题
为什么间隔为1?
这个问题,其实1是为了好算吧,当然可以设置成2, 3,...只要成比例的增加\(w,b\)就可以了
这两条线还有另外的功能: 就是让该有的点,尽量的处于自己的那一侧, 转化成数学表达就是
w^Tx+b \geq 1, y=1\\
w^Tx+b \leq 1, y=-1
\end{cases}\]
现在,我们要找到这这个点, 相应的, 就应该有距离的存在, 那么点到直线的距离公式为:
\]
这里\(||w||\)默认为1范数, 其实2范数也是可以的, 我们知道, 关乎分界线命运的点, 在这条分界线上, 因为他们离这两条线的距离最短(如果有的话),这些在这两条线上的点,我们叫做支持向量,因为第一, 这些点其实在高维的时候就是特征向量嘛
显然, 如果在线上,那么\(|w^Tx+b|=1\),于是
\]
那么我们的距离优化就有了:最大化间隔\(\max r\), 但是一般我们将最大化问题转换为最小化问题,以及这样可以转化为二次规划问题,那么最大化\(r\),相当于最小化\(||w||\), 然后把它变成一个二次规划问题:最小化\(||w||^2\)
\]
形成约束问题
第一是优化\(r\),其次是优化分类的正确性
对于(1)式, 根据同号原则,其可以被表达为
y(w^Tx+b) \geq 1, y=1\\
y(w^Tx+b) \leq 1, y=-1
\end{cases}\]
我们希望尽可能正确的分类,所以约束优化问题的集合就是
\min \frac{1}{2}||w||^2 \\
\min y(w^Tx+b)\geq 1 \\
\min1-y(w^Tx+b) \geq 0
\end{cases}
\]
拉格朗日乘子变换
一般,我们将带约束的优化问题都转化为拉格朗日乘子法经行计算, 这样可以将整个带约束的优化集合转化为一个函数式子
拉格朗日乘子法请看
https://blog.csdn.net/u014792304/article/details/78396955?utm_source=distribute.pc_relevant.none-task
转换后的式子为:
\]
其中, \(\lambda \geq0\)为拉格朗日乘子
KKT条件
我们知道, 拉格朗日乘子法可以表示为:
\]
但是我们本质上优化的还是不等式约束, 不等式约束需要满足KKT条件
g(x) \leq 0 \\
\lambda \geq 0 \\
\lambda g(x)= 0
\end{cases}\]
于是, 我们的式子, 满足KKT条件,需要为:
(1-y(w^Tx+b)) \leq 0 \\
\lambda \geq 0 \\
\lambda_i(1-y(w^Tx+b)) = 0
\end{cases}
\]
为什么引入KKT条件?
- KKT条件是对最优解的约束,而原始问题中的约束条件是对可行解的约束。
对偶问题
对偶是吧原来的式子 min max L 转化为 max min L, 一来是它们近似, 二是这样可以先求解w,b, 然后只用管\(\lambda\),而\(\lambda\)只在支持向量上有作用 问题求解简单化 我将其转化为原问题的对偶问题, 转化为对偶问题之后, 全局上就变成了一个最小化的问题, 我们的原问题是
\]
那么它的对偶问题就是
\]
我们将问题的函数表达视作凸二次规划问题,这样可以分别对参数求偏导求解
\]
这样的关系,我们称其为弱对偶关系,强对偶就是 相等
我们对无约束问题求偏导, 此时\(\lambda\) 看做常量
\]
将其带入\(L\)
=\frac{1}{2}||w||^2+\sum_{i=1}^{N} \lambda_i-\sum \lambda_i y_iw^Tx_i-\sum \lambda_i y_ib\\
