jdk8-stream-api
1.stream简介
stream 是一个用来处理集合个数组的api
jdk 8 引入strream的原因:1.去掉for循环,使编程变的更加简单(实际运行效率可能没有for循环高)2.parallel,多核友好,java函数式编程使得编写并行程序如此简单,你需要的仅仅是调用一下parallel()方法
stream的特性: 1.不是数据结构,没有内存存储 2.不支持索引(没有数据,类似于spark中的RDD,只是搭建计算框架,在最后执行时才执行整个流程) 3.延迟计算 4.支持并行 5.很容易生成数组和集合 6.支持过滤查找转化等多种操作
2.Stream运行机制
Stream分为 源source,中间操作,终止操作 流的源可以是一个数组、一个集合、一个生成器方法,一个I/O通 道等等。 一个流可以有零个和或者多个中间操作,每一个中间操作都会返回 一个新的流,供下一个操作使用。一个流只会有一个终止操作 Stream只有遇到终止操作,它的源才开始执行遍历操作
3.Stream的创建
1、通过数组 2、通过集合来 3、通过Stream.generate方法来创建 4、通过Stream.iterate方法来创建 5、其他API创建
创建stream对象,of 方法中,参数为:(T... ..values) 可看做是一个多个同种类型对象组成的集合,forEach()方法,参数为:(Consumer<? super T>action),即一个Consumer接口,泛型为调用Stream中所装载的对象的父类或者自己,比如下面,调用对象为Stream<Student>,泛型为它的父类Teacher
public static void common_fileInputStream() throws IOException {
String[] arr = {"a", "b", "c", "d", "e", "f", "g", "h"};
Student stu = new Student("q");
Stream<String>stud=Stream.of(arr);
Stream<Student>student=Stream.of(stu,stu,stu,stu);/**1 of : (T... values)*/
Consumer<Teacher> consumer=new Consumer() {
@Override
public void accept(Object o) {
System.out.println("o = " + o);
}
};
student.forEach(consumer);/**参数:(Consumer<? super T> action)*/
// stud.forEach(consumer);
}
4.Stream常用API
中间操作: 过滤 filter 去重 distinct 排序 sorted 截取 limit、skip 转换 map/flatMap 其他 peek
终止操作: 循环 forEach 计算 min、max、count、 average 匹配 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny 汇聚 reduce 收集器 toArray collec
5.代码体现
1.创建Stream并遍历
List<String> list = Arrays.asList("string", "double", "int");
Stream<List> stream = Stream.of(list);
/**写法一*/
/*Consumer<List>consumer=new Consumer<List>() {
@Override
public void accept(List list) {
System.out.println("list = " + list);
}
};
stream.forEach(consumer);*/
// Consumer<List> consumer = (arr) -> System.out.println(arr);
/**写法二*/
stream.forEach((arr) -> System.out.println(arr));
/**写法三*/
Consumer<List> consumer = System.out::println;
/**函数式接口对应实例对象的方法的引用*/
//stream.forEach(System.out::println);
上述代码中,写法一为常规操作,写法二使用了通常的lanbad表达式,写法三中使用了实例对象引用方法的模式,无论哪种,都没有手动调用Consumer的默认方法accept方法,个人理解forEach中应该有对该方法的默认调用,并且在调用时传入了参数。
2.创建stream的方式
@Test
public void createStream(){
/**方法一,通过集合和数组创建*/
List<String>lis=new ArrayList<String>();
lis.add("a");lis.add("b");lis.add("c");
/**数组*/
List<String>lis1=Arrays.asList("a","b","c");
Stream<List>stream1=Stream.of(lis); /**方法二,通过generate方式创建*/
Stream<Integer>sin=Stream.generate(()->1);
/**这种创建的方式创建出来的流时无限的,需要limit做限制*/
sin.limit(3).forEach(System.out::println);
/**输出结果:1,1,1*/ /**方法三,使用迭代器方式创建*/
Stream<Integer>str=Stream.iterate(0,x->x+1);
str.limit(2).forEach(System.out::println);
/**創建方法4*/
String string="abc";
IntStream intStream=string.chars();
intStream.forEach(System.out::println);
/**輸出結果:97,98,99,即hashcode碼值*/ }
3.stream的几种常见用法组合
