大数据学习day36-----flume02--------1.avro source和kafka source 2. 拦截器(Interceptor) 3. channel详解 4 sink 5 slector(选择器)6 sink processor
1.avro source和kafka source
1.1 avro source
avro source是通过监听一个网络端口来收数据,而且接受的数据必须是使用avro序列化框架序列化后的数据。avro是一种序列化框架,并且是跨语言的。
扩展:什么是序列化,什么是序列化框架?
序列化:是将一个有复杂结构的数据块(对象)编程扁平(线性的)二进制序列
序列化框架:一套现成的软件,可以按照既定策略,将对象转成二进制序列
比如:jdk有ObjectOutputStream,hadoop有Writable,跨平台的序列化框架有avro
1.1.1 工作机制
启动一个服务,监听一个端口,收集端口上收到的avro序列化数据流。该source中拥有avro的反序列化器,能够将收到的二进制流进行正确反序列化,并装入一个event写入channel。其带有一个client,可以发送数据。这正是其可以用以agent间级连的原因。
1.1.2 配置文件


a1.sources=r1
a1.channels=c1
a1.sinks=k1 #source配置
a1.sources.r1.type=avro
a1.sources.r1.channels=c1
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=7788 # channel配置
a1.channels.c1.type = memory # sink的配置
a1.sinks.k1.type = logger
a1.sinks.k1.channel=c1
1.1.3 启动测试
[root@feng05 myconf]# /usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf \
> -f myconf/avro-logger.conf \
> -Dflume.root.logger=INFO,console
1.1.4 用一个avro客户端去给启动好的source发送avro序列化数据:
bin/flume-ng avro-client --feng05 --port 7788
最终发现avro客户端发送的数据被avro source接收到

1.1.5 avro source 的使用场景
(1)假设A公司需要从B公司采集数据,但是B公司为了安全,不想A公司在他们机器上装flume,并且A,B公司使用的语言不同,这时B公司就可以在自己机器上安装一个flume,并使用avro(跨语言)客户端将数据发送给A公司。
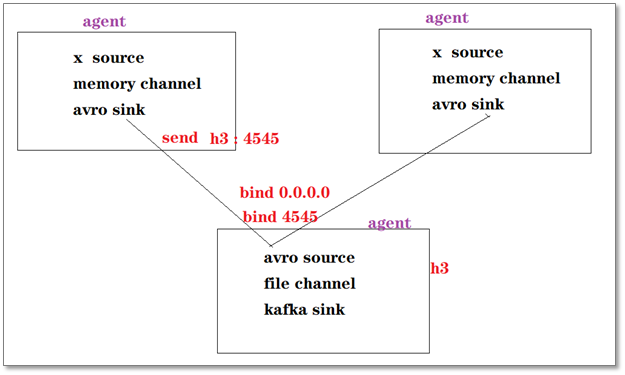
(2)Agent之间的级联
上游agent使用avro sink作为下沉组件,可以将数据从一个节点发到另一个节点,而下游的agent则使用avro source作为源组件,可以从别的节点接收数据
1.2 kafka source
1.2.1 工作机制
Kafka source(内部相当于kafka consumer)的工作机制:就是用kafka consumer连接kafka,读取数据,然后转换成event,写入channel
1.2.2 配置文件
# agent中各组件的名字
a1.sources=r1
a1.channels=c1
a1.sinks=k1 # source配置
a1.sources.r1.type=org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.channels=c1
a1.sources.r1.kafka.bootstrap.servers=feng05:9092,feng06:9092,feng07:9092
a1.sources.r1.kafka.topics=kafka_source # channel配置
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=1000 # sink配置
a1.sinks.k1.type=logger
a1.sinks.k1.channel=c1
注意:source往channel中写入数据批次的大小 <= channel的事务控制容量的大小
1.2.3 启动测试
准备工作:创建好相应的topic,并往这个topic中写入数据,然后启动flume
/usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf/ -f ./kafka-logger.conf -Dflume.root.logger=INFO,console
结果

2. 拦截器(Interceptor)
2.1 拦截器简介
拦截器在source取到数据后,可以对source所产生的Event做进一步的逻辑处理,然后再返回处理之后的event。这样一来,就可以让用户不需要改动source代码的情况下,就可以插入一些数据处理逻辑;Flume软件包中,内置了若干种拦截器,这些拦截器的功能基本上都是向Event的header中插入一些kv标记;不对event的body数据做处理!

