Google,Baidu,Bing三大搜素引擎图片爬虫
Google,Baidu,Bing三大搜素引擎图片爬虫
参考https://mp.weixin.qq.com/s/75QDjRTDCKzuM68L4fg5Lg
这个爬虫由ID为sczhengyabin的用户整理,看头像就知道不好惹。

可以按要求爬取百度、Bing、Google上的图片
项目地址https://github.com/sczhengyabin/Image-Downloader
项目背景
对于很多初⼊深度学习计算机视觉领域的朋友来说,当前开源资料⾮常多,但有时候难以适从,其中很多资料都没有包含完整的项⽬流程,⽽只是对某个流程的部分截取,对能⼒的锻炼不够。图像分类是整个计算机视觉领域中最基础的任务,也是最重要的任务之⼀,最适合拿来进⾏学习实践。为了让新⼿们能够⼀次性体验⼀个⼯业级别的图像分类任务的完整流程,本次我们选择带领⼤家完成⼀个对图片中⼈脸进⾏表情识别的任务。
⼈脸表情识别(facial expression recognition, FER)作为⼈脸识别技术中的⼀个重要组成部分,近年来在⼈机交互、安全、机器⼈制造、⾃动化、医疗、通信和驾驶领域得到了⼴泛的关注,成为学术界和⼯业界的研究热点,是⼈脸属性分析的重点。
数据获取
很多实际项⽬我们不会有现成的数据集,虽然可以通过开源数据集获取,但是我们还是要学会⾃⼰从零开始获取和整理。下⾯讲述如何准备好本次项⽬所需要的数据集,包括以下部分:
- 学会使⽤爬⾍爬取图像。
- 对获得的图⽚数据进⾏整理,包括重命名,格式统⼀。
2.1 数据爬取
由于没有直接对应的开源数据集,或者开源数据集中的数据⽐较少,尤其是对于嘟嘴,⼤笑等类的数据。搜索引擎上有海量数据,所以我们可以从中爬取。下⾯开始讲述具体的步骤,我们的任务是⼀个表情分类任务,因此需要爬取相关图⽚,包括嘟嘴(pout),微笑(smile),⼤笑(openmouth)、无表情(none)等表情。
当前有很多开源的爬虫项目,即使你不懂爬虫的知识,也能够很容易的爬取互联网的资源,下文整理了一些常见的爬虫项目,可以参考进行学习。
【杂谈】深度学习必备,各路免费爬虫一举拿下
