ConcurrentHashMap源码解读三
今天首先讲解helpTransfer方法
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
//如果table不是空,且node节点是转移类型,数据校验,且node节点得nextTable(新table)不是空,同样也是数据校验,那么就尝试帮助扩容。
(nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);//根据length得到一个标识符号
//如果nextTab没有被并发修改,且tab也没有被并发修改,且sizeCtl<0(说明还在扩容)
while (nextTab == nextTable && table == tab &&
(sc = sizeCtl) < 0) {
//如果sizeCtl无符号右移16位不等于rs,sc前16位如果不等于标识符,则标识符变化挂了
//或者sizeCtl == rs+1,扩容结束了,不再有线程进行扩容。
//或者sizeCtl达到最大帮助线程得数量,或者转移下标正在调整,都代表扩容结束。break;返回table。
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
//否则,进行扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
接下来就是transfer部分
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;//stride为每个cpu所需要处理得桶个数。
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)//如果是多cpu,那么每个线程划分任务,最小任务量是16个桶位的迁移
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) {//如果新的table没有初始化,那么就初始化一个大小为原来二倍的数组为新数组,被nextTab引用 // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];//
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;//如果扩容出现错误,则sizeCtl赋值为int最大值返回
return;
}
nextTable = nextTab;
transferIndex = n;//记录线程开始迁移的桶位,从后往前迁移。
}
int nextn = nextTab.length;//记录新数组的末尾。
//当旧数组的某个桶位null或者这个桶的元素已经被全部转移到新数组中,那么就在旧数组中放一个这个
//当其他线程想往旧数组中put元素的时候,如果put元素的index处存的是这个,那么就调用helpTransfer让这个线程一起进行扩容
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);//已经迁移的桶位,会用这个节点占位(这个节点的hash值为-1--MOVED)