2.2 内置拦截器的种类(具体见文档)
- timestamp 插入 时间戳header
- static 插入配死的header
- uuid 插入一个uuid
- host 插入主机名(IP)
3 channel详解
3.1 memory channel
3.1.1 特性
事件被存储在实现配置好容量的内存(队列)中。速度快,但可靠性较低,有可能会丢失数据(当source与channel间的事务commit后,数据放到了channel中并且sink还没来得及从里面获取完这批数据,但此时agent崩了,这样的话就会在成数据丢失(内存不能永久保存数据))
3.1.2 参数
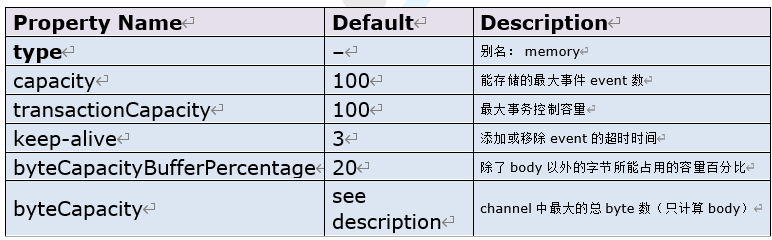
3.1.3 配置示例
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
3.1.4 memory channel源码阅读(见文档)
3.2 file channel
3.2.1 特性
event被缓存在agent所在机器的本地磁盘文件中,可靠性很高,不会丢失数据。但在极端情况下可能会产生数据重复
3.2.2 参数
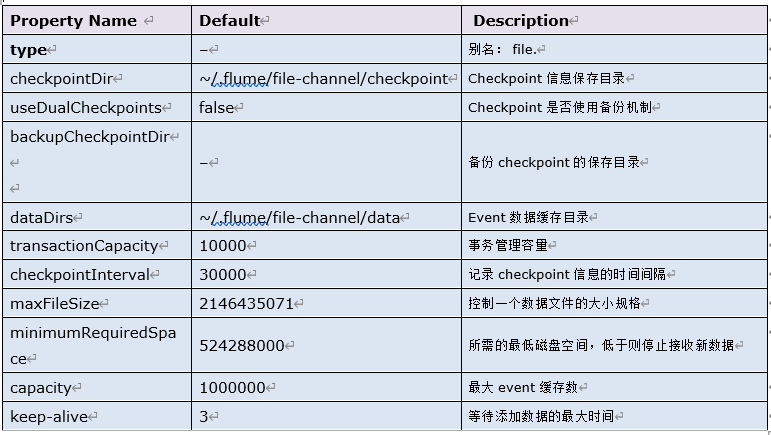
3.2.3 配置示例
a1.sources = r1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /root/taildir_chkp/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /root/weblog/access.log
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000 a1.channels = c1
a1.channels.c1.type = file
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 100
a1.channels.c1.checkpointDir = /root/flume_chkp
a1.channels.c1.dataDirs = /root/flume_data a1.sinks = k1
a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
3.2.4 测试
在使用taildir source和file channel的情况下,经过反复各种人为破坏,发现,没有数据丢失的现象发生。但是,如果时间点掐的比较好(sink取了一批数据写出,但还没来得及向channel提交事务),会产生数据重复的现象。
3.3 kafka channel
3.3.1 特性
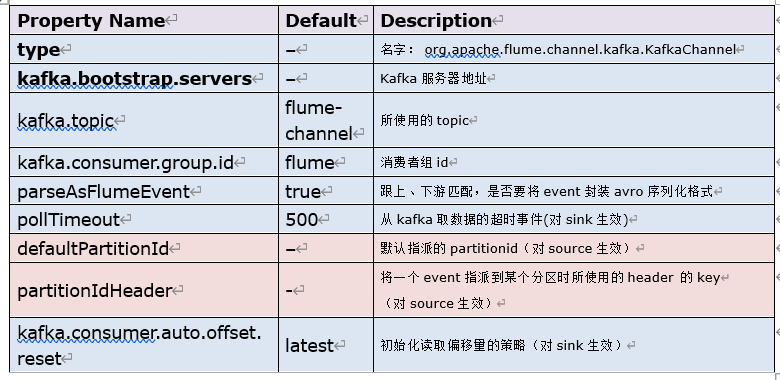
agent利用kafka作为channel数据缓存,kafka channel要跟kafka source、kafka sink区别开来。kafka channel在应用时,可以没有source或者可以没有sink。如果是需要把kafka作为最终采集存储,那么就只要source+kafka channel;如果是把kafka作为数据源,要将kafka中的的数据写往hdfs,那么只需要kafka channel+hdfs sink
3.3.2 参数
4 sink(具体见文档)
sink是从channel中获取、移除数据,并输出到下游(可能是下一级agent,也可能是最终目标存储系统)
- avro sink
avro是将数据通过网络发送出去,通常用于向avro source发送avro序列化数据,这样就可以实现agent自检的级联
- hdfs sink(最常用)
数据被最终发往hdfs,可以生成text文件或sequence文件,而且支持压缩(若需要压缩的话,文件后缀名一定要指定相应压缩名)。支持生成文件的周期性roll file机制:基于文件size,时间间隔或者是event数量(达到这些设置值时,就会重新创建一个文件来存储)。
目标路径,可以使用动态通配符替换,比如用%D代表当前日期;当然,它也能从event的header中,取到一些标记来作为通配符替换;如:
header:{type=abc}
/weblog/%{type}/%D/ 就会被替换成: /weblog/abc/19-06-09/
测试:
(1)配置文件:
a1.sources = s1
a1.channels = c1
a1.sinks = k1 a1.sources.s1.channels = c1
a1.sources.s1.type = exec
a1.sources.s1.command = tail -F /root/logs/a.log
a1.sources.s1.batchSize = 100
a1.sources.s1.interceptors = i1
a1.sources.s1.interceptors.i1.type = timestamp a1.channels.c1.type = memory a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path =hdfs://feng05:9000/hdfs-sink/%Y-%m-%d/%H-%M/
a1.sinks.k1.hdfs.filePrefix = feng-
a1.sinks.k1.hdfs.fileSuffix = .log.gzip
a1.sinks.k1.hdfs.inUseSuffix = .tmp
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.codeC = gzip
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.channel = c1
注意:由于hdfs sink默认是所用的时间不从agent sink本地获取,所以需要配置一个timestamp拦截器,这样后面关于sink配置的时间路径才能取到相应的时间。此处是以minute为单位回滚文件夹的,但若要换成10分钟回滚一次,则可以使用hdfs.roundValue参数,令其等于10即可
(2)启动hdfs
(3)启动agent
/usr/apps/apache-flume-1.9.0-bin/bin/flume-ng agent -n a1 -c conf -f myconf/hdfs-sink.conf -Dflume.root.logger=INFO,console
(4)用for循环脚本往日志文件中不断写入新的数据
i=1
while true
do
echo "$((i++)) $RANDOM --.........ABC......" >>a.log
sleep 0.1
done
这样采集到的数据就会被写入hdfs,由于配置中规定了文件写到多大后才会重新生成另外一个文件写入数据,在数据正在写时,文件夹会有后缀(默认tmp)和前缀,写完后即消失。
注意 由于source往channel写数据很快,但是往hdfs sink从channel取数据却很慢,这样channel很容易溢出,解决办法如下:

- kafka sink
有了kafka channel后,kafka sink的必要性就降低了,因为我们可以用kafka作为channel来接收source产生的数据
5 slector(选择器,具体见文档)
一个source可以对接多个channel,那么,source的数据如何在多个channel之间提交,就由selector来控制。其配置挂载到source组件上。
- 复制选择器(replicating selector)
replicating selector是默认的选择器,它会将source所采集到的event,复制发送到所指定的多个channel中
- 多路复用选择器(multiplexing selector)
根据event header中指定key的不同值,来将event发往事先映射好的不同channel
6 sink processor
6.1 简介
sink processor是sink组处理器;一个agent中,多个sink可以被组装到一个sink组,而数据在组内多个sink之间发送,有两种策略:FailOver:失败切换(通常用于事先HA);LoadBalancing:负载均衡(通常用于分流、均衡负载)
6.2 FailOver组处理器
一组中只有优先级高的那个sink在工作,另一个是等待中。如果高优先级的sink发送数据失败,则转用低优先级的sink去工作,在配置时间penalty之后,还会尝试用高优先级的去发送数据
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
## 对两个sink分配不同的优先级
a1.sinkgroups.g1.processor.priority.k1 = 200
a1.sinkgroups.g1.processor.priority.k2 = 100
## 主sink失败后,停用惩罚时间
a1.sinkgroups.g1.processor.maxpenalty = 5000
可以用来实现两级agent架构中的,下游agent的高可用

