kubernetes集群EFK日志系统搭建
日志收集架构
Kubernetes 集群本身不提供日志收集的解决方案,一般来说有主要的3种方案来做日志收集:
- 在节点上运行一个 agent 来收集日志
- 在 Pod 中包含一个 sidecar 容器来收集应用日志
- 直接在应用程序中将日志信息推送到采集后端
本文使用以下方案:
fluentd-->kafka-->logstash-->elasticsearch-->kibana
搭建 EFK 日志系统
elasticsearch安装使用集群外部环境
192.168.1.122 9200
kafka安装使用集群外部环境
192.168.1.122 9092
kubernetes集群创建名称空间
kubectl create namespace logging
fluentd安装
默认没有kafka插件
使用官方镜像安装:fluent-gem install fluent-plugin-kafka后,commit一下
创建configmap,添加fluentd配置文件
[root@k8s-master ~]# cat fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host 192.168.1.122
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
[root@k8s-master ~]#
注意:修改host 和port
部署fluentd
[root@k8s-master ~]# cat fluentd-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id elasticsearch
@type elasticsearch
@log_level info
include_tag_key true
host 192.168.1.122
port 9200
logstash_format true
request_timeout 30s
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
</match>
[root@k8s-master ~]# cat fluentd-daemonset.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- "namespaces"
- "pods"
verbs:
- "get"
- "watch"
- "list"
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd-es
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
subjects:
- kind: ServiceAccount
name: fluentd-es
namespace: logging
apiGroup: ""
roleRef:
kind: ClusterRole
name: fluentd-es
apiGroup: ""
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-es
namespace: logging
labels:
k8s-app: fluentd-es
version: v2.0.4
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
selector:
matchLabels:
k8s-app: fluentd-es
version: v2.0.4
template:
metadata:
labels:
k8s-app: fluentd-es
kubernetes.io/cluster-service: "true"
version: v2.0.4
# This annotation ensures that fluentd does not get evicted if the node
# supports critical pod annotation based priority scheme.
# Note that this does not guarantee admission on the nodes (#40573).
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
serviceAccountName: fluentd-es
containers:
- name: fluentd-es
image: cnych/fluentd-elasticsearch:v2.0.4
env:
- name: FLUENTD_ARGS
value: --no-supervisor -q
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-volume
mountPath: /etc/fluent/config.d
nodeSelector:
beta.kubernetes.io/fluentd-ds-ready: "true"
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-volume
configMap:
name: fluentd-config
[root@k8s-master ~]#
创建节点标签
[root@k8s-master ~]# kubectl label nodes k8s-master beta.kubernetes.io/fluentd-ds-ready=true
[root@k8s-master ~]# kubectl label nodes k8s-node1 beta.kubernetes.io/fluentd-ds-ready=true [root@k8s-master ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready master 45d v1.13.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/fluentd-ds-ready=true,beta.kubernetes.io/os=linux,kubernetes.io/hostname=k8s-master,node-role.kubernetes.io/master=
k8s-node1 Ready <none> 45d v1.13.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/fluentd-ds-ready=true,beta.kubernetes.io/os=linux,kubernetes.io/hostname=k8s-node1
