雪花算法(SnowFlake)Java实现
分布式id生成算法的有很多种,Twitter的SnowFlake就是其中经典的一种。
算法原理
SnowFlake算法生成id的结果是一个64bit大小的整数,它的结构如下图:
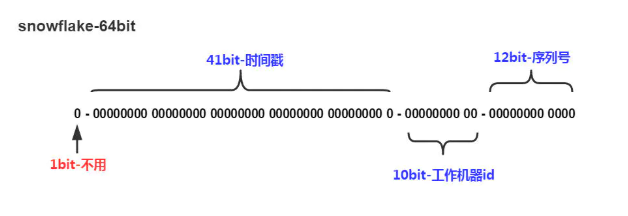
1bit,不用,因为二进制中最高位是符号位,1表示负数,0表示正数。生成的id一般都是用整数,所以最高位固定为0。
41bit-时间戳,用来记录时间戳,毫秒级。
- 41位可以表示
个数字
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至
- 也就是说41位可以表示
年
10bit-工作机器id,用来记录工作机器id
- 可以部署在
个节点,包括5位datacenterId和5位workerId
- 5位(bit)可以表示的最大正整数是
,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
12bit-序列号,序列号,用来记录同毫秒内产生的不同id
- 12位(bit)可以表示的最大正整数是
,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的
SnowFlake可以保证:
- 所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
算法实现(Java)
Twitter官方给出的算法实现 是用Scala写的,这里不做分析,可自行查看
package com.ihrm.common.utils;
public class IdWorker {
//下面两个每个5位,加起来就是10位的工作机器id
private long workerId; //工作id
private long datacenterId; //数据id
//12位的序列号
private long sequence;
public IdWorker(long workerId, long datacenterId, long sequence) {
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);
this.workerId = workerId;
this.datacenterId = datacenterId;
this.sequence = sequence;
}
//初始时间戳
private long twepoch = 1288834974657L;
//长度为5位
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
//最大值
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
//序列号id长度
private long sequenceBits = 12L;
//序列号最大值
private long sequenceMask = -1L ^ (-1L << sequenceBits);
//工作id需要左移的位数,12位
private long workerIdShift = sequenceBits;
//数据id需要左移位数 12+5=17位
private long datacenterIdShift = sequenceBits + workerIdBits;
//时间戳需要左移位数 12+5+5=22位
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
//上次时间戳,初始值为负数
private long lastTimestamp = -1L;
public long getWorkerId() {
return workerId;
}
public long getDatacenterId() {
return datacenterId;
}
public long getTimestamp() {
return System.currentTimeMillis();
}
//下一个ID生成算法
public synchronized long nextId() {
long timestamp = timeGen();
//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
//获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
//将上次时间戳值刷新
lastTimestamp = timestamp;
/**
* 返回结果:
* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数
* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数
* (workerId << workerIdShift) 表示将工作id左移相应位数
* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。
* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id
*/
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
//获取时间戳,并与上次时间戳比较
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
//获取系统时间戳
private long timeGen() {
return System.currentTimeMillis();
}
//---------------测试---------------
public static void main(String[] args) {
IdWorker worker = new IdWorker(1, 1, 1);
for (int i = 0; i < 30; i++) {
System.out.println(worker.nextId());
}
}
}
关于本文介绍雪花算法,大家可以参考(煲煲菜的博客):https://segmentfault.com/a/1190000011282426
雪花算法(SnowFlake)Java实现的更多相关文章
- 雪花算法-snowflake
雪花算法-snowflake 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有 ...
- Twitter雪花算法 SnowFlake算法 的java实现
概述 SnowFlake算法是Twitter设计的一个可以在分布式系统中生成唯一的ID的算法,它可以满足Twitter每秒上万条消息ID分配的请求,这些消息ID是唯一的且有大致的递增顺序. 原理 Sn ...
- 【Java】分布式自增ID算法---雪花算法 (snowflake,Java版)
一般情况,实现全局唯一ID,有三种方案,分别是通过中间件方式.UUID.雪花算法. 方案一,通过中间件方式,可以是把数据库或者redis缓存作为媒介,从中间件获取ID.这种呢,优点是可以体现全局的递增 ...
