MOGA-Net: 多目标遗传算法求解复杂网络中的社区《A Multiobjective Genetic Algorithm to Find Communities in Complex Networks》(遗传算法、多目标优化算法、帕累托最优)
论文:A Multiobjective Genetic Algorithm to Find Communities in Complex Networks
GitHub:
IEEE 2012的论文。
中文翻译参考:https://wenku.baidu.com/view/ca76d69033687e21ae45a915.html#
上计算智能课的英文汇报,周二晚上汇报的,这学期接下来的课就可以不用汇报了,舒服。
大概水一下论文的相关内容.
1、首先什么是遗传算法,具体的看百度百科,以及一些博客的介绍.
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
遗传算法能够自我迭代,让它本身系统内的东西进行优胜劣汰的自然选择,把好的保留下来,次一点的东西就排除掉。遗传算法的本质就是是优胜劣汰,选出最优秀的个体,一般用来寻找最优解。
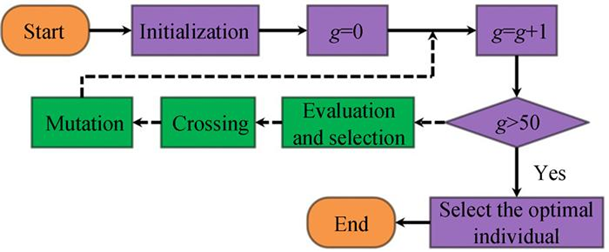
遗传算法的过程(步骤):
1. Initialization(初始化)
2. Calculate Fitness(计算适应度)
3. Selection (选择操作)
4. Crossover (交叉操作)
5. Mutation (变异操作)
6. Judge and End(终止条件判断)
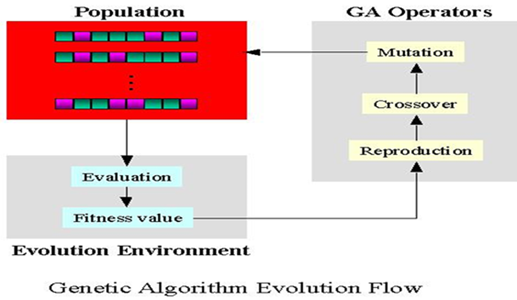
Three basic genetic operations(三个基本遗传算子):
Selection、Crossover、Mutation
Key Operation(核心):Crossover
放两张图参考一下:
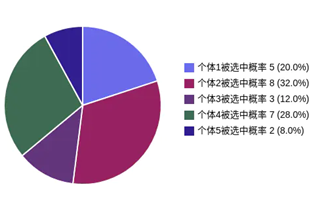
(1)选择操作
Selection(选择):Use the wheel for selection
对于选择操作,通常使用轮盘赌选择,就是按照贡献率转转盘。
假如有5条染色体,他们的适应度分别为5、8、3、7、2。
那么总的适应度为:F = 5 + 8 + 3 + 7 + 2 = 25。
那么各个个体的被选中的概率为:
α1 = ( 5 / 25 ) * 100% = 20%
α2 = ( 8 / 25 ) * 100% = 32%
α3 = ( 3 / 25 ) * 100% = 12%
α4 = ( 7 / 25 ) * 100% = 28%
α5 = ( 2 / 25 ) * 100% = 8%
(2)交叉操作
Crossover(交叉):
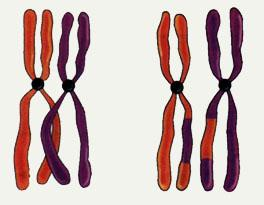
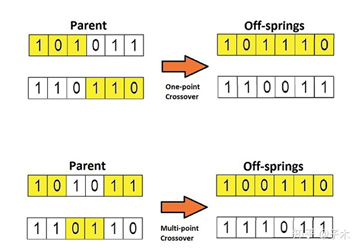
(3)变异操作
Mutation(变异):
101 101 001 011 001
001 101 011 011 001
参考博客:
https://baike.baidu.com/item/%E9%81%97%E4%BC%A0%E7%AE%97%E6%B3%95/838140?fr=aladdinhttps://blog.csdn.net/u010451580/article/details/51178225
https://zhuanlan.zhihu.com/p/49055485
https://www.jianshu.com/p/ae5157c26af9
2、多目标优化之帕累托最优
Pareto Optimality for multi-objective optimization(多目标优化之帕累托最优):
Pareto Optimality(帕累托最优):also named Pareto efficiency,It is the ideal state for resource
allocation。There‘s a group of people who allocate resources,to make at least one person better
without making anyone worse。
Pareto Front(帕累托前沿) :The value corresponding to the Pareto Optimal solution is the Pareto Front。
For a problem with two targets(两目标), the Pareto Optimal solution is usually a line(线).
