SQL 居然还能在 Apache ShardingSphere 上实现这些功能?
在去年 10 月 5.0.0-alpha 版本发布之后,Apache ShardingSphere 经历了长达 8 个多月的持续开发与优化,终于在 6 月 25 日正式迎来了 5.0.0-beta 版本的发布。
本次 5.0.0-beta 版除了提供 DistSQL 这样的新特性外,对 ShardingSphere 内核也进行了增强,主要体现在 SQL 基础解析能力增强、SQL 标准路由能力提升和 SQL 分布式查询能力增强这三方面。通过这三方面优化,不仅进一步提高了对 MySQL,PostgreSQL,SQLServer 和 Oracle 数据库的基础 SQL 解析能力,而且大幅度提高了对用户 SQL 的支持度,特别针对跨数据库实例的关联 SQL 进行了更有针对性的优化。本文将带领大家一起,探秘 5.0.0-beta 版内核增强特性。
作者:端正强
Apache ShardingSphere Committer,SphereEx Java 高级工程师。热爱开源,乐于分享,目前专注于 Apache ShardingSphere 数据库中间件开发。
内核原理
在探秘 5.0.0-beta 版内核增强之前,让我们先来回顾下 ShardingSphere 的内核原理。如下图所示,ShardingSphere 内核主要由解析引擎、路由引擎、改写引擎、Standard 执行引擎、Federate 执行引擎、归并引擎等组成。Federate 执行引擎是本次 5.0.0-beta 版本引入的新功能,用于增强分布式查询能力。
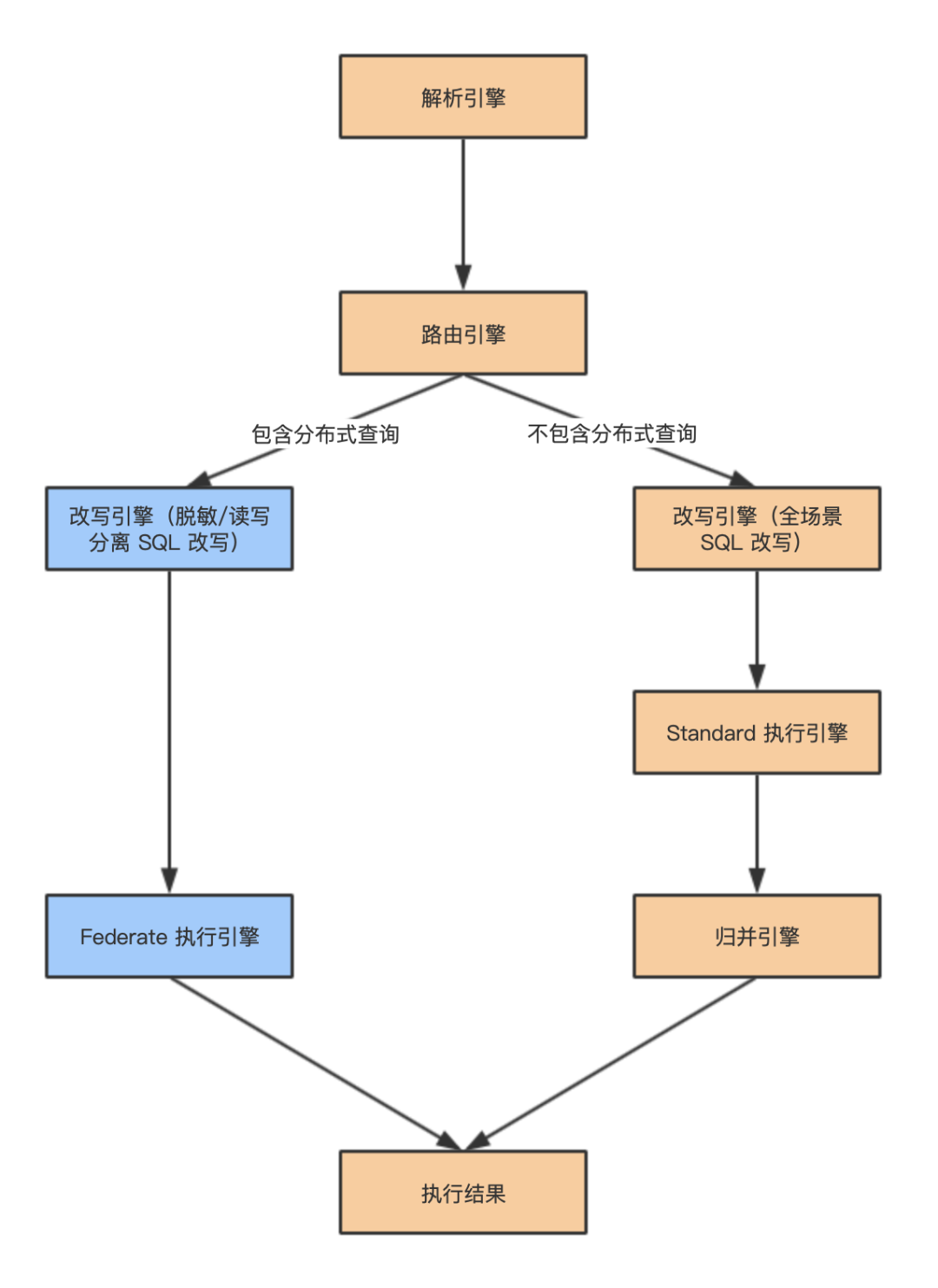
解析引擎:解析引擎负责进行 SQL 解析,具体可以分为词法分析和语法分析。词法分析负责将 SQL 语句拆分为一个个不可再分的单词,然后语法分析器对 SQL 进行理解,并最终得到解析上下文。解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符标记;
路由引擎:路由引擎根据解析上下文,匹配用户配置的分片策略,并生成路由结果,目前支持分片路由和广播路由;
改写引擎:改写引擎负责将 SQL 改写为在真实数据库中可以正确执行的语句,SQL 改写可以分为正确性改写和优化改写;
Standard 执行引擎:Standard 执行引擎负责将路由和改写完成之后的真实 SQL 安全且高效地发送到底层数据源执行;
Federate 执行引擎:Federate 执行引擎负责处理跨多个数据库实例的分布式查询,底层使用的 Calcite 基于关系代数和 CBO 优化,通过最优执行计划查询出结果;
