Unity基础—Computer Shader
Computer Shader是什么?
Computer shader是一段运行在GPU上的一段程序。
什么时候用Computer shader?
假如我们把一个cube当作单独的点,用许多个(cube)点来组成一个变换矩阵。
每帧cpu都需要对矩阵的点进行排序,批处理,将每个点位置复制给GPU,URP每帧需要执行两次,DRP必须执行至少三遍。
当100*100个点时,也许我们的cpu可以轻松应对,但如果我们想组成分辨率更高的图形,1000 * 1000,一百万个点时,CPU和GPU的工作量会大大的增加,从而失去流畅的体验。
而CS就是通过将工作转移到GPU上,最大程度的减少CPU和GPU之前的通讯和数据传输量,从而提升渲染性能。总的来说,在需要高频的重复计算时,我们使用CS;
创建一个计算着色器
Assets/Creats/Shader/Computer Shader,创建一个CS文件
打开文件可以看到如下

//第一个红框中,声明了一个kernel,相当于main函数。在一个cs文件里可以定义多个不同的kernel方法
#pragma kernel CSMain
//第二个红框,定义前面声明的CSMain函数
void CSMain(uint3 id:SV DispatchThreadID){};
在CSMain函数上面的numthreads(8,8,1)]是什么?我们需要了解一下线程组和线程的概念
线程组、线程
当GPU执行CS时,会将其分成几个组(线程组),安排它们独立和并行运行。每个小组由多个线程组成。

最左边的是一个dispatch,由它决定分成几个线程组并行。如图所示,图中有3x2x3个thread groups(线程组)
中间的是一个thread group,由一个个线程组成,每个线程有自己的相对位置。图中有4x4x2个线程,在我们上文提到的numthreads(8,8,1)],表示设置每个线程组的线程数8x8x1个;
最右边的是单个线程。
需要注意的是,一个线程组中最大只支持1024个线程数
更近一步,看下图

上半张图是一个5x3x2的Dispatch,每个格子都代表着一个Thread Group
把坐标(2,1,0)的Thread Group打开,是一个10x8x3的Thread Group,每个格子里都是一个线程。
其中的几个概念:
SV_GroupThreadID:该线程在当前线程组中的坐标,如下半图中箭头指向坐标(7,5,0)
SV_GroupID:该线程所在线程组在Dispatch的坐标(2,1,0);
SV_DispatchThreadID:这是该线程全局唯一的ID,相当于在所有线程中该线程的坐标位置,算法为线程组大小*线程数大小+该线程坐标
SV_GroupIndex:该线程在该线程组中的索引,即线程在这个线程组中排在第几个位置;
我们可以利用这些ID,定位我们的结构化缓冲区。
了解了这些概念,接下来我们可以做一个案例。通过计算着色器做一个动态的波浪矩阵;
1.首先创建一个C#文件,我们需要先创建组成矩阵的点,我们用Cube代替。
点的位置信息我们先不管,因为我们要交给计算着色器来计算。
void Awake()
{
for (int i = 0; i < points.Length; i++) {
points[i]= Instantiate(prefab);
points[i].SetParent(transform);
}
}
2.接下来,我们需要一个缓冲区,用于给GPU计算的区域。通过new ComputeBuffer构造函数,第一个参数是我们要创建的缓冲区的长度,我们有一个矩阵的点 边长*边长的点的位置需要计算,所以我们第一个是resolution * resolution,第二个参数是每个点信息的内存大小,一个position是共有三个浮点数,所以是3 * 4个字节的大小;
positions = new ComputeBuffer(resolution*resolution,12);
分配了缓冲区,我们还需要在disable的时候将缓冲区释放
private void OnDisable()
{
positions.Release();
positions = null;
}
3.还需要定义一个数组,用于存储从GPU返回的位置信息。长度与我们的点数量是一样的
pointsArr = new Vector3[resolution * resolution];
Awake的代码就是这些
void Awake()
{
//位置缓冲区 在这里第一个参数是我们存放的矩阵点的数量
positions = new ComputeBuffer(resolution * resolution, 12);
//从GPU返回的位置信息
pointsArr = new Vector3[resolution * resolution];
//点的实例数组
points = new Transform[resolution * resolution];
//创建点;
for (int i = 0; i < points.Length; i++) {
points[i]= Instantiate(prefab);
points[i].SetParent(transform);
}
}
1.我们要GPU帮我们算出一个波浪矩阵的信息,那么总得给它传递一些信息数据才行。
