Sentry 监控 - Distributed Tracing 分布式跟踪

系列
- 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本
- 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps
- Sentry For React 完整接入详解
- Sentry For Vue 完整接入详解
- Sentry-CLI 使用详解
- Sentry Web 性能监控 - Web Vitals
- Sentry Web 性能监控 - Metrics
- Sentry Web 性能监控 - Trends
- Sentry Web 前端监控 - 最佳实践(官方教程)
- Sentry 后端监控 - 最佳实践(官方教程)
- Sentry 监控 - Discover 大数据查询分析引擎
- Sentry 监控 - Dashboards 数据可视化大屏
- Sentry 监控 - Environments 区分不同部署环境的事件数据
- Sentry 监控 - Security Policy 安全策略报告
- Sentry 监控 - Search 搜索查询实战
- Sentry 监控 - Alerts 告警
目录
- 什么是跟踪?
- 为什么要跟踪?
- 跟踪(Traces)、事务(Transactions和跨度(Spans)
- 示例:调查缓慢的页面加载
- 更多示例
- 跟踪数据模型
- 更多信息
- 数据采样
- 跟踪中的一致性
公众号:黑客下午茶
分布式跟踪(Distributed tracing)通过捕获软件系统之间的交互来提供相关错误和事务的连接视图。通过跟踪,Sentry 可以跟踪您的软件性能并显示跨多个系统的错误影响。 通过服务追溯问题将您的前端连接到您的后端。
启用性能监控以扩充您现有的错误数据,跟踪从前端到后端的交互。通过跟踪,Sentry 可以跟踪您的软件性能,测量吞吐量和延迟等指标,并显示跨多个系统的错误影响。跟踪使 Sentry 成为更完整的监控解决方案,帮助您更快地诊断问题并衡量应用程序的整体健康状况。Sentry 中的跟踪提供了以下见解:
- 特定错误事件或
issue发生了什么 - 导致应用程序出现瓶颈或延迟
issue的条件 - 消耗时间最多的端点或操作
什么是跟踪?
首先,请注意跟踪不是什么:跟踪不是分析。 尽管分析和跟踪的目标有相当多的重叠,虽然它们都可用于诊断应用程序中的问题,但它们在测量内容和数据记录方式方面有所不同。
profiler 可以测量应用程序操作的多个方面:执行的指令数、各种进程使用的内存量、给定函数调用所花费的时间量等等。生成的 profile 是这些测量值的统计汇总。
另一方面,tracing tool 关注发生了什么(以及何时),而不是发生了多少次或花费了多长时间。 结果跟踪(resulting trace)是在程序执行期间发生的事件日志,通常跨多个系统。 尽管跟踪最常见 - 或者,就 Sentry 的跟踪而言,总是 - 包括时间戳(timestamps),允许计算持续时间,但测量性能并不是它们的唯一目的。 它们还可以显示互连系统交互的方式,以及一个系统中的问题可能导致另一个系统出现问题的方式。
为什么要跟踪?
