flink---实时项目--day02-----1. 解析参数工具类 2. Flink工具类封装 3. 日志采集架构图 4. 测流输出 5. 将kafka中数据写入HDFS 6 KafkaProducer的使用 7 练习
1. 解析参数工具类(ParameterTool)
该类提供了从不同数据源读取和解析程序参数的简单实用方法,其解析args时,只能支持单只参数。
用来解析main方法传入参数的工具类
public class ParseArgsKit {
public static void main(String[] args) {
ParameterTool parameters = ParameterTool.fromArgs(args);
String host = parameters.getRequired("redis.host");
String port = parameters.getRequired("redis.port");
System.out.println(host);
System.out.println(port);
}
}
参数的输入格式如下:
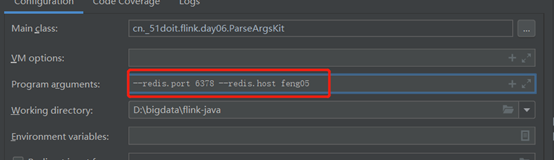
这种解析程序参数的的优点是参数不需要按照顺序指定,但若是参数过多的话,写起来不方便,这时我们可以选择使用解析配置文件的工具类
- 用来解析配置文件的工具类,该配置文件的路径自己指定
public class ParseArgsKit {
public static void main(String[] args) throws IOException {
ParameterTool parameters = ParameterTool.fromPropertiesFile("E:\\flink\\conf.properties");
String host = parameters.getRequired("redis.host");
String port = parameters.getRequired("redis.port");
System.out.println(host);
System.out.println(port);
}
}
配置文件conf.properties
redis.host=feng05
redis.port=4444
2. Flink工具类封装(创建KafkaSource)
RealtimeETL


package cn._51doit.flink.day06; import cn._51doit.flink.Utils.FlinkUtils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream; public class RealtimeETL {
public static void main(String[] args) throws Exception {
ParameterTool parameters = ParameterTool.fromPropertiesFile("E:\\flink\\conf.properties");
//使用Flink拉取Kafka中的数据,对数据进行清洗、过滤整理
DataStream<String> lines = FlinkUtils.createKafkaStream(parameters, SimpleStringSchema.class);
lines.print();
