生产级Redis 高并发分布式锁实战2:缓存架构设计问题优化
对于大多数高并发场景,都是读多写少。比如商品信息,医生挂号信息等。提交订单页只有一个操作。
对于一个普通的缓存架构设计,实现商品的增删改查功能,代码如下:
Controller 层
@RestController("/api/product")
public class ProductController{
@Autowired
private ProductService productService;
@RequestMapping(value="/add",method=RequestMethod.POST)
public Product addProduct(@RequestBody Product productParam){
return productService.addProduct(productParam);
}
@RequestMapping(value="/update",method=RequestMethod.POST)
public Product updateProduct(@RequestBody Product productParam){
return productService.updateProduct(productParam);
}
@RequestMapping(value="/get/{productId}")
public Product getProduct(@PathVariable Long productId){
return productService.getProduct(productId);
}
}
Service层
@Autowired
private RedisUtil redisUtil;
@Autowired
private Redisson redisson;
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24;
@Transactional
public Product addProduct(Product product){
Product productResult = productDao.addProduct(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(),JSON.toJSONString(productResult) );
return productResult;
}
@Transactional
public Product updateProduct(Product product){
Product productResult = productDao.updateProduct(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(),JSON.toJSONString(productResult) );
return productResult;
}
public Product getProduct(Long productId){
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
String productStr = redisUtil.get(productCacheKey);
if(!StringUtils.isEmpty(productStr)){
product = JSON.parseObject(productStr,Product.class);
return product;
}
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product));
}
return product;
}
优化架构问题1: 冷热数据
问题分析:假设几十亿的商品,所有商品数据将存入缓存。每天需要访问的数据,我们称为热数据。仅占内存不到 1%。热数据放缓存,冷数据放数据库,可以设置缓存超时时间,如24小时失效。
冷热数据分离方案:添加缓存失效时间,做到冷热数据分离
// 冷热数据分离,给缓存设置过期时间
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(),JSON.toJSONString(productResult),PRODUCT_CACHE_TIMEOUT,TimeUnit.SECONDS );
// 查到缓存,则添加过期时间。称之为缓存读延期
String productStr = redisUtil.get(productCacheKey);
if(!StringUtils.isEmpty(productStr)){
product = JSON.parseObject(productStr,Product.class);
redisUtil.expire(productCacheKey,PRODUCT_CACHE_TIMEOUT,TimeUnit.SECONDS );
return product;
}
优化架构问题2:缓存失效
参考:缓存击穿,缓存穿透,缓存雪崩问题分析及优化
- 缓存击穿:大批缓存在同一时间失效,导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉。
//设置随机时间
private Integer genProductCacheTimeOut(){