1排序,使用排序的时候需要注意排序的值为null的情况
@Test
public void streamCommonTest() {
/**排序功能*/
String arr[] = {"baierhu", "zhaowenb", "cheng", "2"};
Stream<String> str = Stream.of(arr);
//List list= str.sorted().collect(Collectors.toList());
//System.out.println("arrr = " + list);
/**输出结果:默认为字典排序:arrr = [2, baierhu, cheng, zhaowenb]*/ List list1=str.sorted(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
}).collect(Collectors.toList());
System.out.println(list1);
/**输出结果:按照长度排序*/ Student [] stu={new Student(1,"baierhu"),new Student(2,"zwen"),new Student(null,"aaa"),new Student(null,"chaochao")} ;
/**Stream.of(stu).sorted(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.getName().length()-o2.getName().length();
}
}).collect(Collectors.toList()).forEach(System.out::println);*/
// 输出结果:Student{id=2, name='zwen'}
//Student{id=1, name='baierhu'}
//Student{id=null, name='chaochao'} List<Student>lis=Stream.of(stu).sorted((a,b)->a.getName().length()-b.getName().length()).collect(Collectors.toList());
System.out.println("lis = " + lis); List<Student>lis111=Stream.of(stu).sorted((a,b)->{
if(a.getId()==null && b.getId()==null) return 0;
else if(a.getId()==null) return 0-b.getId();
else if(b.getId()==null) return a.getId()-0;
else return a.getId()-b.getId();}).collect(Collectors.toList());
System.out.println("lis111 = " + lis111);
/**输出:lis111 = [Student{id=null, name='aaa'}, Student{id=null, name='chaochao'}, Student{id=1, name='baierhu'}, Student{id=2, name='zwen'}]*/
}
2、build
@Test
public void buildTest(){
/**build,个人理解可以用add方法多添加几个东西至Stream*/
String arr[] = {"baierhu", "zhaowenb", "cheng", "2"};
Stream.Builder builder = Stream.builder().add(arr);
builder.build().forEach((a)->{
String aa[]=(String[])a;
System.out.println(Arrays.toString(aa));
});
}
/**输出:[baierhu, zhaowenb, cheng, 2]*/
3.filter 注意:方法二中可以在传入参数的时候带上参数类型,否则会默认将参数类型定为object类型
@Test
public void buildFilter(){
/**build,个人理解可以用add方法多添加几个东西至Stream*/
String arr[] = {"baierhu", "zhaowenb", "cheng", "2"};
Stream<String> builder = Stream.of(arr);
Predicate<String>pr=new Predicate<String>() {
@Override
public boolean test(String s) {
if(s.length()>4) return true;
return false;
}
};
/**方法一*/
List<String> aa=builder.filter(pr).collect(Collectors.toList());
System.out.println("ob = " + aa);
/**方法二,简单写法*/
List<String> bb=builder.filter((String a)->a.length()>5).collect(Collectors.toList());
System.out.println(bb);
}
/**输出:[baierhu, zhaowenb]*/
4.collect(mapping,joining,groupby) 收集
//创建数据
List<User> listUser = new ArrayList<>();
listUser.add(new User("李白", 20, true));
listUser.add(new User("杜甫", 40, true));
listUser.add(new User("李清照", 18, false));
listUser.add(new User("李商隐", 23, true));
listUser.add(new User("杜牧", 39, true));
listUser.add(new User("苏小妹", 16, false));
