Hbase(一)【入门安装及高可用】
一.Zookeeper正常部署
Zookeeper集群的正常部署并启动
二.Hadoop正常部署
Hadoop集群的正常部署并启动
三.Hbase部署
1.下载
下载地址:https://hbase.apache.org/downloads.html
2.解压
当前安装版本为hbase-2.0.5,将Hbase解压至指定目录,改名为hbase
tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module
mv /opt/module/hbase-2.0.5 /opt/module/hbase
3.相关配置
1)配置环境变量
修改my_env.sh
sudo vim /etc/profile.d/my_env.sh
添加以下内容
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
source一下
source /etc/profile
将my_env.sh分发其他节点,都source一下
xsync /etc/profile.d/my_env.sh
source /etc/profile
2)修改hbase-env.sh
修改/hbase/conf/hbase-env.sh添加以下内容
export HBASE_MANAGES_ZK=false
3)修改hbase-site.xml
修改成以下内容
hbase.rootdir: 在hdfs的数据存储路径
hbase.zookeeper.quorum: zookeeper集群节点
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/HBase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
4)修改regionservers文件
Hregionserver节点配置,添加以下内容
hadoop102
hadoop103
hadoop104
4.分发文件
xsync hbase/
5.启动、关闭
方式一:群起
[hadoop@hadoop102 hbase]$ bin/start-hbase.sh
对应的停止服务:
[hadoop@hadoop102 hbase]$ bin/stop-hbase.sh
方式二:各节点单独启动
[hadoop@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[hadoop@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
注:在哪个节点启动master,哪个节点就是Hmaster。
提示:如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
修复方法
a、同步时间服务
b、属性:hbase.master.maxclockskew设置更大的值
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
6.验证
启动hbase(先启动zookeeper和hdfs)
[hadoop@hadoop102 ~]$ start-hbase.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
running master, logging to /opt/module/hbase/logs/hbase-atguigu-master-hadoop102.out
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hbase/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hadoop104: running regionserver, logging to /opt/module/hbase/logs/hbase-atguigu-regionserver-hadoop104.out