boolean advance = true;//数组一层层推进的标识符,advance为true就说明这个桶处理完了,有三种情况可以让advance为true。一是旧数组对应位置为null并通过cas写入一个fwd,二是旧数组对应位置就是一个fwd。三是就数组对应的位置已经转移成功
boolean finishing = false; // to ensure sweep before committing nextTab//扩容结束的标识符
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
//while的作用就是确定每个线程需要处理的桶的下标,并且通过i--来遍历hash表中的每个桶,
//假如旧数组有32个桶模板transferferIndex就是32,当第一个线程进来的时候,nextIndex=transferIndex = 32,nextBound = nextIndex-stride = 16,而transferIndex也通过cas被调整为16,所以第一个线程处理桶的范围是从16到31号桶。
//所以第二个线程进来,nextIndex = transferIndex = 16,nextBound = 0
//所以第二个线程处理桶的范围是从0到第15号桶。
while (advance) {
int nextIndex, nextBound;
//过了第一次之后i-->=bound,在这里就跳出循环了,这里的finishing是为了二次循环检查用的,让最后一个线程遍历整个数组,但是如果多线程的时候i--可能会使i跳出这个线程对应的范围,所以用finishing保证i可以一直--。
if (--i >= bound || finishing)
advance = false;
//当所有的线程都分配完对应需要转移的桶的范围后,transferindex就为0,所以当某一个线程完成了自己的任务后,nextIndex=transferIndex=0,所以i被设置为-1,跳出这个whlle。
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//第一次进入这个扩容方法时,是到这里来的,因为前面for循环i=0,所以前面的两个判断都跳过,直接来到这里。这里就是在分配当前线程所需要转移的范围。
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;//线程负责桶区间当前最小下标
i = nextIndex - 1;//线程负责桶区间当前最大下标
advance = false;
}
}
//如果没有更多的需要迁移的桶位,就进入该if
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {//扩容结束后,保存新数组,并重新计算扩容阈值,赋值给sizeCtl
nextTable = null;//删除成员变量
table = nextTab;//更新table
sizeCtl = (n << 1) - (n >>> 1);//更新阈值,就是将阈值变为旧数组的1.5倍,因为旧阈值是旧数组的0.75倍,旧数组扩容2倍对应的阈值也就是扩容两倍,即1.5倍。
return;
}
//扩容任务线程数减1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)//判断当前所有扩容任务线程是否都执行完成
return;