return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60;
}
- 缓存穿透:
被黑客攻击,后台发送大量数据库中不存在请求;
或后台误操作商品在数据库中被删除。此时存在缓存无数据,数据库中无数据。
或使用布隆过滤器。或设置空缓存。
public static final String EMPTY_CACHE = "{}";
public Product getProduct(Long productId){
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
String productStr = redisUtil.get(productCacheKey);
if(!StringUtils.isEmpty(productStr)){
// 如果查到缓存是我们设置的空缓存,则直接返回。
if(EMPTY_CACHE.equals(productStr)){
// 设置读延期
redisUtils.expire(productCackeKey,genEmptyCacheTimeOut(), TimeUnit.SECONDS);
return null;
}
product = JSON.parseObject(productStr,Product.class);
redisUtil.expire(productCacheKey,genProductCacheTimeOut(),TimeUnit.SECONDS );
return product;
}
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
return product;
}
给空缓存设置一个过期时间
//设置随机时间
private Integer genEmptyCacheTimeOut(){
return 60 + new Random().nextInt(30);
}
优化架构问题3:突发性热点缓存重建
假设几百万用户,几十万用户请求商品链接。冷门商品在缓存中不存在,则请求数据库。
假设此时几万请求到数据库,执行相同的设置缓存操作,这是典型的突发性热点缓存重建,导致系统压力暴增问题。
DCL: double check lock 双重检测锁。
方案:1 加锁,则不会让数据库宕机。2 双重检测锁DCL(Double Check Lock)。
- 缓存雪崩:指缓存支撑不住或宕机后,大量请求打到存储层,造成存储层也会级联宕机。
private Product getProductCache(String productCacheKey){
Product product = null;
String productStr = redisUtil.get(productCacheKey);
if(!StringUtils.isEmpty(productStr)){
// 如果查到缓存是我们设置的空缓存,则直接返回。
if(EMPTY_CACHE.equals(productStr)){
// 设置读延期
redisUtils.expire(productCackeKey,genEmptyCacheTimeOut(), TimeUnit.SECONDS);
return null;
}
product = JSON.parseObject(productStr,Product.class);
redisUtil.expire(productCacheKey,genProductCacheTimeOut(),TimeUnit.SECONDS );
}
return product;
}
public Product getProduct(Long productId){
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
// 双重检测 DCL
sysnchronized(this){
// 双重检测,当缓存重建后,直接返回。
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
}
return product;
}
优化架构问题4:JVM锁与分布式锁
商品1 和商品2 的商品链接互不影响, 不需要相互加互斥锁,所以要优化为分布式锁。
public Product getProduct(Long productId){
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
// 双重检测 DCL
sysnchronized(this){
// 双重检测,当缓存重建后,直接返回。
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
}
return product;
}
优化分布式锁:
public static final String HOT_CACHE_PREFIX_LOCK = "hot_cache:lock";
public Product getProduct(Long productId){
Product product = null;
String productCacheKey = RedisKeyPrefixConst.PRODUCT_CACHE + productId;
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
// 双重检测 DCL
