连通图与Tarjan算法
引言
Tarjan算法是一个基于深度优先搜索的处理树上连通性问题的算法,可以解决,割边,割点,双连通,强连通等问题。
首先要明白Tarjan算法,首先要知道它能解决的问题的定义。
连通图
无向图
由双向边构成的图称之为连通图。
割点与桥
给定的无向图中删去节点x,无向图被分割成两个或两个以上的不相连子图,则称节点x为图的割点(割顶,关键点)。
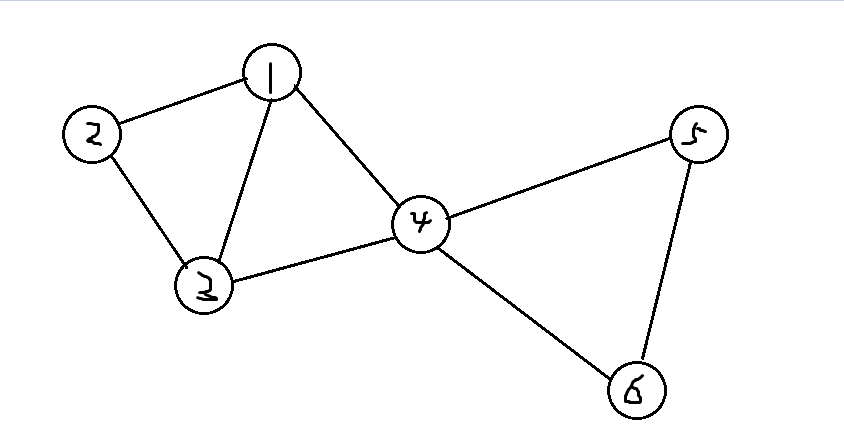
这是一个无向图,其中点4就是一个割点,去掉该点,图会变成,{1,2,3},{5,6}两个不连续的子图,如下图
给定的无向图中删去边e,无向图被分割成两个或两个以上的不相连子图,则称边e为图的割边或桥。
这是一个无向图,其中红边都是割边,去掉任意一个边,图都会变成两个不连续的子图,如下图

双连通
无割点的无向连通图称它为点双连通图,无割边的无向连通图称它为边双连通图,统称双连通图。
无向图的极大点双连通子图称它为点双连通分量v-DCC,无向图的极大边双连通子图称它为边双连通分量e-DCC,统称为双连通分量 DCC(double connected components)
(-分量:图的一个满足什么条件的最大子图。)

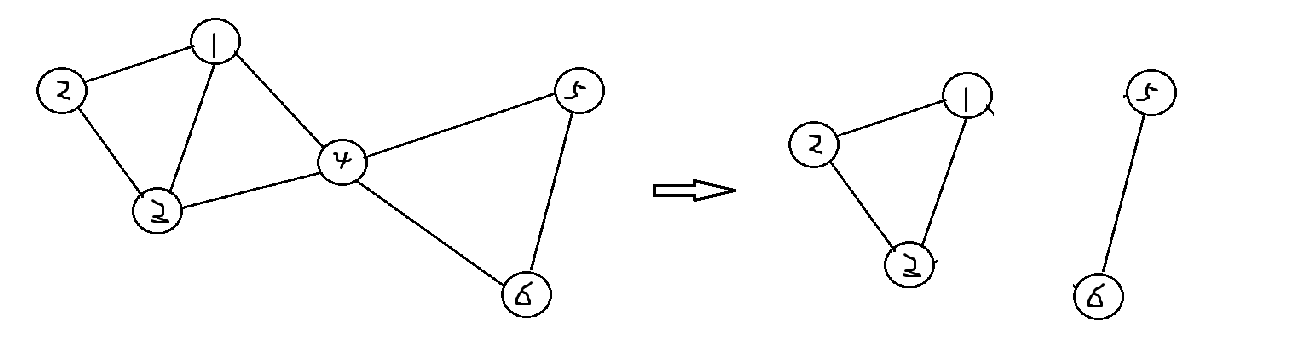
上图G中,子图{1,2,4,3}是图G的一个点双连通子图,但不是点双连通分量,子图{2,4,5}也只是一个点双连通子图,不是点双连通分量,子图{1,2,5,4,3},{5,8},{5,6},{6,7}都是G的点双连通分量。
要注意定义中的极大。
定理
一个无向图是点双连通图,当且仅当满足以下两个条件之一
1.图的顶点数不超过2.