finishing = advance = true;//所有扩容线程都执行完,标识结束
i = n; // recheck before commit//再次循环检查一个表
}
}
//当前迁移的桶位没有元素,那就不用迁移了,直接在该位置通过cas添加一个fwd节点
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)//当前节点已经被迁移
advance = true; // already processed
else {
synchronized (f) { //当前节点需要迁移,加锁迁移,保证多线程安全//加锁防止在这个桶位迁移的时候,别的线程对这个桶位进行元素添加。
if (tabAt(tab, i) == f) {// 判断 i 下标处的桶节点是否和 f 相同
Node<K,V> ln, hn;//ln低位桶,hn高位桶
if (fh >= 0) {// 如果 f 的 hash 值大于 0 。TreeBin 的 hash 是 -2
// 对老长度进行与运算(第一个操作数的的第n位与上第二个操作数的第n位如果都是1,那么结果的第n位也为1,否则为0)int runBit = fh & n;//就比如n是32,那么就是000010000,就只有一个地方为1.所以fn是大于0的数,他的二进制与上n的话,结果只有000010000和00000000;
// 由于 Map 的长度都是 2 的次方(000001000 这类的数字),那么取于 length 只有 2 种结果,一种是 0,一种是1
// 如果是结果是0 ,Doug Lea 将其放在低位,反之放在高位,目的是将链表重新 hash,放到对应的位置上,让新的取于算法能够击中他。
Node<K,V> lastRun = f;// 尾节点,且和头节点的 hash 值取于不相等
for (Node<K,V> p = f.next; p != null; p = p.next) {//开始从这个桶的头节点之后的节点开始遍历元素
int b = p.hash & n;
//其实这里这个for循环,就是为了求出lastRun最后指向的是是链表中的哪个节点。那么在下面的另一个for循环中,lastRun后面的就跟这个lastRun节点是一样的,就可以不用遍历,直接把lastRun这个头节点接过去就行。省了一些时间
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {//如果最后更新的runBit是0,设置低位节点
ln = lastRun;
hn = null;
}
else {
hn = lastRun;// 反之,设置高位节点
ln = null;
}
// 再次循环,生成两个链表,lastRun 作为停止条件,这样就是避免无谓的循环(lastRun 后面都是相同的取与结果)for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
//注意创建node节点的最后一个参数ln指代的是next,也就是说,我们不再是从头到尾节点,而是从尾节点开始往头节点走。当开始遍历到第一个元素的时候,那么就把刚刚得到的ln设置尾新元素的next。
ln = new Node<K,V>(ph, pk, pv, ln);// 如果是0 ,那么创建低位节点
else