本项目使用的爬虫项目是:https://github.com/sczhengyabin/Image-Downloader ,可以按要求爬取百度、Bing、Google 上的图片,提供了非常人性化的 GUI 方便操作,使用方法如下:
下载爬虫工具
使用
python image_downloader_gui.py调用GUI界面,配置好参数(关键词,路径,爬取数目等),关键词可以直接在这里输入也可以选择从txt文件中选择。可以配置需要爬取的样本数目,这里一次爬了2000张,妥妥的3分钟搞定。
该项目的 GUI 界面如下,我们尝试爬取“嘟嘴”的相关表情:
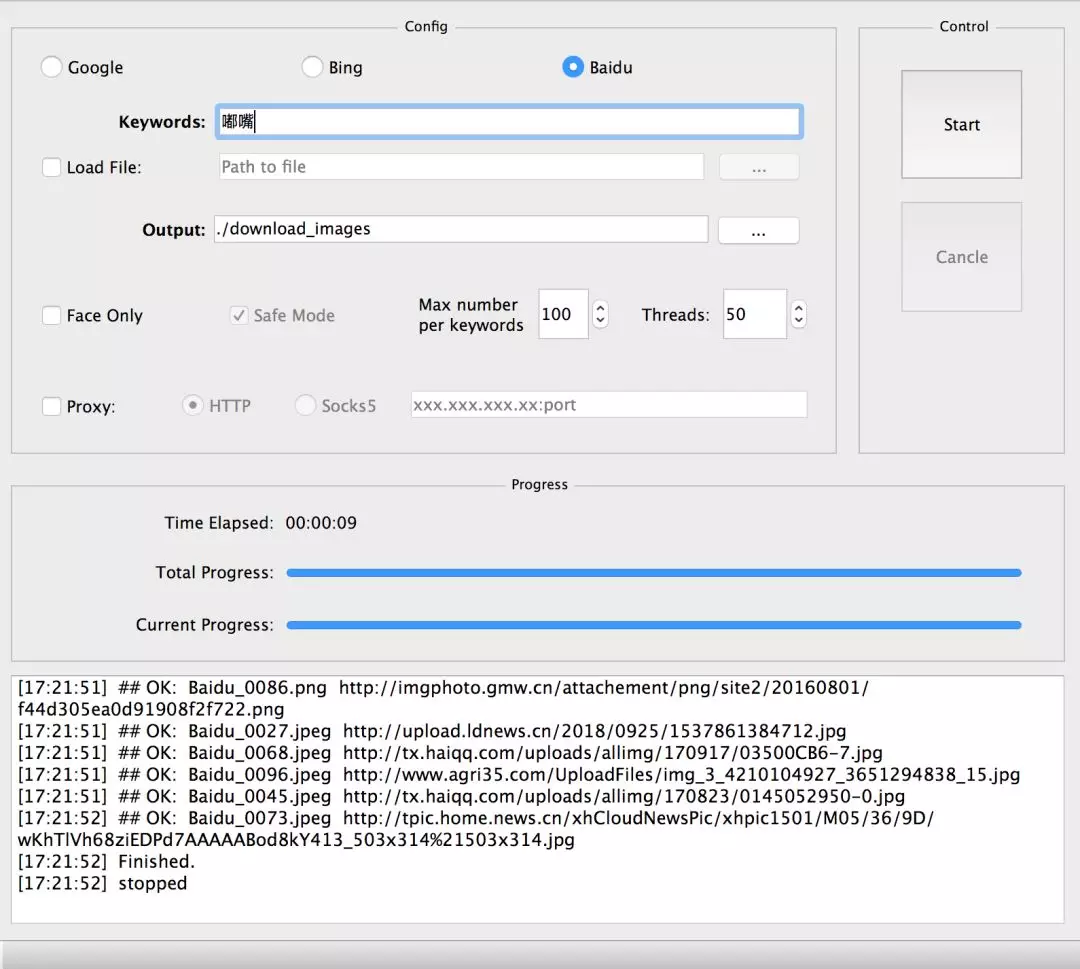
爬取图⽚结果如下:

⾃此就可以获得数千张图像
Google,Baidu,Bing三大搜素引擎图片爬虫的更多相关文章
- 开源搜素引擎:Lucene、Solr、Elasticsearch、Sphinx优劣势比较
https://blog.csdn.net/belalds/article/details/82667692 开源搜索引擎分类 1.Lucene系搜索引擎,java开发,包括: Lucene Solr ...
- 开源搜素引擎——Nutch
Nutch简介 Nutch 是一个开源Java实现的搜索引擎.它提供了我们运行自己的搜索引擎所需的全部工具.包括全文搜索和Web爬虫. Nutch 是一个开源Java 实现的搜索引擎.它提供了我们运行 ...
- Liunx操作指令搜素引擎
链接:http://wangchujiang.com/linux-command/c/vi.html
- haystack+Elasticsearch搜素引擎
搜索引擎原理 通过搜索引擎进行数据查询时,搜索引擎并不是直接在数据库中进行查询,而是搜索引擎会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据. 我们可以将索引结构数据想象成是字典书籍的索引 ...
- 公司官网百度搜素优化(www.curetech.cc)
1. 解读" 百度搜素引擎网页质量白皮书 " . 链接:https://pan.baidu.com/s/1fD7Cm93qsK01M0K1M1cIKw 提取码:9krx 2. ...