For multiple targets(多目标), the Pareto Front is usually a hypersurface(超平面).
土鳖式英语,具体意思看百度百科:
https://baike.baidu.com/item/%E5%B8%95%E7%B4%AF%E6%89%98%E6%9C%80%E4%BC%98/1768788?fr=Aladdin
帕累托最优:一群人分配资源,从一个状态到另一个转态,在没有人的情况变的更糟糕的情况下,至少有一个人的情况会变得更好。
帕累托前沿:帕累托最优对应的目标函数的值就是帕累托前沿。
接下来说一下,什么是支配与分支配,以及如何求解帕累托前沿
1)Dominant and non-dominant rank(支配与非支配)
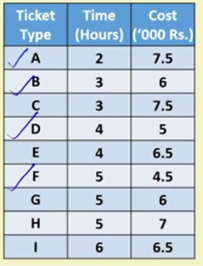
举个例子,你想买飞机票,既想机票价格便宜,又想飞行时间比较短。
如上图所示,若表示为机票,既要考虑飞行时长也要考虑机票价格,保证出行最便捷。A与C相比,A耗时为2,花费为7.5;C耗时为3,花费也为7.5,那么方案A要比C优秀,那么A支配C。但是,纵观全部解,没有在耗时和花费两者全部比A优秀的方案,那么就称A为非支配。
A的耗时为2,花费为7.5;B的耗时为3,花费为6。那么两者进行对比,A只能在时间上获胜,B只能在花费上获胜,但是两者没有既在时间又在花费上获胜的情况。且纵观全局,没有在耗时和花费两者全部比A、B优秀的方案,那么A、B就组成了帕累托最优前沿,D、F类似。因此,得到了下图。
如图所示,A、B、D、F判定为帕累托前沿后,将他们放到一边,暂时不考虑。再在剩下的方案中,再选一组帕累托前沿,依此类推。
就是选出来A、B、D、F之后,这四个属于rank=1,然后把A、B、D、F从所有的票里面删掉,然后再从剩下的里面选最好的,然后选出来C、E、G,这是rank=2这一系列里面的,再把C、E、G删掉,继续选,无限循环这种操作,最后得到下图。
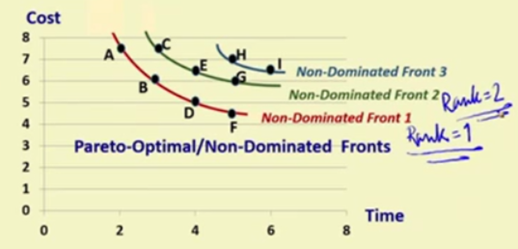
步骤:
Non-Dominated Fronts(非支配前沿/帕累托前沿):
Process:
(1)Let i=1;
(2)For j=1,2.......n ,and j ≠ i,Compare the dominant and non-dominant relationship between individual〖 〗_ and _(比较支配与非支配关系);
(3) If there is no individual _ is better than _,_ is labeled as non-dominant;
(4)Let i = i +1,and go to(2),until end。
参考博客:
https://zhuanlan.zhihu.com/p/54691447
https://blog.csdn.net/cuicanxingchen123456/article/details/88780451
https://blog.csdn.net/qq_39974201/article/details/106770152
https://blog.csdn.net/qq_40434430/article/details/82876572
3、带精英策略的非支配排序的遗传算法(NSGA-II)
接下来,什么是NSGA-II。
NSGA-I(非支配排序遗传算法)、NSGA-II(带精英策略的非支配排序的遗传算法)
Both are multi-objective optimization algorithms based on Genetic Algorithms and Pareto Optimal solution discussion(都是基于遗传算法和帕累托最优解的多目标优化算法).