应用程序通常由互连的组件组成,这些组件也称为服务。 作为一个例子,让我们看一个现代 Web 应用程序,它由以下组件组成,由网络边界分隔:
Frontend (Single-Page Application)前端Backend (REST API)后端Task Queue任务队列Database Server数据库服务器Cron Job Scheduler定时任务调度器
这些组件中的每一个都可以在不同的平台上用不同的语言编写。每个都可以使用 Sentry SDK 单独检测以捕获错误数据或崩溃报告,但该检测不能提供完整的图片,因为每个部分都是单独考虑的。跟踪允许您将所有数据联系在一起。
在我们的示例 Web 应用程序中,跟踪意味着能够跟踪从前端到后端和后端的请求,从请求创建的任何后台任务(background tasks)或通知作业(notification jobs)中提取数据。这不仅可以让您关联 Sentry 错误报告,查看一个服务中的错误如何传播到另一个服务,而且还可以让您更深入地了解哪些服务可能对应用程序的整体性能产生负面影响。
在学习如何在您的应用程序中启用跟踪之前,了解一些关键术语以及它们之间的关系会有所帮助。
跟踪(Traces)、事务(Transactions和跨度(Spans)
trace 表示您要测量或跟踪的整个操作的记录 - 例如页面加载、用户在应用程序中完成某些操作的实例或后端的 cron job。 当跟踪包括多个服务中的工作时,例如上面列出的服务,它被称为分布式跟踪,因为跟踪分布在这些服务中。
每个 trace 由一个或多个称为 transactions 的树状结构组成,其节点称为 spans。 在大多数情况下,每个 transaction 代表被调用服务的单个实例,并且该 transaction 中的每个 span 代表该服务执行单个工作单元,无论是调用该服务中的函数还是调用不同的服务。 这是一个示例跟踪,分解为事务(transactions)和跨度(spans):

由于事务(transaction)具有树结构,因此顶级跨度(top-level spans)本身可以分解为更小的跨度(smaller spans),这反映了一个函数可能调用许多其他更小的函数的方式; 这是使用父子隐喻来表达的,因此每个跨度都可能是多个其他子跨度的父跨度。 此外,由于所有树都必须有一个根,因此每个事务中的一个跨度始终代表事务本身,而事务中的所有其他跨度都从该根跨度下降。这是上图中事务之一的放大视图:
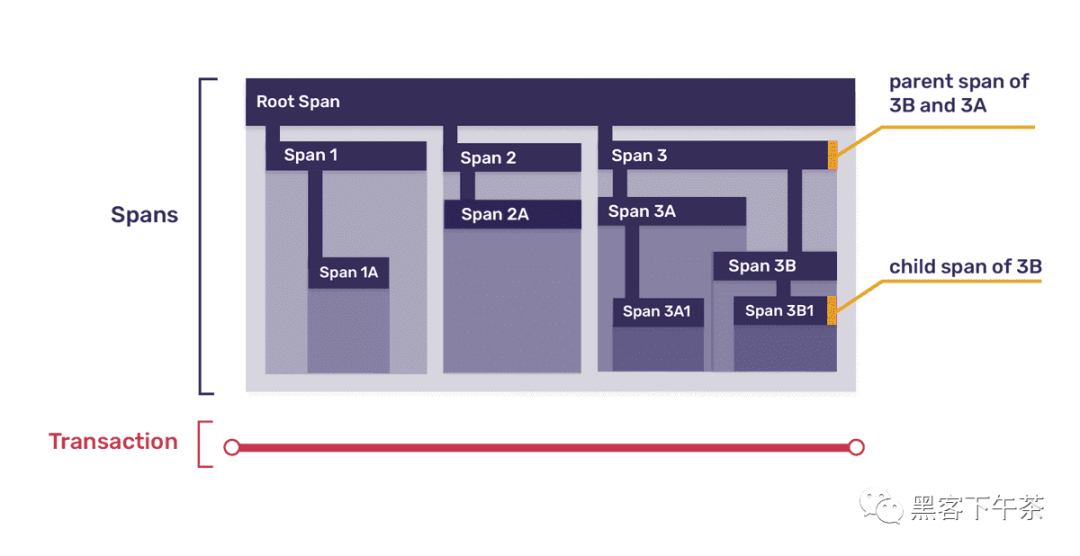
为了使所有这些更具体,让我们再次考虑我们的示例 Web 应用程序。
示例:调查缓慢的页面加载
假设您的 Web 应用程序加载缓慢,您想知道原因。 要使您的应用程序首先进入可用状态,必须发生很多事情:对后端的多个请求,可能是一些工作 - 包括对数据库或外部 API 的调用 - 在返回响应之前完成,并由浏览器处理以呈现所有 将返回的数据转化为对用户有意义的内容。那么这个过程的哪一部分会减慢速度?
