python进阶(24)Python字典的底层原理以及字典效率
前言
- 问题1:python中的字典到底是有序还是无序
- 问题2:python中字典的效率如何
python字典底层原理
在Python 3.5以前,字典是不能保证顺序的,键值对A先插入字典,键值对B后插入字典,但是当你打印字典的Keys列表时,你会发现B可能在A的前面。
但是从Python 3.6开始,字典是变成有顺序的了。你先插入键值对A,后插入键值对B,那么当你打印Keys列表的时候,你就会发现B一定在A的后面。
不仅如此,从Python 3.6开始,下面的三种遍历操作,效率要高于Python 3.5之前:
for key in dict1
for value in dict1.values()
for key, value in dict1.items()
从Python 3.6开始,字典占用内存空间的大小,是字典里面键值对的个数,只有原来的30%~95%。
Python 3.6到底对字典做了什么优化呢?为了说明这个问题,我们需要先来说一说,在Python 3.5之前,字典的底层原理。
python3.5之前字典的底层原理
当我们初始化一个空字典的时候,CPython的底层会初始化一个二维数组,这个数组有8行,3列,如下面的示意图所示:
my_dict = {}
'''
此时的内存示意图
[
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---]
]
'''
现在,我们往字典里面添加一个数据:
my_dict['name'] = 'jkc'
'''
此时的内存示意图
[
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向jkc的指针],
[---, ---, ---],
[---, ---, ---]
]
'''
这里解释一下,为什么添加了一个键值对以后,内存变成了这个样子:
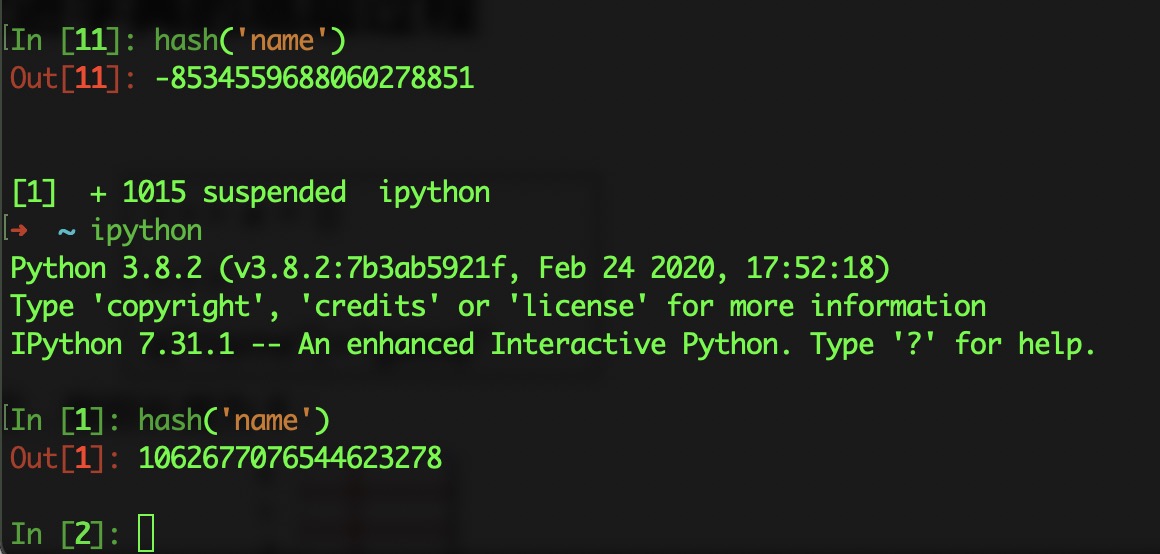
首先我们调用Python 的hash函数,计算name这个字符串在当前运行时的hash值:
In [1]: hash('name')
Out[1]: 1278649844881305901
特别注意,我这里强调了『当前运行时』,这是因为,Python自带的这个hash函数,和我们传统上认为的Hash函数是不一样的。Python自带的这个hash函数计算出来的值,只能保证在每一个运行时的时候不变,但是当你关闭Python再重新打开,那么它的值就可能会改变,如下图所示:
假设在某一个运行时里面,hash('name')的值为1278649844881305901。现在我们要把这个数对8取余数:
In [2]: 1278649844881305901 % 8
Out[2]: 5
余数为5,那么就把它放在刚刚初始化的二维数组中,下标为5的这一行。由于name和jkc是两个字符串,所以底层C语言会使用两个字符串变量存放这两个值,然后得到他们对应的指针。于是,我们这个二维数组下标为5的这一行,第一个值为name的hash值,第二个值为name这个字符串所在的内存的地址(指针就是内存地址),第三个值为jkc这个字符串所在的内存的地址。
现在,我们再来插入两个键值对:
my_dict['age'] = 26
my_dict['salary'] = 999999
'''
此时的内存示意图
[
[-4234469173262486640, 指向salary的指针, 指向999999的指针],
[1545085610920597121, 执行age的指针, 指向26的指针],
[---, ---, ---],
[---, ---, ---],
[---, ---, ---],
[1278649844881305901, 指向name的指针, 指向jkc的指针],
[---, ---, ---],
[---, ---, ---]
]
'''
那么字典怎么读取数据呢?首先假设我们要读取age对应的值。
此时,Python先计算在当前运行时下面,age对应的Hash值是多少:
In [2]: hash('age')
Out[2]: 1545085610920597121
现在这个hash值对8取余数:
In [2]: 1545085610920597121 % 8
Out[2]: 1
余数为1,那么二维数组里面,下标为1的这一行就是需要的键值对。直接返回这一行第三个指针对应的内存中的值,就是age对应的值26。
当你要循环遍历字典的Key的时候,Python底层会遍历这个二维数组,如果当前行有数据,那么就返回Key指针对应的内存里面的值。如果当前行没有数据,那么就跳过。所以总是会遍历整个二维数组的每一行。
每一行有三列,每一列占用8byte的内存空间,所以每一行会占用24byte的内存空间。
由于Hash值取余数以后,余数可大可小,所以字典的Key并不是按照插入的顺序存放的。
注意,这里我省略了与本文没有太大关系的两个点:
- 1.开放寻址,当两个不同的Key,经过Hash以后,再对8取余数,可能余数会相同。此时Python为了不覆盖之前已有的值,就会使用开放寻址技术重新寻找一个新的位置存放这个新的键值对。
- 2.当字典的键值对数量超过当前数组长度的2/3时,数组会进行扩容,8行变成16行,16行变成32行。长度变了以后,原来的余数位置也会发生变化,此时就需要移动原来位置的数据,导致插入效率变低。
python3.6之后字典的底层原理
在Python 3.6以后,字典的底层数据结构发生了变化,现在当你初始化一个空的字典以后,它在底层是这样的:
my_dict = {}
'''
此时的内存示意图
indices = [None, None, None, None, None, None, None, None]
entries = []
'''
当你初始化一个字典以后,Python单独生成了一个长度为8的一维数组。然后又生成了一个空的二维数组。
现在,我们往字典里面添加一个键值对:
my_dict['name'] = 'jkc'
'''
此时的内存示意图
indices = [None, 0, None, None, None, None, None, None]
entries = [[-5954193068542476671, 指向name的指针, 执行jkc的指针]]
'''
为什么内存会变成这个样子呢?我们来一步一步地看:
在当前运行时,name这个字符串的hash值为-5954193068542476671,这个值对8取余数是1:
>>> hash('name')
-5954193068542476671
>>> hash('name') % 8
1
所以,我们把indices这个一维数组里面,下标为1的位置修改为0。
这里的0是什么意思呢?0是二位数组entries的索引。现在entries里面只有一行,就是我们刚刚添加的这个键值对的三个数据:name的hash值、指向name的指针和指向jkc的指针。所以indices里面填写的数字0,就是刚刚我们插入的这个键值对的数据在二位数组里面的行索引。
好,现在我们再来插入两条数据:
my_dict['address'] = 'xxx'
my_dict['salary'] = 999999
'''
此时的内存示意图
indices = [1, 0, None, None, None, None, 2, None]
entries = [
[-5954193068542476671, 指向name的指针, 执行jkc的指针],
[9043074951938101872, 指向address的指针,指向xxx的指针],
[7324055671294268046, 指向salary的指针, 指向999999的指针]
]
'''
现在如果我要读取数据怎么办呢?假如我要读取salary的值,那么首先计算salary的hash值,以及这个值对8的余数:
>>> hash('salary')
7324055671294268046
>>> hash('salary') % 8
6
那么我就去读indices下标为6的这个值。这个值为2.
然后再去读entries里面,下标为2的这一行的数据,也就是salary对应的数据了。
新的这种方式,当我要插入新的数据的时候,始终只是往entries的后面添加数据,这样就能保证插入的顺序。当我们要遍历字典的Keys和Values的时候,直接遍历entries即可,里面每一行都是有用的数据,不存在跳过的情况,减少了遍历的个数。
老的方式,当二维数组有8行的时候,即使有效数据只有3行,但它占用的内存空间还是 8 * 24 = 192 byte。但使用新的方式,如果只有三行有效数据,那么entries也就只有3行,占用的空间为3 * 24 =72 byte,而indices由于只是一个一维的数组,只占用8 byte,所以一共占用 80 byte。内存占用只有原来的41%。
字典的用法总结
- 1.键必须可散列
- (1) 数字、字符串、元组,都是可散列的。
- (2) 自定义对象需要支持下面三点:
- ①支持 hash()函数
- ②支持通过__eq__()方法检测相等性。
- ③若 a==b 为真,则
hash(a)==hash(b)也为真。
- 2.字典在内存中开销巨大,典型的空间换时间。
- 3.键查询速度很快
- 4.往字典里面添加新建可能导致扩容,导致散列表中键的次序变化。因此,不要在遍历字 典的同时进行字典的修改。
参考:https://www.cnblogs.com/songyifan427/p/11198719.html
python进阶(24)Python字典的底层原理以及字典效率的更多相关文章
- python进阶:Python进程、线程、队列、生产者/消费者模式、协程
一.进程和线程的基本理解 1.进程 程序是由指令和数据组成的,编译为二进制格式后在硬盘存储,程序启动的过程是将二进制数据加载进内存,这个启动了的程序就称作进程(可简单理解为进行中的程序).例如打开一个 ...