要想要一个动态波浪的矩阵,随着Time时间变化,Time这个信息我们需要传过去。边长,只有知道了边长,GPU才知道我们的矩阵是什么构造,怎么波动。还需要给它把位置缓冲区传过去,毕竟它需要靠这个给我们返回计算结果。我们通过它们的标识符进行传递。
//获得着色器属性的存储标识符
static readonly int positionsId = Shader.PropertyToID("_Positions"),
resolutionId = Shader.PropertyToID("_Resolution"),
timeId = Shader.PropertyToID("_Time");
void Update()
{
float time = Time.time;
//给着色器传递当前时间
_ComputeShader.SetFloat(timeId, time);
//给着色器传递当前边长
_ComputeShader.SetInt(resolutionId, resolution);
//给着色器传递位置缓冲区
_ComputeShader.SetBuffer(kernel, positionsId, positions);
}
2.万事具备,开始分派线程组,执行内核函数。线程组的分派也有些门道,比如我们现在是8080的矩阵,6400个点。而我们的一个线程组设置的是[8,8,1],那就是88*1=64点;那么怎么说也得把让这些点有足够的线程数用。那就是6400/64=100个组。如果多了几个点,6500个点呢,那只能再把组数加上去。总之总组数,需要让点够用。但是也不能分配太多,否则会造成性能浪费。至于分配的组的形式,不管是[2,50,1],还是[100,1,1],怎么方便怎么分配;
//获取内核函数的索引
kernel = _ComputeShader.FindKernel("CSMain");
//分派线程组,执行内核函数
_ComputeShader.Dispatch(kernel, resolution/8, resolution/8, 1);
3.现在GPU并发执行了它的内核函数,但是我们怎么获取它计算的结果呢;我们通过GetData获取缓冲区的数据,并将它复制给你传进去的参数PointArr,我们开头定义的用来存储从GPU返回的位置信息的数组,最后根据返回的信息,将点位置进行更新即可
//从位置缓冲区获取结果 将结果复制给pointsArr
positions.GetData(pointsArr);
for (int i = 0; i < pointsArr.Length; i++)
{
//将各个点的位置更新
points[i].localPosition = pointsArr[i];
}
再看看计算着色器是怎么运作的
1.刚刚从C#,也就是CPU段传过来了哪些信息呢。时间_Time,边长_Resolution,位置缓冲区_Positions。我们需要用对应的变量存储起来。变量命名是和前面的标识符获取的属性名对应的;

RWStructuredBuffer <float3> _Positions;
float _Time;
uint _Resolution;
2.有了这些数据我们可以开始在内核函数内计算 需要的位置信息;[numthreads(8, 8, 1)],根据前面的概念解释,我们知道这是一个线程组的规格,也就是88的一个二维矩形为一个线程组。
我们通过一个id参数,后面加我们需要获取的类型SV_DispatchThreadID,获取到当前线程在所有线程中的三维坐标,因为我们是单个线程组和dispatch设置的都是二维坐标,所以呈现在我们面前的总线程应该是一个(线程组.xdispatch.x)(线程组.ydispath.y)的二维矩形。而我们的点矩阵被总线程二维的
包含。下图,我们假设线程组我设为[2,2,1],我们的边长是5,所以把dispath设为[3,3,1],即9个线程组,这样才可以完整覆盖我们所有需要计算的点。但是有一行和一列是我们矩阵不需要的点,所以我们把这一行一列除外。即做了一个判断,仅在id.x < _Resolution && id.y < _Resolution作为有效的点位置。
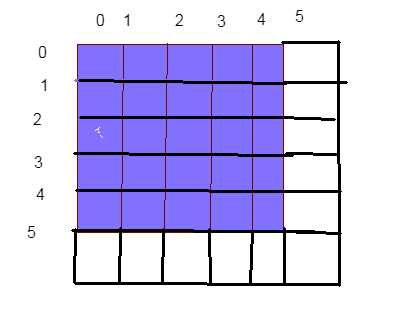

[numthreads(8, 8, 1)]
void CSMain(uint3 id : SV_DispatchThreadID)
{
//获取当前索引
uint index=id.x + id.y * _Resolution;
float3 position;
//获取的id.x
position.x = id.x;
position.z = id.y;
//根据x的位置和时间的变化,让y的位置变化起伏
position.y = sin(PI * (position.x/10 + _Time));
if (id.x < _Resolution && id.y < _Resolution) {
_Positions[index] = position;
}
}
效果图

C#完整代码
using UnityEngine;
public class WaveRect : MonoBehaviour
{
//绑定一个计算着色器
[SerializeField]
ComputeShader _ComputeShader = default;
//我们的cube实例
[SerializeField]
Transform prefab = default;
//定义矩阵边长 配置成可控制的范围10-100;