- 分布式系统-主键唯一id,订单编号生成-雪花算法-SnowFlake
分布式系统下 我们每台设备(分布式系统-独立的应用空间-或者docker环境) * SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作 ...
- 分布式唯一ID生成方案选型!详细解析雪花算法Snowflake
分布式唯一ID 使用RocketMQ时,需要使用到分布式唯一ID 消息可能会发生重复,所以要在消费端做幂等性,为了达到业务的幂等性,生产者必须要有一个唯一ID, 需要满足以下条件: 同一业务场景要全局 ...
- 雪花算法(snowflake)delphi版
雪花算法简单描述: + 最高位是符号位,始终为0,不可用. + 41位的时间序列,精确到毫秒级,41位的长度可以使用69年.时间位还有一个很重要的作用是可以根据时间进行排序. + 10位的机器标识,1 ...
- 雪花算法 Snowflake & Sonyflake
唯一ID算法Snowflake相信大家都不墨生,他是Twitter公司提出来的算法.非常广泛的应用在各种业务系统里.也因为Snowflake的灵活性和缺点,对他的改造层出不穷,比百度的UidGener ...
- Twitter雪花算法SnowFlake算法的java实现
https://juejin.im/post/5c75132f51882562276c5065 package javaDemo; /** * twitter的snowflake算法 -- java实 ...
- Twitter的分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- 分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
随机推荐
- Proteus仿真MSP430单片机的若干问题记录
1.支持的具体型号: P7.8: Proteus8.9: Proteus8.9能够支持的类型明显要多于Proteus7.8.但是对于仿真而言,目前个人还是觉得Proteus7.8更稳定.这也是目前能用 ...
- Wide & Deep的OneFlow网络训练
Wide & Deep的OneFlow网络训练 HugeCTR是英伟达提供的一种高效的GPU框架,专为点击率(CTR)估计训练而设计. OneFlow对标HugeCTR搭建了Wide & ...
- 第四代自动泊车从APA到AVP技术
第四代自动泊车从APA到AVP技术 前言 自动泊车是指汽车自动泊车入位不需要人工控制,系统能够自动帮你将车辆停入车位,在倒车入库中可谓是驾驶者的一项利器.当我们找到一个理想的停车地点,只需轻轻启动按钮 ...
- 国内操作系统OS分析(下)
国内操作系统OS分析(下) 3.2 Android/iOS移动互联网时代 Android是一种基于Linux的自由及开放源代码的操作系统.主要使用于移动设备,如智能手机和平板电脑,由Google公司和 ...
- 激光雷达Lidar与毫米波雷达Radar:自动驾驶的利弊
激光雷达Lidar与毫米波雷达Radar:自动驾驶的利弊 Lidar vs Radar: pros and cons for autonomous driving 新型无人驾驶汽车的数量在缓慢增加,各 ...
- C++/VS基础篇
------------恢复内容开始------------ VS: 1.项目配置 2.IDE设置 错误列表是输出窗口的大概,根据error语法整理出,不准确. C++: 1.C++特点 优点 可直接 ...
- JVM--你常见的jvm 异常有哪些? 代码演示:StackOverflowError , utOfMemoryError: Java heap space , OutOfMemoryError: GC overhead limit exceeded, Direct buffer memory, Unable_to_create_new_native_Thread, Metaspace
直接上代码: public class Test001 { public static void main(String[] args) { //java.lang.StackOverflowErro ...
- WordPress安装篇(3):用宝塔面板在Linux上安装WordPress
前面的文章已经介绍了如何在Windows环境安装WordPress,这篇文章来介绍在Linux环境怎样快速安装WordPress.大家都知道,Linux系统相对于Windows系统而言占用资源更少.更 ...
- xxl-job执行器的注册
一.执行器注册流程 二.具体流程 1.注册监控线程 //类:JobRegistryHelper.java:方法:public void start() registryMonitorThread = ...
- 学习响应式编程 Reactor (4) - reactor 转换类操作符(1)
Reactor 操作符 数据在响应式流中的处理,就像流过一条装配流水线.Reactor 既是传送带,又是一个个的装配工或机器人.原材料从源头(最初的 Publisher )流出,经过一个个的装配线中装 ...