归并引擎:归并引擎负责将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端。
在回顾了 ShardingSphere 内核原理后,下面让我们来具体看看 5.0.0-beta 版内核增强。
SQL 基础解析能力增强
SQL 解析引擎是 ShardingSphere 项目的基石,也是项目中最稳定的基础设施。在 5.0.0-alpha 版中,我们将 SQL 解析引擎与主项目完全剥离,为开发者提供了一套独立的 SQL 解析引擎组件,相比其他老牌 SQL 解析引擎,ShardingSphere SQL 解析引擎具有易于扩展和更完善的 SQL 方言支持等特性。目前,用户可将 ShardingSphere SQL 解析引擎作为独立解析器,进行 SQL 解析,详见官网链接(https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/parse/)。
在本次发布的 5.0.0-beta 中,我们更加关注 SQL 解析引擎最重要的两个衡量指标——性能和 SQL 支持度。对于性能问题,ShardingSphere 已通过缓存将 SQL 解析的性能损耗降至最低。对于社区一直关注的 SQL 支持度问题,ShardingSphere 结合多个不同反馈渠道,在本次发布的 5.0.0-beta 版中进行了大量的 SQL 解析优化和支持度提升。
首先是 ShardingSphere 社区通过协议层反推过来的 SQL 优化,在 SQL 支持度提升的同时,Proxy 接入端也越来越稳定,特别是 ShardingSphere-Proxy PostgreSQL 5.0.0-beta 版,在各个方面都有较大提升,欢迎大家下载使用。此外,针对 MySQL,PostgreSQL,openGauss 数据库的 Proxy 接入端介绍,也会在后续为大家带来技术分享。
其次是 SphereEx 性能测试团队,在使用 sysbench 和 tpcc 进行压测过程中,反馈了很多测试用例中不支持的 SQL。针对 SphereEx 性能测试团队反馈的 SQL 不支持项,我们在 5.0.0-beta 版进行了针对性优化,目前已经全部支持。
针对社区反馈问题较多的 PostgreSQL,SQLServer 和 Oracle 等数据库中的 SQL 支持度问题,ShardingSphere 社区通过核心团队成员领导支持、社区同学大规模参与的方式进行提升。特别是在本次作为 Apache 优秀社区参加的 Google Summer Code 中,海外同学做出了较大贡献。


在众多社区贡献者的努力之下,ShardingSphere 5.0.0-beta 版的 SQL 支持度取得了大幅度提升。为了打造更好的项目基石,我们会持续提升优化 SQL 支持度,期待有更多的贡献者可以参与到这项工作中来,一起提升 SQL 支持度。