hadoop103: running regionserver, logging to /opt/module/hbase/logs/hbase-atguigu-regionserver-hadoop103.out
hadoop102: running regionserver, logging to /opt/module/hbase/logs/hbase-atguigu-regionserver-hadoop102.out
hadoop103: running master, logging to /opt/module/hbase/logs/hbase-atguigu-master-hadoop103.out
jps看一下
[hadoop@hadoop102 ~]$ myjps
================ hadoop102 =====================
3364 NameNode
3497 DataNode
24106 Jps
3117 QuorumPeerMain
23678 HRegionServer
23487 HMaster
================ hadoop103 =====================
2024 DataNode
1882 QuorumPeerMain
11037 HRegionServer
11533 Jps
================ hadoop104 =====================
9536 Jps
1879 QuorumPeerMain
9290 HRegionServer
2124 SecondaryNameNode
2014 DataNode
四.HMaster的高可用
目的:增加hadoop103作为Hmaster的备用节点
1)在hadoop102关闭hbase集群
stop-hbase.sh
2)在%hbase_home%/conf 下增加backup-masters文件
vim hbase/conf/backup-masters
添加以下内容
hadoop103
3)将backup-masters文件分发至其他节点
xsync hbase/conf/backup-masters
4)在hadoop102启动集群
start-hbase.sh
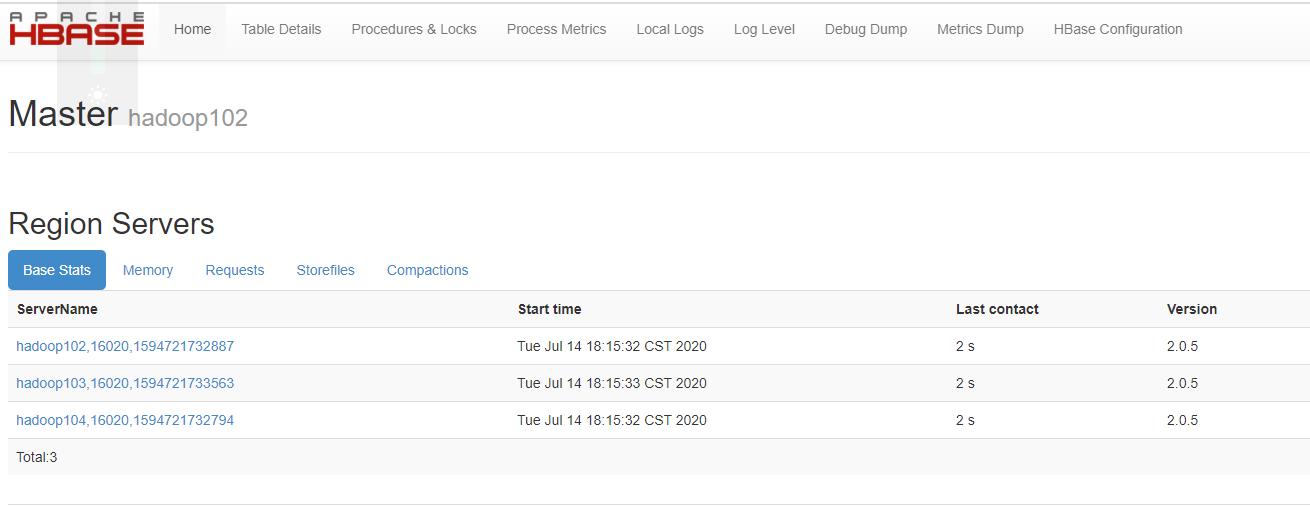
5)观察web页面:
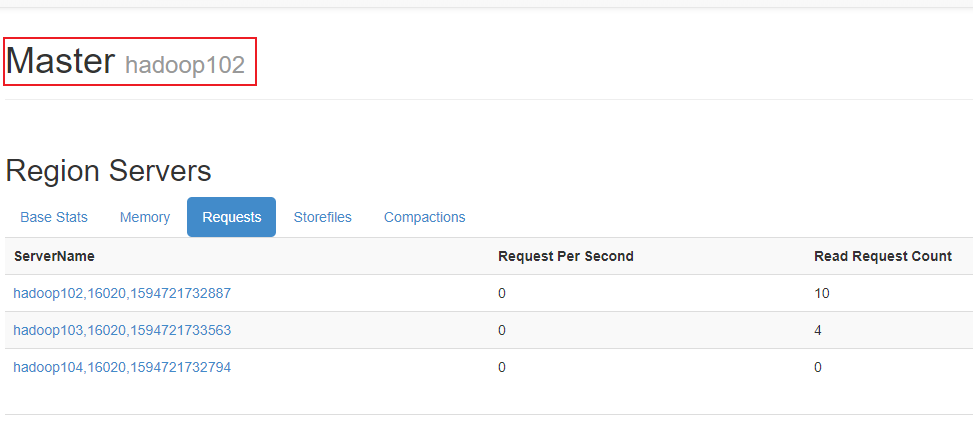
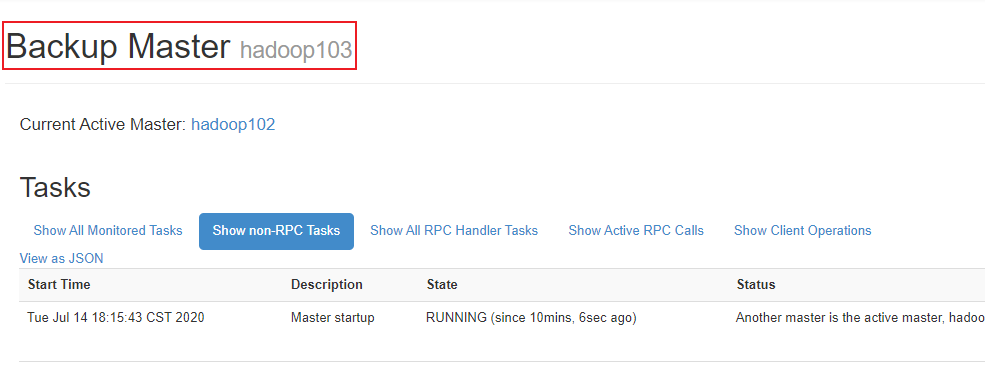
6)验证
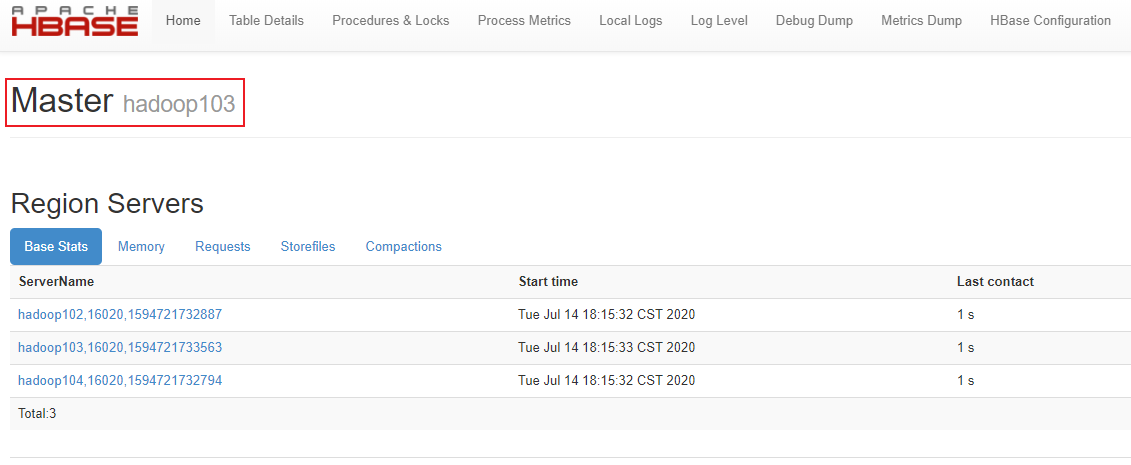
kill掉hadoop102的hmaster
[hadoop@hadoop102 module]$ jps
3364 NameNode
3497 DataNode
3117 QuorumPeerMain
23678 HRegionServer
23487 HMaster
24239 Jps
[hadoop@hadoop102 module]$ kill -9 23487
观察hadoop103
Hbase(一)【入门安装及高可用】的更多相关文章
- 【工具-Nginx】从入门安装到高可用集群搭建
文章已收录至https://lichong.work,转载请注明原文链接. ps:欢迎关注公众号"Fun肆编程"或添加我的私人微信交流经验 一.Nginx安装配置及常用命令 1.环 ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- 安装ORACLE高可用RAC集群11g执行root脚本的输出信息
安装ORACLE高可用RAC集群11g执行root脚本的输出信息 作者:Eric 微信:loveoracle11g [root@node1 ~]# /u01/app/oraInventory/orai ...
