机器学习——主成分分析(PCA)
1 前言
- PCA(Principal Component Analysis)是一种常用的无监督学习方法,是一种常用的数据分析方法。
- PCA 通过利用 正交变换 把由 线性相关变量 表示的观测数据转换为少数几个由 线性无关变量 表示的数据,线性无关的变量称为主成分,可用于提取数据的主要特征分量,常用于高维数据的降维。
- 主成分的个数通常小于原始变量的个数,所以主成分分析属于降维方法。
- 主成分分析主要用于发现数据中的基本结构, 即数据中变量之间的关系。
1.1 基本思想
主成分分析就是把原有的多个指标转化成少数几个代表性较好的综合指标,这少数几个指标能够反映原来指标大部分的信息(85%以上),并且各个指标之间保持独立,避免出现重叠信息。主成分分析主要起着降维和简化数据结构的作用。
主成分分析是把各变量之间互相关联的复杂关系进行简化分析的方法。
主成分分析试图在力保数据信息丢失最少的原则下,对这种多变量的截面数据表进行最佳综合简化,对高维变量空间进行降维处理。
在力求数据信息丢失最少的原则下,对高维的变量空间降维,即研究指标体系的少数几个线性组合,并且这几个线性组合所构成的综合指标将尽可能多地保留原来指标变异方面的信息。这些综合指标就称为主成分。
要讨论的问题是:
- 基于相关系数矩阵/协方差矩阵做主成分分析?
- 选择几个主成分?
- 如何解释主成分所包含的实际意义?
1.2 数据向量表示
一般情况下,在数据挖掘和机器学习中,数据被表示为向量。
例如:某淘宝店2021年全年的流量及交易情况看成一组记录的集合,其中每一天的数据是一条记录,格式如下:
(日期, 浏览量, 访客数, 下单数, 成交数, 成交金额)
其中 “日期” 是一个记录标志而非度量值,而数据挖掘关心的大多是度量值,因此忽略日期这个字段后,得到一组记录,每条记录可被表示为一个五维向量,其中一条看起来大约是这个样子:
$(500,240,25,13,2312.15)^\mathsf{T}$
可对这一组五维向量进行分析和挖掘,很多机器学习算法的复杂度和数据的维数有着密切关系,甚至与维数呈指数级关联。这里只是区区五维的数据,但实际中处理成千上万甚至几十万维的情况并不罕见,在这种情况下,机器学习的资源消耗是不可接受的,因此必须对数据进行降维。
1.3 降维问题
降维意味着信息丢失,不过鉴于实际数据本身常常存在相关性,可以在降维的同时将信息的损失尽量降低。
例如上面淘宝店铺的数据,从经验可知,“浏览量” 和 “访客数” 、 “下单数” 和 “成交数” 往往具有较强的相关关系。这里使用 “相关关系” 这个词,可以直观理解为 “当某一天这个店铺的浏览量较高(或较低)时,应该很大程度上认为这天的访客数也较高(或较低)”。
这种情况表明,如果删除浏览量或访客数其中一个指标,应该期待并不会丢失太多信息。因此可以删除一个,以降低机器学习算法的复杂度。
上面给出的是降维的朴素思想描述,可以有助于直观理解降维的动机和可行性,但并不具有操作指导意义。例如,到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤?