SQL 标准路由能力提升
在 SQL 支持度提升的基础上,ShardingSphere 5.0.0-beta 版也对 SQL 路由逻辑进行了增强,重点优化了 DDL 语句 和 DQL 语句的路由逻辑。在 5.0.0-beta 版优化 DDL 语句路由逻辑前,路由引擎只能处理 DDL 语句中单表的路由,对于包含多表的场景,路由处理并不是很完善。
以 ALTER TABLE 语句为例,假设 t_order 和 t_order_item 为分片表,并且未设置为绑定表关系。在优化前执行如下 SQL 会抛出 Table t_order_item does not exist. 异常,路由逻辑只会针对 t_order 表进行路由,忽视了 t_order_item 表的数据分布情况。
ALTER TABLE t_order ADD CONSTRAINT t_order_fk FOREIGN KEY (order_id) REFERENCES t_order_item (order_id);
想要支持 DDL 语句多表组合路由,需要考虑许多复杂的组合场景。按照 ShardingSphere 中对于表的分类,我们可以将表划分为分片表(sharding table)、广播表(broadcast table)和单表(single table),分片表又可以组成绑定表(binding table)。关于表的详细概念可以参考下面的说明。
分片表(sharding table):又叫逻辑表,水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为 10 张表,分别是 t_order_0 到 t_order_9,他们的逻辑表名为 t_order;
绑定表(binding table):指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系;
广播表(broadcast table):指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表;
单表(single table):指所有的分片数据源中只存在唯一一张的表。适用于数据量不大且不需要做任何分片操作的场景。
对于以上三种主要类型的表进行排列组合,可以得到如下 9 种组合场景:
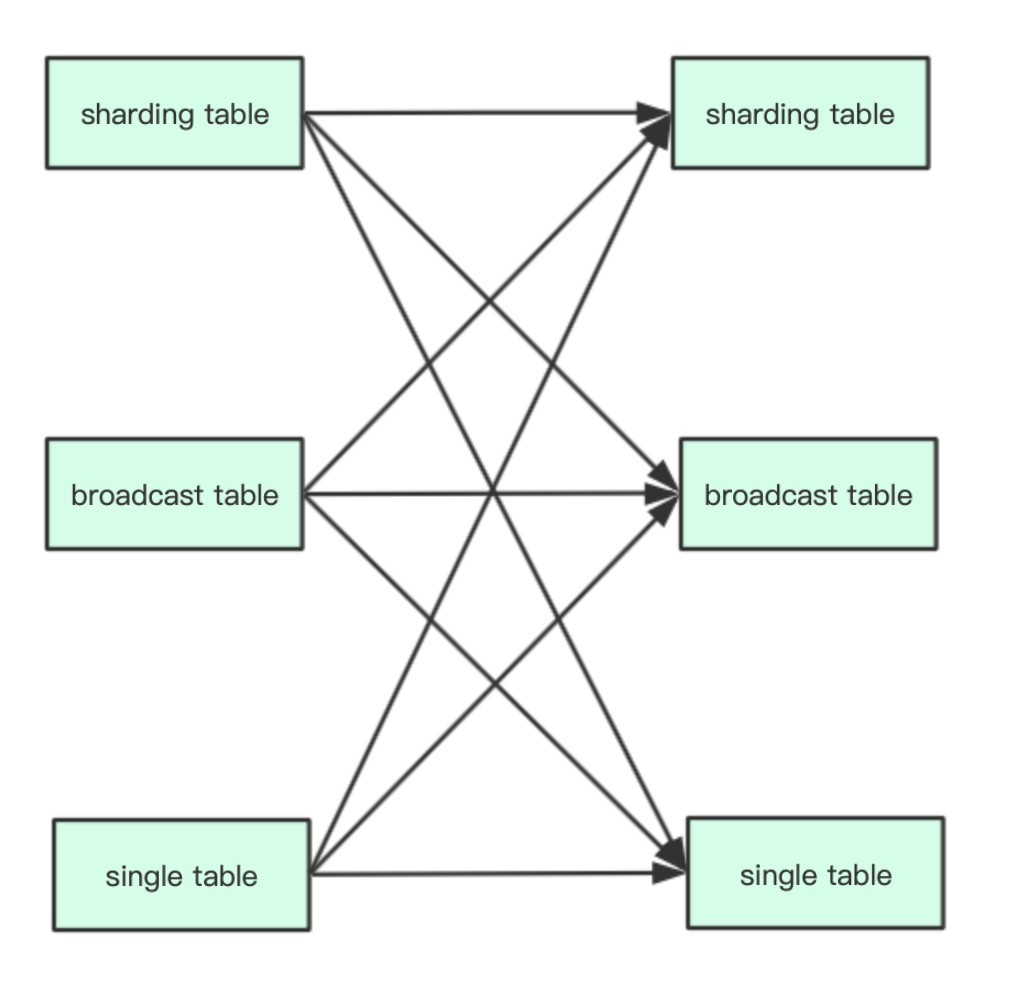
针对这 9 种表的组合场景,ShardingSphere 5.0.0-beta 版对 ShardingTableBroadcastRoutingEngine 路由引擎进行了增强,完全支持分片表/广播表和其他类型表的组合路由。当 SQL 语句中包含的表都为分片表,并且都是绑定表关系时,会按照原有主表驱动路由的方式进行处理。当 SQL 语句中包含的表都为分片表,但不是绑定表关系时,或者 SQL 语句中的部分表为分片表时,路由引擎会按照表所属的数据源先取交集,然后再对同数据源的物理表计算笛卡尔积,得到最终的路由结果。