=\frac{1}{2}||w||^2+\sum_{i=1}^{N} \lambda_i-\sum \lambda_i y_iw^Tx_i
\]
接下来对\(\lambda\):
w=\sum \lambda y x
\]
再次带入\(L\)并化简:
\]
那么\(b\)呢? 我们通过KKT条件来解\(b\)
我们把
\]
称作作松弛互补条件
并设置2条虚线, 有点落在线上时, 就是松弛条件的解
我们假设存在\((x_k,y_k)\)
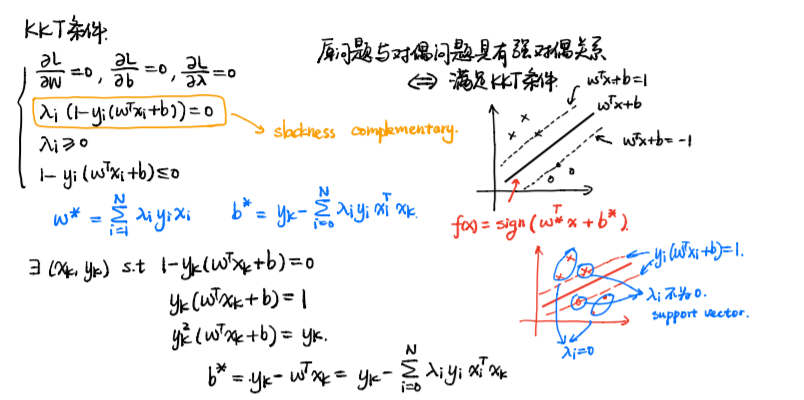
那么. 最后, hard-margin的解为:
\]
\(w\)可以看作是数据\(x\)的线性组合, 但对于\(\lambda\) ,当且仅当数据落在两条虚线上时, \(\lambda\)才有值,对于其他的sample, \(\lambda\)不起作用,这部分叫支持向量
引入 SMO

软间隔SVM, 松弛变量\(\xi\), 和惩罚系数\(C\)
思想: 允许存在一点点错误
- hard-margin:假设数据是非常理想的, 数据是可分的
- soft-margin:数据是含有噪声的, 或者难以分类的
公式:在原先的基础上, 加上一个损失
\min\frac{1}{2}||w||^2+C\sum_{i=1}^{N} \xi_i
\]
这里的损失可以理解为:距离,(hinge loss,合页损失)
if\quad y_i(w^Tx+b) \geq 1, lss = 0 \\
if\quad y_i(w^Tx+b) \leq 1, loss = 1-y_i(w^Tx+b)
\end{cases}\]

\(\xi\)和\(C\)的问题
首先, 软间隔SVM通过增加一个合页损失, 来增加SVM的容忍度, 我们将错分时候的损失表示为
\]
并将其记为\(\xi\), 仔细看来, 这个\(\xi\)的作用是:
表示样本偏离离群点或者偏离分界线的一个程度,当然,肯定是往错误的方向偏
而对于\(C\)来说, 其可以理解为一个惩罚项, 表示着模型对错分样本的容忍度, 惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大,此时就暗示着你非常不愿意放弃这些离群点, 最极端的情况是你把C定为无限大,这样只要稍有一个点离群,目标函数的值马上变成无限大,马上让问题变成无解,这就退化成了硬间隔问题
核SVM
其实核函数是将低纬空间的点, 转化到高维空间中去, 让线性不可分变得可分, 核函数内, 大部分是向量内积的一个操作

优化公式:
\]
其实, 就是对\(x_i, x_j\)进行一种变换: 常见的核如:
- 线性变换: \(x^Tx\), 可以分离出一个平面
SVM三则的更多相关文章
- 简介支持向量机热门(认识SVM三位置)
支持向量机通俗导论(理解SVM的三层境地) 作者:July .致谢:pluskid.白石.JerryLead.出处:结构之法算法之道blog. 前言 动笔写这个支持向量机(support vector ...
- SVM(三)线性支持向量机
本文是在微信公众号发表的原创~ 额,图片粘不过来~就把链接给你们吧 http://mp.weixin.qq.com/s?__biz=MjM5MzM5NDAzMg==&mid=400740076 ...
- SVM算法简单应用
第一部分:线性可分 通俗解释:可以用一条直线将两类分隔开来 一个简单的例子,直角坐标系中有三个点,A,B点为0类,C点为1类: from sklearn import svm # 三个点 x = [[ ...
- 机器学习6—SVM学习笔记
机器学习牛人博客 机器学习实战之SVM 三种SVM的对偶问题 拉格朗日乘子法和KKT条件 支持向量机通俗导论(理解SVM的三层境界) 解密SVM系列(一):关于拉格朗日乘子法和KKT条件 解密SVM系 ...