hn = new Node<K,V>(ph, pk, pv, hn);// 1 则创建高位
}
setTabAt(nextTab, i, ln);//ln挂到新数组的原下标
setTabAt(nextTab, i + n, hn);//hn挂到新数组的原下标+老数组长度,跟HashMap一样。
setTabAt(tab, i, fwd);//把fwd放入旧表中。
advance = true;
}
else if (f instanceof TreeBin) {//红黑树的情况
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) ://如果长度小于等于6,则将红黑树转换成链表
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
接下来借用这个博客的图https://www.jianshu.com/p/2829fe36a8dd来更好理解上述的链表转移
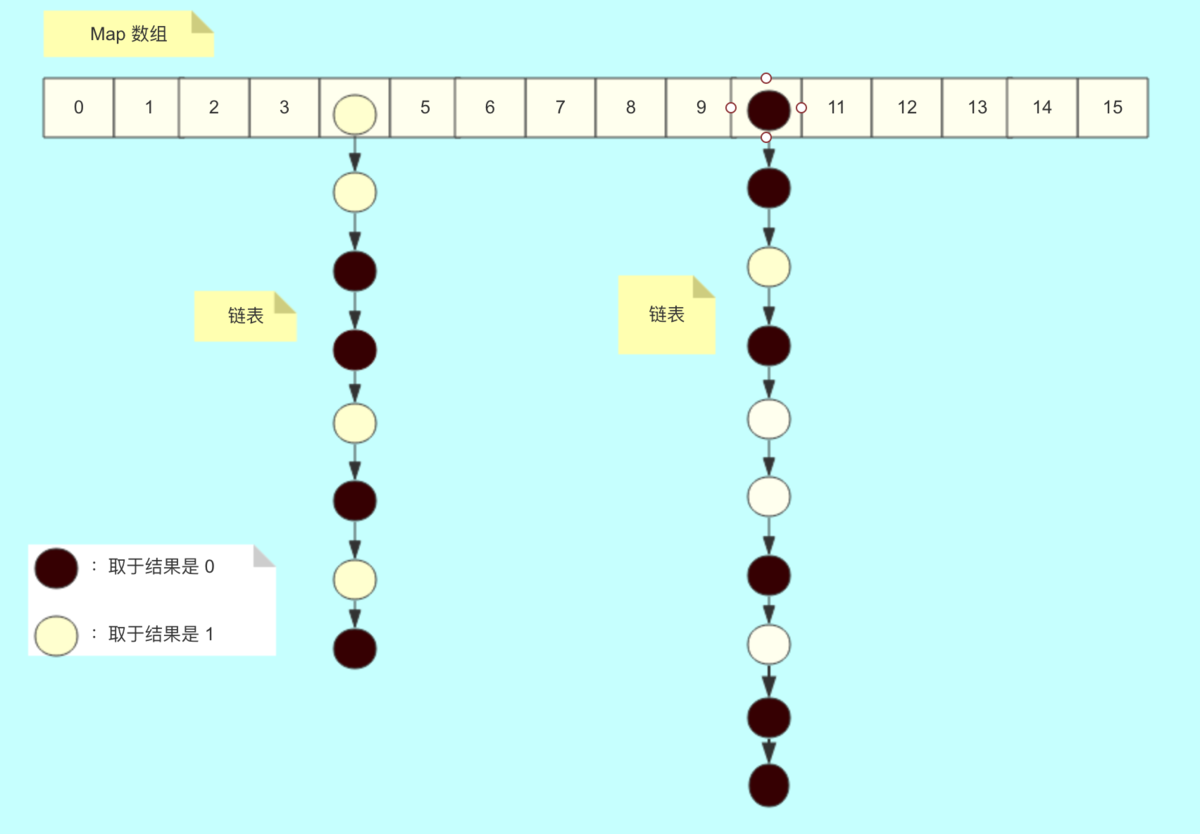
可以看到四号桶和10号桶的元素转移时都会把链表拆成两份,规则就是上述根据hash值取与旧表的长度,如果结果是0,放在低位,否则放在高位。假如只看10号桶,那么黑丝的会放在新表的10号位置,白色节点会放在10+16也就是26的位置。
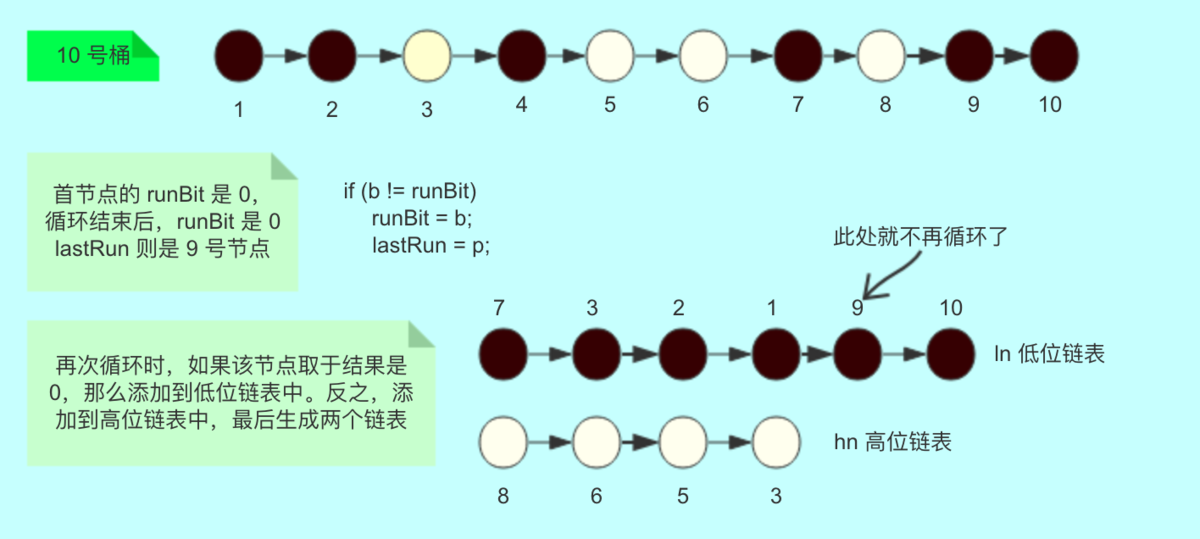
从这个for循环中可以发现。如果节点是上面图的一样,那么最后9和10是黑色,因此lastRun就是9。可以从1开始for循环验证。
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
经过第二个for循环时
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
这里可以看到,还未到lastRun的节点都是倒序的。比如黑色的7-4-2-1。原图数字标错,将4误标为了3。白色的就是8-6-5-3。当循环到p为9时,也就是lastRun时,那么9包括后面的节点,也就是10,直接插入到1之后。所以第一个for循环就是省了遍历9,10这个节点的时间。处理之后的数组结构就是这样的
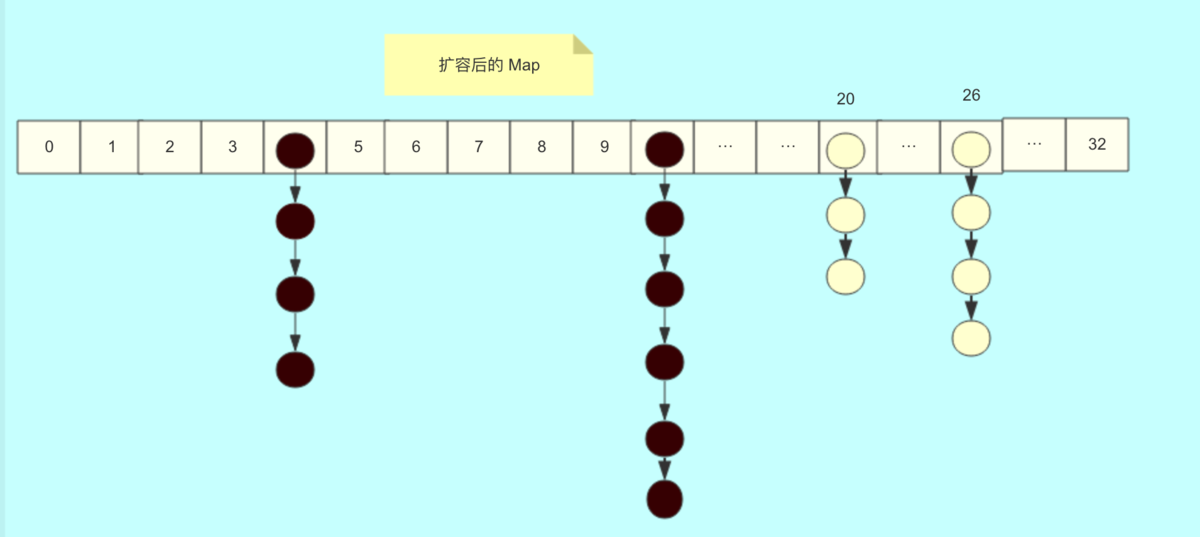
总结:转移旧数组是从右至左开始转移的。数组扩容是按两倍进行扩容的。阈值也就相应的变为原来的两倍。链表的转移是有一个小优化来节省时间的。就是得到lastRun节点。然后是反向的。转移后的桶位,低位链就是原来的位置,高位链就是原来的位置加旧数组长度的位置。
ConcurrentHashMap源码解读三的更多相关文章
- HashTable、HashMap与ConCurrentHashMap源码解读
HashMap 的数据结构 hashMap 初始的数据结构如下图所示,内部维护一个数组,然后数组上维护一个单链表,有个形象的比喻就是想挂钩一样,数组脚标一样的,一个一个的节点往下挂. 我们可以 ...
- go语言 nsq源码解读三 nsqlookupd源码nsqlookupd.go
从本节开始,将逐步阅读nsq各模块的代码. 读一份代码,我的思路一般是: 1.了解用法,知道了怎么使用,对理解代码有宏观上有很大帮助. 2.了解各大模块的功能特点,同时再想想,如果让自己来实现这些模块 ...
