再谈多线程模型之生产者消费者(多生产者和单一消费者 )(c++11实现)
0.关于
为缩短篇幅,本系列记录如下:
再谈多线程模型之生产者消费者(基础概念)(c++11实现)
再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现)
再谈多线程模型之生产者消费者(单一生产者和多消费者)(c++11实现)
再谈多线程模型之生产者消费者(多生产者和单一消费者 )(c++11实现)【本文】
再谈多线程模型之生产者消费者(多生产者和多消费者 )(c++11实现)
再谈多线程模型之生产者消费者(总结)(c++11实现)
本文涉及到的代码演示环境: VS2017
欢迎留言指正
1.多生产者&单一消费者
1.1 与 单一生产者和多消费者模型类似, 因为存在多个生产者,需要考虑生产者之间的互斥访问; 消费者只有一个,因此不存在消费者之间的互斥与竞争。
1.2 多个生产者, 可能同时放入商品,类比吃水果,父母同时向果盘放入水果,只有子女中的一个吃水果的情况。
1.3 具体点
情况 处理 生产者速率 > 消费者速率 消费者只有一个,因此,不存在消费者之间的竞争。生产者存在多个,多个生产者之间生产好数据就需要按照竞争将数据放入缓冲区,谁先拿到锁,谁就先放入。最开始,生产者有多个,只能通过竞争生产。但是由于生产效率大于消费速率, 所以定然会出现商品数量 > 消费者数量。当商品总量达到总数,则需要暂停生产,等待消费者消费 生产者速率 < 消费者速率 最开始,剩余放入总数 > 生产者总数,可以同时放入,随着时间的推移,可能会出现: 剩余放入空间 > 生产者总数 和 剩余放入空间 < 生产者总数。 当出现 剩余空间 < 生产者总数 时,已经不满足同时放入,此时就需要锁。来保证 1.4 结构体模型
template<typename T>
struct repo_
{
// 用作互斥访问缓冲区
std::mutex _mtx_queue;
// 缓冲区最大size
unsigned int _count_max_queue_10 = 10;
// 缓冲区
std::queue<T> _queue;
// 缓冲区没有满,通知生产者继续生产
std::condition_variable _cv_queue_not_full;
// 缓冲区不为空,通知消费者继续消费
std::condition_variable _cv_queue_not_empty;
// 用于生产者之间的竞争
std::mutex _mtx_pro;
// 计算当前已经生产了多少数据了
unsigned int _cnt_cur_pro = 0;
repo_(const unsigned int count_max_queue = 10) :_count_max_queue_10(count_max_queue)
, _cnt_cur_con(0)
{
;
}
repo_(const repo_&instance) = delete;
repo_& operator = (const repo_& instance) = delete;
repo_(const repo_&&instance) = delete;
repo_& operator = (const repo_&& instance) = delete;
};
对比单一生产者和单一消费者 可知,仅仅增加了下面的代码
// 用于生产者之间的竞争
std::mutex _mtx_pro;
// 计算当前已经生产了多少数据了
unsigned int _cnt_cur_pro = 0;
- 1.5 生产者线程变化如下
template< typename T >
void thread_pro(const int thread_index, const int count_max_produce, repo<T>* param_repo)
{
if (nullptr == param_repo || NULL == param_repo)
return;
while (true)
{
bool is_running = true;
{
// 用于生产者之间竞争
std::unique_lock<std::mutex> lock(param_repo->_mtx_pro);
// 缓冲区没有满,继续生产
if (param_repo->_cnt_cur_pro < cnt_total_10)
{
thread_produce_item<T>(thread_index, *param_repo, param_repo->_cnt_cur_pro);
++param_repo->_cnt_cur_pro;
}
else
is_running = false;
}
std::this_thread::sleep_for(std::chrono::microseconds(16));
if (!is_running)
break;
}
}
- 1.6 完整源码
#pragma once
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <queue>
#include <vector>
std::mutex _mtx;