FlinkUtils.env.execute();
}
}
FlinkUtils
package cn._51doit.flink.Utils; import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import java.io.IOException;
import java.util.Arrays;
import java.util.List;
import java.util.Properties; public class FlinkUtils {
public static final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
public static <T> DataStream<T> createKafkaStream(ParameterTool parameters, Class<? extends DeserializationSchema<T>> clazz) throws IOException, IllegalAccessException, InstantiationException {
// 设置checkpoint的间隔时间
env.enableCheckpointing(parameters.getLong("checkpoint.interval",300000));
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
//就是将job cancel后,依然保存对应的checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
String checkPointPath = parameters.get("checkpoint.path");
if(checkPointPath != null){
env.setStateBackend(new FsStateBackend(checkPointPath));
}
int restartAttempts = parameters.getInt("restart.attempts", 30);
int delayBetweenAttempts = parameters.getInt("delay.between.attempts", 30000);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(restartAttempts, delayBetweenAttempts));
Properties properties = parameters.getProperties();
String topics = parameters.getRequired("kafka.topics");
List<String> topicList = Arrays.asList(topics.split(",")); FlinkKafkaConsumer<T> flinkKafkaConsumer = new FlinkKafkaConsumer<T>(topicList, clazz.newInstance(), properties);
//在Checkpoint的时候将Kafka的偏移量不保存到Kafka特殊的Topic中,默认是true
flinkKafkaConsumer.setCommitOffsetsOnCheckpoints(false);