2.图中任意两点都同时包含在至少一个简单环中。
(简单环:简单环又称简单回路,图的顶点序列中,除了第一个顶点和最后一个顶点相同外,其余顶点不重复出现的回路叫简单回路。或者说,若通路或回路不重复地包含相同的边,则它是简单的,简单的说就是不自交的环。)
这些都是点双连通图
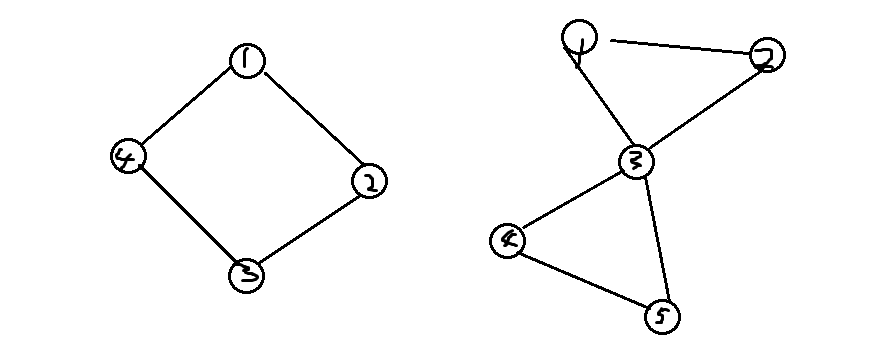
左边环{1,2,3,4,1}是简单环,右边环{1,2,3,5,4,3,1}不是简单环,右边环{1,2,3,1}是简单环。
一个无向图是边双连通图,当且仅当任意一条边都包含在至少一个简单环中。
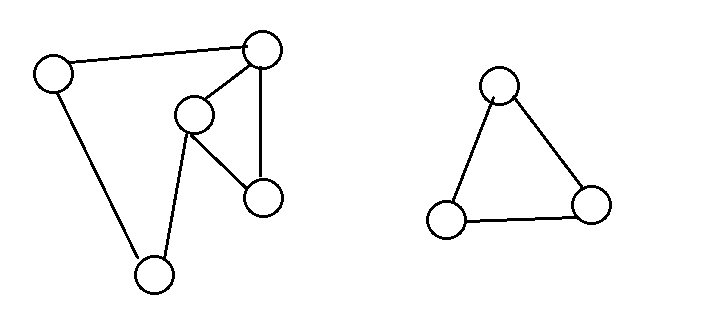
这些是边双连通图
有向图
由单向边构成的图称之为有向图
强连通分量 SCC(strongly connected components)
一个有向图中任意两个节点可以互相到达则称该图为强连通图
有向图的极大强连通子图被称为强连通分量
必经点
起点为S,终点为T,若从S到T的每条路径都经过一个点x,该点就是S到T的一个必经点。
必经边
同理,起点为S,终点为T,若从S到T的每条路径都经过一个边x,该边就是S到T的一个必经点。
无向图的Tarjan算法
Tarjan算法的复杂度为O(V+E)
这里讲无向图的Tarjan算法,以下的“图”,若无特别说明都默认指无向图。
首先我们引入一些定义。
时间戳
图的深度优先搜索过程中,按照每一个节点依次按1~N给与的一个标记,称之为时间戳,有的人也叫它dfs序,一般记为dfn[x]。
(时间戳的定义很关键,后面一些算法都有用到,如树链剖分。因为它本身能处理树上的子树问题,把复杂的子树结构变成一串连续的数字,因为它有个特点,时间戳大于等于当前点的时间戳,并且小于等于该子树最后一个节点的时间戳的节点必定在当前节点的子树中。)
搜索树
对一个图进行深度优先搜索,每个节点遍历一次,所有经过的节点和边构成的一个子图就是一颗树,称它为搜索树,也有人叫它dfs树。当搜索的是有向图的时候,由于有向图不一定连通,所以会构成多颗搜索树,合起来构成搜索森林。
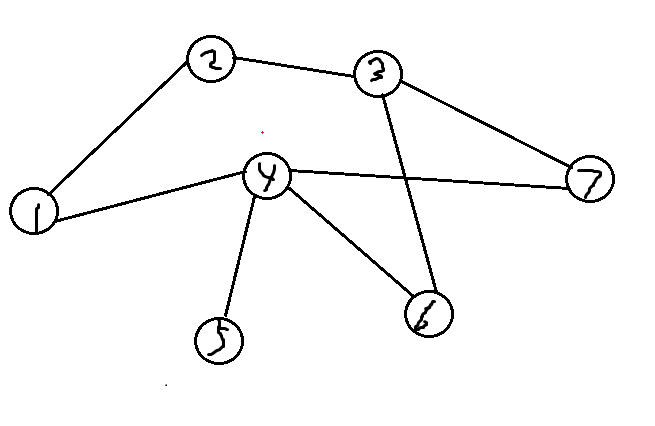
这是一个图,对他从点1开始是进行深度优先搜索,结果如下图。
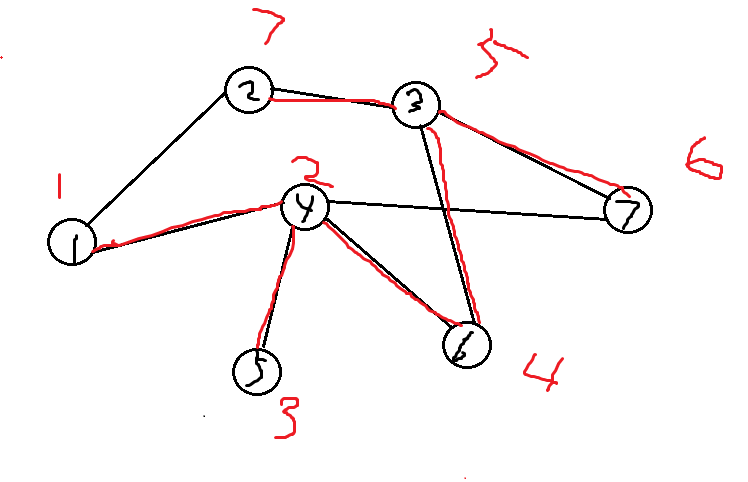
从点1开始,顺时针寻边,点上数字即dfs序,红线是搜索路径,红线加上遍历的那些点,构成一颗搜索树。
我们记在图中非搜索树中的边,为回溯边,这时回溯边有个有意思的性质,被回溯边相连的点一定有祖孙关系。
证明:
回溯边的出现条件是,深度优先搜索过程中遍历到的一条边指向已遍历过的点。若出现回溯边(a,b)。设dfn(a)>dfn(b) ,此时一定是点b连向a,也就是说正在遍历点b。如果要使回溯边连接的两个点无,祖孙关系,一定要使深度优先搜索遍历回退后再遍历到b,但由于深度优先搜索的性质,它在搜索点a时一定会将点a周围所有边遍历后再回退,所以b如果能通过a有一条不经过a的祖先节点的道路相连,a就一定是b的祖先。
(祖孙关系:设树上两点a,b,subtree(a)中包含b 或 subtree(b)包含a)

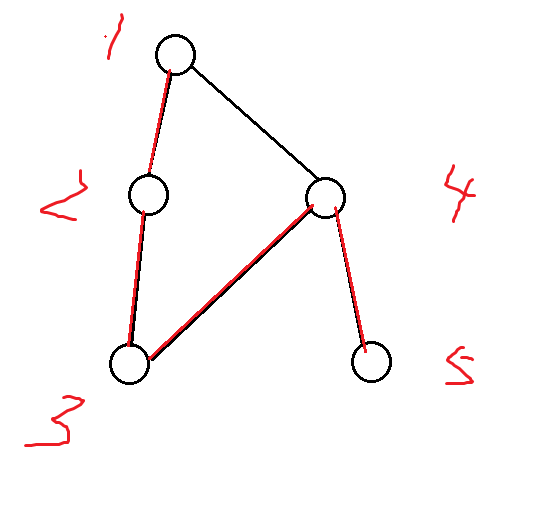
如有个这样的图,它的搜索树不可能是如下图,因为在遍历到3点的时候,会继续遍历4点
