Python实战:截图识别文字,过万使用量版本!(附源码!!)
前人栽树后人乘凉,以不造轮子为由
使用百度的图片识字功能,实现了一个上万次使用量的脚本。
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
完整代码下载:Baidu_Ocr.py-Python
一、获取百度智能云token
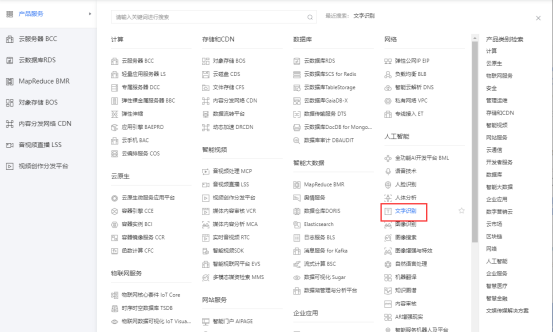
百度智能云登录后找到人工智能界面下的文字识别->管理界面创建应用文字识别。
创建应用完成后记录下,后台界面提供的AppID、API key、Secret Key的信息

接下来根据 官方提供的文档获取使用Token
# encoding:utf-8
import requests
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=wgEHks0l6MCpalbs3lPuFX1U&client_secret=Z4Rn4ghBx9k06fUYPmSEIRbCFvWFxLyQ'
response = requests.get(host)
if response:
print(response.json()['access_token'])

二、百度借口调用
使用获取后token调用百度接口对图片进行识别提取文字
# encoding:utf-8 import requests
import base64
'''
通用文字识别(高精度版)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('图片.png', 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
# 获取后的Token的调用
access_token = '24.0d99efe8a0454ffd8d620b632c58cccc.2592000.1639986425.282335-24065278'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
print (response.json())
获取后的token为json格式的数据

此处步骤我们可以看出识别后的文件是以json的格式返回的所以要想达到取出文字的效果就需要对json格式的返回值进行解析