return env.addSource(flinkKafkaConsumer);
}
}
此处的重点是FlinkKafkaConsumer这个类的使用,下图显示的是其中一种构造方法
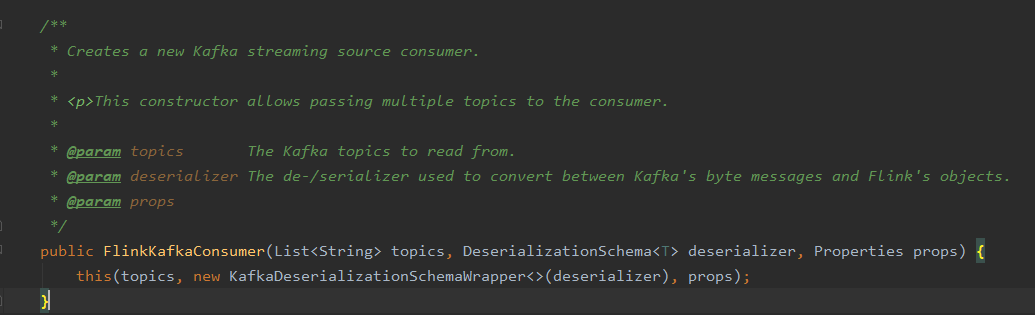
参数一:topic名或 topic名的列表
Flink Kafka Consumer 需要知道如何将来自Kafka的二进制数据转换为Java/Scala对象。DeserializationSchema接口允许程序员指定这个序列化的实现。该接口的 T deserialize(byte[]message) 会在收到每一条Kafka的消息的时候被调用。我们通常会实现 AbstractDeserializationSchema,它可以描述被序列化的Java/Scala类型到Flink的类型(TypeInformation)的映射。如果用户的代码实现了DeserializationSchema,那么就需要自己实现getProducedType(...) 方法。
为了方便使用,Flink提供了一些已实现的schema:
(1) TypeInformationSerializationSchema (andTypeInformationKeyValueSerializationSchema) ,他们会基于Flink的TypeInformation来创建schema。这对于那些从Flink写入,又从Flink读出的数据是很有用的。这种Flink-specific的反序列化会比其他通用的序列化方式带来更高的性能。
(2)JsonDeserializationSchema (andJSONKeyValueDeserializationSchema) 可以把序列化后的Json反序列化成ObjectNode,ObjectNode可以通过objectNode.get(“field”).as(Int/String/…)() 来访问指定的字段。
(3)SimpleStringSchema可以将消息反序列化为字符串。当我们接收到消息并且反序列化失败的时候,会出现以下两种情况: 1) Flink从deserialize(..)方法中抛出异常,这会导致job的失败,然后job会重启;2) 在deserialize(..) 方法出现失败的时候返回null,这会让Flink Kafka consumer默默的忽略这条消息。请注意,如果配置了checkpoint 为enable,由于consumer的失败容忍机制,失败的消息会被继续消费,因此还会继续失败,这就会导致job被不断自动重启。
参数二:
反序列化约束,以便于Flink决定如何反序列化从Kafka获得的数据。
参数三
Kafka consumer的属性配置,下面三个属性配置是必须的:

3 日志采集架构图
(1)以前学习离线数仓时,采集数据是使用flume的agent级联的方式,中间层是为了增大吞吐(负载均衡),和容错(failOver),这两个可以同时实现(多个sink)
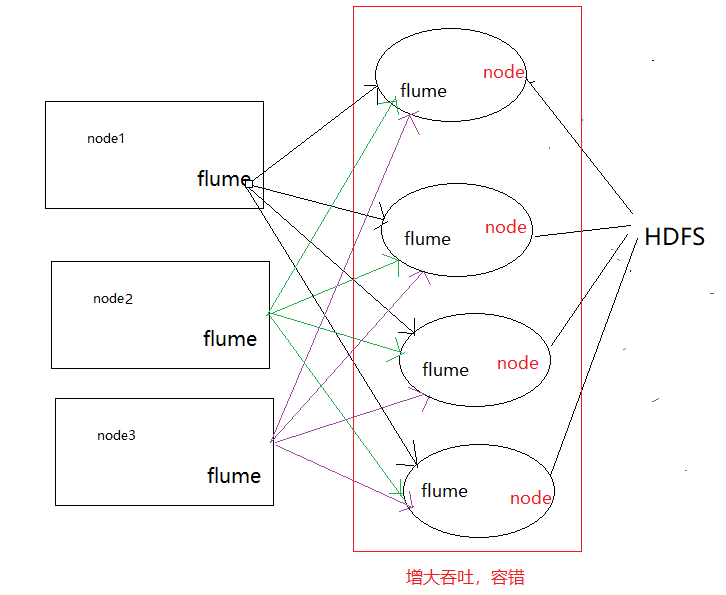
这种agent级联的方式是一种过时的做法了,在flume1.7前一半使用这种,flume1.7后,有kafkachannel,这种方式就被取代了,其一级agent实现不了容错。更好的方式如下
(2)直接source+kafkaChannel的形式,kafka直接解决掉高吞吐量和容错的问题,并且一级agent中还实现了容错如下图