这个User就是一个普通的Bean对象,有name(姓名)、age(年龄)、gender(性别)三个属性及对应的set/get方法。
joining方法:
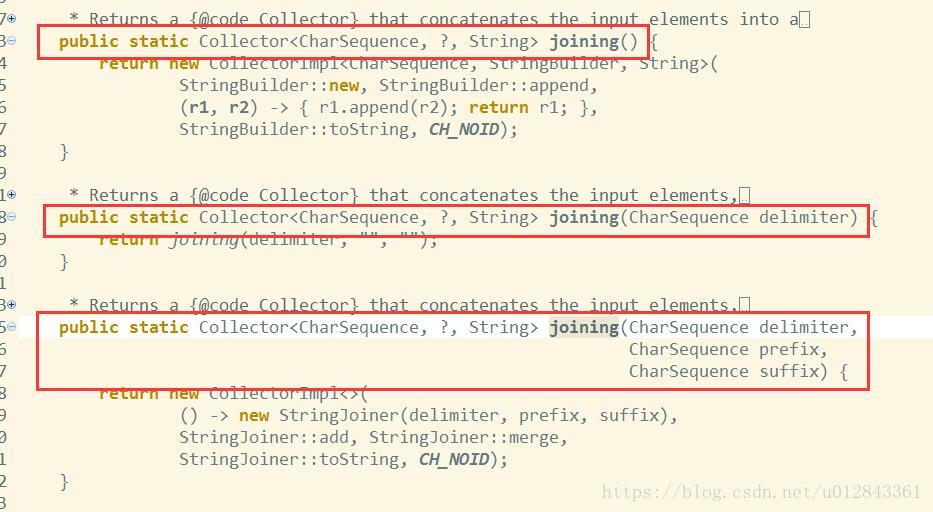
从 joining 方法的定义可以看到,这里重载了3个 joining 方法:无参数,1个参数,3个参数。然后从参数命名上看delimiter-分隔符、prefix-前缀、suffix-后缀大约可以猜出参数的作用了,然后再看注释的参数说明
Returns a {@code Collector} that concatenates the input elements,separated by the specified delimiter, with the specified prefix and suffix, in encounter order.
将指定的值join成字符串
String join1 = listUser.stream().map(User::getName).collect(Collectors.joining());
System.out.println("join后的结果:" + join1); // 输出==》 李白杜甫李清照李商隐杜牧苏小妹
将List中的用户名join成中间用","分隔的字符串
String join2 = listUser.stream().map(User::getName).collect(Collectors.joining(","));
System.out.println("join后的结果:" + join2); // 输出==》李白,杜甫,李清照,李商隐,杜牧,苏小妹
将List中的用户名join成以前缀是"{",后缀是"}",中间用","分隔的字符串
String join3 = listUser.stream().map(User::getName).collect(Collectors.joining(",", "{", "}"));
System.out.println("join后的结果:" + join3); // 输出==》{李白,杜甫,李清照,李商隐,杜牧,苏小妹}
mapping方法的定义如图

方法有2个参数,Function类型的mapper和Collector类型的downstream。通过注释可以看到方法是通过参数mapper函数来处理List中的每一个数据,然后用downstream来将处理后的数据收集起来。举例说明:
取出List中所有人的姓名放到一个新的List中去
// 定义一个入参为User,返回String的函数
Function<User,String> mapper=(user)->{
return user.getName();
};
List<String> userNames = listUser.stream().collect(Collectors.mapping(mapper, Collectors.toList()));
以上代码再简写一下:
List<String> userNames = listUser.stream().collect(Collectors.mapping((user)->{return user.getName();}, Collectors.toList()));
或者:
List<String> userNames = listUser.stream().collect(Collectors.mapping(User::getName, Collectors.toList()));
以上mapping 和joining转载于:https://blog.csdn.net/u012843361/article/details/83090199
group by
转载于:https://blog.csdn.net/u014231523/article/details/102535902
public Product(Long id, Integer num, BigDecimal price, String name, String category) {
this.id = id;
this.num = num;
this.price = price;
this.name = name;
this.category = category;
}
Product prod1 = new Product(1L, 1, new BigDecimal("15.5"), "面包", "零食");
Product prod2 = new Product(2L, 2, new BigDecimal("20"), "饼干", "零食");
Product prod3 = new Product(3L, 3, new BigDecimal("30"), "月饼", "零食");
Product prod4 = new Product(4L, 3, new BigDecimal("10"), "青岛啤酒", "啤酒");
Product prod5 = new Product(5L, 10, new BigDecimal("15"), "百威啤酒", "啤酒");
List<Product> prodList = Lists.newArrayList(prod1, prod2, prod3, prod4, prod5);
- 按照类目分组:
Map<String, List<Product>> prodMap= prodList.stream().collect(Collectors.groupingBy(Product::getCategory)); //{"啤酒":[{"category":"啤酒","id":4,"name":"青岛啤酒","num":3,"price":10},{"category":"啤酒","id":5,"name":"百威啤酒","num":10,"price":15}],"零食":[{"category":"零食","id":1,"name":"面包","num":1,"price":15.5},{"category":"零食","id":2,"name":"饼干","num":2,"price":20},{"category":"零食","id":3,"name":"月饼","num":3,"price":30}]}