RLock redissonLock = redisson.getLock(HOT_CACHE_PREFIX_LOCK + productId);
redissonLock.lock(); // 用lua 脚本实现的setnx分布式锁
try{
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
} finally {
redissonLock.unlock();
}
return product;
}
优化架构问题5:缓存数据库双写不一致
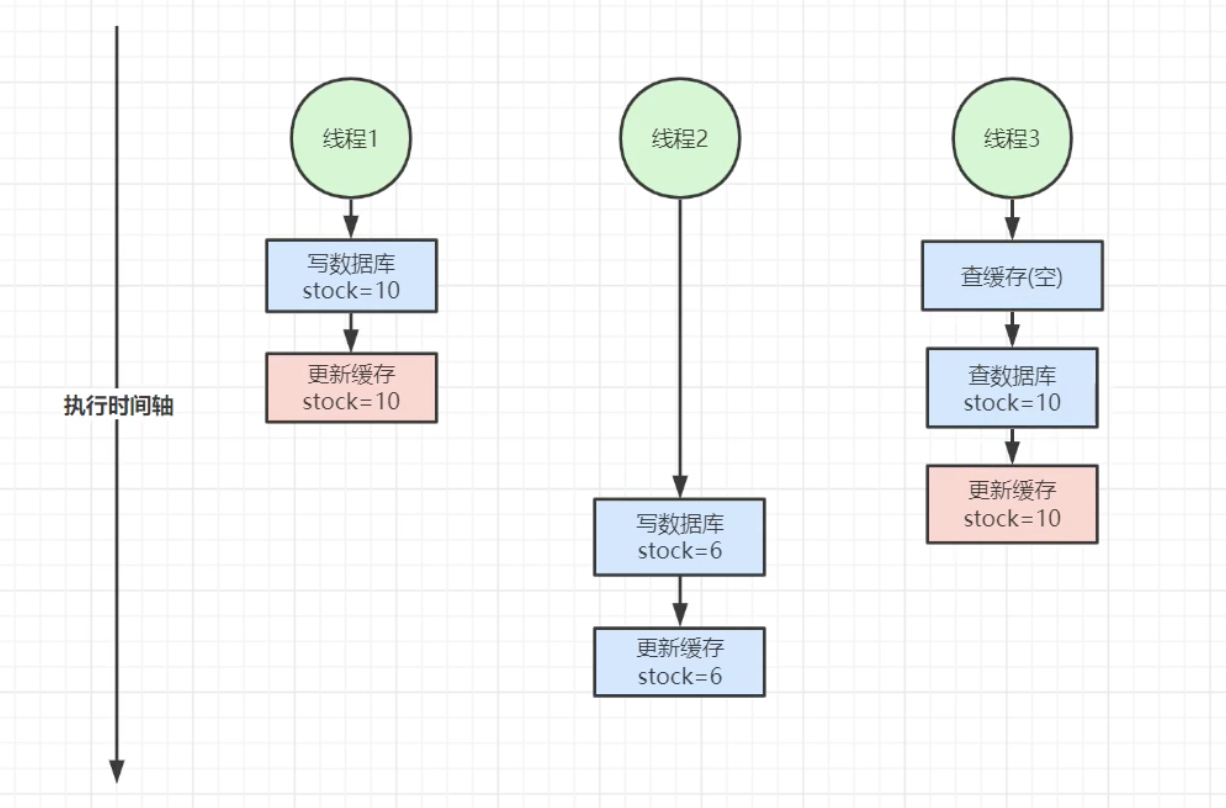
问题描述:
- 线程1写数据库product=10, -- 更新缓存为10.
- 线程2 --- --- --- --- 写数据库product=6,更新缓存6.
- 线程3--查缓存,为空。查数据库10, --- --- 更新缓存为10.
更新缓存和删除缓存是一样的问题。
public static final String UPDATE_PRODUCT_LOCK = "update_product:lock";
//getProduct 加锁
try{
product = getProductCache(productCacheKey);
if(product != null){
return product;
}
//加锁
RLock updateProductLock = redisson.getLock(UPDATE_PRODUCT_LOCK+productId);
updateProductLock.lock();
try{
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
} finally {
updateProductLock.unlock();
}
} finally {
redissonLock.unlock();
}
// update 加锁
@Transactional
public Product updateProduct(Product product){
Product productResult =null;
//与查询方法中的锁是同一把锁,互斥
RLock updateProductLock = redisson.getLock(UPDATE_PRODUCT_LOCK+productId);
updateProductLock.lock();
// 串行执行,没有并发安全问题
try{
productDao.updateProduct(product);
redisUtil.set(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(),JSON.toJSONString(productResult),genProductCacheTimeout(),TimeUnit.SECONDS);
} finally {
updateProductLock.unlock();
}
return productResult;
}
优化架构问题6:优化缓存数据库双写不一致下的分布式锁的优化
读写锁。读锁的时候是共享锁,并行执行。
// 读锁
//RLock updateProductLock = redisson.getLock(UPDATE_PRODUCT_LOCK+productId);
//updateProductLock.lock();
RReadWriteLock readWriteLock = redisson.getLock(UPDATE_PRODUCT_LOCK+productId);
RLock rLock = readWriteLock.readLock();
rLock.lock();
try{
product = productDao.get(productId);
if(product != null){
redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeOut(), TimeUnit.SECONDS);
} else {
// 设置空缓存
redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeOut(), TimeUnit.SECONDS);
}
} finally {
rLock.unlock();
}
同理,更新操作改为写锁,代码略。读写锁也是基于lua 脚本实现,
优化架构问题7:空发热点缓存环境下的分布式锁的优化
DCL 双重检测锁。
串行转并发思想
串行转并发:保证第一次线程在3s 内加锁完毕并且把逻辑走完,其他等待的几万的请求直接并行查缓存。
问题:假如第一个请求重建逻辑缓存需要4s,大量在等待的线程会在3s 的时候查缓存,此时缓存没有重建完成,会导致请求到数据库,相当于缓存失效。
// 原有DCL 的逻辑:
RLock redissonLock = redisson.getLock(""+productId);
redissonLock.lock();
优化为:
redissonnLock.tryLock(3, TimeUnit.SECONDS);
3s 后,假设有几万在等待的请求,则直接并行查缓存返回。
问题:假设第一个线程4s,大量数据会击穿缓存查数据库,又会导致数据库压力爆增。要提前想好,做好权衡。
做架构,要根据业务场景,选择更适合的技术。
系统逻辑增加,会不会也会导致系统变慢,那么加锁的意义又没意义了?