假设在这个简化的示例中,当用户在浏览器中加载应用程序时,每个服务中都会发生以下情况:
Browser(浏览器)HTML、CSS和JavaScript各1个请求1次渲染任务,触发2次JSON数据请求 ^
Backend(后端)3个提供静态文件(HTML、CSS和JS)的请求2个JSON数据请求 -1个需要调用数据库 -1个需要调用外部API并在将结果返回到前端之前处理结果^
Database Server(数据库服务器)1个请求需要2次查询1查询以检查身份验证1查询获取数据
注意:外部 API 并未准确列出,因为它是外部的,因此您看不到它的内部。
在此示例中,整个页面加载过程(包括上述所有过程)由单个 trace 表示。 该跟踪将由以下事务(transactions)组成:
1个浏览器事务(用于页面加载)5个后端事务(每个请求一个)1个数据库服务器事务(用于单个DB请求)
每个事务将被分解为跨度(spans)如下:
- 浏览器页面加载事务:
7个span1个根span代表整个页面加载HTML、CSS和JS请求各1个(共3个)- 渲染任务的
1个span,它本身包含2个子span,每个JSON请求一个
让我们在这里暂停一下以说明一个重点:此处列出的浏览器事务中的一些(尽管不是全部)跨度与前面列出的后端事务有直接对应关系。 具体来说,浏览器事务中的每个请求跨度对应于后端中的一个单独的请求事务。 在这种情况下,当一个服务中的跨度引起后续服务中的事务时,我们将原始跨度称为事务及其根跨度的父跨度。在下图中,波浪线代表这种父子关系。
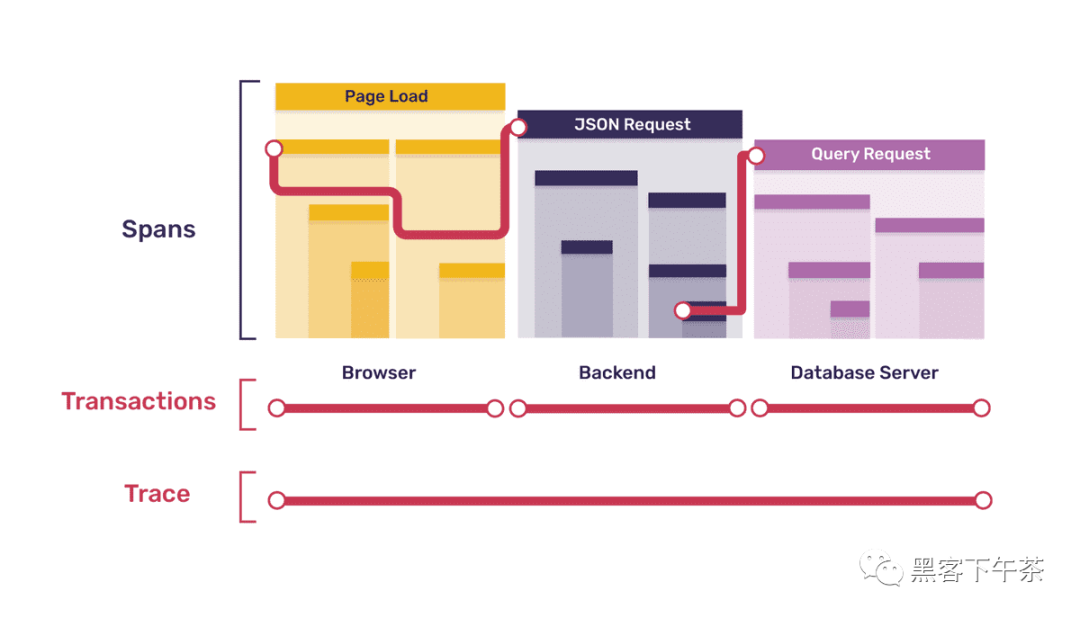
在我们的示例中,除了初始浏览器页面加载事务之外的每个事务都是另一个服务中一个跨度的子项,这意味着除了浏览器事务根之外的每个根跨度都有一个父跨度(尽管在不同的服务中)。
在 fully-instrumented 的系统(其中每个服务都启用了跟踪的系统)中,这种模式将始终适用。 唯一的无父 span 将是初始 transaction 的根;每隔一个 span 都会有一个父级。 此外,parents 和 children 将始终生活在同一个服务中,除非在子 span 是子 transaction 的根的情况下,在这种情况下,父 span 将在调用服务中,而子 transaction/child 根 span 将在被调用服务中。
换句话说,一个 fully-instrumented 的系统创建一个跟踪,它本身就是一个连接的树——每个事务都是一个子树——在这棵树中,子树/事务之间的边界正是服务之间的边界。上图显示了我们示例的完整跟踪树的一个分支。
现在,为了完整起见,回到我们的 spans:
- 后端 HTML/CSS/JS 请求事务:每个 1 个
span- 代表整个请求的 1 个根跨度(浏览器跨度的子项)^
- 带有数据库调用事务的后端请求:2 个
span- 1 个表示整个请求的根跨度(浏览器跨度的子项)
- 1 个跨度用于查询数据库(数据库服务器事务的父级)^
- 带有 API 调用事务的后端请求:3 个
span- 1 个表示整个请求的根跨度(浏览器跨度的子项)
- API 请求的 1 个跨度(与数据库调用不同,不是父跨度,因为 API 是外部的)
- 1 个跨度用于处理
API数据^
- 数据库服务器请求事务:3 个
span- 1 个代表整个请求的根跨度(上面后端跨度的子项)
- 1 跨度用于身份验证查询
- 1 个跨度用于查询检索数据的
总结一下这个例子:在检测了所有服务之后,您可能会发现——出于某种原因——是数据库服务器中的身份验证查询(auth query)导致了速度变慢,占了完成整个页面加载过程所需时间的一半以上。跟踪无法告诉你为什么会发生这种情况,但至少现在你知道该去哪里找了!
更多示例
本节包含更多跟踪示例,分为事务(transaction)和跨度(span)。
衡量特定的用户动作
如果您的应用程序涉及电子商务,您可能希望测量从用户单击“提交订单(Submit Order)”到订单确认出现之间的时间,包括跟踪向支付处理器提交费用和发送订单确认电子邮件。 整个过程是一个跟踪,通常您会有事务 (T) 和跨度 (S) 用于:
- 浏览器全过程(T 和根跨度 S)
- 对后端的
XHR请求* (S) - 渲染确认
screen(S)^
- 对后端的
- 您的后端对该请求的处理(T 和根跨度 S)
- 计算总数的函数(
Function)调用 (S) - 存储订单数据库(
DB)调用* (S) - 对支付处理器的
API调用 (S) - 电子邮件确认排队* (S) ^
- 计算总数的函数(
- 您的数据库更新客户订单历史的工作(T 和根跨度 S)
- 单个
SQL查询 (S) ^
- 单个
- 发送电子邮件的排队任务(T 和根跨度 S)
- 用于填充电子邮件模板的函数调用 (S)
- 对电子邮件发送服务的
API调用 (S)
注意:带星号的跨度表示作为后续事务(及其根跨度)的父跨度。
监控后台进程
如果您的后端定期轮询外部服务的数据,对其进行处理、缓存,然后将其转发给内部服务,则发生这种情况的每个实例都是一个跟踪,您通常会有以下事务 (T) 和跨度 (S):
- 完成整个过程的
cron job(T 和根跨度 S)API调用外部服务 (S)Processing函数 (S)- 调用缓存服务* (S)
- API 调用内部服务* (S) ^
- 在您的缓存服务中完成的工作(T 和根跨度 S)
- 检查现有数据的缓存 (S)
- 在缓存中存储新数据 (S) ^
- 您的内部服务对请求的处理(T 和根跨度 S)
- 服务可能为处理请求而做的任何事情 (S)
注意:带星号的跨度表示作为后续事务(及其根跨度)的父跨度。
跟踪数据模型
“给我看你的流程图而隐藏你的表,我仍然莫名其妙。如果给我看你的表,那么我将不再需要你的流程图,因为它们太明显了。”
Fred Brooks, 《The Mythical Man-Month》(人月神话)
虽然这个理论很有趣,但最终任何数据结构都是由它包含的数据类型定义的,数据结构之间的关系由它们之间的链接如何记录来定义。跟踪、事务和跨度也不例外。
Traces(跟踪)
Traces 本身并不是一个实体。相反,跟踪被定义为共享一个 trace_id 值的所有事务的集合。
Transactions(事务)
Transactions 与其根跨度共享其大部分属性(开始和结束时间、标签等),因此下面描述的跨度的相同选项在事务中可用,并且在任一位置设置它们是等效的。
Transactions 还有一个不包含在跨度中的附加属性,称为 transaction_name,它在 UI 中用于标识 transaction。transaction_name 值的常见示例包括后端请求事务的端点路径(如 /store/checkout/ 或 api/v2/users/<user_id>/)、cron job 事务的任务名称(如 data.cleanup.delete_inactive_users)和 URL( 像 https://docs.sentry.io/performance-monitoring/distributed-tracing/) 用于页面加载事务。
Spans(跨度)
transaction 中的大部分数据驻留在事务包含的单个 span 中。span 数据包括:
parent_span_id: 将span与其父span联系起来op: 标识跨度正在测量的操作类型或类别的短字符串start_timestamp:span打开时end_timestamp:span关闭时description:span操作的较长描述,唯一标识span,但跨span实例保持一致(可选)status: 指示操作状态的短code(可选)tags:key-value对保存有关跨度的附加数据(可选)data: 关于span的任意结构的附加数据(可选)
op 和 description 属性一起使用的示例是 op: sql.query 和 description: SELECT * FROM users WHERE last_active < %s。 status 属性通常用于指示 span 操作的成功或失败,或者在 HTTP 请求的情况下用于 response code。 最后,tags 和 data 允许您将更多上下文信息附加到 span,例如 function: middleware.auth.is_authenticated 用于函数调用或 request: {url: ..., headers: ... , body: ...} 用于 HTTP 请求。