NSGA-II is improved based on NSGA-I with three main improvements(改进了三个内容):
(1) Fast non-dominated sorting algorithm(快速非支配排序算法);
(2) Congestion and congestion comparison operator(拥挤度和拥挤度比较算子);
(3) Elitist Strategy(精英策略)。
快速非支配排序算法就是前面说的求帕累托前沿。
接下来说一下什么是拥挤度和拥挤度比较算子,以及精英策略是什么。
(1)Congestion(拥挤度)
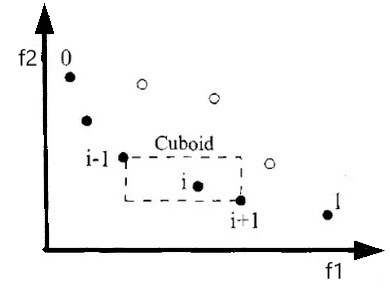
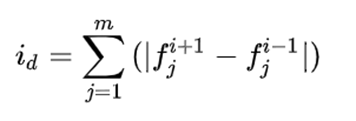
为了得到种群中特定解周围的解的拥挤度估计,我们根据每一目标函数计算这点两侧的两个点的平均距离。这个数值作为以最近邻居作为顶点的长方体周长的估计(称为拥挤系数)。
在上图中,第i个解在它所在前沿面的拥挤系数是它周围长方体的长度(如虚线框所示),拥挤度的计算保证种群多样性。
拥挤系数的计算需要根据每一目标函数值的大小的升序顺序对种群进行排序(即假如得到第一级非支配层,则对其按照目标函数的大小进行排序,然后计算拥挤度)。因此,对每一目标函数,边界解(拥有最大和最小值的解)被指定为无穷大距离的值。所有其它中间的解都被指定为等于两个相邻解的函数值归一化后的绝对差值。计算方法对其它目标函数也是这样。全部拥挤系数值是通过个体每一目标的距离值的加和计算得到的,每一目标函数在计算拥挤系数前都会进过归一化处理。
具体步骤:
①每个点的拥挤度id置为 0;
② 针对每个目标,对种群进行非支配排序,令边界的两个个体拥挤度为无穷,即 od=Id=∞
③ 对其他个体进行拥挤度的计算: 公式如上图
其中: id 表示 i 点的拥挤度, fj i+1 表示 i+1点的第 j 个目标函数值, fj i-1表示 i -1点的第 j个目标函数值。
(2)Congestion Comparison Operator(拥挤度比较算子)
Two attributes:_(级数,即第几级)和_(拥挤度)
拥挤度比较算子就是得到的rank和d这两个系数。
比较的规则如下:
① _ <_
② _ =_ and _>_
经过前面的快速非支配排序和拥挤度计算之后,种群中的每个个体i
都拥有两个属性:非支配排序决定的非支配序 ̇_rank(级数,即第几级)和拥挤度_。
根据这两个属性,可以定义拥挤度比较算子:
个体i与另一个个体 j 进行比较,只要下面任意一个条件成立,则个体i获胜。
① 如果个体i所处非支配层优于个体 j 所处的非支配层,即i rank<j rank
② 如果他们有相同的等级,且个体i比个体 j 有一个更大的拥挤距离,即i rank=j rank且i d>j d
第一个条件确保被选择的个体属于较优的非劣等级。第二个条件根据它们的拥挤距离选择由于在同一非劣等级而不分胜负的两个个体中位于较不拥挤区域的个体(有较大的拥挤度i d)。胜出的个体进入下一个操作。