由于表的组合关系复杂,路由结果也存在多种情况。当分片表只配置了单个数据节点,并且分布在同一数据源时,DDL 语句多表组合的笛卡尔积路由结果是合法的,而当分片表配置了多个数据节点时,笛卡尔积路由结果往往是非法的。路由引擎需要能够判断出合法路由结果和非法路由结果,对于非法的路由结果,路由引擎需要抛出合适的异常信息。

为了保证用户使用 ShardingSphere 的安全性,针对不支持的 SQL 或非法 SQL,ShardingSphere 引入了前置校验(pre validate)和后置校验(post validate)。前置校验主要用于校验 SQL 语句的基本信息是否合法,如:表是否存在、索引是否存在、多个单表是否存在于同一个数据源中。后置校验主要用于校验路由的结果是否合法,如:在 ALTER TABLE 语句中添加外键约束时,我们认为所有的主表(primary table)都成功添加外键约束为合法路由结果,否则将抛出异常信息。
对于 DQL 语句路由逻辑的优化,主要是针对跨数据库实例 JOIN 及子查询进行的。路由引擎在处理 DQL 语句时,如果当前语句中的表跨多个数据库实例,则会使用 ShardingTableBroadcastRoutingEngine 路由引擎来处理。在下面一个部分,将会对 SQL 分布式查询能力增强进行介绍。
SQL 分布式查询能力增强
在 ShardingSphere 5.0.0-beta 版前,跨数据库实例进行 JOIN 及子查询一直是令用户头疼的问题。在同时使用多个数据库实例时,业务研发人员需要时刻注意查询 SQL 的使用范畴,尽量避免跨数据库实例进行 JOIN 及子查询,这使得业务层面的功能受到了数据库限制。
在 ShardingSphere 5.0.0-beta 版中,借助于 Apache Calcite 和 ShardingSphere 自身的解析、路由和执行能力,通过路由引擎进行判断,将跨数据实例的分布式查询 SQL,交由 Federate 执行引擎处理,完美支持了跨数据库实例的 JOIN 及子查询。
同时,针对 ShardingSphere 尚不支持的一些复杂查询语句,我们也在最新的 master 分支进行了尝试,使用 Federate 执行引擎进行处理,目前已经取得了良好的效果。例如:查询语句使用 Having 过滤,子查询使用聚合函数,多聚合函数组合查询等语句,已经得到了支持,支持的 SQL 样例如下。