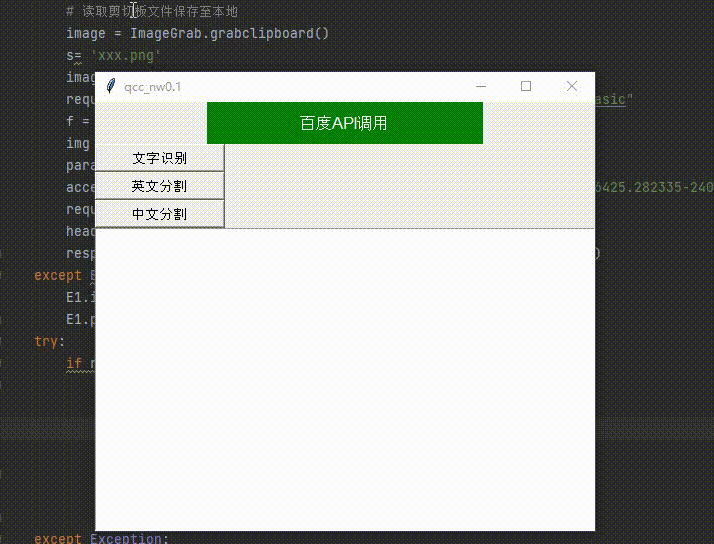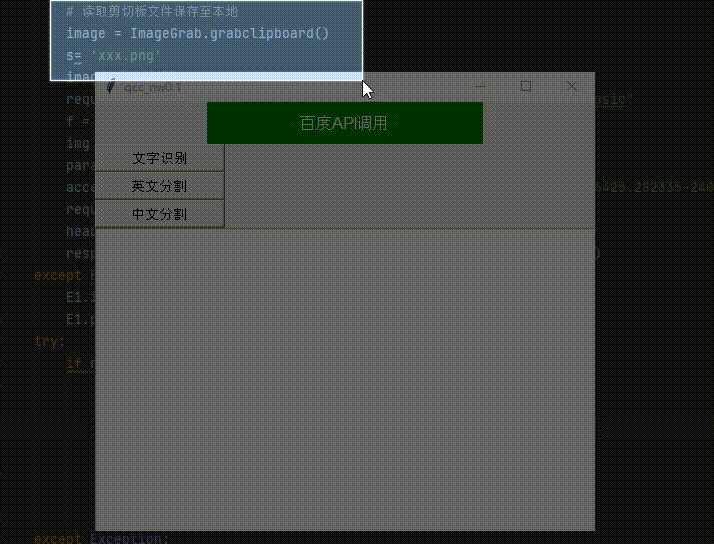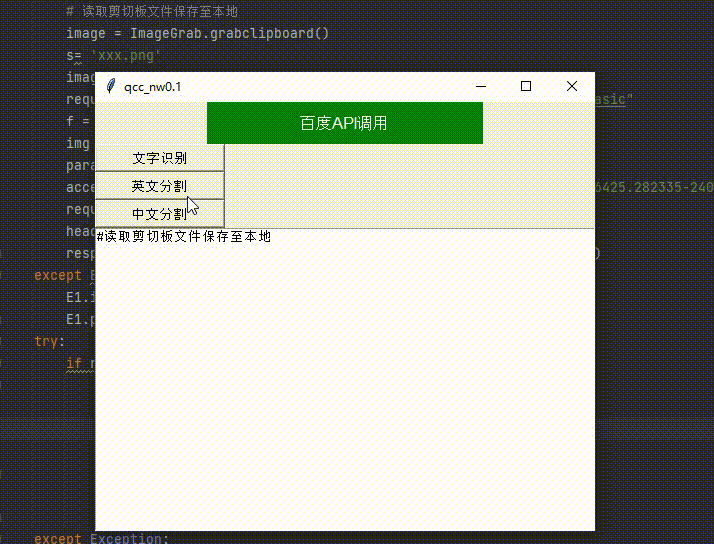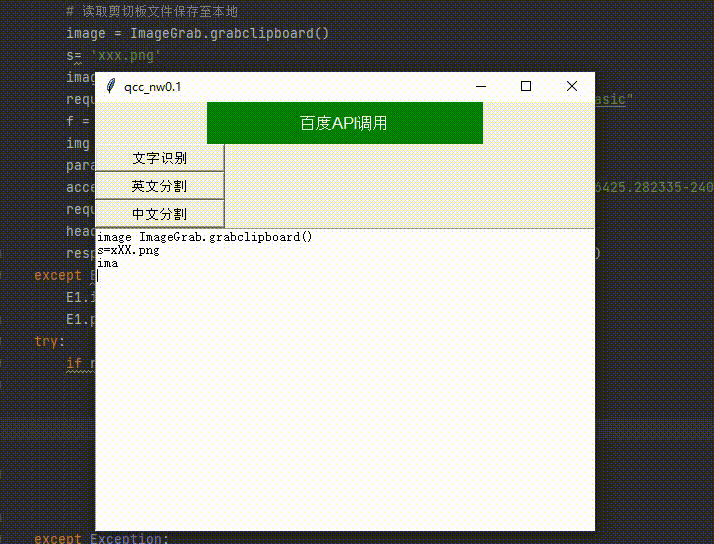
三、搭建窗口化的程序以便于使用
实现窗口可视化的第三方类库是Tkinter。可在终端输入 pip install tkinter 自行下载安装
导入tkinter模块包 构建我们的可视化窗口,要是实现的功能有截图识别文字,中英文分离,文字识别后自动发送给剪切板
from tkinter import *
# 创建窗口
window = Tk()
# 窗口名称
window.title('qcc-tnw')
# 设置窗口大小
window.geometry('400x600')
# 窗口标题设置
l=Label(window,text='百度API调用', bg='green', fg='white', font=('Arial', 12), width=30, height=2)
l.pack()
# 设置文本接收框
E1 = Text(window,width='100',height='100')
# 设置操作Button,单击运行文字识别 "window窗口,text表示按钮文本,font表示按钮本文字体,width表示按钮宽度,height表示按钮高度,command表示运行的函数"
img_txt = Button(window, text='文字识别', font=('Arial', 10), width=15, height=1)
# 设置操作Button,单击分割英文
cut_en = Button(window, text='英文分割', font=('Arial', 10), width=15, height=1)
# 设置操作Button,单击分割中文
cut_cn = Button(window, text='中文分割', font=('Arial', 10), width=15, height=1)
# 参数anchor='nw'表示在窗口的北偏西方向即左上角
img_txt.pack(anchor='nw')
cut_en.pack(anchor='nw')
cut_cn.pack(anchor='nw')
# 使得构建的窗口始终显示在桌面最上层
window.wm_attributes('-topmost',1)
window.mainloop()
四、实现截图的自动保存
通过上述对百度接口的解析发现接口是不支持提取剪切板中的文件的
所以通过PIL库截取的图片从剪切板保存到本地,在调用百度的接口实现图片中文字的识别