std::condition_variable _cv_not_full;
std::condition_variable _cv_not_empty;
const int max_queue_size_10 = 10;
enum
{
// 总生产数目
cnt_total_10 = 10,
};
template<typename T>
struct repo_
{
// 用作互斥访问缓冲区
std::mutex _mtx_queue;
// 缓冲区最大size
unsigned int _count_max_queue_10 = 10;
// 缓冲区
std::queue<T> _queue;
// 缓冲区没有满,通知生产者继续生产
std::condition_variable _cv_queue_not_full;
// 缓冲区不为空,通知消费者继续消费
std::condition_variable _cv_queue_not_empty;
// 用于生产者之间的竞争
std::mutex _mtx_pro;
// 计算当前已经生产了多少数据了
unsigned int _cnt_cur_pro = 0;
repo_(const unsigned int count_max_queue = 10) :_count_max_queue_10(count_max_queue)
, _cnt_cur_con(0)
{
;
}
repo_(const repo_&instance) = delete;
repo_& operator = (const repo_& instance) = delete;
repo_(const repo_&&instance) = delete;
repo_& operator = (const repo_&& instance) = delete;
};
template <typename T>
using repo = repo_<T>;
//----------------------------------------------------------------------------------------
// 生产者生产数据
template <typename T>
void thread_produce_item(const int &thread_index, repo<T>& param_repo, const T& repo_item)
{
std::unique_lock<std::mutex> lock(param_repo._mtx_queue);
// 1. 生产者只要发现缓冲区没有满, 就继续生产
param_repo._cv_queue_not_full.wait(lock, [&] { return param_repo._queue.size() < param_repo._count_max_queue_10; });
// 2. 将生产好的商品放入缓冲区
param_repo._queue.push(repo_item);
// log to console
std::cout << "生产者" << thread_index << "生产数据:" << repo_item << "\n";
// 3. 通知消费者可以消费了
//param_repo._cv_queue_not_empty.notify_one();
param_repo._cv_queue_not_empty.notify_one();
}
//----------------------------------------------------------------------------------------
// 消费者消费数据
template <typename T>
T thread_consume_item(const int thread_index, repo<T>& param_repo)
{
std::unique_lock<std::mutex> lock(param_repo._mtx_queue);
// 1. 消费者需要等待【缓冲区不为空】的信号
param_repo._cv_queue_not_empty.wait(lock, [&] {return !param_repo._queue.empty(); });
// 2. 拿出数据
T item;
item = param_repo._queue.front();
param_repo._queue.pop();
std::cout << "消费者" << thread_index << "从缓冲区中拿出一组数据:" << item << std::endl;
// 3. 通知生产者,继续生产
param_repo._cv_queue_not_full.notify_one();
return item;
}
//----------------------------------------------------------------------------------------
/**
* @ brief: 生产者线程