- 按照几个属性拼接分组:
Map<String, List<Product>> prodMap = prodList.stream().collect(Collectors.groupingBy(item -> item.getCategory() + "_" + item.getName())); //{"零食_月饼":[{"category":"零食","id":3,"name":"月饼","num":3,"price":30}],"零食_面包":[{"category":"零食","id":1,"name":"面包","num":1,"price":15.5}],"啤酒_百威啤酒":[{"category":"啤酒","id":5,"name":"百威啤酒","num":10,"price":15}],"啤酒_青岛啤酒":[{"category":"啤酒","id":4,"name":"青岛啤酒","num":3,"price":10}],"零食_饼干":[{"category":"零食","id":2,"name":"饼干","num":2,"price":20}]} - 根据不同条件分组
Map<String, List<Product>> prodMap= prodList.stream().collect(Collectors.groupingBy(item -> {
if(item.getNum() < 3) {
return "3";
}else {
return "other";
}
})); //{"other":[{"category":"零食","id":3,"name":"月饼","num":3,"price":30},{"category":"啤酒","id":4,"name":"青岛啤酒","num":3,"price":10},{"category":"啤酒","id":5,"name":"百威啤酒","num":10,"price":15}],"3":[{"category":"零食","id":1,"name":"面包","num":1,"price":15.5},{"category":"零食","id":2,"name":"饼干","num":2,"price":20}]}多级分组
要实现多级分组,我们可以使用一个由双参数版本的Collectors.groupingBy工厂方法创 建的收集器,它除了普通的分类函数之外,还可以接受collector类型的第二个参数。那么要进 行二级分组的话,我们可以把一个内层groupingBy传递给外层groupingBy,并定义一个为流 中项目分类的二级标准。Map<String, Map<String, List<Product>>> prodMap= prodList.stream().collect(Collectors.groupingBy(Product::getCategory, Collectors.groupingBy(item -> {
if(item.getNum() < 3) {
return "3";
}else {
return "other";
}
}))); //{"啤酒":{"other":[{"category":"啤酒","id":4,"name":"青岛啤酒","num":3,"price":10},{"category":"啤酒","id":5,"name":"百威啤酒","num":10,"price":15}]},"零食":{"other":[{"category":"零食","id":3,"name":"月饼","num":3,"price":30}],"3":[{"category":"零食","id":1,"name":"面包","num":1,"price":15.5},{"category":"零食","id":2,"name":"饼干","num":2,"price":20}]}}按子组收集数据
- 求总数
Map<String, Long> prodMap = prodList.stream().collect(Collectors.groupingBy(Product::getCategory, Collectors.counting())); //{"啤酒":2,"零食":3} - 求和
Map<String, Integer> prodMap = prodList.stream().collect(Collectors.groupingBy(Product::getCategory, Collectors.summingInt(Product::getNum))); //{"啤酒":13,"零食":6} - 把收集器的结果转换为另一种类型
Map<String, Product> prodMap = prodList.stream().collect(Collectors.groupingBy(Product::getCategory, Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Product::getNum)), Optional::get))); //{"啤酒":{"category":"啤酒","id":5,"name":"百威啤酒","num":10,"price":15},"零食":{"category":"零食","id":3,"name":"月饼","num":3,"price":30}} - 联合其他收集器
Map<String, Set<String>> prodMap = prodList.stream().collect(Collectors.groupingBy(Product::getCategory, Collectors.mapping(Product::getName, Collectors.toSet()))); //{"啤酒":["青岛啤酒","百威啤酒"],"零食":["面包","饼干","月饼"]}
map
转载于:https://zhangzw.com/posts/20191205.html
// 简单对象
@Accessors(chain = true) // 链式方法
@lombok.Data
class User {
private String id;
private String name;
}
然后有这样一个 List:
List<User> userList = Lists.newArrayList(
new User().setId("A").setName("张三"),
new User().setId("B").setName("李四"),
new User().setId("C").setName("王五")
);
我们希望转成 Map 的格式为:
A-> 张三
B-> 李四
C-> 王五
过去的做法(循环):
Map<String, String> map = new HashMap<>();
for (User user : userList) {
map.put(user.getId(), user.getName());
}
jdk 1.8
userList.stream().collect(Collectors.toMap(User::getId, User::getName));
当然,如果希望得到 Map 的 value 为对象本身时,可以这样写:
userList.stream().collect(Collectors.toMap(User::getId, t -> t));
或:
userList.stream().collect(Collectors.toMap(User::getId, Function.identity()));
关于 Collectors.toMap 方法
Collectors.toMap 有三个重载方法:
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction);
toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier);
参数含义分别是: keyMapper:Key 的映射函数 valueMapper:Value 的映射函数 mergeFunction:当 Key 冲突时,调用的合并方法 mapSupplier:Map 构造器,在需要返回特定的 Map 时使用
还是用上面的例子,如果 List 中 userId 有相同的,使用上面的写法会抛异常:
List<User> userList = Lists.newArrayList(
new User().setId("A").setName("张三"),
new User().setId("A").setName("李四"), // Key 相同
new User().setId("C").setName("王五")
);
userList.stream().collect(Collectors.toMap(User::getId, User::getName)); // 异常:
java.lang.IllegalStateException: Duplicate key 张三
at java.util.stream.Collectors.lambda$throwingMerger$114(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1245)
at java.util.stream.Collectors.lambda$toMap$172(Collectors.java:1320)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1374)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at Test.toMap(Test.java:17)
...
这时就需要调用第二个重载方法,传入合并函数,如:
userList.stream().collect(Collectors.toMap(User::getId, User::getName, (n1, n2) -> n1 + n2)); // 输出结果:
A-> 张三李四
C-> 王五
第四个参数(mapSupplier)用于自定义返回 Map 类型,比如我们希望返回的 Map 是根据 Key 排序的,可以使用如下写法:
List<User> userList = Lists.newArrayList(
new User().setId("B").setName("张三"),
new User().setId("A").setName("李四"),
new User().setId("C").setName("王五")
);
userList.stream().collect(
Collectors.toMap(User::getId, User::getName, (n1, n2) -> n1, TreeMap::new)
); // 输出结果:
A-> 李四
B-> 张三
C-> 王五
flatmap
List<Long> listFlatLong = listFlat.stream()
.flatMap(employees -> employees.stream())
.flatMapToLong(employee -> LongStream.of(employee.getId()))
.boxed()
.collect(Collectors.toList());
System.out.println("listFlatLong = " + listFlatLong);
当有双层时,比如List<List<>>或者List<Map<>>比较适合使用这种方式
如果使用的是map方法,返回的是[ ...['y', 'o', 'u', 'r'], ['n', 'a', 'm', 'e']]
如果使用的是flatMap方法,返回的是['y', 'o', 'u', 'r', 'n', 'a', 'm', 'e']
这是map和flatMap的区别
jdk8-stream-api的更多相关文章
- 十分钟学会Java8的lambda表达式和Stream API
01:前言一直在用JDK8 ,却从未用过Stream,为了对数组或集合进行一些排序.过滤或数据处理,只会写for循环或者foreach,这就是我曾经的一个写照. 刚开始写写是打基础,但写的多了,各种乏 ...
- Java8新特性之三:Stream API
Java8的两个重大改变,一个是Lambda表达式,另一个就是本节要讲的Stream API表达式.Stream 是Java8中处理集合的关键抽象概念,它可以对集合进行非常复杂的查找.过滤.筛选等操作 ...