[root@k8s-master ~]#
最后应用配置文件
kubectl apply -f fluentd-daemonset.yaml
查看pods情况
[root@k8s-master ~]# kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
fluentd-es-pjcpx 1/1 Running 0 72m
fluentd-es-x5bck 1/1 Running 0 72m
[root@k8s-master ~]#
最后就可以在kibana的dashboard上展示
如下过滤kubernetes集群入口ingressgateway日志信息
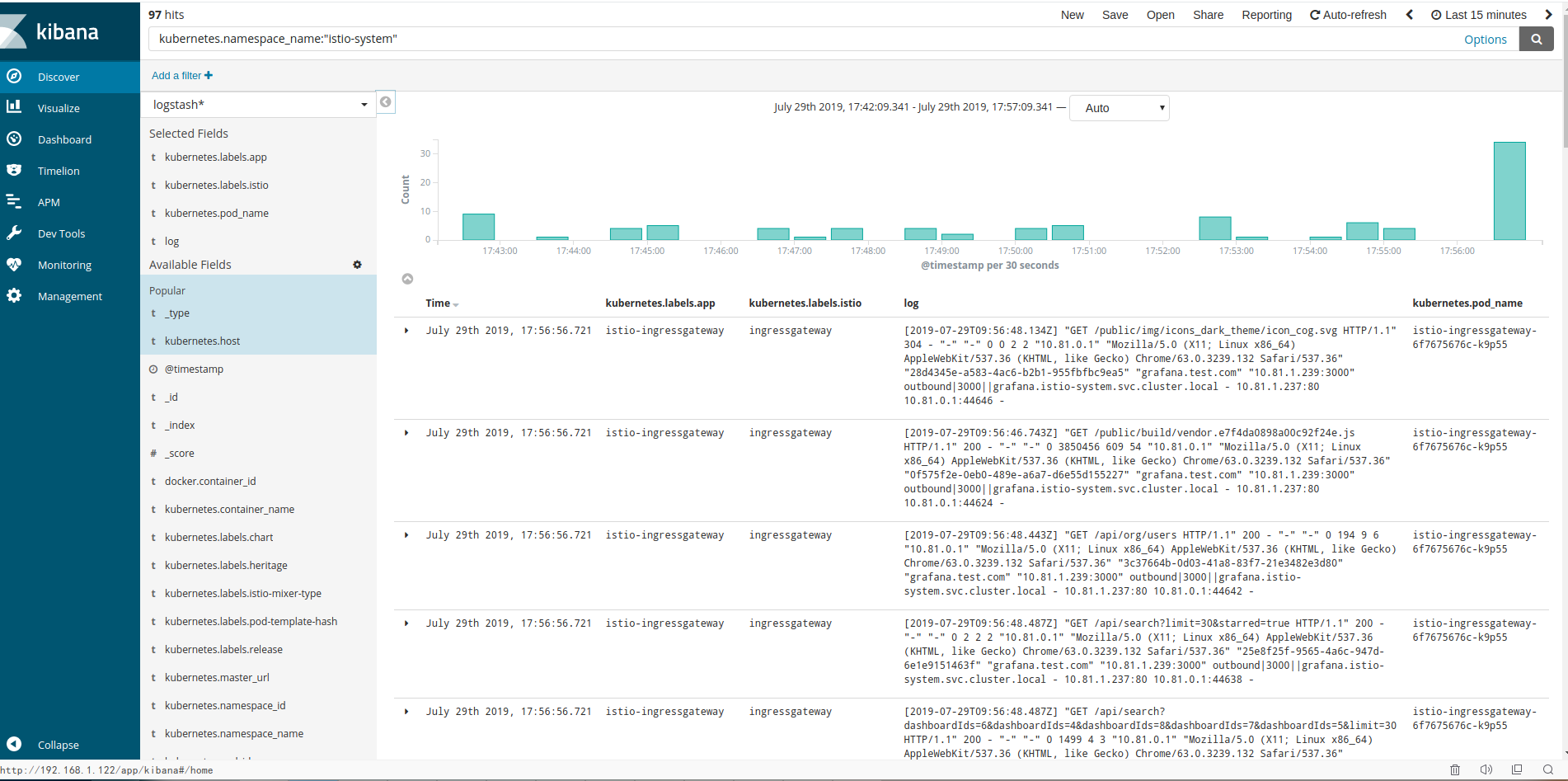
接入kafka收集日志
kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-config
namespace: logging
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
<system>
root_dir /tmp/fluentd-buffers/
</system>
containers.input.conf: |-
<source>
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
time_format %Y-%m-%dT%H:%M:%S.%NZ
localtime
tag raw.kubernetes.*
format json
read_from_head true
</source>
# Detect exceptions in the log output and forward them as one log entry.
<match raw.kubernetes.**>
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
</match>
system.input.conf: |-
# Logs from systemd-journal for interesting services.
<source>
@id journald-docker
@type systemd
filters [{ "_SYSTEMD_UNIT": "docker.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag docker
</source>
<source>
@id journald-kubelet
@type systemd
filters [{ "_SYSTEMD_UNIT": "kubelet.service" }]
<storage>
@type local
persistent true
</storage>
read_from_head true
tag kubelet
</source>
forward.input.conf: |-
# Takes the messages sent over TCP
<source>
@type forward
</source>
output.conf: |-
# Enriches records with Kubernetes metadata
<filter kubernetes.**>
@type kubernetes_metadata
</filter>
<match **>
@id kafka
@type kafka2
@log_level info
include_tag_key true
# list of seed brokers
brokers 192.168.1.122:9092
use_event_time true
# buffer settings
<buffer>
@type file
path /var/log/fluentd-buffers/kubernetes.system.buffer
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
default_topic messages
# producer settings
required_acks -1
compression_codec gzip
</match>
修改output使用kafka插件:https://docs.fluentd.org/output/kafka
brokers 192.168.1.122:9092
topic_key topic
default_topic messages
# producer settings
required_acks -1
compression_codec gzip
重启fluentd
[root@k8s-master ~]# kubectl get pods -n logging