- python 进阶篇 python 的值传递
值传递和引用传递 值传递,通常就是拷贝参数的值,然后传递给函数里的新变量,这样,原变量和新变量之间互相独立,互不影响. 引用传递,通常是指把参数的引用传给新的变量,这样,原变量和新变量就会指向同一块内 ...
- python基础24 -----python中的各种锁
一.全局解释器锁(GIL) 1.什么是全局解释器锁 在同一个进程中只要有一个线程获取了全局解释器(cpu)的使用权限,那么其他的线程就必须等待该线程的全局解释器(cpu)使 用权消失后才能使用全局解释 ...
- Python学习-24.Python中的算术运算
加法:+,与C#中并无区别,并且一样可以作用于字符串. 但Python中不支持字符串与数值类型的相加. i = 1 s = ' print(s + i) 这样是会在运行时报错的,正确写法如下: i = ...
- Python进阶:切片的误区与高级用法
2018-12-31 更新声明:切片系列文章本是分三篇写成,现已合并成一篇.合并后,修正了一些严重的错误(如自定义序列切片的部分),还对行文结构与章节衔接做了大量改动.原系列的单篇就不删除了,毕竟也是 ...
- 智普教育Python培训之Python开发视频教程网络爬虫实战项目
网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 01.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Python视频 02.mp4 网络爬虫项目实训:看我如何下载韩寒博客文章Pytho ...
- Redis核心原理与实践--散列类型与字典结构实现原理
Redis散列类型可以存储一组无序的键值对,它特别适用于存储一个对象数据. > HSET fruit name apple price 7.6 origin china 3 > HGET ...
- 操作系统底层原理与Python中socket解读
目录 操作系统底层原理 网络通信原理 网络基础架构 局域网与交换机/网络常见术语 OSI七层协议 TCP/IP五层模型讲解 Python中Socket模块解读 TCP协议和UDP协议 操作系统底层原理 ...
- Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化
Python进阶----索引原理,mysql常见的索引,索引的使用,索引的优化,不能命中索引的情况,explain执行计划,慢查询和慢日志, 多表联查优化 一丶索引原理 什么是索引: 索引 ...
随机推荐
- Java 16 中新增的 Stream 接口的一些思考
这里先提一个题外话,如果想看 JDK 不同版本之间有何差异,增加或者删除了哪些 API,可以通过下面这个链接查看: https://javaalmanac.io/jdk/17/apidiff/11/ ...
- MySQL数据库常用命令汇总
-- 查看mysql的当前登陆用户 select user(); -- 列出数据库 show databases; -- 使用数据库 use mysql; describe mysql.user; s ...
- Swoole 中使用 Atomic 实现进程间无锁计数器
使用示例: $atomic = new Swoole\Atomic(); $serv = new Swoole\Server('127.0.0.1', '9501'); $serv->set([ ...
- Zabbix忘记用户名和密码的解决方法
问题描述: 最近刚搭建了zabbix服务器,然后新增加了一个用户,并且把默认的Admin禁用了.然后这个监控页面一直没关,保持了10多天,今天不小心把浏览器关闭了,重新打开后,突然忘记了用户名,这下麻 ...
- Go语言命名规范
一.变量命名规范 变量命名一般采用驼峰式,当遇到特有名词(缩写或简称,如DNS)的时候,特有名词根据是否私有全部大写或小写.例子: var apiClient var URLString 二.常量命名 ...
- 深入理解Java虚拟机之自己编译JDK
题外话 最近在阅读<深入理解Java虚拟机>,其中有一小节实战是自己编译JDK,实际操作下来后遇到问题不少,为此特地记录,也希望可以给大家带来一些参考! 前置准备 平台及工具:Window ...
- STC8H开发(三): 基于FwLib_STC8的模数转换ADC介绍和演示用例说明
目录 STC8H开发(一): 在Keil5中配置和使用FwLib_STC8封装库(图文详解) STC8H开发(二): 在Linux VSCode中配置和使用FwLib_STC8封装库(图文详解) ST ...
- 函数实现将 DataFrame 数据直接划分为测试集训练集
虽然 Scikit-Learn 有可以划分数据集的函数 train_test_split ,但在有些特殊情况我们只希望它将 DataFrame 数据直接划分为 train, test 而不是像 tr ...
- 【Java】获取两个字符串中最大相同子串
题目 获取两个字符串中最大相同子串 前提 两个字符串中只有一个最大相同子串 解决方案 public class StringDemo { public static void main(String[ ...
- 浅解XXE与Portswigger Web Sec
XXE与Portswigger Web Sec 相关链接: 博客园 安全脉搏 FreeBuf 简介XML XML,可扩展标记语言,标准通用标记语言的子集.XML的简单易于在任何应用程序 ...