要回答上面的问题,就要对降维问题进行数学化和形式化的讨论,而PCA是一种具有严格数学基础并且已被广泛采用的降维方法。
2 相关数学知识
数据被抽象为一组向量,那么就要研究一些向量的数学性质,而这些数学性质将成为后续导出PCA的理论基础。
2.1 内积与投影
内积
内积:两个维数相同的向量的内积被定义为:
$(a_1,a_2,\cdots,a_n)^\mathsf{T}\cdot (b_1,b_2,\cdots,b_n)^\mathsf{T}=a_1b_1+a_2b_2+\cdots+a_nb_n$
内积运算将两个向量映射为一个实数。
投影
假设 $A$ 和 $B$ 是两个 $n$ 维向量, $n$ 维向量可以等价表示为 $n$ 维空间中的一条从原点发射的有向线段,为了简单起见假设 $A$ 和 $B$ 均为二维向量,则 $A=(x_1,y_1)$,$B=(x_2,y_2)$。则在二维平面上 $A$ 和 $B$ 可以用两条发自原点的有向线段表示,见下图:
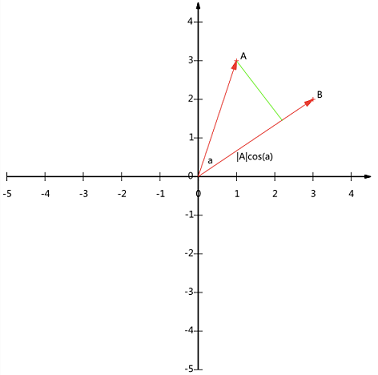
现从 $A$ 点向 $B$ 所在直线引一条垂线。垂线与 $B$ 的交点叫做 $A$ 在 $B$ 上的投影,再设 $A$ 与 $B$ 的夹角是 $a$,则投影的矢量长度为 $|A|cos(a)$ ,其中 $|A|=\sqrt{x_1^2+y_1^2}$ 是向量 $A$ 的模,也就是 $A$ 线段的标量长度。
这里区分了矢量长度和标量长度,标量长度总是大于等于 $0$,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。
将内积表示为另一种熟悉的形式:
$A\cdot B=|A||B|cos(a)$
$A$ 与 $B$ 的内积等于 $A$ 到 $B$ 的投影长度乘以 $B$ 的模。再进一步,假设 $B$ 的模为 $1$,即让 $|B|=1$,就变成:
$A\cdot B=|A|cos(a)$
等价于设向量 $B$ 的模为 $1$,则 $A$ 与 $B$ 的内积值等于 $A$ 向 $B$ 所在直线投影的矢量长度,这是内积的一种几何解释。
2.2 基
一个二维向量对应二维笛卡尔直角坐标系中从原点出发的一个有向线段。如下面这个向量:
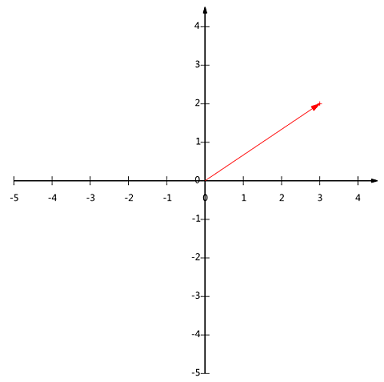
在代数表示方面,经常用线段终点的点坐标表示向量,如上面的向量表示为 $(3,2)$。
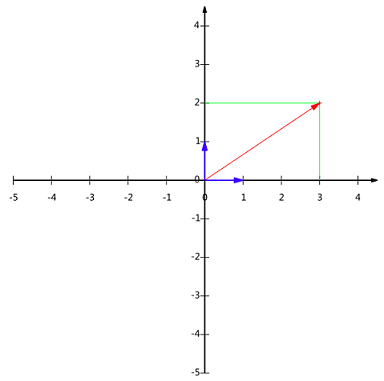
通常只有一个 $(3,2)$ 不能精确表示一个向量。这里 $3$ 实际表示向量在 $x$ 轴上的投影值是 $3$ ,在 $y$ 轴上的投影值是 $2$。相当于隐式引入一个定义:以 $x$ 轴和 $y$ 轴上正方向长度为 $1$ 的向量为标准。向量 $(3,2)$ 实际在 $x$ 轴投影为 $3$ 而 $y$ 轴的投影为 2。注意投影是一个矢量,可以为负。
正式的说,向量 $(x,y)$ 表示线性组合:
$x(1,0)^\mathsf{T}+y(0,1)^\mathsf{T}$
不难证明所有二维向量都可表示为线性组合。此处 $(1,0)$ 和 $(0,1)$ 叫做二维空间中的一组基。
要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值。通常默认以 $(1,0)$ 和 $(0,1)$ 为基。
之所以默认选择 $(1,0)$ 和 $(0,1)$ 为基,因为它们分别是 $x$ 和 $y$ 轴正方向上的单位向量,因此使得二维平面上点坐标和向量一一对应。实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以认为是两个不在一条直线上的向量。
例如,$(1,1)$ 和 $(-1,1)$ 也可成为一组基。一般来说,基的模是 $1$,因为从内积的意义可以看到,如果基的模是 $1$,那么就可用向量点乘基直接获得其在新基上的坐标。实际上,对应任何一个向量总可以找到其同方向上模为 $1$ 的向量,只要让两个分量分别除以模。例如,上面的基可以变为 $(\frac{1}{\sqrt{2}} ,\frac{1}{\sqrt{2}})$ 和 $(-\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}})$ 。