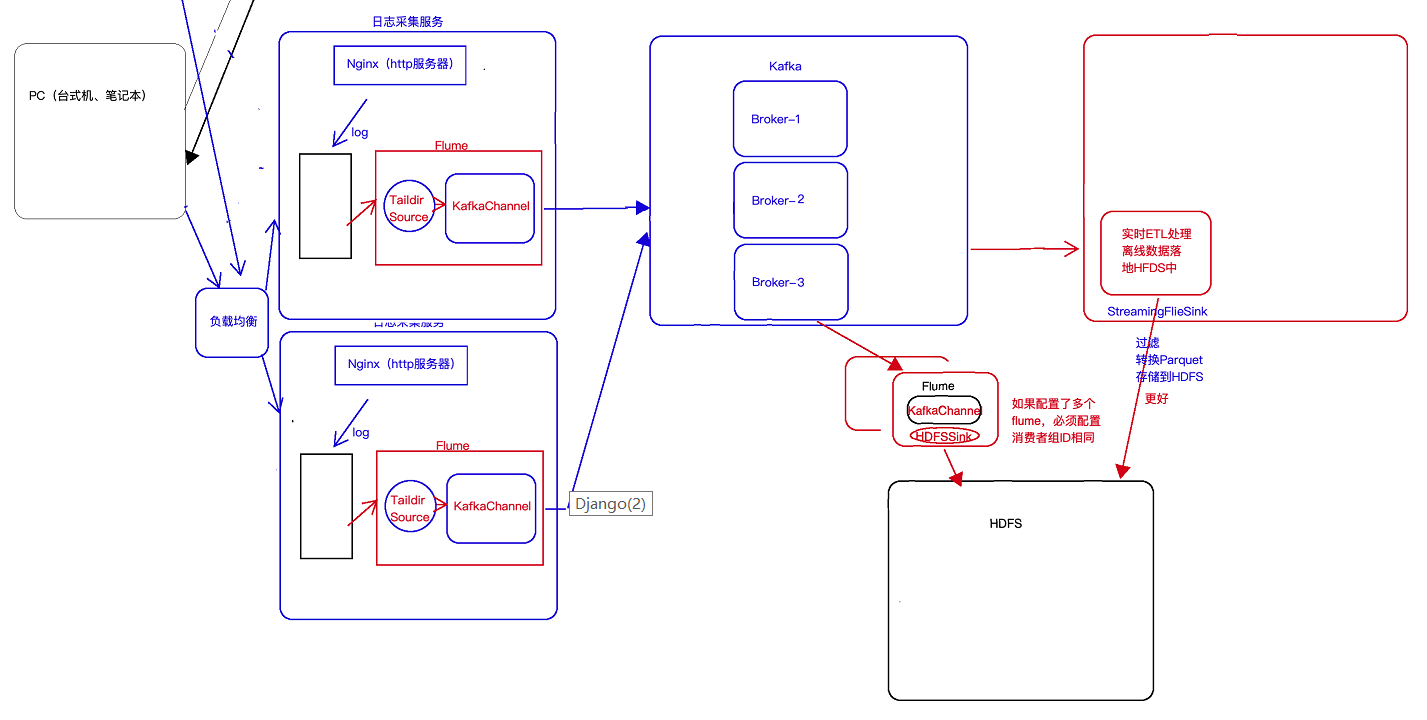
4. 测流输出
测流输出与split+select相似。当单存的过滤出某类数据时,用filter效率会高点,但若是对某个数据进行分类时,若再使用filter的话,则要过滤多次,即运行多次任务,效率比较低。若是使用测流输出,运行一次即可
SideOutPutDemo
package cn._51doit.flink.day06; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag; public class SideOutPutDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("feng05", 8888); SingleOutputStreamOperator<Tuple3<String, String, String>> tpData = lines.map(new MapFunction<String, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> map(String value) throws Exception {
String[] fields = value.split(" ");
String event = fields[0];
String guid = fields[1];
String timestamp = fields[2];
return Tuple3.of(event, guid, timestamp);
}
});
OutputTag<Tuple3<String, String, String>> viewTag = new OutputTag<Tuple3<String, String, String>>("view-tag"){};
OutputTag<Tuple3<String, String, String>> activityTag = new OutputTag<Tuple3<String, String, String>>("activity-tag"){};
OutputTag<Tuple3<String, String, String>> orderTag = new OutputTag<Tuple3<String, String, String>>("order-tag"){}; SingleOutputStreamOperator<Tuple3<String, String, String>> outDataStream = tpData.process(new ProcessFunction<Tuple3<String, String, String>, Tuple3<String, String, String>>() {
@Override
public void processElement(Tuple3<String, String, String> input, Context ctx, Collector<Tuple3<String, String, String>> out) throws Exception {
// 将数据打上标签
String type = input.f0;
if (type.equals("pgview")) {
ctx.output(viewTag, input);
} else if (type.equals("activity")) {
ctx.output(activityTag, input);