过程:source读取到数据并将之放入channel,通过sink的处理器知晓了用哪个sink,当下游的agent1单点故障时,上游组件发现数据发送不过去(数据发送失败,连接断开),其就会启用另外一个sink,并在原先的偏移量上读取数据,然后通过agent2将数据写入hdfs中(跟agent1写入的文件一致)
6.3 LoadBalancing组处理器
允许channel中的数据在一组sink中的多个sink之间进行轮转,策略有:round-robin(轮着发),random(随机挑)
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random
7. 如何既实现高可用,又实现负载均衡,以下是自己的想法(未证实)
想法一:
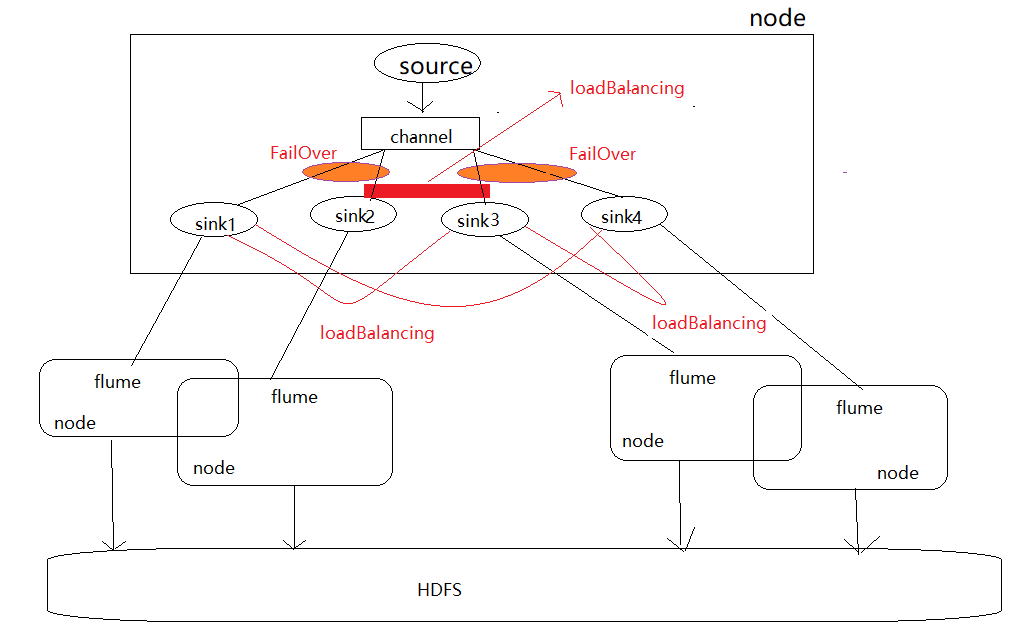
想法二:

大数据学习day36-----flume02--------1.avro source和kafka source 2. 拦截器(Interceptor) 3. channel详解 4 sink 5 slector(选择器)6 sink processor的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记——Linux完整部署篇(实操部分)
Linux环境搭建完整操作流程(包含mysql的安装步骤) 从现在开始,就正式进入到大数据学习的前置工作了,即Linux的学习以及安装,作为运行大数据框架的基础环境,Linux操作系统的重要性自然不言 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习之Linux进阶02
大数据学习之Linux进阶 1-> 配置IP 1)修改配置文件 vi /sysconfig/network-scripts/ifcfg-eno16777736 2)注释掉dhcp #BOOTPR ...
随机推荐
- path-sum-ii leetcode C++
Given a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given su ...
- Qt5 项目程序打包发布 详细教程
概述 当我们用QT写好了一个软件,要把你的程序分享出去的时候,不可能把编译的目录拷贝给别人去运行.编译好的程序应该是一个主程序,加一些资源文件,再加一些动态链接库,高大上一些的还可以做一个安装文件. ...
- 设计模式二--模板方法Template method
模式分类: 书籍推荐:重构-改善既有代码的设计 重构获得模式 设计模式:现代软件设计的特征是"需求的频繁变化".设计模式的要点是 "寻找变化点,然后在变化点处应用设计模式 ...
- .NET Core资料精选:架构篇
.NET 6.0 马上就要发布,高性能云原生开发框架.希望有更多的小伙伴加入大.NET阵营.这是本系列的第三篇文章:架构篇,喜欢的园友速度学起来啊. 本系列文章,主要分享一些.NET Core比较优秀 ...
- MongoDB与MySQL效率对比
本文主要通过批量与非批量对比操作的方式介绍MongoDB的bulkWrite()方法的使用.顺带与关系型数据库MySQL进行对比,比较这两种不同类型数据库的效率.如果只是想学习bulkWrite()的 ...
- IDEA中三种注释方式的快捷键
三种注释方式 行注释.块注释.方法或类说明注释. 一.快捷键:Ctrl + / 使用Ctrl+ /, 添加行注释,再次使用,去掉行注释 二.演示代码 if (hallSites != null ...
- Python基础(返回函数)
#我们在函数lazy_sum中又定义了函数f1,并且,内部函数f1可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数f1时,相关参数和变量都保存在返回的函数中,这种称为&qu ...
- ES6基础知识(async 函数)
1.async 函数是什么?一句话,它就是 Generator 函数的语法糖. const fs = require('fs'); const readFile = function (fileNam ...
- ES6—数值(Number,Math对象)(复习+学习)
ES6-数值(Number,Math对象)(复习+学习) 每天一学,今天要学习ES6的关于数的扩展以及复习,然后通过看书,查阅资料,以及webAPI来搞清楚遇到的,没见过的对象方法等等,下面为本次学习 ...
- C++getline()
#include <iostream>#include <cstring>#include <string>using namespace std;int main ...