想获得 $(3,2)$ 在新基上的坐标,即在两个方向上的投影矢量值,根据内积的几何意义,要分别计算 $(3,2)$ 和两个基的内积,得到新的坐标为 $(\frac{5}{\sqrt{2}},-\frac{1}{\sqrt{2}})$ 。下图给出新的基以及 $(3,2)$ 在新基上坐标值的示意图:
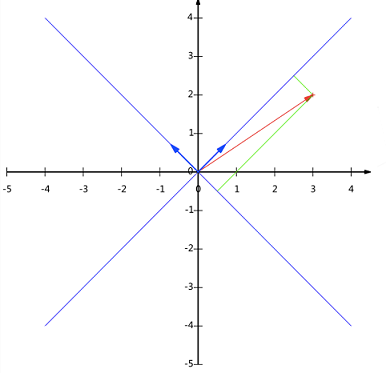
要注意的是,例子中基是正交的(即内积为 $0$,或说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好性质,所以一般使用正交基。
2.3 基变换的矩阵表示
下面找一种简便的方式来表示基变换。将 $(3,2)$ 变换为新基上的坐标,用 $(3,2)$ 与第一个基做内积运算,作为第一个新的坐标分量,然后用 $(3,2)$ 与第二个基做内积运算,作为第二个新坐标的分量。实际上,可用矩阵相乘形式简洁的表示:
$\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix} \begin{pmatrix} 3 \\ 2 \end{pmatrix} = \begin{pmatrix} 5/\sqrt{2} \\ -1/\sqrt{2}\end{pmatrix}$
其中矩阵的两行分别为两个基,乘以原向量,结果为新基的坐标。推广一下,如果有 $m$ 个二维向量,只要将二维向量按列排成一个 $2$ 行 $m$ 列矩阵,然后用 “基矩阵” 乘这个矩阵,得到这些向量在新基下的值。例如 $(1,1)$ ,$(2,2)$ ,$(3,3)$ ,想变换到刚才那组基上,表示为:
$\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2}\end{pmatrix}\begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3\end{pmatrix}=\begin{pmatrix}2/\sqrt{2} & 4/\sqrt{2} & 6/\sqrt{2} \\0 & 0 & 0\end{pmatrix}$
一般的,如果有 $m$ 个 $n$ 维向量(需要变换的向量,每个向量维度为 $n$ ),想将其变换为由 $r$ 个 $n$ 维向量表示的新空间中。首先将 $r$ 个基按行组成矩阵 $A$ ,然后将要变换的向量按列组成矩阵 $B$ ,那么两矩阵的乘积 $C$ 就是变换结果,其中 $C$ 的第 $m$ 列 为变换后的向量。
数学表示为:
$A_{rn}\ B_{nm}=C_{rm}$
$\ \Longleftrightarrow \begin{pmatrix}a_{11} & a_{11} & \cdots & a_{1n} \\a_{21} & a_{22} & \cdots & a_{2n} \\\vdots & \vdots & \ddots & \vdots \\a_{r1} & a_{r2} & \cdots & a_{rn}\end{pmatrix}*\begin{pmatrix}b_{11} & b_{21} & \cdots & b_{m1} \\b_{12} & b_{22} & \cdots & b_{m2} \\\vdots & \vdots & \ddots & \vdots \\b_{1n} & b_{2n} & \cdots & b_{mn}\end{pmatrix}=\begin{pmatrix}c_{11} & c_{21} & \cdots & c_{m1} \\c_{12} & c_{22} & \cdots & c_{m2} \\\vdots & \vdots & \ddots & \vdots \\c_{1r} & c_{2r} & \cdots & c_{mr}\end{pmatrix}$
要注意的是, $r$ 可以小于 $n$ , $r$ 决定了变换后数据的维数。等价于将一 $n$ 维数据变换到更低的 $r$ 维空间中去,变换后的维度取决于基的数量。
最后,给出矩阵相乘的一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。
2.4 协方差矩阵及优化目标
选择不同的基可对同样一组数据给出不同的表示,若基的数量少于向量本身的维数,则可以达到降维的效果。但还需要知道如何选择基才能得到最优效果。若有一组 $n$ 维向量,现在要将其降到 $r$ 维($r$ 小于 $n$),应该如何选择 $r$ 个基才能最大程度保留原有信息?