} else {
ctx.output(orderTag, input);
}
// 输出主流的数据,此处不输出主流数据的话,在外面则获取不到主流数据
out.collect(input);
}
});
// 输出的测流只能通过getSideOutput
// DataStream<Tuple3<String, String, String>> viewDataStream = outDataStream.getSideOutput(viewTag);
// viewDataStream.print();
outDataStream.print();
env.execute();
}
}
改进使用processElement方法
package cn._51doit.flink.day06; import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag; /**
* 1.将数据整理成Tuple3
* 2.然后使用侧流输出将数据分类
*/
public class SideOutputsDemo2 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // view,pid,2020-03-09 11:42:30
// activity,a10,2020-03-09 11:42:38
// order,o345,2020-03-09 11:42:38
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); OutputTag<Tuple3<String, String, String>> viewTag = new OutputTag<Tuple3<String, String, String>>("view-tag") {
};
OutputTag<Tuple3<String, String, String>> activityTag = new OutputTag<Tuple3<String, String, String>>("activity-tag") {
};
OutputTag<Tuple3<String, String, String>> orderTag = new OutputTag<Tuple3<String, String, String>>("order-tag") {
}; //直接调用process方法
SingleOutputStreamOperator<Tuple3<String, String, String>> tpDataStream = lines.process(new ProcessFunction<String, Tuple3<String, String, String>>() { @Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
} @Override
public void processElement(String input, Context ctx, Collector<Tuple3<String, String, String>> out) throws Exception { //1.将字符串转成Tuple2
String[] fields = input.split(",");
String type = fields[0];
String id = fields[1];