[SerializeField,Range(10,100)]
int resolution = 10;
//储存我们实例的数组
Transform[] points;
//定义结构化缓冲区 用于给计算着色器 计算我们需要的点 的位置
ComputeBuffer positions;
//获得着色器属性的存储标识符
static readonly int positionsId = Shader.PropertyToID("_Positions"),
resolutionId = Shader.PropertyToID("_Resolution"),
timeId = Shader.PropertyToID("_Time");
//存放由计算着色器也就是Gpu返回的点位置信息
private Vector3[] pointsArr;
void Awake()
{
//位置缓冲区 在这里第一个参数是我们存放的矩阵点的数量
positions = new ComputeBuffer(resolution * resolution, 12);
//从GPU返回的位置信息
pointsArr = new Vector3[resolution * resolution];
//点的实例数组
points = new Transform[resolution * resolution];
//创建点;
for (int i = 0; i < points.Length; i++) {
points[i]= Instantiate(prefab);
points[i].SetParent(transform);
}
}
int kernel;
void Update()
{
float time = Time.time;
//给着色器传递当前时间
_ComputeShader.SetFloat(timeId, time);
//给着色器传递当前边长
_ComputeShader.SetInt(resolutionId, resolution);
//给着色器传递位置缓冲区
_ComputeShader.SetBuffer(kernel, positionsId, positions);
kernel = _ComputeShader.FindKernel("CSMain");
//分派线程组,执行内核函数
int count = Mathf.CeilToInt(resolution / 8);
_ComputeShader.Dispatch(kernel, count, count, 1);
//从位置缓冲区获取结果 将结果复制给pointsArr
positions.GetData(pointsArr);
for (int i = 0; i < pointsArr.Length; i++)
{
//将各个点的位置更新
Debug.Log(i +"====="+ pointsArr[i]);
points[i].localPosition = pointsArr[i];
}
}
private void OnDisable()
{
positions.Release();
positions = null;
}
}
CS完整代码
// Each #kernel tells which function to compile; you can have many kernels
#pragma kernel CSMain;
#define PI 3.14159265358979323846
// Create a RenderTexture with enableRandomWrite flag and set it
// with cs.SetTexture
RWStructuredBuffer <float3> _Positions;
float _Time;
uint _Resolution;
[numthreads(8, 8, 1)]
void CSMain(uint3 id : SV_DispatchThreadID)
{
//获取当前索引
float3 position;
position.x = id.x;
position.z = id.y;
position.y = sin(PI * (position.x/10 + _Time));
if (id.x < _Resolution && id.y < _Resolution) {
_Positions[id.x + id.y * _Resolution] = position;
}
}
欢迎批评指正。原文博客http://xmxw.top/index.php/2021/04/19/unitybasic-computer-shader/;
Unity基础—Computer Shader的更多相关文章
- 【浅墨Unity3D Shader编程】之二 雪山飞狐篇:Unity的基本Shader框架写法&颜色、光照与材质
本系列文章由@浅墨_毛星云 出品,转载请注明出处. 文章链接:http://blog.csdn.net/poem_qianmo/article/details/40955607 作者:毛星云(浅墨) ...
- Unity基础6 Shadow Map 阴影实现
这篇实现来的有点墨迹,前前后后折腾零碎的时间折腾了半个月才才实现一个基本的shadow map流程,只能说是对原理理解更深刻一些,但离实际应用估计还需要做很多优化.这篇文章大致分析下shadow ma ...