PIL的安装 终端输入 pip install PIL
from PIL import ImageGrab #取出剪切板的文件保存至本地 image = ImageGrab.grabclipboard()
s= 'xxx.png'
image.save(s)
#百度接口调用
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
f = open(s, 'rb')
img = base64.b64encode(f.read())
params = {"image": img}
access_token = '24.ee0e97cbc00530d449464a563e628b8d.2592000.1640228774.282335-24065278'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
for i in response.json()['words_result']:
print(i['words'])
完成后可以使用qq或微信等的截图功能截图并运行程序

五、将识别到的文字输出显示在窗口文本框中并将文字发送到剪切板
if response:
for i in response.json()['words_result']:
# 接受识别后的文本
E1.insert("insert", i['words'] + '\n')
E1.pack(side=LEFT)
# 将识别后的文字写入剪切板
pyperclip.copy(E1.get("1.0","end"))
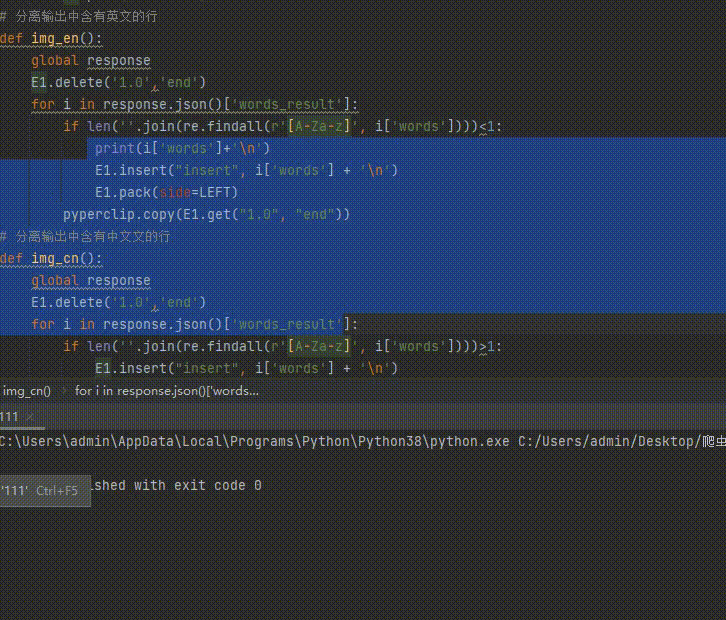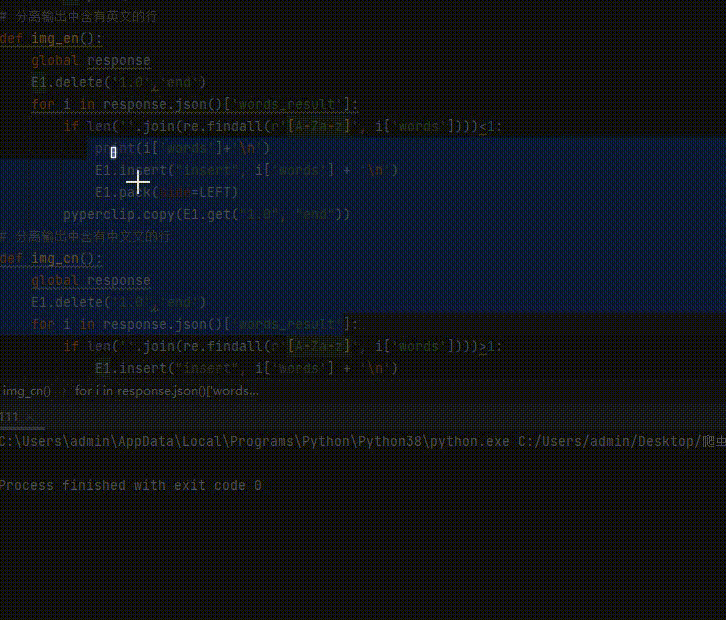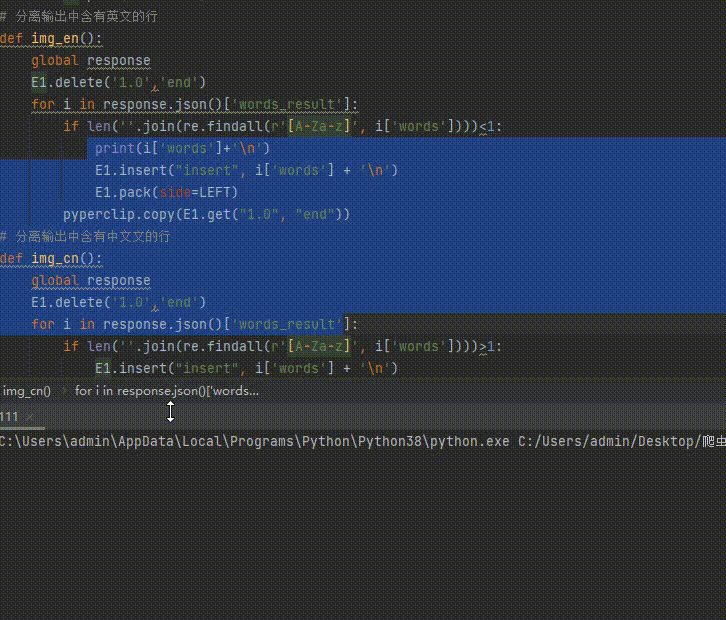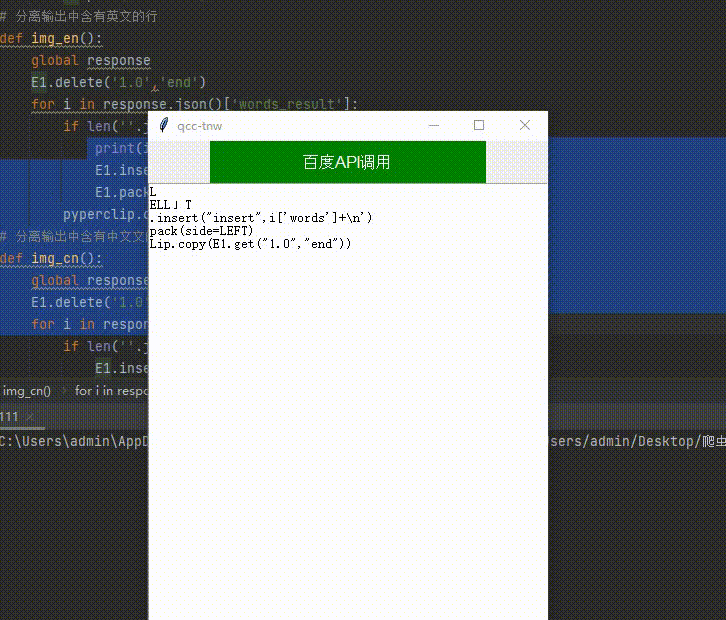
六、提取识别后文字中的中(英)文
此处的判断相对简单将 if len(''.join(re.findall(r'[A-Za-z]', i['words'])))<1: 中的‘<’改为‘>’即为中文
E1.delete('1.0','end')
for i in response.json()['words_result']:
#判断是否存在英文
if len(''.join(re.findall(r'[A-Za-z]', i['words'])))<1:
#将识别正则过滤后的文本在文本框中显示