* @ thread_index - 线程标识,区分是哪一个线程
* @ count_max_produce - 最大生产次数
* @ param_repo - 缓冲区
* @ return - void
*/
template< typename T >
void thread_pro(const int thread_index, const int count_max_produce, repo<T>* param_repo)
{
if (nullptr == param_repo || NULL == param_repo)
return;
while (true)
{
bool is_running = true;
{
// 用于生产者之间竞争
std::unique_lock<std::mutex> lock(param_repo->_mtx_pro);
// 缓冲区没有满,继续生产
if (param_repo->_cnt_cur_pro < cnt_total_10)
{
thread_produce_item<T>(thread_index, *param_repo, param_repo->_cnt_cur_pro);
++param_repo->_cnt_cur_pro;
}
else
is_running = false;
}
std::this_thread::sleep_for(std::chrono::microseconds(16));
if (!is_running)
break;
}
}
/**
* @ brief: 消费者线程
* @ thread_index - 线程标识,区分线程
* @ param_repo - 缓冲区
* @ return - void
*/
template< typename T >
void thread_con(const int thread_index, repo<T>* param_repo)
{
if (nullptr == param_repo || NULL == param_repo)
return;
static int cnt_cur_con = 0;
while (true)
{
bool is_running = true;
{
// std::unique_lock<std::mutex> lock(param_repo->_mtx_con);
// 还没消费到指定的数目,继续消费
if (cnt_cur_con < cnt_total_10)
{
thread_consume_item<T>(thread_index, *param_repo);
++cnt_cur_con;
}
else
is_running = false;
}
std::this_thread::sleep_for(std::chrono::microseconds(16));
// 结束线程
if ((!is_running))
break;
}
}
// 入口函数
//----------------------------------------------------------------------------------------
int main(int argc, char *argv[], char *env[])
{
// 缓冲区
repo<int> repository;
// 线程池
std::vector<std::thread> vec_thread;
// 生产者
vec_thread.push_back(std::thread(thread_pro<int>, 1, cnt_total_10, &repository));
vec_thread.push_back(std::thread(thread_pro<int>, 2, cnt_total_10, &repository));
// 消费者
vec_thread.push_back(std::thread(thread_con<int>, 1, &repository));
for (auto &item : vec_thread)
{
item.join();
}
return 0;
}
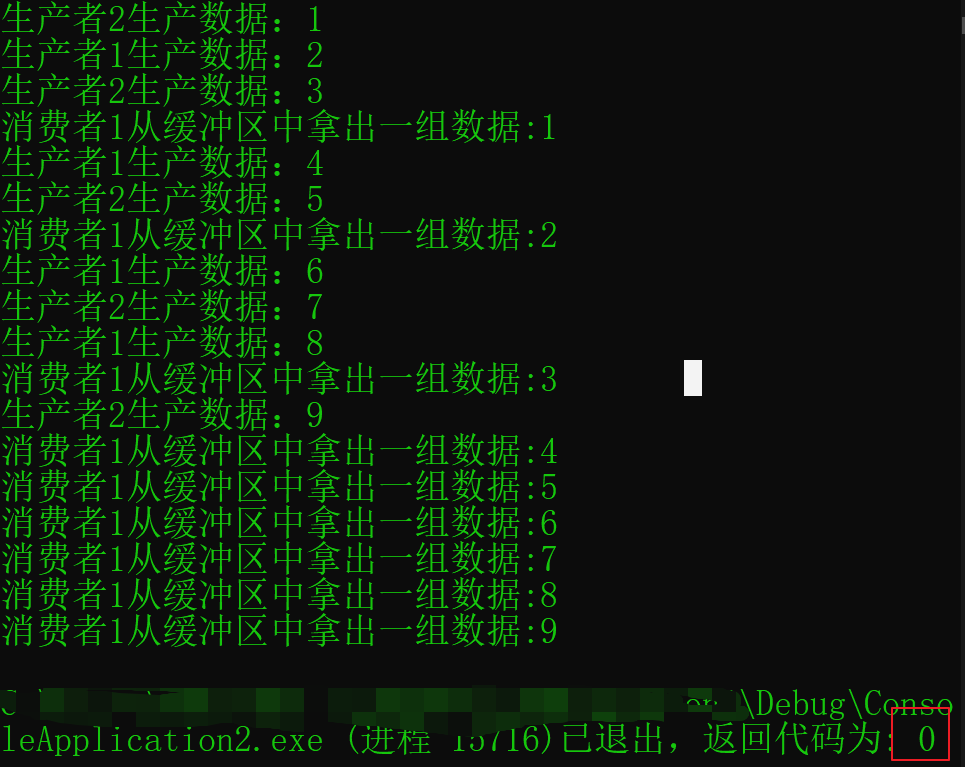
- 1.7 可能结果
再谈多线程模型之生产者消费者(多生产者和单一消费者 )(c++11实现)的更多相关文章
- 再谈多线程模型之生产者消费者(总结)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(多生产者和多消费者 )(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(单一生产者和多消费者 )(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生产者消费 ...
- 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现) 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现)[本文] 再谈多线程模型之生 ...