- 安装ORACLE高可用RAC集群11g校验集群安装的可行性输出信息
安装ORACLE高可用RAC集群11g校验集群安装的可行性输出信息 作者:Eric 微信:loveoracle11g [grid@node1 grid]$ ./runcluvfy.sh stage - ...
- 使用kubeadm安装kubernetes高可用集群
kubeadm安装kubernetes高可用集群搭建 第一步:首先搭建etcd集群 yum install -y etcd 配置文件 /etc/etcd/etcd.confETCD_NAME=inf ...
- 阿里云HBase推出普惠性高可用服务,独家支持用户的自建、混合云环境集群
HBase可以支持百TB数据规模.数百万QPS压力下的毫秒响应,适用于大数据背景下的风控和推荐等在线场景.阿里云HBase服务了多家金融.广告.媒体类业务中的风控和推荐,持续的在高可用.低延迟.低成本 ...
- springcloud 入门 10 (eureka高可用)
eureka高可用: 说白了,就是加一个实例作为原实例的备份,然后一起对外提供服务.这样可以保证在一台机器宕机的时候,整个系统不会死掉.保证其继续对外服务. eureka的集群化: 服务注册中心Eur ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- 大数据高可用集群环境安装与配置(06)——安装Hadoop高可用集群
下载Hadoop安装包 登录 https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/ 镜像站,找到我们要安装的版本,点击进去复制下载链接 ...
随机推荐
- STM32程序异常——中断处理要谨慎
问题背景 最近有一个新项目(车载项目),板子上除了原来的ARM + STM32F030K6Tx又多了一个8bit的mcu的单片机,这可真是嵌入式全家福了. 系统的主要核心工作是由arm来完成,但是在开 ...
- 顺时针打印矩阵 牛客网 剑指Offer
顺时针打印矩阵 牛客网 剑指Offer 题目描述 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 ...
- Mybatis实现简单的CRUD(增删改查)原理及实例分析
Mybatis实现简单的CRUD(增删改查) 用到的数据库: CREATE DATABASE `mybatis`; USE `mybatis`; DROP TABLE IF EXISTS `user` ...
- Mac 搭建后端PHP+Go环境
准备工作 1. 安装brew命令 #很慢很慢.. ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/insta ...
- 【Java】String、StringBuffer、StringBuilder
java.lang.String类 概述 String:代表字符串.Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现 String声明为final,不可被 ...
- vue监听器watch & 计算属性computed
侦听器watch vue中watch是用来监听vue实例中的数据变化 watch监听时有几个属性: handle:其值是一个回调函数,就是监听对象对话的时候需要执行的函数 deep:其值true 或者 ...
- D3.js V5 教程
D3.js V5 教程 1.在项目中使用D3.js 2. 选择元素和设置(获取)属性 3. 绑定数据 4. 理解Update.Enter.Exit 与 添加.删除元素 未完待续..........
- Swift学习笔记(一)
1.Constants and Variables(常量和变量) let定义常量,var定义变量. [Note] If a stored value in your code won't change ...
- 『学了就忘』Linux软件包管理 — 44、在RPM包中提取文件
目录 1.RPM包中文件的提取 2.在RPM包中提取文件的操作 (1)cpio命令介绍 (2)提取RPM包中文件 1.RPM包中文件的提取 为什么要做这个事呢? 在操作Linux系统的时候误删除一个文 ...
- dart系列之:创建Library package
目录 简介 Library package的结构 导入library 条件导入和导出library 添加其他有效的文件 library的文档 发布到pub.dev 总结 简介 在dart系统中,有pu ...