- 《AI算法工程师手册》
本文转载自:http://www.huaxiaozhuan.com/ 这是一份机器学习算法和技能的学习手册,可以作为学习工作的参考,都看一遍应该能收获满满吧. 作者华校专,曾任阿里巴巴资深算法工程师, ...
- 机器学习理论基础学习4--- SVM(基于结构风险最小化)
一.什么是SVM? SVM(Support Vector Machine)又称为支持向量机,是一种二分类的模型.当然如果进行修改之后也是可以用于多类别问题的分类.支持向量机可以分为线性和非线性两大类. ...
- 机器学习算法与Python实践之(三)支持向量机(SVM)进阶
机器学习算法与Python实践之(三)支持向量机(SVM)进阶 机器学习算法与Python实践之(三)支持向量机(SVM)进阶 zouxy09@qq.com http://blog.csdn.net/ ...
- LibLinear(SVM包)使用说明之(三)实践
LibLinear(SVM包)使用说明之(三)实践 LibLinear(SVM包)使用说明之(三)实践 zouxy09@qq.com http://blog.csdn.net/zouxy09 我们在U ...
- CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3 2===本节课的收获 ===熟悉SVM及其多分类问题 ===熟悉softmax分类问题 ===了解优化思想 由上节课即KNN的分析步骤 ...
- 三种SVM的对偶问题
一.SVM原问题及要变成对偶问题的解决办法 对于SVM的,我们知道其终于目的是求取一分类超平面,然后将新的数据带入这一分类超平面的方程中,推断输出结果的符号,从而推断新的数据的正负. 而求解svm分类 ...
随机推荐
- Nebula Graph 源码解读系列 | Vol.01 Nebula Graph Overview
上篇序言中我们讲述了源码解读系列的由来,在 Nebula Graph Overview 篇中我们将带你了解下 Nebula Graph 的架构以及代码仓分布.代码结构和模块规划. 1. 架构 Nebu ...
- Java 接口:比较对象的大小
1 package com.bytezreo.interfacetest; 2 3 /** 4 * 5 * @Description 接口:比较对象的大小 6 * @author Bytezero·z ...
- 基于centos7 创建一个jdk8的镜像
前言: 直接使用docker拉取jdk8镜像因有时区问题,设置后也不生效,所以干脆自己做一个 以下是Dockerfile文件 FROM centos:7 RUN ln -snf /usr/share/ ...
- TLS原理与实践(四)国密TLS
主页 个人微信公众号:密码应用技术实战 个人博客园首页:https://www.cnblogs.com/informatics/ 引言 TLS作为保证网络通信安全的关键技术和基石被广泛应用,但目前主流 ...
- C#中的JSON序列化方法
在C#中的使用JSON序列化及反序列化时,推荐使用Json.NET--NET的流行高性能JSON框架,当然也可以使用.NET自带的 System.Text.Json(.NET5).DataContra ...
- PV的回收策略、访问策略和状态
PersistentVolume(PV)的回收策略.访问策略和状态是Kubernetes存储管理中的重要概念. 回收策略 Retain:当PV的回收策略设置为Retain时,即使对应的Persiste ...
- 2023中山市第三届香山杯网络安全大赛初赛wp
序 被带飞了 PWN move 先往变量 sskd 写入 0x20 字节,往第二个输入点输入 0x12345678 即可进入到第三个输入点,存在 0x8 字节的溢出.思路是在第一个输入点布置 rop ...
- 基于stm32H730的解决方案开发之点亮第一个LED灯
一 概述 STM32H730超值系列内含ArmCortex-M7内核(具有双精度浮点单元),工作频率可达550 MHz.内嵌的128 KB闪存使意法半导体能够为开发人员提供一种经济划算的解决方案.凭借 ...
- Android Studio安装插件重启插件消失
问题 安装插件后,已经提示让重启IDE,但是重启后发现插件是安装失败了 解决方法 原因是自己改了配置,如果下载的插件是jar包,则可以安装,如果是zip压缩文件的插件,则是要我们手动解压一下 我上面的 ...
- 寒武纪加速平台(MLU200系列) 摸鱼指南(三)--- 模型移植-分割网络实例
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...