NAME READY STATUS RESTARTS AGE
fluentd-es-mdsnz 1/1 Running 0 4d
fluentd-es-tc59t 1/1 Running 0 4d
[root@k8s-master ~]# kubectl logs -f fluentd-es-tc59t -n logging
2019-08-05 07:13:44 +0000 [info]: [kafka] brokers has been set: ["192.168.1.122:9092"]
2019-08-05 07:13:44 +0000 [warn]: parameter 'include_tag_key' in <match **>
@id kafka
@type kafka2
@log_level "info"
include_tag_key true
brokers 192.168.1.122:9092
use_event_time true
topic_key "topic"
default_topic "messages"
required_acks -1
compression_codec "gzip"
<buffer>
@type "file"
path "/var/log/fluentd-buffers/kubernetes.system.buffer"
flush_mode interval
retry_type exponential_backoff
flush_thread_count 2
flush_interval 5s
retry_forever
retry_max_interval 30
chunk_limit_size 2M
queue_limit_length 8
overflow_action block
</buffer>
<format>
@type "json"
</format>
</match> is not used.
2019-08-05 07:13:44 +0000 [info]: [kafka] initialized kafka producer: fluentd
启动成功后查看kafka里已经新生成了 messages的topic
在kafka上查看数据情况如下:
[root@dev-log-server kafka]# ./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic messages
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
{"log":"2019-08-05 07:40:31.966 [INFO][65] client.go 587: Update: api.Update{KVPair:model.KVPair{Key:model.BlockAffinityKey{CIDR:net.IPNet{IPNet:net.IPNet{IP:net.IP{0xa, 0x51, 0x1, 0x0}, Mask:net.IPMask{0xff, 0xff, 0xff, 0x0}}}, Host:\"k8s-node1\"}, Value:(*model.BlockAffinity)(0xc4207e94c0), Revision:\"512369\", TTL:0}, UpdateType:0x2}\n","stream":"stdout","docker":{"container_id":"49f48c1613be45a92ea1fc06efc6c2928347edf1c86a43432871ab8c5cfac323"},"kubernetes":{"container_name":"calico-node","namespace_name":"kube-system","pod_name":"calico-node-2srnw","pod_id":"23241398-8e80-11e9-8cc4-000c29a74c85","labels":{"controller-revision-hash":"99dc95f6f","k8s-app":"calico-node","pod-template-generation":"1"},"host":"k8s-node1","master_url":"https://10.96.0.1:443/api","namespace_id":"aac82294-8e7f-11e9-8cc4-000c29a74c85"}}