String time = fields[2];
Tuple3<String, String, String> tp = Tuple3.of(type, id, time); //2.对数据打标签
//将数据打上标签
if (type.equals("view")) {
//输出数据,将数据和标签关联
ctx.output(viewTag, tp); //ctx.output 输出侧流的
} else if (type.equals("activity")) {
ctx.output(activityTag, tp);
} else {
ctx.output(orderTag, tp);
}
//输出主流的数据
out.collect(tp);
}
}); //输出的测流只能通过getSideOutput
DataStream<Tuple3<String, String, String>> viewDataStream = tpDataStream.getSideOutput(viewTag); //分别处理各种类型的数据。
viewDataStream.print(); env.execute(); }
}
5. 将kafka中数据写入HDFS
- 方案一:使用flume,具体见下图:
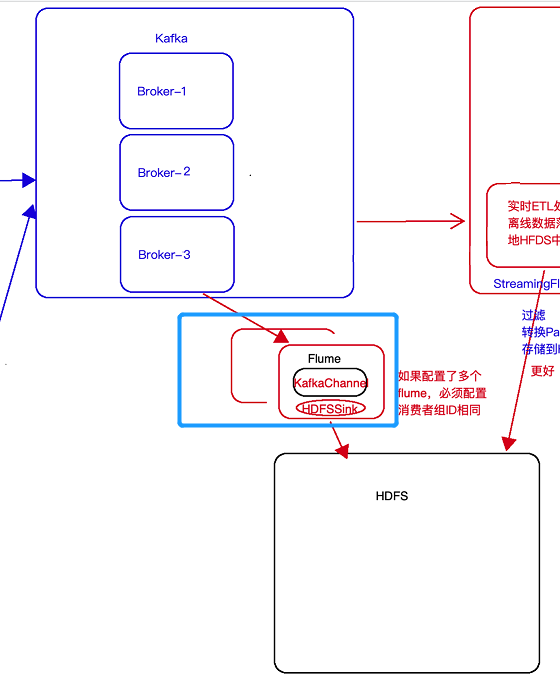
- 方案二:使用StreamingFileSink,此种形式更加好,其可以按照需求滚动生成文件
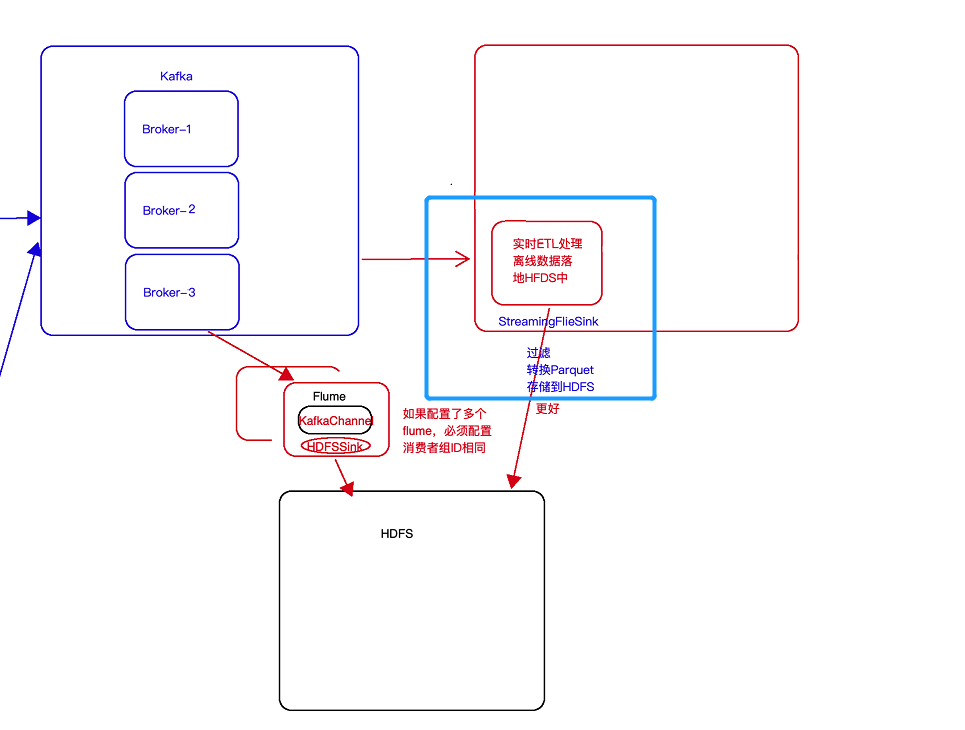
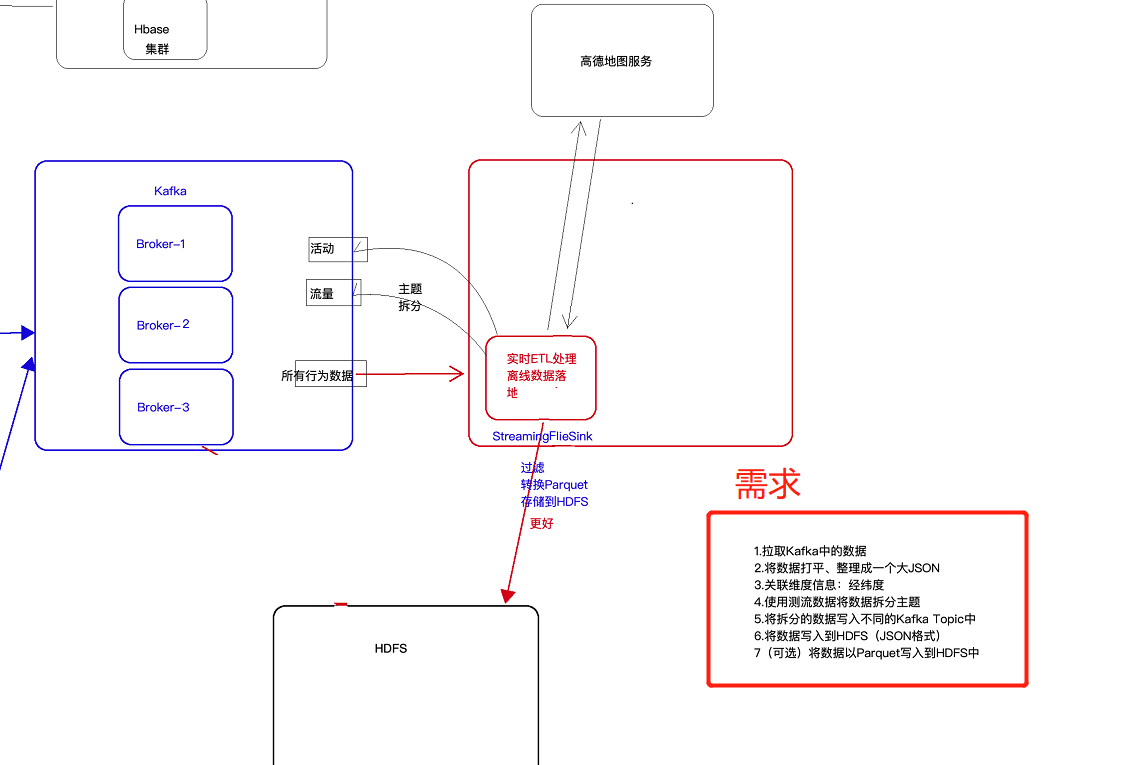
6 KafkaProducer的使用
现在的需求是将kafka中的数据进行处理(分主题等),然后写回kafka中去。如下所示
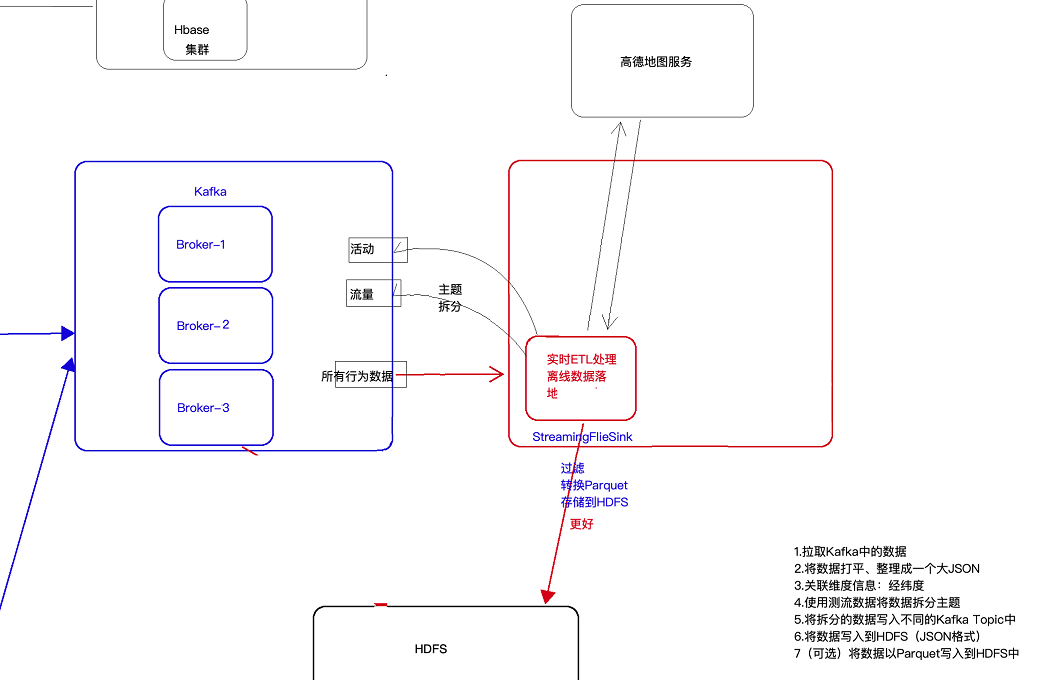
这时可以使用flink的自定义sink往kafka中写数据,具体代码如下
KafkaSinkDemo(老版本1.9以前)
package cn._51doit.flink.day06; import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; public class KafkaSinkDemo { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> lines = env.socketTextStream("localhost", 8888); FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<String>(
"node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092", // broker list
"etl-test", // target topic
new SimpleStringSchema()); // serialization schema myProducer.setWriteTimestampToKafka(true); //将数据写入到Kafka
lines.addSink(myProducer); env.execute(); }
}
KafkaSinkDemo2(flink1.9以后)
package cn._51doit.flink.day06; import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import java.util.Properties; /**