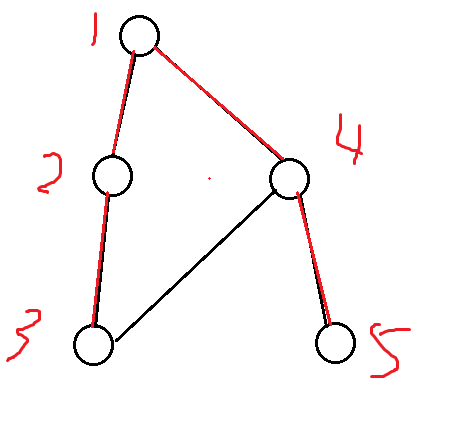
正确的图应该如此
追溯值
设subtree(x)表示搜索树中以x为根的子树,追溯值low[x]表示subtree(x)中节点的时间戳和通过subtree(x)中节点中不在搜索树中的直接相邻的边可以到达的所有节点的时间戳的最小值。
或者说,low[x]表示min(low(subtree(x)))与subtree(x)直接相连的回溯边连接的时间戳的最小值。其中low(S)表示集合S中所有的元素的追溯值的集合。min(S)表示集合S中的最小值。
很容易知道,当图是一颗树的时候low[x]会等于dfn[x]。当非根节点x的追溯值low[x]小于它的父节点f的时间戳dfn[f]时说明,子树subtree(x)中没有任意一个点能通过图中的一条边到达,

图中紫色数字是追溯值,也就是low数组的值,其中low[1]=1,因为subtree(1)中有条边(2,1)指向时间戳为1的点1,所以点1的追溯值是1,同理,点4、6、3、2的子树中都有边(2,1),所以也追溯值也都是1。点5的追溯值是3,因为subtree(5)中没有任何一条不在搜索树中的边指向最小值,subtree(5)中唯一一条边(5,4)在搜索树上所以不能更新low[5],所以low[5]的值是dfn[5]就是3,subtree(7)中有条回溯边。
求时间戳和追溯值的代码,Tarjan的基本框架。
vector<int>e[N];
int dfn[N], low[N];
int tol = 0;
//x表示当前遍历的点,f表示x的父节点
void tarjan(int x,int f) {
dfn[x] = ++tol;
low[x] = dfn[x]; for (int i = 0;i< e[x].size(); i++) {
int y = e[x][i];
if (!dfn[y]) {
tarjan(y, x);
low[x] = min(low[x], low[y]);
}
else if(y!=f){//判断这条边是不是搜索树上的边
low[x] = min(low[x], dfn[y]);
} }
}
代码很简单,图使用的是std动态数组实现的邻接表储存,但要理解需要对深度优先搜索的过程有比较深刻的了解。这属于基本功,就不多过解释代码了。
Tarjan求割点割边
割边
定理:无向边(x,y)是割边,当且仅当搜索树上存在点x的一个子节点y,满足: dfn[x]<low[y]
证明:
根据定义,dfn[x]<low[y],说明,从subtree(y)出发,在不经过边(x,y)的前提下,不存在一条边能到达,x或比x更早访问的节点。再由上文搜索树的性质,也不存在一条边,可以到达非点y祖宗的节点。若把边(x,y)删除,则subtree(y)就形成一个孤立的图,即删除边(x,y)把原图分割成两个不相连通的子图,所以根据割边的定义,此时边(x,y)为割边。
性质:割边一定是搜索树的边,并且一个简单环中的边一定不是割边。
如上图中边(4,5)就是一条割边,因为dfn[4]<low[5]。下图中红边是搜索树,黑色数字是点序号同时也是时间戳,红数字是追溯值。其中只有边(4,7)是割点,因为,dfn[4]<low[7],即4>7,同时,其他所有边都在简单环内。割去边(4,7)后图被分割成两个不相连通的子图。

割点