SELECT user_id, SUM(order_id) FROM t_order GROUP BY user_id HAVING SUM(order_id) > 10;
SELECT (SELECT MAX(user_id) FROM t_order) a, order_id FROM t_order;
SELECT COUNT(DISTINCT user_id), SUM(order_id) FROM t_order;
ShardingSphere 最新 SQL 语句支持情况可以参考官方文档(https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/)。5.0.0-beta 版对于分布式查询能力的增强是一个良好的开端,未来 ShardingSphere 将持续优化,不断增强分布式查询能力。
结语
Apache ShardingSphere 项目仍然在快速发展中,在后续的版本中,我们将持续提升各种数据库的 SQL 支持度,不断完善内核功能,努力为社区提供更多强大的功能,欢迎持续关注并积极参与社区任务,也欢迎点击“链接”下载使用。

欢迎关注我们
SQL 居然还能在 Apache ShardingSphere 上实现这些功能?的更多相关文章
- Apache ShardingSphere 5.0.0 内核优化及升级指南
经过近两年时间的优化和打磨,Apache ShardingSphere 5.0.0 GA 版终于在本月正式发布,相比于 4.1.1 GA 版,5.0.0 GA 版在内核层面进行了大量的优化.首先,基于 ...
- DistSQL:像数据库一样使用 Apache ShardingSphere
Apache ShardingSphere 5.0.0-beta 深度解析的第一篇文章和大家一起重温了 ShardingSphere 的内核原理,并详细阐述了此版本在内核层面,特别是 SQL 能力方面 ...
- Apache ShardingSphere 5.1.2 发布|全新驱动 API + 云原生部署,打造高性能数据网关
在 Apache ShardingSphere 5.1.1 发布后,ShardingSphere 合并了来自全球的团队或个人的累计 1028 个 PR,为大家带来 5.1.2 新版本.该版本在功能.性 ...
- SQL Server在本地计算机上用SSMS(SQL Server Management Studio)登录不上,错误消息:(Microsoft SQL Server, Error: 18456)
今天遇到了一个奇怪的问题,公司目前在SQL Server上都采用AD域账号登录,由于账号人数众多,所以我们建立了一个AD Group(域组),将大家的AD账号加入了这个AD Group,然后我们将这个 ...