{"log":"2019-08-05 07:40:29.278 [INFO][63] ipsets.go 254: Resyncing ipsets with dataplane. family=\"inet\"\n","stream":"stdout","docker":{"container_id":"49f48c1613be45a92ea1fc06efc6c2928347edf1c86a43432871ab8c5cfac323"},"kubernetes":{"container_name":"calico-node","namespace_name":"kube-system","pod_name":"calico-node-2srnw","pod_id":"23241398-8e80-11e9-8cc4-000c29a74c85","labels":{"controller-revision-hash":"99dc95f6f","k8s-app":"calico-node","pod-template-generation":"1"},"host":"k8s-node1","master_url":"https://10.96.0.1:443/api","namespace_id":"aac82294-8e7f-11e9-8cc4-000c29a74c85"}}
{"log":"2019-08-05 07:40:31.137 [INFO][65] client.go 587: Update: api.Update{KVPair:model.KVPair{Key:model.ResourceKey{Name:\"k8s-node1\", Namespace:\"\", Kind:\"Node\"}, Value:(*v3.Node)(0xc4204d2000), Revision:\"512369\", TTL:0}, UpdateType:0x2}\n","stream":"stdout","docker":{"container_id":"49f48c1613be45a92ea1fc06efc6c2928347edf1c86a43432871ab8c5cfac323"},"kubernetes":{"container_name":"calico-node","namespace_name":"kube-system","pod_name":"calico-node-2srnw","pod_id":"23241398-8e80-11e9-8cc4-000c29a74c85","labels":{"controller-revision-hash":"99dc95f6f","k8s-app":"calico-node","pod-template-generation":"1"},"host":"k8s-node1","master_url":"https://10.96.0.1:443/api","namespace_id":"aac82294-8e7f-11e9-8cc4-000c29a74c85"}}
配置logstash
配置logstash消费messages日志写入elasticsearch
cat config/kafkaInput_fluentd.conf
input {
kafka {
bootstrap_servers => ["192.168.1.122:9092"]
client_id => "fluentd"
group_id => "fluentd"
consumer_threads => 1
auto_offset_reset => "latest"
topics => ["messages"]
}
} filter {
json{
source => "message"
} ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
ruby {
code => "event.set('find_time',event.get('@timestamp').time.localtime - 8*60*60)"
}
mutate {
remove_field => ["timestamp"]
remove_field => ["message"]
} }
output {
elasticsearch{
hosts => ["192.168.1.122:9200"]
index => "kubernetes_%{+YYYY_MM_dd}" }
# stdout {
# codec => rubydebug
# }
}
启动logstash
nohup ./bin/logstash -f config/kafkaInput_fluentd.conf --config.reload.automatic --path.data=/opt/logstash/data_fluentd 2>&1 > fluentd.log &
最终日志展示:
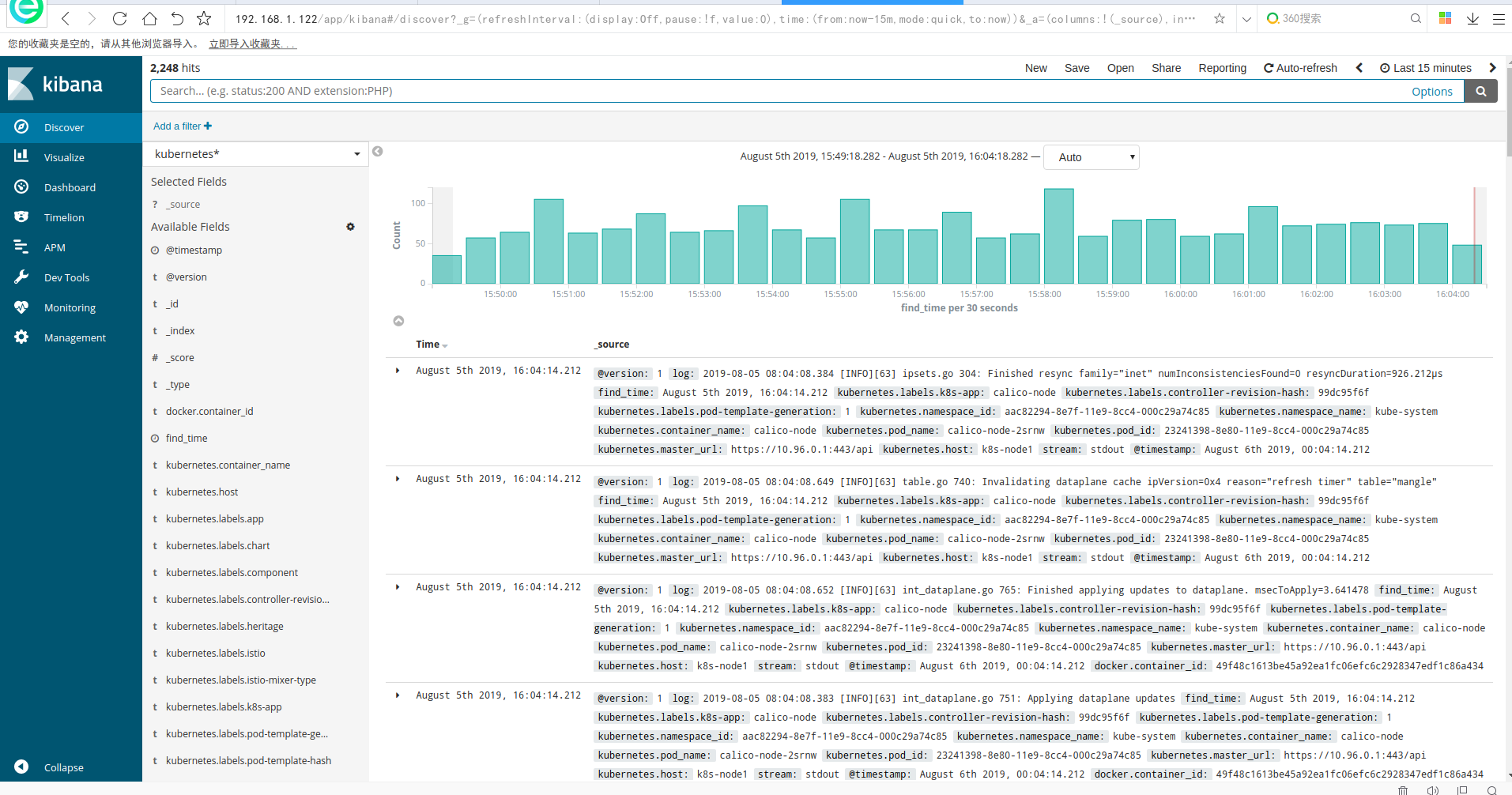
kubernetes集群EFK日志系统搭建的更多相关文章
- 谈一下Docker与Kubernetes集群的日志和日志管理
本文的测试环境为CentOS 7.3,Kubernetes集群为1.11.2,安装步骤参见kubeadm安装kubernetes V1.11.1 集群 日志对于我们管理Kubernetes集群及其上的 ...