- Google 以图搜图 - 相似图片搜索原理 - Java实现
前阵子在阮一峰的博客上看到了这篇<相似图片搜索原理>博客,就有一种冲动要将这些原理实现出来了. Google "相似图片搜索":你可以用一张图片,搜索互联网上所有与它相 ...
- Google 以图搜图 - 相似图片搜索原理 - Java实现 (转)
前阵子在阮一峰的博客上看到了这篇<相似图片搜索原理>博客,就有一种冲动要将这些原理实现出来了. Google "相似图片搜索":你可以用一张图片,搜索互联网上所有与它相 ...
- HDU 1226 超级密码 (搜素)
题目地址:http://acm.hdu.edu.cn/showproblem.php?pid=1226 题意简单,本来是一道很简单的搜素题目. 但是有两个bug: 1.M个整数可能有重复的. 2.N可 ...
- [windows篇] 使用Hexo建立个人博客,自定义域名https加密,搜索引擎google,baidu,360收录
为了更好的阅读体验,欢迎阅读原文.原文链接在此. [windows篇] 使用Hexo建立个人博客,自定义域名https加密,搜索引擎google,baidu,360收录 Part 2: Using G ...
- ElasticSearch 实现分词全文检索 - 搜素关键字自动补全(Completion Suggest)
目录 ElasticSearch 实现分词全文检索 - 概述 ElasticSearch 实现分词全文检索 - ES.Kibana.IK安装 ElasticSearch 实现分词全文检索 - Rest ...
随机推荐
- Vue保持用户登录状态(各种token存储方式)
目录 怎么设置Cookie Cookie的缺点: LocalStorage与SessionStorage存储Token LocalStorage与SessionStorage的主要区别: Vuex存储 ...
- centos7或者centos8下安装google-chrome谷歌浏览器 亲测成功 20220302
第一步: wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm 第二步: 安装 Google ...
- 报表工具能用来做 DashBoard 和大屏吗?
我们首先来理一下 DashBoard.大屏和报表的关系. DashBoard 是指企业仪表盘,也叫管理者驾驶舱,通常被简称为 DBD.从表现形式上来看,DBD 由多个决策者关注的各类指标数据拼接而成, ...
- 论文研究区域图的制作方法:ArcGIS
本文介绍基于ArcMap软件,绘制论文中研究区域示意图.概况图等的方法. 最近需要绘制与地学有关论文.文献中的研究区域概况图.对于这一类图片,我个人比较喜欢基于ArcMap与PPT结合的方式来 ...
- 多python版本的库安装和导库
同时安装多python版本的,使用pip安装python的库,以及导出python库列表及版本,使用导出的库列表批量进行新环境的库安装. 1.同时安装python2和python3时,要进行pip安装 ...
- State 和 Props的理解以及区别
一.state 一个组件的显示形态可以由数据状态和外部参数所决定,而数据状态就是state,一般在 constructor 中初始化 当需要修改里面的值的状态需要通过调用setState来改变,从而达 ...
- 《Effective C#》系列之(四)——最小化内存泄露和资源占用
一.内存泄露 在<Effective C#>这本书中,最小化资源泄漏是其中一章的内容.以下是该章节的一些核心建议,以及使用C#代码示例说明: 及时释放非托管资源:在使用非托管资源时,需要手 ...
- EMR StarRocks 极速数据湖分析原理解析
简介:数据湖概念日益火热,本文由阿里云开源大数据 OLAP 团队和 StarRocks 数据湖分析团队共同为大家介绍" StarRocks 极速数据湖分析 "背后的原理. [首月9 ...
- 用手机写代码:基于 Serverless 的在线编程能力探索
简介:Serverless 架构的按量付费模式,可以在保证在线编程功能性能的前提下,进一步降低成本.本文将会以阿里云函数计算为例,通过 Serverless 架构实现一个 Python 语言的在线编 ...
- Inclavare Containers:云原生机密计算的未来
简介:本文为你详细的梳理一次 Inclavare Containers 项目的发展脉络,解读它的核心思想和创新技术. 作为业界首个面向机密计算场景的开源容器运行时,Inclavare Conta ...