hive DML 操作
数据导入
load data [local] inpath '数据的 path' [overwrite] into table
student [partition (partcol1=val1,…)];
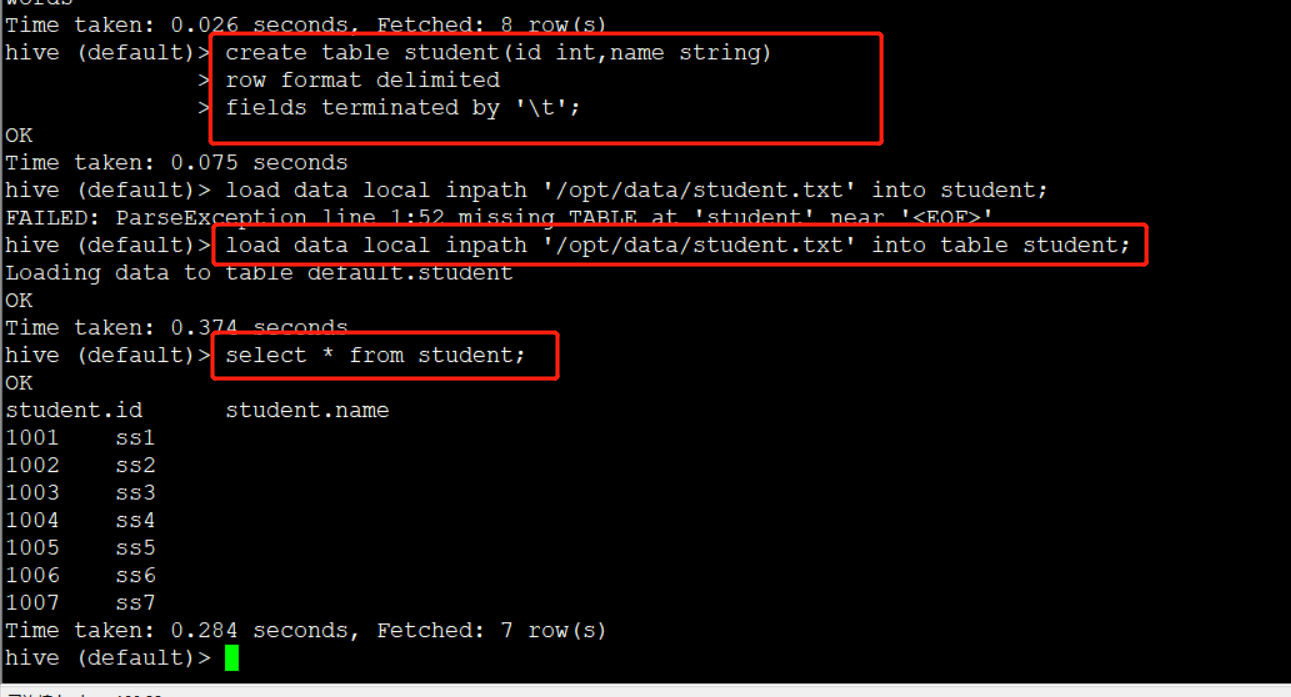
创建表
create table student(id string, name string) row format
delimited fields terminated by '\t';
load data local inpath
'/opt/module/data/student.txt' into table default.student;

(0)创建一张表
create table student(id string, name string) row format
delimited fields terminated by '\t';
(1)加载本地文件到 hive
load data local inpath
'/opt/module/hive/datas/student.txt' into table default.student;
(2)加载 HDFS 文件到 hive 中
上传文件到 HDFS
hive (default)> dfs -put /opt/module/hive/data/student.txt
/user/atguigu/hive;
加载 HDFS 上数据
load data inpath '/user/atguigu/hive/student.txt' into table default.student;
(3)加载数据覆盖表中已有的数据
上传文件到 HDFS
hive (default)> dfs -put /opt/module/data/student.txt /user/atguigu/hive;
加载数据覆盖表中已有的数据
hive (default)> load data inpath '/user/atguigu/hive/student.txt'
overwrite into table default.student;
1)创建一张表
hive (default)> create table student_par(id int, name string) row format
delimited fields terminated by '\t';
2)基本插入数据
hive (default)> insert into table student_par
values(1,'wangwu'),(2,'zhaoliu');
3)基本模式插入(根据单张表查询结果)
hive (default)> insert overwrite table student_par
select id, name from student where month='201709';
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
注意:insert 不支持插入部分字段
4)多表(多分区)插入模式(根据多张表查询结果)
hive (default)> from student
insert overwrite table student partition(month='201707')
select id, name where month='201709'
insert overwrite table student partition(month='201706')
select id, name where month='201709';
根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3
as select id, name from student;
4.创建表时通过 Location 指定加载数据路径
1)上传数据到 hdfs 上
hive (default)> dfs -mkdir /student;
hive (default)> dfs -put /opt/module/datas/student.txt /student; 2)创建表,并指定在 hdfs 上的位置
hive (default)> create external table if not exists student5(
id int, name string
)
row format delimited fields terminated by '\t'
location '/student;
Import 数据到指定 Hive 表中
数据导出
1 Insert 导出
hive (default)> insert overwrite local directory
'/opt/module/hive/data/export/student'
select * from student;
hive(default)>insert overwrite local directory
'/opt/module/hive/data/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
hive (default)> insert overwrite directory '/user/atguigu/student2'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
2 Hadoop 命令导出到本地
hive (default)> dfs -get /user/hive/warehouse/student/student.txt
/opt/module/data/export/student3.txt;
Export 导出到 HDFS 上
清除表中数据(Truncate)
注意:Truncate 只能删除管理表,不能删除外部表中数据
查询
hive DML 操作的更多相关文章
- hive DML操作
1.数据导入 1)向表中装载数据(load) 语法 hive> load data [local] inpath '/opt/module/datas/student.txt' [overwri ...