举例:假设一个数据由五条记录组成,表示成矩阵形式 $\mathrm{X}$ :
$\mathrm{X} = \begin{pmatrix}1 & 1 & 2 & 4 & 2 \\ 1 & 3 & 3 & 4 & 4\end{pmatrix}$
均值矩阵 $\bar{\mathrm{X}}$:
$\bar{\mathrm{X}} =\begin{pmatrix}\bar{x_{1}} \\\bar{x_{2}}\end{pmatrix}=\begin{pmatrix}2 \\3\end{pmatrix}$
其中每一列为一条数据记录,而一行为一个字段。
首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为 $0$。
变换后变成矩阵 $\mathrm{Y}$:
$\mathrm{Y} = \begin{pmatrix}-1 & -1 & 0 & 2 & 0 \\-2 & 0 & 0 & 1 & 1\end{pmatrix}$
可以看下五条数据在平面直角坐标系内的样子:
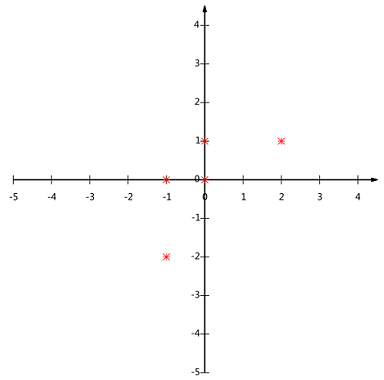
若必须使用一维来表示这些数据,又希望尽量保留原始的信息,怎么处理?
这个问题要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线,用投影值表示原始记录。
那么如何选择这个方向(基)才能尽量保留最多的原始信息?直观的看法是:投影后的投影值尽可能分散。
以上图为例,如果向 $x$ 轴投影,那么最左边的两个点会重叠在一起,中间的两个点也会重叠在一起,于是本身四个各不相同的二维点投影后只剩下两个不同的值了,这是一种严重的信息丢失,同理,如果向 $y$ 轴投影最上面的两个点和分布在x轴上的两个点也会重叠。所以看来 $x$ 和 $y$ 轴都不是最好的投影选择。直观目测,如果向通过第一象限和第三象限的斜线投影,则五个点在投影后还是可以区分的。
下面,用数学方法表述这个问题。
2.5 方差
上文说到,希望投影后投影值尽可能分散,这种分散程度,数学上用方差表述。一个字段的方差是每个元素与字段均值的差的平方和的均值,即:
$Var(a)=\frac{1}{m}\sum \limits _{i=1}^m{(a_i-\mu)^2}$
由于上面已经将每个字段的均值都化为 $ 0$ 了,因此方差可以直接用每个元素的平方和除以元素个数表示:
$Var(a)=\frac{1}{m}\sum \limits _{i=1}^m{a_i^2}$
上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
2.6 协方差
三维降到二维问题,首先希望找到一个方向使得投影后方差最大,完成第一个方向的选择,继而选择第二个投影方向。
如果单纯只选择方差最大的方向,很明显,第二个方向与第一个方向应该是“几乎重合在一起”,显然这样的维度是没有用的,因此,应该有其他约束条件。从直观上说,让两个字段尽可能表示更多的原始信息,不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
数学上两个字段的协方差表示相关性,由于已经让每个字段均值为 $0$,则:
在字段均值为 $0$ 的情况下,两个字段的协方差简洁的表示为其内积除以元素数 $m$ 。
当协方差为 $0$ 时,表示两个字段完全独立。为让协方差为 $0$,选择第二个基时只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的。
至此,得到降维问题的优化目标:将一组 $n$ 维向量降为 $r$ 维($r$ 大于 $0$,小于 $n$),其目标是选择 $r$ 个单位正交基(模为 $1$),使得原始数据变换到这组基上后,各字段两两间协方差为 $0$,而字段的方差则尽可能大(在正交的约束下,取最大的 $r$ 个方差)。
2.7 协方差矩阵
上面导出了优化目标,但这个目标似乎不能直接作为操作指南,因为它只说要什么,但根本没有说怎么做。
最终要达到的目的与字段内方差及字段间协方差有密切关系。因此希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。
假设只有 $a$ 和 $b$ 两个字段,那么将它们按行组成矩阵 $X$:
$X=\begin{pmatrix} a_1 & a_2 & \cdots & a_m \\ b_1 & b_2 & \cdots & b_m \end{pmatrix}$
然后用 $X$ 乘以 $X$ 的转置,并乘上系数 ${\large \frac{1}{m}} $:
$\frac{1}{m}XX^\mathsf{T}=\begin{pmatrix} \frac{1}{m}\sum \limits _{i=1}^m{a_i^2} & \frac{1}{m}\sum \limits_{i=1}^m{a_ib_i} \\ \frac{1}{m}\sum \limits_{i=1}^m{a_ib_i} & \frac{1}{m}\sum \limits_{i=1}^m{b_i^2} \end{pmatrix}$