- Java8的lambda表达式和Stream API
一直在用JDK8 ,却从未用过Stream,为了对数组或集合进行一些排序.过滤或数据处理,只会写for循环或者foreach,这就是我曾经的一个写照. 刚开始写写是打基础,但写的多了,各种乏味,非过来 ...
- Java 8 Stream API
Java 8 Stream API JDK8 中有两大最为重要的改变.第一个是 Lambda 式:另外 Stream API(java.util.stream.*) Stream 是 JDK8 中处理 ...
- 试水jdk8 stream
jdk8出来日子不短了,jdk11都出来了,不过用的最多的不过是1.5罢了. 今年终于鼓起勇气认真对待它,在18年记录下学习stream,画上一个圆. 先看个图 Java8中有两大最为重要的改变.第一 ...
- Java8的Stream API使用
前言 这次想介绍一下Java Stream的API使用,最近在做一个新的项目,然后终于可以从老项目的祖传代码坑里跳出来了.项目用公司自己的框架搭建完成后,我就想着把JDK版本也升级一下吧(之前的项目, ...
- JDK8 Stream 数据流效率分析
JDK8 Stream 数据流效率分析 Stream 是Java SE 8类库中新增的关键抽象,它被定义于 java.util.stream (这个包里有若干流类型: Stream<T> ...
- JDK 8 新特性之函数式编程 → Stream API
开心一刻 今天和朋友们去K歌,看着这群年轻人一个个唱的贼嗨,不禁感慨道:年轻真好啊! 想到自己年轻的时候,那也是拿着麦克风不放的人 现在的我没那激情了,只喜欢坐在角落里,默默的听着他们唱,就连旁边的妹 ...
- 【Java 8】Stream API
转自 Java 8 Stream Java8的两个重大改变,一个是Lambda表达式,另一个就是本节要讲的Stream API表达式.Stream 是Java8中处理集合的关键抽象概念,它可以对集合进 ...
- Java 8 Stream API详解--转
原文地址:http://blog.csdn.net/chszs/article/details/47038607 Java 8 Stream API详解 一.Stream API介绍 Java8引入了 ...
随机推荐
- 获取SpringBoot中所有的url和其参数
获取所有url和方法的对应关系 1 @Data 2 public class Param { 3 4 /** 5 * 字段名称 6 */ 7 private String name; 8 9 /** ...
- redhat安装python3.7
下载并解压: 1 wget https://www.python.org/ftp/python/3.7.2/Python-3.7.2.tgz 2 tar -xzvf Python-3.7.2.tgz ...
- Ubuntu pip版本的安装,卸载,查看,更新
pip版本的安装: sudo apt-get install python3-pip pip版本的查看: pip3 --version pip3 -V pip更新: sudo pip3 install ...
- org.springframework.web.util.IntrospectorCleanupListener作用
回收那些不会主动回收,导致内存泄漏的垃圾,如javabeans
- 060_Cookie/Session
目录 会话 有状态会话 保存会话的两种技术 cookie session 常见场景 Cookie cookie细节 删除cookie Session 什么是session session使用场景 se ...
- Java程序员都要懂得知识点:反射
摘要:Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为java语 ...
- 移动端调试vConsole
当我们在进行移动端开发的时候,经常会出现在pc显示正常,在移动端却各种异常的情况.这时候我们在手机上又看不到error log. 所以我们就需要vConsole这样一个移动端开发神器. 那具体要怎么使 ...
- CMD控制台(命令提示符)的打开方式
打开CMD的方式 打开+系统+命令提示符 Win键 +R 输入cmd 打开控制台(推荐使用) 在任意的文件夹下面,按住shift键+鼠标右键点击+在此处打开命令行窗口 资源管理器的地址栏前面加上cmd ...
- 如何查看spark版本
使用spark-shell命令进入shell模式
- docker 容器重启策略
查看docker 容器重启策略 docker inspect 容器ID docker run -d --restart=always bba-208 docker run -d --restart=o ...