- ConcurrentHashMap源码解读一
最近在学习并发map的源码,如果由错误欢迎指出.这仅供我自己学习记录使用. 首先就先来说一下几个全局变量 private static final int MAXIMUM_CAPACITY = 1 & ...
- ConcurrentHashMap源码解读二
接下来就讲解put里面的三个方法,分别是 1.数组初始化方法initTable() 2.线程协助扩容方法helpTransfer() 3.计数方法addCount() 首先是数组初始化,再将源码之前, ...
- jQuery源码解读三选择器
直接上jQuery源码截取代码 // Map over jQuery in case of overwrite _jQuery = window.jQuery, // Map over the $ i ...
- Python Web Flask源码解读(三)——模板渲染过程
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- 深入理解JAVA集合系列二:ConcurrentHashMap源码解读
HashMap和Hashtable的区别 在正式开始这篇文章的主题之前,我们先来比较下HashMap和Hashtable之间的差异点: 1.Hashtable是线程安全的,它对外提供的所有方法都是都使 ...
- mybatis源码解读(三)——数据源的配置
在mybatis-configuration.xml 文件中,我们进行了如下的配置: <!-- 可以配置多个运行环境,但是每个 SqlSessionFactory 实例只能选择一个运行环境常用: ...
- JUC回顾之-ConcurrentHashMap源码解读及原理理解
ConcurrentHashMap结构图如下: ConcurrentHashMap实现类图如下: segment的结构图如下: package concurrentMy.juc_collections ...
随机推荐
- Go语言学习 学习资料汇总
从进入实验室以来,一直听小溪师兄说Go语言,但是第一学期的课很多,一直没有时间学习,现在终于空出来时间学习,按照我的学习习惯,我一般分为三步走 学习一门语言首先要知道学会了能干什么, 然后再把网上的资 ...
- WinForm的Socket实现简单的聊天室 IM
1:什么是Socket 所谓套接字(Socket),就是对网络中不同主机上的应用进程之间进行双向通信的端点的抽象. 一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制. 从 ...
- 简要说一下.Net的编译过程.
看面试题的时候遇到这样一道题目,简要说明.NET的编译过程,在网上看了很多资料,简单总结如下: 1.一般的编译过程 通常高级语言的程序编译过程是:首先写好的程序是源代码,然后编译器编译为本地机器语言, ...
- Object类中的常用方法
1.getClass方法 源码: 功能: 返回此Object的运行时类. 什么是运行时类? 如上图所示,类从被加载到虚拟机内存开始,到卸载出内存为止,他的生命周期一共包含7个阶段.其中加载阶段虚拟机需 ...
- frp穿透内网使用vsftpd服务
本篇文章将会介绍如何使用frp穿透内网以及如何在centos8环境下安装和使用vsftpd,最后在公网通过frp穿透内网使用ftp. 一.内网穿透神器frp frp 是一个专注于内网穿透的高性能的反向 ...
- CVPR2021| 继SE,CBAM后的一种新的注意力机制Coordinate Attention
前言: 最近几年,注意力机制用来提升模型性能有比较好的表现,大家都用得很舒服.本文将介绍一种新提出的坐标注意力机制,这种机制解决了SE,CBAM上存在的一些问题,产生了更好的效果,而使用与SE,CBA ...
- [图论]剑鱼行动:kruskal
剑鱼行动 目录 剑鱼行动 Description Input Output Sample Input Sample Output 解析 难点 代码 Description 给出N个点的坐标,对它们建立 ...
- [Fundamental of Power Electronics]-PART II-9. 控制器设计-9.5 控制器的设计
9.5 控制器设计 现在让我们来考虑如何设计控制器系统,来满足有关抑制扰动,瞬态响应以及稳定性的规范或者说设计目标.典型的直流控制器设计可以用以下规范定义: 1.负载电流变化对输出电压调节的影响.当负 ...
- 【设计模式】- 生成器模式(Builder)
生成器模式 建造者模式.Builder 生成器模式 也叫建造者模式,可以理解成可以分步骤创建一个复杂的对象.在该模式中允许你使用相同的创建代码生成不同类型和形式的对象. 生成器的结构模式 生成器(Bu ...
- (七)Struts2Action访问Servlet API
第一种方式: Struts2提供了一个ServletActionContext对象可以访问ServletAPI. 例如 HttpServletRequest request=ServletAction ...