如果系统没有高并发的情况,可采用我们初始的代码。但在大型生产环境下,就会存在并发的问题。
代码逻辑增加,系统执行会有影响吗?
90% 的问题得到解决,不会请求到代码逻辑。10% 的性能用来处理小概率场景,高并发下的小概率场景是不允许出错的。
架构的设计思想:要根据具体的业务场景来设计技术架构。
优化架构问题8:商品大促环境下的缓存血崩
多级缓存架构。此时可以加一个JVM 进程级别的缓存
public static Map<String, Product> productMap = new ConcurrentHashMap();
private Product getProductCache(String productCacheKey){
// 1 先查jvm 进程级别的缓存,每秒可支持百万并发
Product product = productMap.get(productCacheKey);
if (null != product){
return product;
}
// 2 在查redis 缓存 ,redis 支持分片操作
String productStr = redisUtil.get(productCacheKey);
if(!StringUtils.isEmpty(productStr)){
// 如果查到缓存是我们设置的空缓存,则直接返回。
if(EMPTY_CACHE.equals(productStr)){
// 设置读延期
redisUtils.expire(productCackeKey,genEmptyCacheTimeOut(), TimeUnit.SECONDS);
return null;
}
product = JSON.parseObject(productStr,Product.class);
redisUtil.expire(productCacheKey,genProductCacheTimeOut(),TimeUnit.SECONDS );
}
return product;
}
// 更新redis 数据时,也要更新jvm 缓存
productMap.put(RedisKeyPrefixConst.PRODUCT_CACHE + productResult.getId(),product);
//问题1: 如果部署多台服务器,此时会导致jvm 缓存不一致
//问题2:map 越来越大,可能导致内存溢出。
解决了一个问题,创造了两个问题。那么这些问题该如何处理呢?
by:一只阿木木
生产级Redis 高并发分布式锁实战2:缓存架构设计问题优化的更多相关文章
- Redis高并发分布式锁详解
为什么需要分布式锁 1.为了解决Java共享内存模型带来的线程安全问题,我们可以通过加锁来保证资源访问的单一,如JVM内置锁synchronized,类级别的锁ReentrantLock. 2.但是随 ...
- Redis实现高并发分布式锁
分布式锁场景在分布式环境下多个操作需要以原子的方式执行首先启一个springboot项目,再引入redis依赖包: <!-- https://mvnrepository.com/artifa . ...
- Netty Redis 亿级流量 高并发 实战 (长文 修正版)
目录 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -30[ 博客园 总入口 ] 写在前面 1.1. 快速的能力提升,巨大的应用价值 1.1.1. 飞速提升能力,并且满足实际开发要求 1 ...
- 《Netty Zookeeper Redis 高并发实战》 图书简介
<Netty Zookeeper Redis 高并发实战> 图书简介 本书为 高并发社群 -- 疯狂创客圈 倾力编著, 高度剖析底层原理,深度解读面试难题 疯狂创客圈 Java 高并发[ ...
- Netty 100万级到亿级流量 高并发 仿微信 IM后台 开源项目实战
目录 写在前面 亿级流量IM的应用场景 十万级 单体IM 系统 高并发分布式IM系统架构 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -10[ 博客园 总入口 ] 写在前面 大家好 ...
- Redis实现高并发分布式序列号
使用Redis实现高并发分布式序列号生成服务 序列号的构成 为建立良好的数据治理方案,作数据掌握.分析.统计.商业智能等用途,业务数据的编码制定通常都会遵循一定的规则,一般来讲,都会有自己的编码规则和 ...