更多信息
关于跟踪、事务和跨度以及它们相互关联的方式的一些更重要的点:
Trace Duration(跟踪持续时间)
因为 trace 只是 transaction 的集合,所以 trace 没有自己的开始和结束时间。 相反,trace 在其最早的 transaction 开始时开始,并在其最新的 transaction 结束时结束。 因此,您无法直接明确地开始或结束 trace。 相反,您通过在该 trace 中创建第一个 transaction 来创建 trace,并通过完成它包含的所有 transaction 来完成 trace。
Async Transactions(异步事务)
由于异步进程的可能性,子事务(child transaction)可能比包含其父跨度(parent span)的事务的寿命长很多数量级。例如,如果后端 API 调用启动了一个长时间运行的处理任务,然后立即返回响应,则后端事务将在异步任务事务完成之前很久完成(并且其数据将被发送到 Sentry)。异步性还意味着 transaction 发送到(和接收)Sentry 的顺序与创建它们的顺序没有任何关系。 (相比之下,同一 trace 中 transaction 的接收顺序与完成顺序相关,但由于传输时间的可变性等因素,相关性远非完美。)
Orphan Transactions(孤儿事务)
理论上,在一个 fully instrumented 的系统中,每个 trace 应该只包含一个 transaction 和一个 span(transaction的根),没有父项,即原始服务中的 transaction。但是,在实践中,您可能不会在每一项服务中都启用 trace,或者检测的服务可能由于网络中断或其他不可预见的情况而无法报告 transaction。发生这种情况时,您可能会在跟踪层次结构中看到间隙。 具体来说,您可能会在 span 的中途看到其父 span 尚未记录为任何已知 transaction 的一部分的 transaction。这种非发起、无父 transaction 被称为孤儿事务。
Nested Spans(嵌套跨度)
尽管我们上面的示例在其层次结构中有四个级别(跟踪trace、事务transaction、跨度span、子跨度child span),但跨度嵌套的深度没有设置限制。 但是,存在实际限制:发送到 Sentry 的事务有效负载具有最大允许大小,并且与任何类型的日志记录一样,需要在数据的粒度与其可用性之间取得平衡。
Zero-duration Spans(零持续时间跨度)
跨度可能具有相同的开始时间和结束时间,因此被记录为不占用时间。这可能是因为 span 被用作标记(例如在浏览器的 Performance API 中完成的),或者因为操作花费的时间少于测量分辨率(这将因服务而异)。
Clock Skew(时钟偏移)
如果您从多台机器收集 transaction,您可能会遇到 clock skew,其中一个 transaction 中的时间戳与另一个 transaction 中的时间戳不一致。 例如,如果您的后端进行数据库调用,则后端事务在逻辑上应该在数据库事务之前开始。 但是,如果每台机器(分别托管后端和数据库的机器)上的系统时间未同步到通用标准,则情况可能并非如此。 排序也有可能是正确的,但是两个记录的时间范围没有以准确反映实际发生的方式排列。为了减少这种可能性,我们建议使用网络时间协议 (NTP) 或您的云提供商的时钟同步服务。
如何发送数据
单个 span 不会发送到 Sentry; 相反,整个 transaction 作为一个单位发送。 这意味着 Sentry 的服务器不会记录任何 span 数据,直到它们所属的 transaction 被关闭和分派。 然而,反过来就不是这样了——尽管没有 transaction 就不能发送 span,但 transaction 仍然有效,并且会被发送,即使它们包含的唯一 span 是它们的根 span。
