【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量
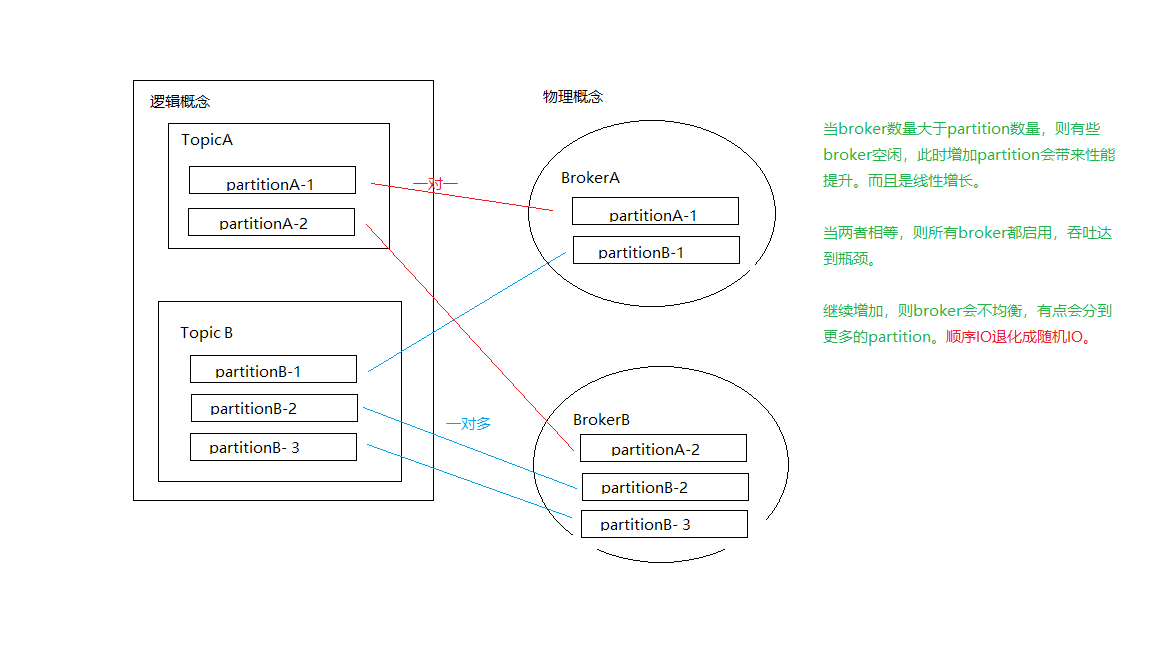
broker的数量最好大于等于partition数量
一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
一个broker如果对应多个partition,需要随机分发,顺序IO会退化成随机IO。
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
第一阶段:
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。
3个 Partition 时,同理会有3个 Broker 为该 Topic 服务。
第二阶段:
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
总结:
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
consumer数量最好和partition数量一致
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
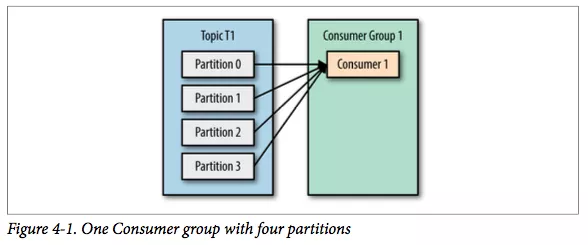
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。

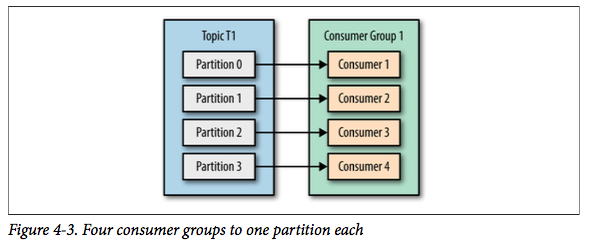
如果增加到 4 个消费者,那么每个消费者将会分别��到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
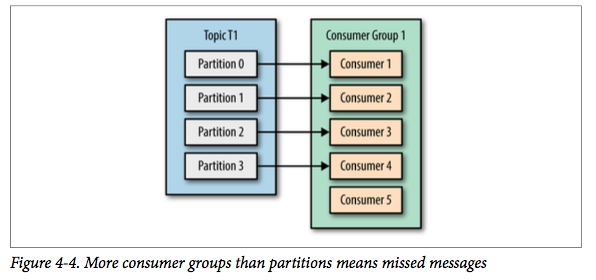
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。
这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
● 保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
● 解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
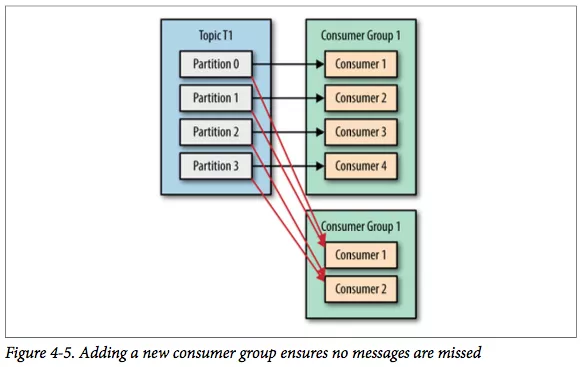
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
总结
如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
- broker的数量最好大于等于partition数量
- consumer数量最好和partition数量一致
【Kafka最佳实践】合理安排kafka的broker、partition、consumer数量的更多相关文章
- Kafka最佳实践
一.硬件考量 1.1.内存 不建议为kafka分配超过5g的heap,因为会消耗28-30g的文件系统缓存,而是考虑为kafka的读写预留充足的buffer.Buffer大小的快速计算方法是平均磁盘写 ...