定理:非根节点x是割点,当且仅当搜索树上存在点x的一个子节点y,满足: dfn[x]<=low[y]
若节点x为根,那至少要有两个子节点y1,y2满足上述情况。
证明与割边类似,这里就不在赘述。
在上图中,节点4、7都为割点,因为dfn[4]=low[5],dfn[7]=low[8]。
代码
割边
vector<int>e[N];
int dfn[N], low[N];
int tol = 0;
//x表示当前遍历的点,f表示x的父节点
void tarjan(int x,int f) {
dfn[x] = ++tol;
low[x] = dfn[x]; for (int i = 0;i< e[x].size(); i++) {
int y = e[x][i];
if (!dfn[y]) {
tarjan(y, x);
low[x] = min(low[x], low[y]);
if (dfn[x] < low[y]) { }
}
else if(y!=f){//判断这条边是不是搜索树上的边
low[x] = min(low[x], dfn[y]);
} }
}
割点
vector<int>e[N];
int dfn[N], low[N];
int cut[N];
int tol = 0; int n, m;
void tarjan(int x, int f) {
dfn[x] = ++tol;
low[x] = dfn[x];
int flag = 0;
ll tmp = 0;
for (int i = 0; i < e[x].size(); i++) {
int y = e[x][i];
if (!dfn[y]) {
tarjan(y, x);
low[x] = min(low[x], low[y]); if (dfn[x] <= low[y]) {
if (x != 1 || flag) {//特判根节点
cut[x] = 1;//标记点
}
flag++;
}
}
else if (y != f) {
low[x] = min(low[x], dfn[y]);
} }
}
Tarjan求双连通分量与缩点
缩点
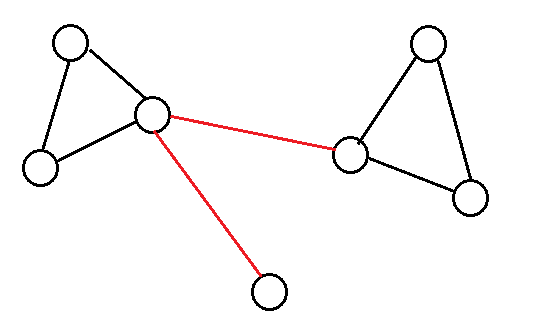
缩点顾名思义,就是把图中多个点根据要求合并成一个点,以此来减少处理问题的复杂度。
和双连通分量有关的题,大部分情况都要用上缩点, 把每一个双连通分量缩成一个点,新图就会变成一颗树,方便我们处理问题。
缩点的时候要注意处理重边和自环。
如下图就是一个简单的缩点,缩点后把边合并了。

边双连通分量(e-DCC)
边双连通分量好处理,先跑一遍tarjan找割边,再对整张图进行深度优先搜索(不经过割边),对每一个连通块标记。其中,每一个连通块就是一个边双连通分量。
简单的说,就是去掉割边后的所有连通块都是一个边双连通分量。因为要标记边所以这里使用链式前向星更为方便处理。当然vector实现的邻接表也能够处理。
e-DCC缩点
把每一个e-DCC都看做一个节点,把割边当作新点的边,连接它们,就会形成一颗树,这就是e-DCC缩点。
为了方便处理可以在Tarjan的过程在中先储存割边,最后好对新图进行连边。
下图过程就是e-DCC割点的过程,先找到割边,再确定e-DCC,最后将每一个e-DCC缩成一个点。由于e-DCC缩点的代码简单,也比较少用,就不给出代码了。

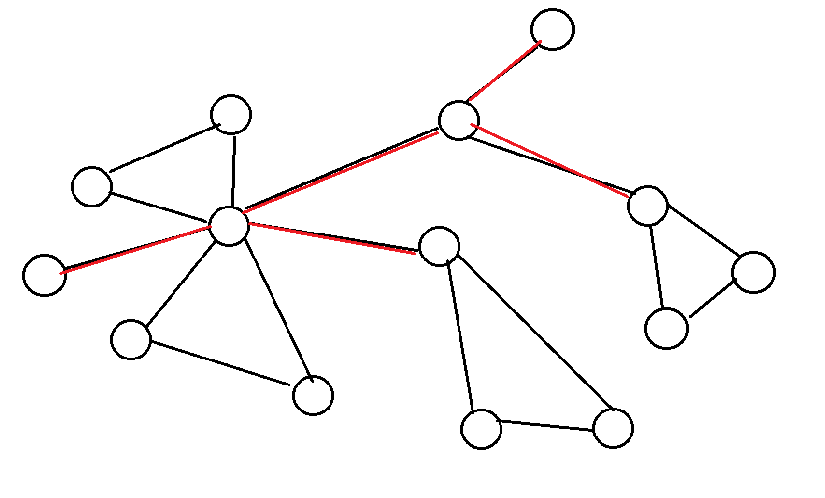