数据采样
当您在跟踪设置中启用采样时,您可以选择要发送到 Sentry 的已收集交易的百分比。例如,如果您有一个每分钟接收 1000 个请求的端点,0.25 的采样率将导致每分钟大约 250 个事务 (25%) 被发送到 Sentry。(这个数字是近似的,因为每个请求要么被跟踪,要么被独立和伪随机地跟踪,概率为 25%。因此,以同样的方式,100 个公平硬币,在翻转时会导致大约 50 个正面,SDK 将“决定” 在大约 250 个案例中收集跟踪。)因为您知道采样百分比,所以您可以推断您的总流量。
在收集跟踪时,我们建议对您的数据进行采样,原因有两个。 首先,虽然捕获单个跟踪的开销最小,但捕获每个页面加载或每个 API 请求的跟踪可能会给您的系统增加不希望的负载量。 其次,启用采样可以让您更好地管理发送到 Sentry 的事件数量,以便您可以根据组织的需求对其进行定制。
选择采样率时,目标是不要收集太多数据(鉴于上述原因),而是收集足够的数据,以便得出有意义的结论。如果您不确定要选择什么速率,我们建议从一个较低的值开始,并随着您对流量模式和流量的了解逐渐增加,直到找到一个速率,使您能够平衡性能和流量与数据准确性之间的关系。
跟踪中的一致性
对于涉及多个事务的跟踪,Sentry 使用 “基于头部(head-based)” 的方法:在原始服务中做出采样决策,然后将该决策传递给所有后续服务。要了解这是如何工作的,让我们回到上面的 webapp示例。考虑两个用户 A 和 B,他们都在各自的浏览器中加载应用程序。当 A 加载应用程序时,SDK 伪随机“决定”收集跟踪,而当 B 加载应用程序时,SDK “决定”不收集跟踪。当每个浏览器向您的后端发出请求时,它会在这些请求的标题中包含“yes, please collect transactions)”或“no, don't collect transactions this time”的决定。
当您的后端处理来自 A 浏览器的请求时,它会看到 “yes” 的决定,收集事务和跨度数据,并将其发送给 Sentry。此外,它在向后续服务(如您的数据库服务器)发出的任何请求中都包含“yes”决定,这些服务同样会收集数据,将数据发送给 Sentry,并将决定传递给它们调用的任何服务。通过这个过程,A的跟踪中的所有相关事务都被收集并发送到 Sentry。
另一方面,当您的后端处理来自 B 浏览器的请求时,它会看到 “no” 决定,因此它不会收集和发送事务和跨度数据到 Sentry。然而,它在将决策传播到后续服务方面做与在 A 的情况下所做的相同的事情,告诉他们也不要收集或发送数据。 然后他们又告诉他们调用的任何服务不要发送数据,这样就不会收集到来自 B 跟踪的事务。
简而言之:这种 head-based 的方法的结果是,决策在原始服务中作出一次,并传递给所有后续服务,要么收集给定跟踪的所有事务,要么不收集任何事务,因此不应存在任何不完整的跟踪。
公众号:黑客下午茶
Sentry 监控 - Distributed Tracing 分布式跟踪的更多相关文章
- Sentry 监控 - 全栈开发人员的分布式跟踪 101 系列教程(第一部分)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构简介(Kafka+Clickhouse)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构(Data Model 简介)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构(Query Processing 简介)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构(编写和测试 Snuba 查询)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构(SnQL 查询语言简介)
本文描述了 Snuba 查询语言 (SnQL). 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒 ...
- Sentry 监控 - Snuba 数据中台本地开发环境配置实战
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - 私有 Docker Compose 部署与故障排除详解
内容整理自官方开发文档 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Map ...
- 基于SkyWalking的分布式跟踪系统 - 微服务监控
上一篇文章我们搭建了基于SkyWalking分布式跟踪环境,今天聊聊使用SkyWalking监控我们的微服务(DUBBO) 服务案例 假设你有个订单微服务,包含以下组件 MySQL数据库分表分库(2台 ...
随机推荐
- linux下静态库的制作
在我们编写软件的过程当中,少不了需要使用别人的库函数.因为大家知道,软件是一个协作的工程.作为个人来讲,你不可能一个人完成所有的工作.另外,网络上一些优秀的开源库已经被业内广泛接受,我们也没有必要把 ...
- uwp 之语音朗读
xml code --------------------------------- <Page x:Class="MyApp.MainPage" xmlns="h ...
- Contos7 克隆实例 以及 配置网络-服务-等相关信息
以下为我自己整理的克隆虚拟机和设置固定IP的方法,记录一下,以防忘记: 桥接模式网络配置 1.配置ip地址等信息在文件里做如下配置: /etc/sysconfig/network-scripts/if ...
- 莫逸风CSDN文章目录
『Ⅱ』-----随笔 莫逸风CSDN文章目录 The Programmer's Oath程序员的誓言-- 今天突发奇想写了一个小工具,CSDN文章目录生成器 vue去掉一些烦人的校验规则 输入npm ...
- Spring第一课:配置文件及IOC引入(一)
Spring最核心的特点就是控制反转:(IOC)和面向切面(AOP) 首先作为一个Spring的项目需要导入的四个核心包,一个依赖: 四核心:core.context.beans.expression ...
- BeanUtils低依赖属性拷贝测试(一)
javabean package entity; import java.util.Date; /** * 一个测试用: * student,javaBean * @author mzy * 一个标准 ...
- Redis(一):安装
Ubuntu中使用yum安装redis: sudo apt-get install redis-server # 安装redis,安装完成后会自动启动 ps aux|grep redis # 查看进程 ...
- for in和for of的简单区别
//for in可以遍历数组和对象,但是for of只能遍历数组,不可以遍历对象 var arr = [1,4,5,6,7,8]; var obj = { name:'za', age:19, say ...
- vue 打开新窗口进行打印
父文件 let { href } = this.$router.resolve({ path: ' 自己配置本地路由,不需要动态路由 ', query: 个人建议传一整个对象 }) window.op ...
- 什么是云效持续集成?如何关联Jenkins进行持续集成?
什么是云效持续集成?如何关联Jenkins进行持续集成?云效流水线 Flow是一款企业级.自动化的研发交付流水线, 提供灵活易用的持续集成.持续验证. 持续发布功能,帮助企业高质量.高效率的交付业务. ...