- 再谈多线程模型之生产者消费者(基础概念)(c++11实现)
0.关于 为缩短篇幅,本系列记录如下: 再谈多线程模型之生产者消费者(基础概念)(c++11实现)[本文] 再谈多线程模型之生产者消费者(单一生产者和单一消费者)(c++11实现) 再谈多线程模型之生 ...
- Java 多线程基础(十二)生产者与消费者
Java 多线程基础(十二)生产者与消费者 一.生产者与消费者模型 生产者与消费者问题是个非常典型的多线程问题,涉及到的对象包括“生产者”.“消费者”.“仓库”和“产品”.他们之间的关系如下: ①.生 ...
- Java 多线程详解(四)------生产者和消费者
Java 多线程详解(一)------概念的引入:http://www.cnblogs.com/ysocean/p/6882988.html Java 多线程详解(二)------如何创建进程和线程: ...
- [Java基础] java多线程关于消费者和生产者
多线程: 生产与消费 1.生产者Producer生产produce产品,并将产品放到库存inventory里:同时消费者Consumer从库存inventory里消费consume产品. 2.库存in ...
- Java多线程-同步:synchronized 和线程通信:生产者消费者模式
大家伙周末愉快,小乐又来给大家献上技术大餐.上次是说到了Java多线程的创建和状态|乐字节,接下来,我们再来接着说Java多线程-同步:synchronized 和线程通信:生产者消费者模式. 一.同 ...
随机推荐
- 3个CSS动画库,比Animated还好用,让你的网站酷炫起来
本文首发于https://www.1024nav.com/tools/css-animation-library 转载请注明出处 整理了日常前端开发中常用的css动画库,让你的网页动起来,可以在生成中 ...
- 【基因组注释】同源注释比对软件tblastn、gamp和exonerate比较
基因结构预测中同源注释策略,将mRNA.cDNA.蛋白.EST等序列比对到组装的基因组中,在文章中通常使用以下比对软件: tblastn gamp exonerate blat 根据我的实测,以上软件 ...
- python-django-请求响应对象
用户请求终端的信息: 包括使用的ip地址,浏览器类型等 cookie: 测试测试: def print_request(request): print(request) print("!!! ...
- 15.Pow(x, n)
Pow(x, n) Total Accepted: 88351 Total Submissions: 317095 Difficulty: Medium Implement pow(x, n). 思路 ...
- UE4之Slate: SImage
概述 距离上次记录<UE4之Slate:纯C++工程配置>后已经好长时间了: 这个随笔来记录并分享一下SImage控件的使用,以在屏幕上显示一张图片: 目标 通过SImage控件的展示,学 ...
- LeetCode子矩形查询
LeetCode 子矩形查询 题目描述 请你实现一个类SubrectangleQueries,它的构造函数的参数是一个rows * cols的矩形(这里用整数矩阵表示),并支持以下两种操作: upda ...
- 最新的Android Sdk 使用Ant多渠道批量打包
实例工程.所需的文件都在最后的附件中. 今天花费了几个小时,参考网上的资料,期间遇到了好几个问题, 终于实现了使用Ant批量多渠道打包,现在,梳理一下思路,总结使用Ant批量多渠道打包的方法:1 ...
- 使用MySQL的SELECT INTO OUTFILE ,Load data file,Mysql 大量数据快速导入导出
使用MySQL的SELECT INTO OUTFILE .Load data file LOAD DATA INFILE语句从一个文本文件中以很高的速度读入一个表中.当用户一前一后地使用SELECT ...
- my42_Mysql基于ROW格式的主从同步
模拟主从update事务,从库跳过部分update事务后,再次开始同步的现象 主库 mysql> select * from dbamngdb.isNodeOK; +----+--------- ...
- idea如何在git上将分支代码合并到主干
1.首先将idea中的代码分支切换到master分支,可以看到我们在dev上提交的代码 在master上是没有的 2.如图所示,在remote branch 上选择分支,点击后面的三角图标,展开之后选 ...