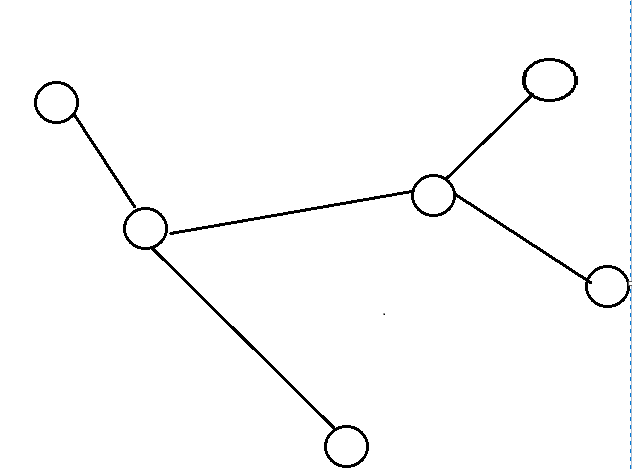
点双连通分量(v-DCC)
v-DCC与e-DCC不同,并不是去掉割点后的连通块就是v-DCC,割点也是v-DCC中的一个节点,并且割点还不止是一个v-DCC的节点,上文v-DCC定义处给的例图应该指出了这种情况,没有理解清楚,可以看图重新理解下。
因为以上性质,我们要求出v-DCC就较为麻烦,为了求出v-DCC我们可以在Tarjan的过程中使用栈来帮助处理,并按如下情况维护栈内元素。
1.当一个节点第一次被访问时,把该节点入栈。
2.dfn[x]<=low[y]时,不断弹出节点,直到y被弹出。
每一次的连续弹出的节点就是一个v-DCC。(e-DCC其实也可以用一样的方法得出,学有余力的读者试试实现)
原理很简单,和上文中时间戳的特殊用法同理,按深度优先搜索入栈的节点不停弹出直到弹至当前节点时,根据上文Tarjan算法的原理,那些被弹出部分就是一个独立的连通块,并且由于该连通块下方,其他的有割点的区块都被弹出了,所以当前弹出的部分就是一个v-DCC。
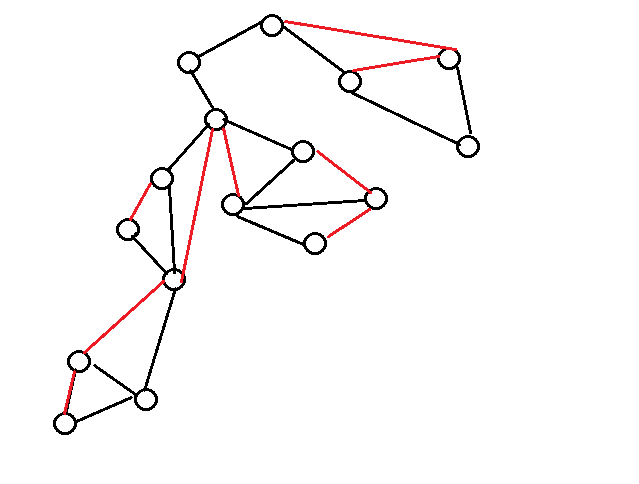
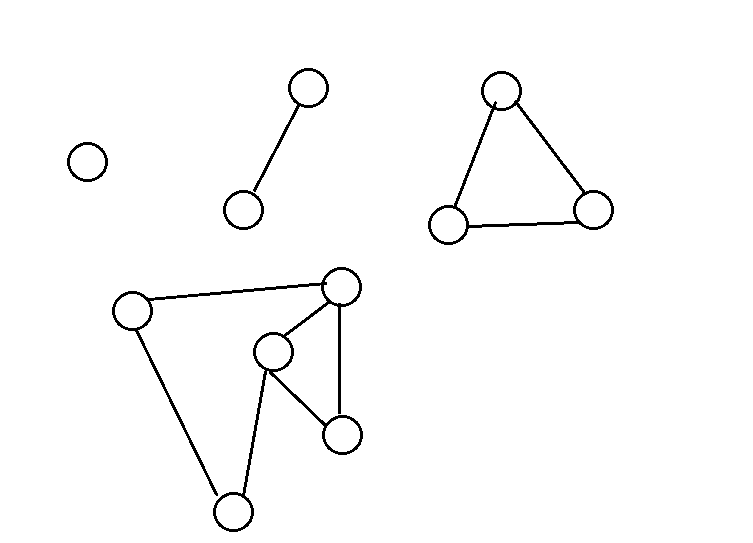
这是一个图,其中黑色的为搜索树,红色的边回溯边。

每一个用红色粗线圈起来的连通块都是一个v-DCC
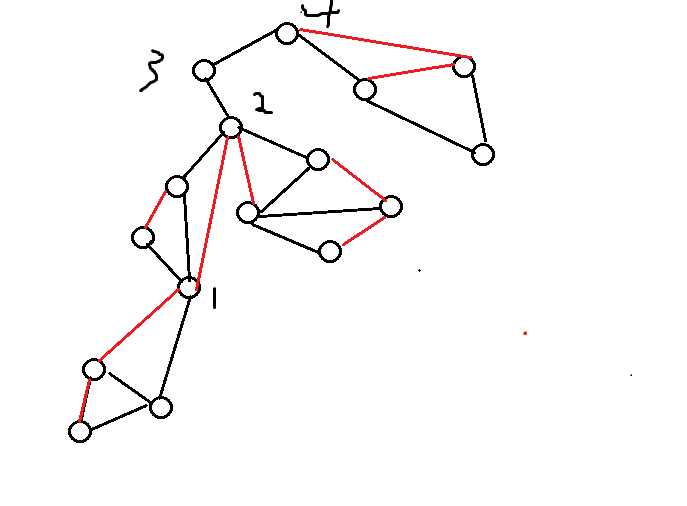
我们将割点编号。
在Tarjan的过程中,首先遍历到的割点是,左下角第一个割点1.此时满足条件dfn[x]<=low[y],对栈进行弹出操作,直到弹出的节点为节点1的子节点,把这些点再加上节点1本身,这就是一个v-DCC,这时继续回退,到下一个割点节点2,因为前面已经把很多节点弹出了,所以这时栈中节点2后的元素,只有节点1和节点1到节点2之间的那些节点,节点1的孙子节点全部被弹出,即subtree(1) 中的节点除了节点1其他的全部被弹出,这样保证了上方的v-DCC不会被下方的割点所影响。用一样的步骤我们也同样能得出下一个v-DCC,即节点2,节点1,与节点1,2之间的那两个节点。
缩点为如下图
具体实现见代码。
代码
vector<int>e[N],dcc[N];
int dfn[N], low[N];
int cut[N];
int tol = 0;
stack<int>s;
int cnt;
int n, m;
void tarjan(int x, int f) {
dfn[x] = ++tol;
low[x] = dfn[x];
int flag = 0;
ll tmp = 0;
for (int i = 0; i < e[x].size(); i++) {
int y = e[x][i];
if (!dfn[y]) {
tarjan(y, x);
low[x] = min(low[x], low[y]); if (dfn[x] <= low[y]) {
if (x != 1 || flag) {
cut[x] = 1;
}
flag++;
cnt++;
int z;
do {
z = s.top();
s.pop();
dcc[cnt].emplace_back(z);
} while (z != y);
dcc[cnt].emplace_back(x);