发现这个矩阵对角线上的两个元素是两个字段的方差,而其它元素是 $a$ 和 $b$ 的协方差,两者被统一到了一个矩阵的。
根据矩阵相乘的运算法则,推广到一般情况:
设有 $m$ 个 $n$ 维数据记录,将其按列排成 $n$ 乘 $m$ 的矩阵 $X$ ,设 $C=\frac{1}{m}XX^\mathsf{T}$ ,则 $C$ 是一个对称矩阵,其对角线分别个各个字段的方差,而第 $i$ 行 $j$ 列和 $j$ 行 $i$ 列元素相同,表示 $i$ 和 $j$ 两个字段的协方差。
2.8 协方差矩阵对角化
根据上述推导,要达到优化目等价于将协方差矩阵对角化:即除对角线外的其它元素化为 $0$,并且在对角线上将元素按大小从上到下排列,这样就达到了优化目的。进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
设原始数据矩阵 $X$ 对应的协方差矩阵为 $C$ ,而 $P$ 是一组基按行组成的矩阵,设 $Y=PX$ ,则 $Y$ 为 $X$ 对 $P$ 做基变换后的数据。设 $Y$ 的协方差矩阵为 $D$ ,推导一下 $D$ 与 $C$ 的关系:
$\begin{array}{l l l} D & = & \frac{1}{m}YY^\mathsf{T} \\ & = & \frac{1}{m}(PX)(PX)^\mathsf{T} \\ & = & \frac{1}{m}PXX^\mathsf{T}P^\mathsf{T} \\ & = & P(\frac{1}{m}XX^\mathsf{T})P^\mathsf{T} \\ & = & PCP^\mathsf{T} \end{array}$
发现要找的 $P$ 不是别的,而是能让原始协方差矩阵对角化的 $P$。换句话说,优化目标变成了寻找一个矩阵 $P$,满足 $PCP^\mathsf{T}$ 是一个对角矩阵,并且对角元素按从大到小依次排列,那么 $P$ 的前 $K$ 行就是要寻找的基,用 $P$ 的前 $K$ 行组成的矩阵乘以 $X$ 就使得 $X$ 从 $n$ 维降到了 $r$ 维并满足上述优化条件。
现在所有焦点都聚焦在了协方差矩阵对角化问题上,由上文知,协方差矩阵 $C$ 是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
1)实对称矩阵不同特征值对应的特征向量必然正交。
2)设特征向量 $\lambda$ 重数为 $r$,则必然存在 $r$ 个线性无关的特征向量对应于 $\lambda$,因此可以将这 $r$ 个特征向量单位正交化。
由上面两条可知,一个 $n$ 行 $n$ 列的实对称矩阵一定可以找到 $n$ 个单位正交特征向量,设这 $n$ 个特征向量为$e_1,e_2,\cdots,e_n$,我们将其按列组成矩阵:
$E=\begin{pmatrix} e_1 & e_2 & \cdots & e_n \end{pmatrix}$
则对协方差矩阵$C$有如下结论:
$E^\mathsf{T}CE=\Lambda=\begin{pmatrix} \lambda_1 & & & \\ & \lambda_2 & & \\ & & \ddots & \\ & & & \lambda_n \end{pmatrix}$
其中 $\Lambda$ 为对角矩阵,其对角元素为各特征向量对应的特征值(可能有重复)。
以上结论不再给出严格的数学证明,对证明感兴趣的朋友可以参考线性代数书籍关于“实对称矩阵对角化”的内容。
到这里,我们发现我们已经找到了需要的矩阵P:
$P=E^\mathsf{T}$
$P$ 是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是 $C$ 的一个特征向量。如果设 $P$ 按照 $Λ$ 中特征值的从大到小,将特征向量从上到下排列,则用 $P$ 的前 $K$ 行组成的矩阵乘以原始数据矩阵 $X$,就得到了需要的降维后的数据矩阵 $Y$。
3 算法及实例
3.1 PCA的算法
PCA的算法步骤:
设有 $m$ 条 $n$ 维数据。
- 将原始数据按列组成 $n$ 行 $m$ 列矩阵 $X$ 。
- 将 $X$ 的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值。
- 求出协方差矩阵 $C=\frac{1}{m}XX^\mathsf{T}$。
- 求出协方差矩阵的特征值及对应的特征向量。
- 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前 $k$ 行组成矩阵 $P$。
- $Y=PX$ 即为降维到 $k$ 维后的数据。
3.2 实例
仍然使用上述数据,其由五条记录组成,其中每一列为一条数据记录,而一行为一个字段。用PCA方法将这组二维数据其降到一维。
Step1:将它表示成矩阵形式:
$\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}$