E1.insert("insert", i['words'] + '\n')
E1.pack(side=LEFT)
#复制到剪切板
pyperclip.copy(E1.get("1.0", "end"))
最后将方法封装为函数形式传递至我们定义好的窗口按钮中
# 设置操作Button,单击运行文字识别 "window窗口,text表示按钮文本,font表示按钮本文字体,width表示按钮宽度,height表示按钮高度,command表示运行的函数"
img_txt = Button(window, text='文字识别', font=('Arial', 10), width=15, height=1,command=img_all)
# 设置操作Button,单击分割英文
cut_en = Button(window, text='英文分割', font=('Arial', 10), width=15, height=1,command=img_en)
# 设置操作Button,单击分割中文
cut_cn = Button(window, text='中文分割', font=('Arial', 10), width=15, height=1,command=img_cn)
# 参数anchor='nw'表示在窗口的北偏西方向即左上角
img_txt.pack(anchor='nw')
cut_en.pack(anchor='nw')
cut_cn.pack(anchor='nw')
window.wm_attributes('-topmost',1)
Python实战:截图识别文字,过万使用量版本!(附源码!!)的更多相关文章
- Python的开源人脸识别库:离线识别率高达99.38%(附源码)
Python的开源人脸识别库:离线识别率高达99.38%(附源码) 转https://cloud.tencent.com/developer/article/1359073 11.11 智慧上云 ...
- C# 30分钟完成百度人脸识别——进阶篇(文末附源码)
距离上次入门篇时隔两个月才出这进阶篇,小编惭愧,对不住关注我的卡哇伊的小伙伴们,为此小编用这篇博来谢罪. 前面的准备工作我就不说了,注册百度账号api,创建web网站项目,引入动态链接库引入. 不了解 ...
- 用python的TK模块实现猜成语游戏(附源码)
说明:本游戏使用到的python模块有tkinter,random,hashlib:整个游戏分为四个窗口,一个进入游戏的窗口.一个选关窗口.一个游戏进行窗口和一个游戏结束的窗口. 源码有两个主要的py ...