接下来就是精英策略。
(3)Elitist Strategy(精英策略)
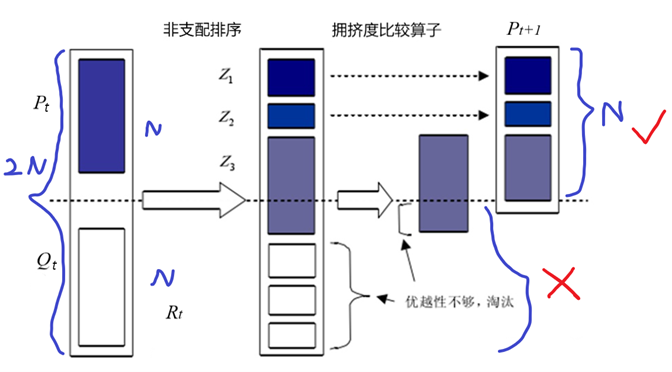
首先将第t代产生的新种群Qt与父代Pt合并组成Rt,种群大小为 2N 。然后进行非支配排序,产生一系列非支配集Z1、Z2、Z3...并计算拥挤度。由于子代和父代个体都包含在其中,则经过非支配排序以后的非支配集中包含的个体是子代和父代中最好的,所以先将Z1放入新的父代种群Pt+1中。如果的大小小于 N ,则继续向新的父代种群中填充下一级非支配集Z2,直到添加Z3时,种群的大小超出 N ,对Z3中的个体使用拥挤度比较算子,使个体数量达到N 。然后通过遗传算子(选择、交叉、变异)产生新的子代种群。
说人话,就是父代和子代合在一起,然后利用非支配排序算法得到Z1、Z2、Z3...,Z1是最好的,Z2是次优,依次往下,然后利用规则① 从好的开始往下一代里面加,一直加到数量为N,
如果加到某一级时,图上是Z3级,Z3级全都加入,那么总的数量超过N,所以使用规则② ,选出来一部分好的加入,正好数量凑够N,结束了。
参考博客:
https://zhuanlan.zhihu.com/p/57482087
https://www.cnblogs.com/bnuvincent/p/5268786.html
http://www.doc88.com/p-2864919313679.html
OK,以上就是论文中涉及到的相关知识点。
//---------------------------------------------------------我是分割线--------------------------------------------------------------//
接下来就是论文了。
论文大体意思就是使用多目标遗传算法求解复杂网络中的社区(废话,题目就叫这个)
首先理解社区是什么意思,论文中给出了解释,不解释了。
然后论文的目的就是想让社区内关系紧密,社区间关系稀疏。
因为对应的是两个目标,就是社区内和社区间,这两个是无法衡量哪一种比较好,所以是多目标问题,所以要用帕累托最优来判断,通过一系列操作之后,最后通过一个叫模块度的东西来综合评价最后谁是最优的。
贴一下组友写的东西:
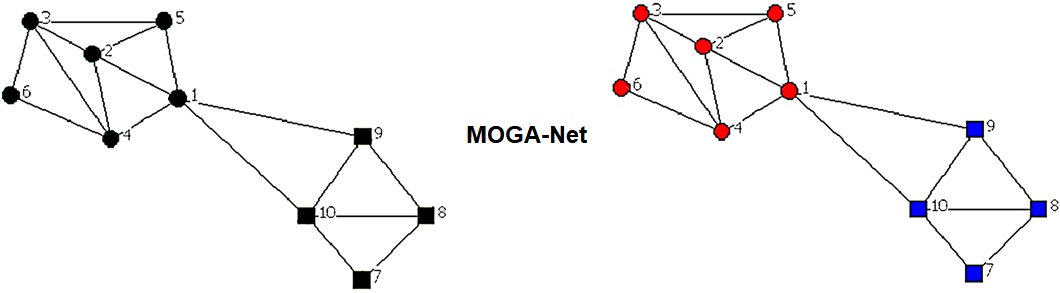
如图所示,我们有一个复杂的网络,本篇论文所作的工作就是通过MOGA-Net算法识别出复杂网络中的社区结构,最终得到的结果如右图所示,左图的复杂网络被分成了两个社区,分别用红色和蓝色结点表示。
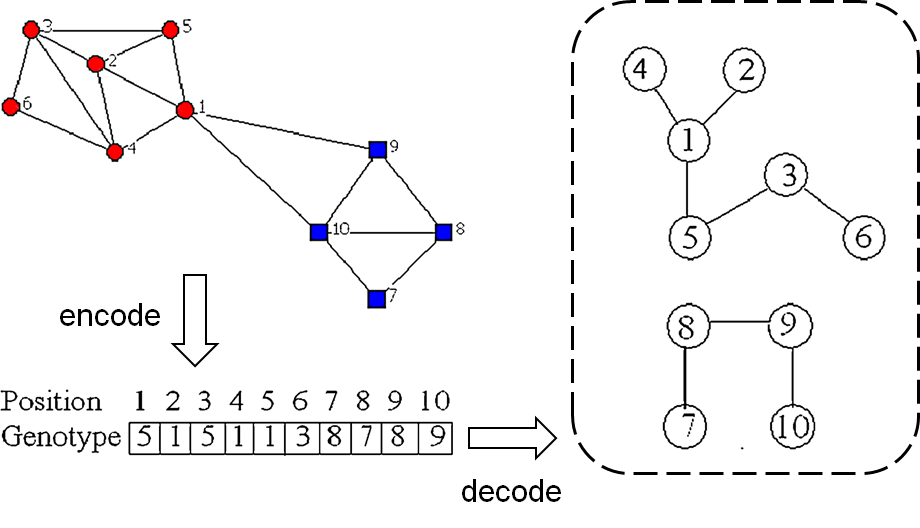
(a)Network of ten nodes partitioned in two communities {1, 2, 3, 4, 5, 6} and {7, 8, 9, 10}
(b)Locus-based representation of a genotype.