Step2:发现这个矩阵的每行已经是零均值。
Step3:直接求协方差矩阵:
$ C=\frac{1}{5}\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}\begin{pmatrix} -1 & -2 \\ -1 & 0 \\ 0 & 0 \\ 2 & 1 \\ 0 & 1 \end{pmatrix}=\begin{pmatrix} \frac{6}{5} & \frac{4}{5} \\ \frac{4}{5} & \frac{6}{5} \end{pmatrix}$
Step4:求其特征值和特征向量,求解后特征值为:
$\lambda_1=2,\lambda_2=\frac{2}{5}$
其对应的特征向量分别是:
$c_1=\begin{pmatrix} 1 \\ 1 \end{pmatrix},c_2=\begin{pmatrix} -1 \\ 1 \end{pmatrix}$
其中对应的特征向量分别是一个通解,$c_1$ 和 $c_2$ 可取任意实数。那么标准化后的特征向量为:
$\begin{pmatrix} 1/\sqrt{2} \\ 1/\sqrt{2} \end{pmatrix},\begin{pmatrix} -1/\sqrt{2} \\ 1/\sqrt{2} \end{pmatrix}$
Step5:因此矩阵 $P$ 是:
$P=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}$
可以验证协方差矩阵 $C$ 的对角化:
$PCP^\mathsf{T}=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \\ -1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}\begin{pmatrix} 6/5 & 4/5 \\ 4/5 & 6/5 \end{pmatrix}\begin{pmatrix} 1/\sqrt{2} & -1/\sqrt{2} \\ 1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}=\begin{pmatrix} 2 & 0 \\ 0 & 2/5 \end{pmatrix} $
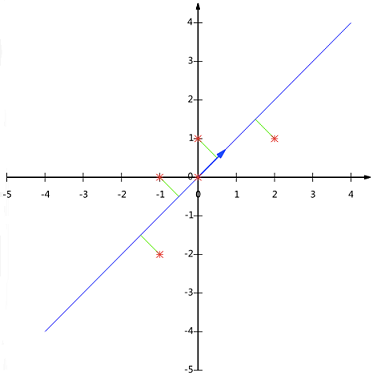
Step6:最后用 $P$ 的第一行乘以数据矩阵,就得到了降维后的表示:
$Y=\begin{pmatrix} 1/\sqrt{2} & 1/\sqrt{2} \end{pmatrix}\begin{pmatrix} -1 & -1 & 0 & 2 & 0 \\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}=\begin{pmatrix} -3/\sqrt{2} & -1/\sqrt{2} & 0 & 3/\sqrt{2} & -1/\sqrt{2} \end{pmatrix}$
降维投影结果如下图:
4 总结
根据上面对PCA的数学原理的解释,我们可以了解到一些PCA的能力和限制。PCA本质上是将方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
因此,PCA也存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关,关于这点就不展开讨论了。另外,PCA假设数据各主特征是分布在正交方向上,如果在非正交方向上存在几个方差较大的方向,PCA的效果就大打折扣了。
最后需要说明的是,PCA是一种无参数技术,也就是说面对同样的数据,如果不考虑清洗,谁来做结果都一样,没有主观参数的介入,所以PCA便于通用实现,但是本身无法个性化的优化。
机器学习——主成分分析(PCA)的更多相关文章
- 机器学习--主成分分析(PCA)算法的原理及优缺点
一.PCA算法的原理 PCA(principle component analysis),即主成分分析法,是一个非监督的机器学习算法,是一种用于探索高维数据结构的技术,主要用于对数据的降维,通过降维可 ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- 机器学习之主成分分析PCA原理笔记
1. 相关背景 在许多领域的研究与应用中,通常需要对含有多个变量的数据进行观测,收集大量数据后进行分析寻找规律.多变量大数据集无疑会为研究和应用提供丰富的信息,但是也在一定程度上增加了数据采集的 ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 线性判别分析(LDA), 主成分分析(PCA)及其推导【转】
前言: 如果学习分类算法,最好从线性的入手,线性分类器最简单的就是LDA,它可以看做是简化版的SVM,如果想理解SVM这种分类器,那理解LDA就是很有必要的了. 谈到LDA,就不得不谈谈PCA,PCA ...