- python爬虫-淘宝商品密码(图文教程附源码)
今天闲着没事,不想像书上介绍的那样,我相信所有的数据都是有规律可以寻找的,然后去分析了一下淘宝的商品数据的规律和加密方式,用了最简单的知识去解析了需要的数据. 这个也让我学到了,解决问题的方法不止一个 ...
- Python爬虫实战,完整的思路和步骤(附源码)
前言 小的时候心中总有十万个为什么类似的问题,今天带大家爬取一个问答类的网站. 本堂课使用正则表达式对文本类的数据进行提取,正则表达式是数据提取的通用方法. 环境介绍: python 3.6 pych ...
- 一张图片在Python操作下的4种玩法(附源码)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:黄伟呢 1.利用python绘制一个小猪佩奇 turtle库是一个很 ...
- 摸鱼人常备5个Python迷你项目,玩一整天不是问题(附源码)
大家好鸭,我是小熊猫 在使用Python的过程中,我最喜欢的就是Python的各种第三方库,能够完成很多操作. 下面就给大家介绍5个通过Python构建的项目,以此来学习Python编程. 一.石头剪 ...
- 【Storm】Storm实战之频繁二项集挖掘(附源码)
一.前言 针对大叔据实时处理的入门,除了使用WordCount示例之外,还需要相对更深入点的示例来理解Storm,因此,本篇博文利用Storm实现了频繁项集挖掘的案例,以方便更好的入门Storm. 二 ...
- selenium实战:窗口化爬取*宝数据(附源码链接)
完整代码&火狐浏览器驱动下载链接:https://pan.baidu.com/s/1pc8HnHNY8BvZLvNOdHwHBw 提取码:4c08 双十一刚过,想着某宝的信息看起来有些少很难做 ...
随机推荐
- Mybatis初始化机制
对于任何框架而言,在使用前都要进行一系列的初始化,MyBatis也不例外.本章将通过以下几点详细介绍MyBatis的初始化过程. 1.MyBatis的初始化做了什么 2. MyBatis基于XML配置 ...
- Excel一对多查找
很多人在Excel中用函数公式做查询的时候,都必然会遇到的一个大问题,那就是一对多的查找/查询公式应该怎么写?大多数人都是从VLOOKUP.INDEX+MATCH中入门的,纵然你把全部的多条件查找方法 ...
- LeetCode:并查集
并查集 这部分主要是学习了 labuladong 公众号中对于并查集的讲解,文章链接如下: Union-Find 并查集算法详解 Union-Find 算法怎么应用? 概述 并查集用于解决图论中「动态 ...
- Zabbix 5.0:监控阿里云RDS
Blog:博客园 个人 由于近期压测,需要频繁登录阿里云查看RDS监控,每次登录查看监控步骤较为繁琐,故将监控接入到zabbix. 概述 由于阿里云已做了RDS的监控,我们只需要通过阿里云SDK把这些 ...
- CODING 助力江苏高速信息实现组织敏捷与研发敏捷,领跑智慧交通新基建
疫情之下的高速公路管控重任 江苏高速公路信息工程有限公司(以下简称:江苏高速信息)成立于 2002 年,是江苏交通控股旗下,专业从事高速公路领域机电系统集成.智能交通软硬件研发.大数据分析运营的高新技 ...
- 单片机STM32学习笔记之寄存器映射详解
我们知道,存储器本身没有地址,给存储器分配地址的过程叫存储器映射,那什么叫寄存器映射?寄存器到底是什么? 在存储器Block2 这块区域,设计的是片上外设,它们以四个字节为一个单元,共32bit,每一 ...
- 对dy和Δy的浅薄理解
一.导数定义 当函数y=f(x)的自变量x在一点x0上产生一个增量Δx时,函数输出值的增量Δy与自变量增量Δx的比值在Δx趋于0时的极限a如果存在,a即为在x0处的导数,记作f'(x0)或df(x0) ...
- C++ map操作——插入、查找、遍历
c++ map 操作学习 #include <iostream> #include <map> #include <string> #include <vec ...
- STL 去重 unique
一.unique函数 类属性算法unique的作用是从输入序列中"删除"所有相邻的重复元素. 该算法删除相邻的重复元素,然后重新排列输入范围内的元素,并且返回一个迭代器(容器的长度 ...
- Django 实现分页功能(django 2.2.7 python 3.7.5 )
Django 自带名为 Paginator 的分页工具, 方便我们实现分页功能.本文就讲解如何使用 Paginator 实现分页功能. 一. Paginator Paginator 类的作用是将我们需 ...