}
}
else if (y != f) {
low[x] = min(low[x], dfn[y]);
} }
}
v-DCC缩点
v-DCC的缩点较e-DCC的缩点麻烦,但也很简单,在对每一个连通块编号后,再对每一个割点编号,然后遍历连通块,将与连通块相连的割点连接起来,要注意的是连通块中有割点本身,遍历到割点本身的时候不需要操作。
代码
int cut[N];//割点的标记
int id[N];//新节点编号
int cnt;//新节点数量
int num;//节点计数器 for (int i = 1; i <= n; i++) {
if (cut[i])id[i] = ++num;
}
for (int i = 1; i <= cnt; i++) {
for (int j = 0; j < dcc[i].size(); j++) {
int x = dcc[i][j];
if (cut[x]) {
//加边(i,id[x])
} }
}
有向图的Tarjan算法
Tarjan求强连通分量
无向图的Tarjan和有向图类似,也有它对应的,搜索树,时间戳,追溯值,首先还是先讲解这些东西的定义。
流图(Flow Graph)
给定有向图G,若存在一点r,能到达G中所以点,则称G为一个流图。其中称r为流图的源点。
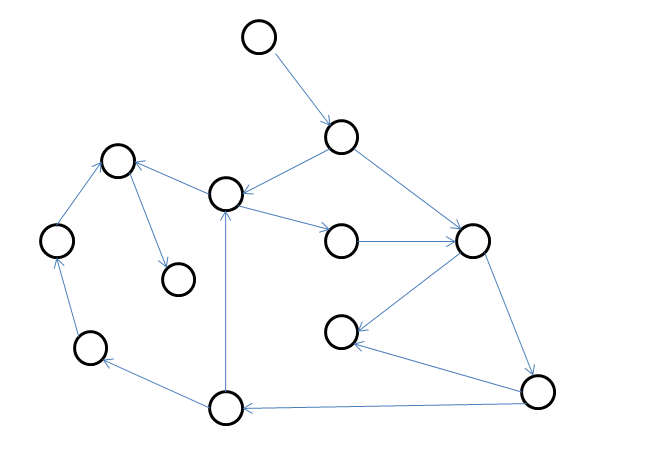
该无向图为一张流图,流图的源点为最上方的那点。
搜索树
和无向图类似,对流图的源点进行深度优先搜索,每一个点只访问一次,遍历过的点与边产生的以源点为根的树就是该流图的搜索树
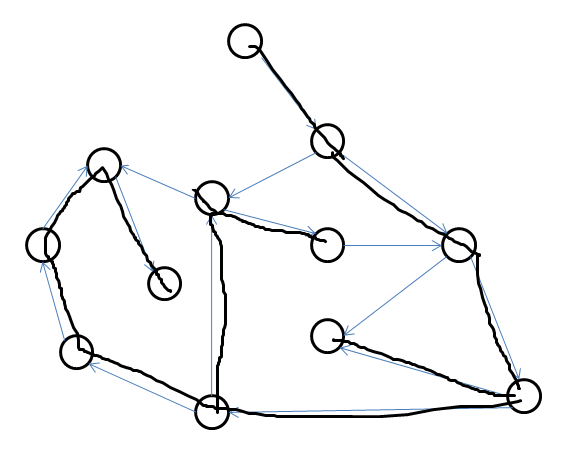
黑线构成的以最上方那点的树为该流图的搜索树,边的搜索顺序是入边开始顺时针。
时间戳
同样,在深度优先搜索中,按访问顺序给每一个节点从1编号,这些编号被称为时间戳,同记为dfn[x]。

点边的黑色数字为该点的时间戳。
流图边
流图上有向边(x,y)必定分为以下4种。
1.树枝边,搜索树上的边,即x为y的父节点。
2.前向边,x是y的祖先节点。
3.后向边,y是x的祖先节点。
4.横叉边,除以上三种情况的边。(必定满足dfn[y]<dfn[x]。)
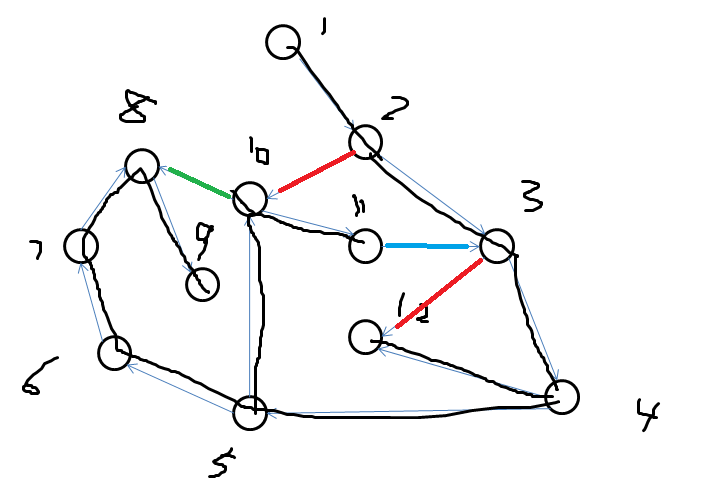
上图中
黑色的边为树枝边。
红色的边为前向边。
蓝色的边为后向边。
绿色的边为横叉边。
追溯值
有向图的追溯值较无向图复杂,我们先思考,强连通分量的性质。
如果图中存在x到y的路径,也存在y到x的路径,那x,y就在一条环路上,一个环路一定是强连通图,环上任意两点可互相到达。有向图Tarjan算法的基本思路就是对每一个点,尽量找到与它一起能构成环的所有节点,也就是找到,x到y的路径和y到x的路径。
容易发现,在上面定义中前向边(x,y)没有什么用处,因为搜索树中已经存在一条路径能使x到y。后向边可以和搜索树上的边直接构成一个环路。虽然横叉边(x,y)不能直接和搜索树上的边构成环路,但如果能在图上找到一条从y出发到x的路径就是有用的,比如它可能可以和后向边(y,z),搜索树上的路径(z,x),构成环路{z...x,y,z}。
为了找到横叉边和后向边构成的环路,Tarjan算法在深度优先搜索的过程中维护了一个栈。
栈中保存以下两类节点。
1.搜索树上x的祖先节点,记为anc(x)。