(c)Graph-based structure of the genotype.
我们的算法使用[43]中提出的基于轨迹的邻接表示,并在[28]和[38]中用于多目标聚类。在这个基于图的表示中,一个单独的个体由N个基因g:.... , gx组成,每个基因可以假设等位基因值j,取值范围是{[1.....N}。基因和等位基因表示网络N的建模—一图G= (V,E中的节点。j值分配给第i个基因被解读为节点i和 j之间连接。这就意味着在社区解中会发现 i 和 j 在同一个社区。然而,解码步骤中关键是识别对应图中所有的单独部分。同一部分中的节点被分配到同一社区。
我们可以通过编码操作将一个网络编码成一个基因型,基因型的长度和网络中包含的节点个数相同。如图所示,Position 代表网络中的节点,Position和Genotype一一对应的关系代表网络中的连接。比如说Position 1 对应Genotype 5 代表网络中节点1和节点5通过一条边互相连接。
We can encode a network into a genotype through the encoding operation. The length of the genotype is the same as the number of nodes in the network. As shown in the figure, Position represents the node in the network, and the one-to-one correspondence between Position and Genotype represents the connection in the network. For example, Position 1 corresponds to Genotype 5, which means that node 1 and node 5 are connected to each other through an edge in the network.
通过解码操作,我们可以根据Genotype把原始的网络分割成多个组件,上图所示的 Genotype 通过解码操作后就分解成了右图所示的两个组件。一个组件就是一个社区。
Through the decoding operation, we can divide the original network into multiple components according to Genotype. The Genotype shown in the figure above is decomposed into the two components shown in the right figure after the decoding operation. A component is a community.
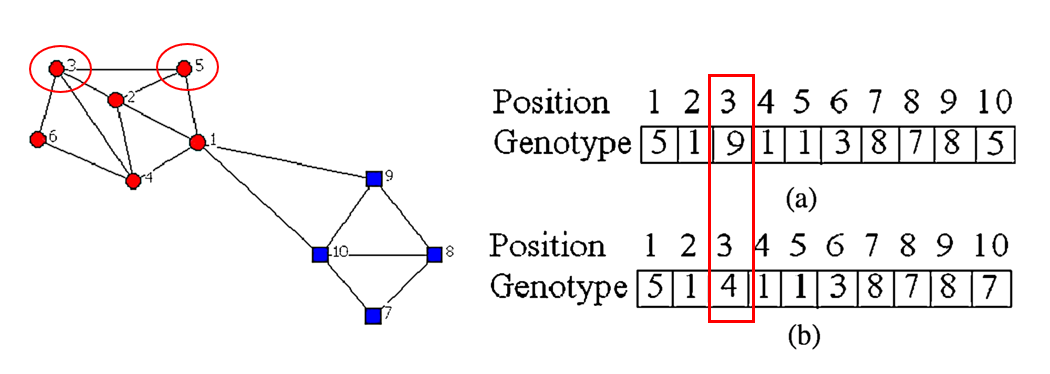
(a) Genotype where the couples (3, 9) and (10, 5) are not edges of the graph reported in Fig. 1(a).
(b) Modified genotype.