- [译]Vulkan教程(13)图形管道基础之Shader模块
[译]Vulkan教程(13)图形管道基础之Shader模块 Shader modules Unlike earlier APIs, shader code in Vulkan has to be s ...
- unity之初识shader
自己做个总结先.当然文中很多内容都是从各位大神的文档当中看的.我只是站在巨人的肩膀上. 首先什么是shader?其实就是一个在显示屏当中的显示程序,俗称着色器.它可以定义物体在硬件显示屏当 ...
- 【unity shaders】:Unity中的Shader及其基本框架
shader和Material的基本关系 Shader(着色器)实际上就是一小段程序,它负责将输入的Mesh(网格)以指定的方式和输入的贴图或者颜色等组合作用,然后输出.绘图单元可以依据这个输出来将图 ...
- unity 基础之InputManager
unity 基础之InputManager 说一下unity中的InputManager,先截个图 其中Axes指的是有几个轴向!Size指的是有几个轴,改变Size可以添加或者减少轴! Name指 ...
- unity 基础学习 transform
unity 基础学习 transform 1.unity采用的是右手坐标系,X轴右手为+,Y轴向上为+,Z轴朝里为+; 但是我们从3D MAX中导入模型之后,发现轴向并没有遵从这个原理, 其实是 ...
- 【Unity Shaders】Shader学习资源和Surface Shader概述
写在前面 写这篇文章的时候,我断断续续学习Unity Shader半年了,其实还是个门外汉.我也能体会很多童鞋那种想要学好Shader却无从下手的感觉.在这个期间,我找到一些学习Shader的教程以及 ...
- Unity 基础
Unity 基础是unity入门的关键.他将讲解Unity的界面, 菜单项,使用资源,创设场景,并发布版本. 当你读完这段,你将理解unity是怎么工作的,如何有效地使用它,并且完成一个基本的游戏. ...
随机推荐
- 永远不要眼高手低,Vue完整实现一套简单的增删改查CURD操作
1: 永远不要眼高手低,看起来很简单,但是你从来没有去动手试一下,就不知道其中真正需要注意的许多细节, 2:完整code如下: 1 <!DOCTYPE html> 2 <html l ...
- Python爬虫系统化学习(3)
一般来说当我们爬取网页的整个源代码后,是需要对网页进行解析的. 正常的解析方法有三种 ①:正则匹配解析 ②:BeatuifulSoup解析 ③:lxml解析 正则匹配解析: 在之前的学习中,我们学习过 ...
- 高级FTP
一.作业需求 1. 用户加密认证(已完成) 2. 多用户同时登陆(已完成) 3. 每个用户有自己的家目录且只能访问自己的家目录(已完成) 4. 对用户进行磁盘配额.不同用户配额可不同(已完成) 5 ...
- 后端程序员之路 14、NumPy
NumPy - NumPyhttp://www.numpy.org/ NumPy-快速处理数据 - 用Python做科学计算http://old.sebug.net/paper/books/scipy ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- cat常用参数
cat 命令格式 cat [选项] [文件] -A, --show-all:等价于 -vET. -b --number-nonblank:和 -n 相似,只不过对于空白行不编号. -e:等价于&qu ...
- 【python+selenium的web自动化】- Selenium WebDriver原理及安装
简单介绍 selenium selenium是一个用于测试web网页的自动化测试工具,它直接运行在浏览器中,模拟用户的操作.
- 内省详解(Introspector/BeanInfo/MethodDescriptor/PropertyDescriptor)
内省(Introspector)概念 内省Introspector 是Java提供的操作 JavaBean 的 API,用来访问某个属性的 getter/setter 方法.对于一个标准的 Jav ...
- vue 仿zTree折叠树
需求: vue实现仿zTree折叠树,此文章仅作为记录文档. 实现: <template> <div class="line-tree"> <div ...
- 怎么理解onStart可见但不可交互
前言 今天朋友遇到一个面试题,分享给大家: onStart生命周期表示Activity可见,那为什么不能交互呢? 这个问题看似简单,但涉及到的面还是比较多的,比如Activity生命周期的理解,进程的 ...