如果此时遍历到边(x,y) ,y属于anc(x),那边(x,y)就是一条后向边,后向边和树上路径构成环路。
2.已经访问过,并且存在一条路径到达anc(x)的节点。
如果存在点z,从z出发存在一条路径到达y(y属于anc(x))。若存在,一条横叉边(x,z),则,(x,z)、z到y的路径、y到x的路径形成一个环路。
同样,我们设subtree(x)表示流图的搜索树中以x为根的子树。x的追溯值low[x]定义为满足以下条件的节点的最小时间戳。
1.该点在栈中。
2.subtree(x)出发的边能到达的点。
根据定义我们可有如下方法计算追溯值。
1.当前点x第一次访问,将x入栈,初始化low[x]=dfn[x]。
2.扫描从x出发的所有边(x,y),
(1).若点y没有被访问,则递归访问y,当y回溯后,令low[x]=min(low[x],low[y])。
(2).若点y被访问,并且y在栈内,令low[x]=min(low[x],dfn[y])。
3从x回溯前,判断low[x]=dfn[x],若成立,则弹出节点,直至x出栈。
从栈中连续弹出的节点就组成一个强连通分量。至于证明,以上已经讲的比较清晰了,并且与上文中无向图的也类似,就不予重复证明了。
代码
代码和无向图的也类似。
vector<int>e[N];
int dfn[N], low[N];
stack<int>s;
int ins[N], c[N];//ins[x] 表示x节点有无在栈中,c[x]表示点x在第几个scc中
vector<int>scc[N];//scc[x]表示第x个scc的集合
int n, m, tol, cnt; void tarjan(int x) {
dfn[x] = ++tol;
low[x] = dfn[x];
s.push(x);
ins[x] = 1;
for (int i = 0; i < e[x].size(); i++) {
int y = e[x][i];
if (!dfn[y]) {
tarjan(y);
low[x] = min(low[x], low[y]);
}
else if (ins[y]) {
low[x] = min(low[x], dfn[y]);
}
}
if (dfn[x] == low[x]) {
cnt++;
int y;
do {
y = s.top();
s.pop();
ins[y] = 0;
c[y] = cnt;
scc[cnt].emplace_back(y);
} while (x != y);
} }
缩点
与无向图e-DCC缩点类似,我们把每一个SCC缩成一个点,最后构成一个有向无环图。
Tarjan求必经点与必经边
Lenguar-Tarjan算法通过计算支配树(Dominator-Tree),能够在O(nlogn)的时间求出单源的必经点与必经边。
另外
代码中的emplace_back(),方法为c++11的新特性,和push_back()的意思一样,但它可以减少一次加入时的拷贝操作,理论上速度比push_back()快一倍。
连通图与Tarjan算法的更多相关文章
- 无向连通图求割点(tarjan算法去掉改割点剩下的联通分量数目)
poj2117 Electricity Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 3603 Accepted: 12 ...