初始化过程中考虑网络中节点的有效连接。产生随机的个体。然而,如果第 i 个位置的等位基因值是 j,但边(i,j)不存在,个体j会被替代为与 i 相邻的节点之一。例如,在图2(a)在位置3和10分别对应等位基因值9和5。然而边(3,9)和(10,5)在图1(a)所示网络中不存在,因此9被4替代,5被7替代。
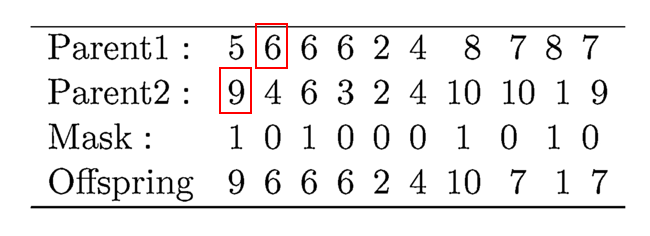
Uniform Crossover:均匀交叉
MOGA-Net使用了一个标准均匀的交叉算子。首先,随机产生一个交叉掩码,长度为N即节点的数量。通过从掩码为0对应的第一个父代的基因和掩码为1对应的第二个父代的基因产生一个子代。利用均匀交叉的主要动机是它能保证维持子代个体中网络节点的有效连接。事实上,因为有偏倚地初始化,对种群种每个个体,如果基因i包含值j,那么边(i,j)存在。
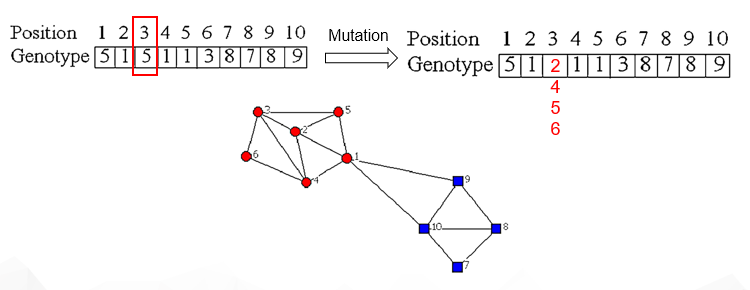
突变操作是随机改变第 I 个基因的值 j,引起搜索空间的一个无效探测,因为和节点连接的上述观察一样。因此,一个等为基因能够假设的可能值被严格限制在基因i 的邻近基因中。例如,考虑图1(a)中的网络,第三个位置的基因所允许的等位基因值是2,4,5,6。这种突变操作保证了每个节点只和它的邻近之一相连的突变子代的后代。
然后就来贴一下伪代码:
(1)创建一个由长度为 N 的随机个体组成的种群
While
编码种群中的每个个体,生成由 k 个组件组成的图 G 的划分

(2)解码

(3)通过这两个公式来评价社区内和社区间

(4)交叉变异

(5)使用模块度进行最终的综合评价

结束,就这些内容,水完博客了,该滚去开例会了。
在下告辞 ε=ε=ε=┌(; ・_・)┘
MOGA-Net: 多目标遗传算法求解复杂网络中的社区《A Multiobjective Genetic Algorithm to Find Communities in Complex Networks》(遗传算法、多目标优化算法、帕累托最优)的更多相关文章
- 多目标优化算法(一)NSGA-Ⅱ(NSGA2)(转载)
多目标优化算法(一)NSGA-Ⅱ(NSGA2) 本文链接:https://blog.csdn.net/qq_40434430/article/details/82876572多目标优化算法(一)NSG ...
- 译<容器网络中OVS-DPDK的性能>
译<容器网络中OVS-DPDK的性能> 本文来自对Performance of OVS-DPDK in Container Networks的翻译. 概要--网络功能虚拟化(Network ...
- 【智能算法】超详细的遗传算法(Genetic Algorithm)解析和TSP求解代码详解
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 文章声明 此文章部分资料和代码整合自网上,来源太多已经无法查明出处,如侵犯您的权利,请联系我删除. 00 目录 遗传算法定义 生 ...
- 【优化算法】遗传算法GA求解混合流水车间调度问题(附C++代码)
00 前言 各位读者大家好,好久没有介绍算法的推文了,感觉愧对了读者们热爱学习的心灵.于是,今天我们带来了一个神奇的优化算法--遗传算法! 它的优点包括但不限于: 遗传算法对所求解的优化问题没有太多的 ...