- Hive DDL、DML操作
• 一.DDL操作(数据定义语言)包括:Create.Alter.Show.Drop等. • create database- 创建新数据库 • alter database - 修改数据库 • dr ...
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
- 23-hadoop-hive的DDL和DML操作
跟mysql类似, hive也有 DDL, 和 DML操作 数据类型: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ ...
- Hive数据库操作
Hive数据结构 除了基本数据类型(与java类似),hive支持三种集合类型 Hive集合类型数据 array.map.structs hive (default)> create table ...
- Vertica并发DML操作性能瓶颈的产生与优化(转)
文章来源:中国联通网研院网优网管部IT技术研究团队 作者:陆昕 1. 引言 众所周知,MPP数据库以其分布式的超大存储能力以及列式的高速汇总能力,已经成为大数据分析比不可少的工具.Vertica就是这 ...
- salesforce 零基础开发入门学习(三)sObject简单介绍以及简单DML操作(SOQL)
salesforce中对于数据库操作和JAVA等语言对于数据库操作是有一定区别的.salesforce中的数据库使用的是Force.com 平台的数据库,数据表一行数据可以理解成一个sObject变量 ...
- Sql Server之旅——第十站 看看DML操作对索引的影响
我们都知道建索引是需要谨慎的,当只有利大于弊的时候才适合建,我们也知道建索引是需要维护成本的,这个维护也就在于DML操作了, 下面我们具体看看到底DML对索引都有哪些内幕.... 一:delete操作 ...
- spark使用Hive表操作
spark Hive表操作 之前很长一段时间是通过hiveServer操作Hive表的,一旦hiveServer宕掉就无法进行操作. 比如说一个修改表分区的操作 一.使用HiveServer的方式 v ...
随机推荐
- 牛客练习赛44 C:小y的质数
链接:https://ac.nowcoder.com/acm/contest/634/C?tdsourcetag=s_pcqq_aiomsg 来源:牛客网 题目描述 给出一个区间\([L,R]\),求 ...
- Docker_安装和卸载(2)
1.检查是否安装docker docker -v 下图为已安装docker的结果 下图为未安装docker的结果 2.卸载docker 查看已安装的版本 yum list installed | gr ...
- 获取iframe外的document
在iframe中点击弹出层外部分弹出层消失,但是点击iframe外部分就操作不了弹出层了,被这个问题困扰了不少时间,今天得以解决,代码如下: 说明:$(top.document,document).c ...
- MCU软件最佳实践——独立按键
1. 引子 在进行mcu驱动和应用开发时,经常会遇到独立按键驱动的开发,独立按键似乎是每一个嵌入式工程师的入门必修课.笔者翻阅了许多书籍(包括上大学时候用的书籍)同时查阅了网上许多网友的博客,无一例外 ...
- Android中添加监听回调接口的方法
在Android中,我们经常会添加一些监听回调的接口供别的类来回调,比如自定义一个PopupWindow,需要让new这个PopupWindow的Activity来监听PopupWindow中的一些组 ...
- 学习javaScript必知必会(6)~类、类的定义、prototype 原型、json对象
一.定义类:使用的是funciton,因为在js中没有定义类的class语句,只有function. ■ 举例: //定义一个Person类(通过类的无参构造函数定义类) function Perso ...
- Metasploit生成木马入侵安卓手机
开始 首先你需要一个Metasploit(废话) Linux: sudo apt install metasploit-framework Termux: 看这里 指令 sudo su //生成木马文 ...
- 【reverse】逆向4 初识堆栈
[reverse]逆向4 初识堆栈 1.问题引入 假设我们需要一块内存,有如下的要求 主要用于临时存储一些数据(如果数据很少可以放入寄存器中) 能够记录存了多少数据 能够非常快速的找到某个数据 2.模 ...
- Java将引入新的对象类型来解决内存利用问题
2022年Java将有什么新的特性和改进,我相信很多Java开发者都想知道.结合Java语言架构师布莱恩·格茨(Brian Goetz)最近的一些分享,胖哥给大家爆个料.老规矩,点赞走起. Valha ...
- 刚进公司,不懂GIt工作流的我瑟瑟发抖
前言 不懂git工作流,被辞退了! 之前在看到这句话的时候,我刚实习入职不久,瑟瑟发抖.好巧不巧,今天又看到了类似的文章讲git重要性的. 眼下,学校导师安排给我的课题组了一个新的工程项目,使用git ...