- ### Error building SqlSession. ### The error may exist in SQL Mapper Configuration ### Cause: org.apache.ibatis.builder.BuilderException: Error parsing SQL Mapper Configuration. Cause: org.apache.ibat
这是一个由粗心导致的错误,具体报错如下: org.apache.ibatis.exceptions.PersistenceException: ### Error building SqlSessio ...
- Apache ShardingSphere 在京东白条场景的落地之旅
京东白条使用 Apache ShardingSphere 解决了千亿数据存储和扩容的问题,为大促活动奠定了基础. 2014 年初,"京东白条"作为业内互联网信用支付产品,数据量爆发 ...
- Apache ShardingSphere:由开源驱动的分布式数据库中间件生态
2021 年 7 月 21 日 2021 亚马逊云科技中国峰会现场,SphereEx 联合创始人.Apache ShardingSphere PMC 潘娟受邀参与此次峰会,以<Apache Sh ...
- Apache ShardingSphere 元数据加载剖析
唐国城 小米软件工程师,主要负责 MIUI 浏览器服务端研发工作.热爱开源,热爱技术,喜欢探索,热衷于研究学习各种开源中间件,很高兴能参与到 ShardingSphere 社区建设中,希望在社区中努力 ...
- 重磅|Apache ShardingSphere 5.0.0 即将正式发布
Apache ShardingSphere 5.0.0 GA 版在经历 5.0.0-alpha 及 5.0.0-beta 接近两年时间的研发和打磨,终于将在 11 月份与大家正式见面! 11 月 10 ...
随机推荐
- java8时间类API安全问题(赠送新的时间工具类哟)
LocalDateTime等新出的日期类全是final修饰的类,不能被继承,且对应的日期变量都是final修饰的,也就是不可变类.赋值一次后就不可变,不存在多线程数据问题. simpleDateFor ...
- PENETRATION第一步
PENETRATION第一步 第一次去打靶机,本来都快成功了,电脑蓝屏警告了...(=_=) 靶机下载连接 (https://download.vulnhub.com/admx/AdmX_new.7z ...
- vue 嵌入倒计时组件( 亲测可用 )
由于花费了我不少时间才找到的组件,所以记录一下,后面方便自己好找一些,也算是分享出来给各位前端一起用. npm 下载npm install vue2-flip-countdown --save tem ...
- 一、Rabbitmq的简单介绍
以下只是本人从零学习过程的整理 部分内容参考地址:https://www.cnblogs.com/ysocean/p/9240877.html 1.RabbitMQ的概念 RabbitMQ是实现了高级 ...
- APT组织跟踪与溯源
前言 在攻防演练中,高质量的蓝队报告往往需要溯源到攻击团队.国内黑产犯罪团伙.国外APT攻击. 红队现阶段对自己的信息保护的往往较好,根据以往溯源成功案例来看还是通过前端js获取用户ID信息.mysq ...
- [考试总结]noip模拟43
这个题目出的还是很偷懒.... 第一题...第二题...第三题...四.... 好吧... 这几次考得都有些问题,似乎可能是有些疲惫,脑袋也是转不太动,考完总觉得自己是能力的问题,但是改一分钟之后会发 ...
- Selenium系列(十七) - Web UI 自动化基础实战(4)
如果你还想从头学起Selenium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1680176.html 其次,如果你不懂前端基础知识, ...
- Linux - yum 安装软件时被 PackageKit 锁定
问题描述 yum 安装软件的时候报错 sudo yum install netease-cloud-music 已加载插件:fastestmirror, langpacks /var/run/yum. ...
- VSCode一些设置
//每次保存后自动格式化 "editor.formatOnSave": true, // #每次保存的时候将代码按eslint格式进行修复 "editor.codeAct ...
- 第23篇-虚拟机对象操作指令之getstatic
Java虚拟机规范中定义的对象操作相关的字节码指令如下表所示. 0xb2 getstatic 获取指定类的静态域,并将其值压入栈顶 0xb3 putstatic 为指定的类的静态域赋值 0xb4 ge ...