- 利用遗传算法求解TSP问题
转载地址 https://blog.csdn.net/greedystar/article/details/80343841 目录 一.问题描述 二.算法描述 三.求解说明 四.参考资料 五.源代码 ...
- Python动态展示遗传算法求解TSP旅行商问题(转载)
版权声明:本文为博主原创文章,遵循 CC 4.0 by-sa 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/jiang425776024/articl ...
- ARIMA模型--粒子群优化算法(PSO)和遗传算法(GA)
ARIMA模型(完整的Word文件可以去我的博客里面下载) ARIMA模型(英语:AutoregressiveIntegratedMovingAverage model),差分整合移动平均自回归模型, ...
- 超详细的遗传算法(Genetic Algorithm)解析
https://blog.csdn.net/u010451580/article/details/51178225 https://www.jianshu.com/p/c82f09adee8f 00 ...
- 遗传算法 Genetic Algorithm
2017-12-17 19:12:10 一.Evolutionary Algorithm 进化算法,也被成为是演化算法(evolutionary algorithms,简称EAs),它不是一个具体的算 ...
- 遗传算法Genetic Algorithm
遗传算法Genetic Algorithm 好家伙,回回都是这个点,再这样下去人估计没了,换个bgm<夜泊秦淮>,要是经典咏流传能投票选诗词,投票选歌,俺一定选这个 开始瞎叨叨 遗传算法的 ...
随机推荐
- [oeasy]教您玩转python - 0006 - 自由软件运动和开源运动
顺序执行 回忆上次内容 上次写了10000行代码 10000行代码 都是写在明面上的 人家一下载py 文件 就能看个明明白白 修改或者运行程序都很方便 这程序全都这么公开出来 大家随意修改 ...
- CCF 无线网络
题目原文 问题描述(题目链接登陆账号有问题,要从这个链接登陆,然后点击"模拟考试",进去找本题目) 试题编号: 201403-4 试题名称: 无线网络 时间限制: 1.0s 内存限 ...
- docker 将镜像发布到网络
1.发布自己的镜像 hub.docker.com 创建账号 docker login -u supermao -p xxxx docker tag ls supermaofox/ls:1.0 先打标签 ...
- Fiddler篡改请求和响应数据
Fiddler标记断点后,我们可以通过篡改请求或响应数据,来模拟客户端请求和服务器响应. 一.打断点的方式 1.1 工具栏设置断点 工具栏勾选断点类型进行断点,路径:Rules->Automat ...
- 在Python中使用sqlalchemy来操作数据库的几个小总结
在探索使用 FastAPI, SQLAlchemy, Pydantic,Redis, JWT 构建的项目的时候,其中数据库访问采用SQLAlchemy,并采用异步方式.数据库操作和控制器操作,采用基类 ...
- 对比python学julia(第四章:人工智能)--(第二节)人脸识别
2.1. 项目简介 人脸识别是基于人的脸部特征信息进行身份识别的一种图像识别技术.使用0PenCV 进行人脸识别的过程如下. (1) 针对每个识别对象收集大量的人脸图傣作为样本. (2) 将样本 ...
- 【IDEA】创建Maven工程
当前工程,点new - project 选Maven,不需要点选什么骨架创建,骨架创建要下载大量依赖,生成时间太长, 空Maven的目的是让我们自己了解这个项目结构,需要什么依赖再加什么依赖 框线内的 ...
- 【Hibernate】Re07 关系映射处理
一.单向多对一关系映射处理 演示案例列举了员工与部门的关系,一个部门下具有多个员工,相反的一个员工只隶属于一个部门下面 Maven依赖坐标: <dependency> <groupI ...
- 植物大战僵尸杂交版v2.1整合包全解锁+高清工具
植物大战僵尸杂交版v2.1整合包全解锁+高清工具 引言 <植物大战僵尸>作为一款经典的塔防游戏,自2009年发布以来,就以其独特的游戏机制和幽默的风格赢得了全球玩家的喜爱.随着游戏的不 ...
- 【摘录】人形机器人和自动驾驶技术 —— 3D机器视觉技术
以下内容引自: https://www.eda365.com/forum.php?mod=viewthread&tid=744288 3D机器视觉技术分为两个部分,即3D重构技术和3D数据分析 ...