- 【译】Kafka最佳实践 / Kafka Best Practices
本文来自于DataWorks Summit/Hadoop Summit上的<Apache Kafka最佳实践>分享,里面给出了很多关于Kafka的使用心得,非常值得一看,今推荐给大家. 硬 ...
- window下Kafka最佳实践
Kafka的介绍和入门请看这里kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 当前文章从实践的角度为大家规避window下使用的坑. 1.要求: java 6+ 2.下载kafka ...
- Apache Kafka: 优化部署的10个最佳实践
原文作者:Ben Bromhead 译者:江玮 原文地址:https://www.infoq.com/articles/apache-kafka-best-practices-to-opti ...
- 【kafka学习笔记】合理安排broker、partition、consumer数量
broker的数量最好大于等于partition数量 一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势. broker如果免得是多个partition,需要随机分发,顺序IO会退 ...
- 大规模使用 Apache Kafka 的20个最佳实践
必读 | 大规模使用 Apache Kafka 的20个最佳实践 配图来源:书籍<深入理解Kafka> Apache Kafka是一款流行的分布式数据流平台,它已经广泛地被诸如New Re ...
- Kafka在大型应用中的 20 项最佳实践
原标题:Kafka如何做到1秒处理1500万条消息? Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台).Uber.Square(移动支付公 ...
- Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践
Spring Boot 自定义kafka 消费者配置 ContainerFactory最佳实践 本篇博文主要提供一个在 SpringBoot 中自定义 kafka配置的实践,想象这样一个场景:你的系统 ...
- HP下kafka的实践
kafka 简介 Kafka 是一种高吞吐量的分布式发布订阅消息系统 kafka角色必知 producer:生产者. consumer:消费者. topic: 消息以topic为类别记录,Kafka将 ...
- Spark Streaming与kafka整合实践之WordCount
本次实践使用kafka console作为消息的生产者,Spark Streaming作为消息的消费者,具体实践代码如下 首先启动kafka server .\bin\windows\kafka-se ...
随机推荐
- CF877F Ann and Books (分类统计贡献+普通莫队)
CF877F Ann and Books 题意: 商店里有 \(n\) 本书,每本书中有 \(a_i\) 个 \(t_i=1/2\) 类问题. \(m\) 次询问,每次询问给出一个区间,求有多少个符合 ...
- kali 忘记账户密码
kali 忘记账户密码 重启 kali 虚拟机,在开始界面不需要选择,按 e 键 找到 Linux 开头的行,将 ro 处及该行后面的字符替换为:rw init=/bin/bash 按 F10 进入命 ...
- MinDoc 编译安装(linux环境)
目录 MinDoc 简介 项目地址: 下面以 Linux 系统为例: Gomod方式安装 下载项目代码到本地 写入依赖 下载依赖 创建数据库 配置数据库 编译main.go 提升文件权限 初使化数据库 ...
- JavaScript面向对象的继承应用
面向对象语言的三大特征:继承.封装.多态 <!DOCTYPE html> <html> <head> <title>Extend-OPP</tit ...
- Splashtop获5000万美元新投资 成为远程桌面行业独角兽
加利福尼亚州圣何塞,2021 年 1 月 27 日 - 下一代远程访问和远程支持领域的新兴领导者 Splashtop Inc. 完成了新一轮的 5000 万美元融资,其估值已超过了 10 亿美元的独角 ...
- 全面系统的AI学习路径,帮助普通人也能玩转AI
前言 现如今AI技术和应用的发展可谓是如火如荼,它们在各个领域都展现出了巨大的潜力和影响力.AI的出现对于我们这些普通人而言也是影响匪浅,比如说使用AI工具GPT来写文档查问题.使用AI辅助编程工具帮 ...
- 磁盘空间满了报错cannot create temp file for here-document: No space left on device
如下:虚拟机设置的存储空间是20G,.目前用到100%了.执行命令会报错设备没有空间 我想删除镜像释放空间,也无法操作 分级找到文件,但是不知道删除哪个 退出的容器都找不到了 把昨天下午弄的删了 容器 ...
- FFmpeg开发笔记(二十一)Windows环境给FFmpeg集成AVS3解码器
AVS3是中国AVS工作组制定的第三代音视频编解码技术标准,也是全球首个已推出的面向8K及5G产业应用的视频编码标准.AVS工作组于2019年3月9日完成第三代AVS视频标准(AVS3)基准档次的制 ...
- 解读注意力机制原理,教你使用Python实现深度学习模型
本文分享自华为云社区<使用Python实现深度学习模型:注意力机制(Attention)>,作者:Echo_Wish. 在深度学习的世界里,注意力机制(Attention Mechanis ...
- NOIP模拟90(多校23)
T1 回文 解题思路 原来 \(n^3\) 可以过 500 ... 先枚举一下路径长度,对于同一路径长度点数最多是 \(n\) 个,我们可以接着枚举从 \((n,m)\) 出发的路径长度相同的点. 然 ...