* 使用新的Kafka Sink API
*/
public class KafkaSinkDemo2 { public static void main(String[] args) throws Exception { ParameterTool parameters = ParameterTool.fromPropertiesFile(args[0]);
DataStream<String> lines = FlinkUtils.createKafkaStream(parameters, SimpleStringSchema.class);
//写入Kafka的topic
String topic = "etl-test";
//设置Kafka相关参数
Properties properties = new Properties();
properties.setProperty("transaction.timeout.ms",1000 * 60 * 5 + "");
properties.setProperty("bootstrap.servers",
"node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092");
//创建FlinkKafkaProducer
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<String>(
topic, //指定topic
new KafkaStringSerializationSchema(topic), //指定写入Kafka的序列化Schema
properties, //指定Kafka的相关参数
FlinkKafkaProducer.Semantic.EXACTLY_ONCE //指定写入Kafka为EXACTLY_ONCE语义
);
//添加KafkaSink
lines.addSink(kafkaProducer);
//执行
FlinkUtils.env.execute(); }
}
这里需要注意一个点,要设置如下参数:
properties.setProperty("transaction.timeout.ms",1000 * 60 * 5 + "");
kafka brokers默认的最大事务超时时间为15min,生产者设置事务时不允许大于这个值。但是在默认的情况下,FlinkKafkaProducer设置事务超时属性为1h,超过了默认transaction.max.ms 15min。这个时候我们选择生产者的事务超时属性transaction.timeout.ms小于15min即可
7. 练习(未练)
flink---实时项目--day02-----1. 解析参数工具类 2. Flink工具类封装 3. 日志采集架构图 4. 测流输出 5. 将kafka中数据写入HDFS 6 KafkaProducer的使用 7 练习的更多相关文章
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
- 3.Flink实时项目之流程分析及环境搭建
1. 流程分析 前面已经将日志数据(ods_base_log)及业务数据(ods_base_db_m)发送到kafka,作为ods层,接下来要做的就是通过flink消费kafka 的ods数据,进行简 ...