- 一般实现分布式锁都有哪些方式?使用redis如何设计分布式锁?使用zk来设计分布式锁可以吗?这两种分布式锁的实现方式哪种效率比较高?
#(1)redis分布式锁 官方叫做RedLock算法,是redis官方支持的分布式锁算法. 这个分布式锁有3个重要的考量点,互斥(只能有一个客户端获取锁),不能死锁,容错(大部分redis节点创建了 ...
- Redisson 分布式锁实战与 watch dog 机制解读
Redisson 分布式锁实战与 watch dog 机制解读 目录 Redisson 分布式锁实战与 watch dog 机制解读 背景 普通的 Redis 分布式锁的缺陷 Redisson 提供的 ...
- 一个Redis实现的分布式锁
import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.data.redis.conne ...
- redis客户端、分布式锁及数据一致性
Redis Java客户端有很多的开源产品比如Redission.Jedis.lettuce等. Jedis是Redis的Java实现的客户端,其API提供了比较全面的Redis命令的支持:Redis ...
随机推荐
- 从Java开发者到.NET Core初级工程师学习路线:C#语言基础
1. C#语言基础 1.1 C#语法概览 欢迎来到C#的世界!对于刚从Java转过来的开发者来说,你会发现C#和Java有很多相似之处,但C#也有其独特的魅力和强大之处.让我们一起来探索C#的基本语法 ...
- javaweb上传图片存到本地,并存储地址到数据库
前端使用layui的图片上传,将文件base64编码,然后在后端使用转码类来操作base64编码,并保存图片到本地,继而获取文件地址,将文件地址保存到数据库中 1.使用layui的图片上传 infos ...
- 关于UE5打包DLC
首先打开Project Lanucher,参考下图:,其次编辑配置两个edit Profile,参考下图: 第一个用来打包项目,第二个生成DLC,dlc填写的名字和插件一样,Main的配置如下: DL ...
- scratch源码下载 | 炮轰僵尸
程序说明: <炮轰僵尸>是一款基于Scratch平台制作的游戏程序,它采用了植物大战僵尸的经典场景.在游戏中,玩家需要控制一枚大炮来对抗不断入侵的僵尸.通过移动鼠标,玩家可以调整炮筒的方向 ...
- 国内外GPT哪家强?对比#ChatGPT #bard #豆包 #bing #百度文心 #星火 #通义千问
#ChatGPT(openAi) ChatGPT已经被错误调教,经常把作者和名字搞混. #豆包(字节跳动) 豆包拒绝错误调教 #百度文心(百度) #星火(科大讯飞) #通义千问 (阿里巴巴) #bar ...
- ansible 一键部署openstack (双节点)
1.三台虚拟机设置 ansible 内存 2GB 处理器 4 硬盘 40GB 光盘iso centos1804 网络适配器 仅主机模式 显示器 自动检测 controller 内存 5.3GB 处理器 ...
- ClickHouse的向量处理能力
ClickHouse的向量处理能力 引言 在过去,非结构化数据(如文本.图片.音频.视频)通常被认为难以在数据库中直接使用,因为这些数据类型的多样性和复杂性.然而,随着技术的发展,嵌入技术可以将非结构 ...
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-62 - 判断元素是否可操作
1.简介 有些页面元素的生命周期如同流星一闪,昙花一现.我们也不知道这个元素在没在页面中出现过,为了捕获这一美好瞬间,让其成为永恒.我们就来判断元素是否显示出现过. 在操作元素之前,可以先判断元素的状 ...
- 【Java】Main方法的命令行参数
可以使用命令行注入参数执行
- 【Tool】常用软件地址(装机备用)
浏览器: 360极速 https://browser.360.cn/ee/ 谷歌 https://www.google.cn/chrome/ 社交通讯 微信 https://weixin.qq.com ...