- 高可用Kubernetes集群-15. 部署Kubernetes集群统一日志管理
参考文档: Github:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/fluentd-elasticsear ...
- Kubernetes 集群:规划与搭建
Kubernetes 集群环境: IP地址 主机名 角色 软硬件限制 192.168.119.134 master1 deploy ,master1 ,lb1 ,etcd (1) CPU至少1核,内存 ...
- Kubernetes 集群中使用 Helm 搭建 Spinnaker
在我们部署Spinnaker之前,我们需要一个YAML格式的配置文件,它会包含了一些配置信息.可以从Spinnaker Helm Chart repository[2]获得这个文件. $curl -L ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- Kubernetes 日志:搭建 EFK 日志系统
Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案. Elasticsearch 是一个 ...
- k8s-搭建 EFK 日志系统
搭建 EFK 日志系统 大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch.Fluentd 和 Kibana( ...
- Kubernetes集群
Kubernetes已经成为当下最火热的一门技术,未来一定也会有更好的发展,围绕着云原生的周边产物也越来越多,使得上云更加便利更加有意义,本文主要讲解一些蔚来汽车从传统应用落地到Kubernetes集 ...
- 基于kubernetes集群部署DashBoard
目录贴:Kubernetes学习系列 在之前一篇文章:Centos7部署Kubernetes集群,中已经搭建了基本的K8s集群,本文将在此基础之上继续搭建K8s DashBoard. 1.yaml文件 ...
随机推荐
- Java基本概念:封装
一.简介 描述: 生活中,我们要看电视,只需要按一下开关和换台就可以了.我们没有有必要了解电视机内部的结构. 制造厂家为了方便我们使用电视,把复杂的内部细节全部封装起来,只给我们暴露简单的接口,比如电 ...
- PAT-1132(Cut Integer )数的拆分+简单题
Cut Integer PAT-1132 #include<iostream> #include<cstring> #include<string> #includ ...
- Java 多线程 02
多线程·线程间通信 和 GUI 单例设计模式 * A:单例设计模式 * 保证类在内存中只有一个对象 * B:如何保证 * a:控制类的创建,不让其他类来创建泵类的对象,私有化构造方法 * b:在本类中 ...
- 在onBackPress中实现退出拦截时不生效
现象描述 在快应用中弹出一个弹窗,期望效果是该弹窗在用户确认后再退出,但是使用onbackpress控制确认弹窗后自动退出不生效. 问题分析 快应用引擎实现机制决定了onbackpress不能有耗时的 ...
- 靶场练习-Sqli-labs通关记录(1-4关)
0x00 实验环境 本地:Win 10 靶场:sqli-labs(共65关,每日一关) 0x02 通关记录 简介:一天一关! (1)第一关: 简单的 ...
- SQL驱动限制,导致插入失败
insert into TB_IF_ORDERS (DC_CD,JOB_DT,SEQ_NO,ORDER_KEY,ORDER_ID,ORDER_LINE_NUM,COMPANY_CD,CUST_CD,S ...
- 从一部电影史上的趣事了解 Spring 中的循环依赖问题
title: 从一部电影史上的趣事了解 Spring 中的循环依赖问题 date: 2021-03-10 updated: 2021-03-10 categories: Spring tags: Sp ...
- Everything is Serverless,从开源框架对比说起
摘要:Everything is Serverless. 在众多云计算解决方案中,Serverless 逐渐崭露头角,受到了很多关注并且发展迅猛,今天就关于serverless 开源框架细说二三. 什 ...
- java基础:数据类型拓展
public static void main(String[] args) { //单行注释 //输出hello,world! //System.out.println("hello,wo ...
- 【odoo14】第十三章、网站开发(对外服务)
本章我们将介绍一些关于odoo web服务方面的基础知识.进阶的内容,将在第十四章介绍. odoo中的web请求是由python的werkzeug库驱动的.odoo为了操作方便,对werkzeug进行 ...