- 一步步教你轻松学主成分分析PCA降维算法
一步步教你轻松学主成分分析PCA降维算法 (白宁超 2018年10月22日10:14:18) 摘要:主成分分析(英语:Principal components analysis,PCA)是一种分析.简 ...
- 机器学习13—PCA学习笔记
主成分分析PCA 机器学习实战之PCA test13.py #-*- coding:utf-8 import sys sys.path.append("pca.py") impo ...
- 05-03 主成分分析(PCA)
目录 主成分分析(PCA) 一.维数灾难和降维 二.主成分分析学习目标 三.主成分分析详解 3.1 主成分分析两个条件 3.2 基于最近重构性推导PCA 3.2.1 主成分分析目标函数 3.2.2 主 ...
- SciKit-Learn 可视化数据:主成分分析(PCA)
## 保留版权所有,转帖注明出处 章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Le ...
随机推荐
- SpringMVC学习04(数据处理及跳转)
4.数据处理及跳转 4.1结果跳转方式 4.1.1 ModelAndView 设置ModelAndView对象 , 根据view的名称 , 和视图解析器跳到指定的页面 . 页面 : {视图解析器前缀} ...
- 阿里云NAS文件迁移项目实践
阿里云文件存储NAS是阿里云推出的用于传统文件共享的,使用NFS协议挂载的共享文件夹. 产品背景 下图是NAS和阿里云另一明星产品OSS以及块存储EBS的区别 NAS核心优势:无需修改程序,挂载之后, ...
- TreeUtil.java
package com.infish.util; import java.lang.reflect.Method; import java.util.ArrayList; import java.ut ...
- 零基础学Java之Java学习笔记(三):变量和数据类型
为什么需要变量? 变量是一个程序的基本组成单位. 变量的概念: 变量相当于内存中一个数据存储空间的表示,你可以把变量看做是一个房间的门牌号,通过门牌号我们可以找到房 间,而通过变量名可以访问到变量(值 ...
- 深入理解HTTP请求流程
以前写过一篇博客,叫做HTTP的报文分析:https://blog.csdn.net/ZripenYe/article/details/119593269但是感觉还是不太深入.不够全面,顶多了解个大概 ...
- DVWA-全等级验证码Insecure CAPTCHA
DVWA简介 DVWA(Damn Vulnerable Web Application)是一个用来进行安全脆弱性鉴定的PHP/MySQL Web应用,旨在为安全专业人员测试自己的专业技能和工具提供合法 ...
- chcon命令详解
导读 chcon命令是修改对象(文件)的安全上下文,比如:用户.角色.类型.安全级别.也就是将每个文件的安全环境变更至指定环境.使用--reference选项时,把指定文件的安全环境设置为与参考文件相 ...
- sql查询第10条到第20条数据
select top(10) * from T1 where Id >= (select MAX(Id) from (select top(20) * from T1 order by Id) ...
- yield 关键字的认知
namespace ConsoleDemo{ class Program { static void Main(string[] args) { string[] str = { "1&qu ...
- 使用git下载码云仓库文件步骤总结
从码云下载文件的两种方式(私服时) 1.让私服管理者复制链接,然后你加入私服: 2.生成公钥,让私服管理者添加你的公钥. 在eclipse中找到git,输入自己的登录账号和密码,下载文件到本地仓库,然 ...