- 4.Flink实时项目之数据拆分
1. 摘要 我们前面采集的日志数据已经保存到 Kafka 中,作为日志数据的 ODS 层,从 kafka 的ODS 层读取的日志数据分为 3 类, 页面日志.启动日志和曝光日志.这三类数据虽然都是用户 ...
- 6.Flink实时项目之业务数据分流
在上一篇文章中,我们已经获取到了业务数据的输出流,分别是dim层维度数据的输出流,及dwd层事实数据的输出流,接下来我们要做的就是把这些输出流分别再流向对应的数据介质中,dim层流向hbase中,dw ...
- 7.Flink实时项目之独立访客开发
1.架构说明 在上6节当中,我们已经完成了从ods层到dwd层的转换,包括日志数据和业务数据,下面我们开始做dwm层的任务. DWM 层主要服务 DWS,因为部分需求直接从 DWD 层到DWS 层中间 ...
- 9.Flink实时项目之订单宽表
1.需求分析 订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户.地区.商品.品类.品牌等等.为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合 ...
- 1.Flink实时项目前期准备
1.日志生成项目 日志生成机器:hadoop101 jar包:mock-log-0.0.1-SNAPSHOT.jar gmall_mock |----mock_common |----mock ...
- 8.Flink实时项目之CEP计算访客跳出
1.访客跳出明细介绍 首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来.那么就要抓住几个特征: 该页面是用户近期访问的第一个页面,这个可以通过该页面是否有上一个页面(last_p ...
- 10.Flink实时项目之订单维度表关联
1. 维度查询 在上一篇中,我们已经把订单和订单明细表join完,本文将关联订单的其他维度数据,维度关联实际上就是在流中查询存储在 hbase 中的数据表.但是即使通过主键的方式查询,hbase 速度 ...
随机推荐
- DeWeb 电脑和手机动态适配
DeWeb 做多平台适配很方便! 多平台适配代码在OnMouseUp中. X,Y分别表示当前设备的Width/Height: Button : mbLeft : 屏幕纵向, mbRight:屏幕横向: ...
- Vmware 中 Kali linux 2020 设置共享文件夹
前言 kali2020已经自带vmware-tools工具,因此,只要是原装的kali2020是不需要继续安装vmhgfs工具的. 过程 vmware 设置共享目录 使用vmware-hgfsclie ...
- Spring Cloud Alibaba 使用Seata解决分布式事务
为什么会产生分布式事务? 随着业务的快速发展,网站系统往往由单体架构逐渐演变为分布式.微服务架构,而对于数据库则由单机数据库架构向分布式数据库架构转变.此时,我们会将一个大的应用系统拆分为多个可以独立 ...
- 浅谈springboot自动配置原理
前言 springboot自动配置关键在于@SpringBootApplication注解,启动类之所以作为项目启动的入口,也是因为该注解,下面浅谈下这个注解的作用和实现原理 @SpringBootA ...
- 羽夏看Win系统内核——系统调用篇
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- uni-app APP端隐藏导航栏自定义按钮
话不多说,上代码 // #ifdef APP-PLUS var webView = this.$mp.page.$getAppWebview(); // 修改buttons webView.setTi ...
- [python]selenium常用的操作
浏览器 1.火狐浏览器 br = webdriver.Firefox() #最大化窗口br.maximize_window() br.get('http://baidu.com') 2.谷歌浏览器 b ...
- Linux usb 1. 总线简介
文章目录 1. USB 发展历史 1.1 USB 1.0/2.0 1.2 USB 3.0 1.3 速度识别 1.4 OTG 1.5 phy 总线 1.6 传输编码方式 2. 总线拓扑 2.1 Devi ...
- mysql 存储ipv6
自定义列 https://groups.google.com/g/sqlalchemy/c/lZw0GipVYFw https://docs.sqlalchemy.org/en/14/core/cus ...
- Effective C++ 总结笔记(一)
一.让自己习惯C++ 01.视C++为一个语言联邦 c++是多重范型编程 语言,视c++包括4种次语言: 1:C 2:Object-Oreinted C++: 3:Template C++: 4:ST ...