- Tarjan算法:求解无向连通图图的割点(关节点)与桥(割边)
1. 割点与连通度 在无向连通图中,删除一个顶点v及其相连的边后,原图从一个连通分量变成了两个或多个连通分量,则称顶点v为割点,同时也称关节点(Articulation Point).一个没有关节点的 ...
- TarJan 算法求解有向连通图强连通分量
[有向图强连通分量] 在有向图G中,如果两个 顶点间至少存在一条路径,称两个顶点强连通(strongly connected).如果有向图G的每两个顶点都强连通,称G是一个强连通图.非强连通图有向图的 ...
- 有向图强连通分支的Tarjan算法讲解 + HDU 1269 连通图 Tarjan 结题报告
题目很简单就拿着这道题简单说说 有向图强连通分支的Tarjan算法 有向图强连通分支的Tarjan算法伪代码如下:void Tarjan(u) {dfn[u]=low[u]=++index//进行DF ...
- 强连通分量的Tarjan算法
资料参考 Tarjan算法寻找有向图的强连通分量 基于强联通的tarjan算法详解 有向图强连通分量的Tarjan算法 处理SCC(强连通分量问题)的Tarjan算法 强连通分量的三种算法分析 Tar ...
- tarjan算法--求无向图的割点和桥
一.基本概念 1.桥:是存在于无向图中的这样的一条边,如果去掉这一条边,那么整张无向图会分为两部分,这样的一条边称为桥无向连通图中,如果删除某边后,图变成不连通,则称该边为桥. 2.割点:无向连通图中 ...
- Tarjan算法求有向图的强连通分量
算法描述 tarjan算法思想:从一个点开始,进行深度优先遍历,同时记录到达该点的时间(dfn记录到达i点的时间),和该点能直接或间接到达的点中的最早的时间(low[i]记录这个值,其中low的初始值 ...
- tarjan算法 POJ3177-Redundant Paths
参考资料传送门 http://blog.csdn.net/lyy289065406/article/details/6762370 http://blog.csdn.net/lyy289065406/ ...
- Tarjan算法应用 (割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)问题)(转载)
Tarjan算法应用 (割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)问题)(转载) 转载自:http://hi.baidu.com/lydrainbowcat/blog/item/2 ...
随机推荐
- 不藏了,这些Java反射用法总结都告诉你们
摘要:Java反射是一种非常强大的机制,它可以在同一个系统中去检测内部的类的字段.方法和构造函数.它非常多的Java框架中,都大量应用了反射技术,如Hibernate和Spring.可以说,反射机制的 ...
- Java高质量面试总结
面试 一般都是由浅到深去问,思路是: 先考察基础是否过关,因为基础知识决定了一个技术人员发展的上限 再通过深度考察是否有技术热情和深度以及技术的广度 同时可能会提出一些质疑和挑战来考察候选人能否与有不 ...
- IDEA部署了项目,其他页面可以正常访问,但访问tomcat的localhost:8080却出现404
解决方案 点击Edit Configurations 点击右边的加号, 把目录放在你tomcat目录下的ROOT目录.之后就可以正常运行了
- SpringBoot 如何统一后端返回格式?老鸟们都是这样玩的!
大家好,我是飘渺. 今天我们来聊一聊在基于SpringBoot前后端分离开发模式下,如何友好的返回统一的标准格式以及如何优雅的处理全局异常. 首先我们来看看为什么要返回统一的标准格式? 为什么要对Sp ...
- pxe+kickstart部署多个版本的Linux操作系统(下)---实践篇
我们在企业运维环境中,难免会遇到使用多个Linux操作系统的情况,如果每天都需要安装不同版本的Linux系统的话,那么使用Kickstart只能安装一种版本的Linux系统的方法则显得有些捉襟 ...
- Spring 的循环依赖问题
什么是循环依赖 什么是循环依赖呢?可以把它拆分成循环和依赖两个部分来看,循环是指计算机领域中的循环,执行流程形成闭合回路:依赖就是完成这个动作的前提准备条件,和我们平常说的依赖大体上含义一致.放到 S ...
- Python - 基本数据类型_str 字符串
前言 字符串是编程中最重要的数据类型,也是最常见的 字符串的表示方式 单引号 ' ' 双引号 " " 多引号 """ ""&quo ...
- ES6新增语法(四)——面向对象
ES6中json的2个变化 简写:名字和值相同时,json可以可以简写 let a=12,b=5; let json = { a, b } console.log(json) // { a:12 , ...
- poj 折半搜索
poj2549 Sumsets 题目链接: http://poj.org/problem?id=2549 题意:给你一个含有n(n<=1000)个数的数列,问这个数列中是否存在四个不同的数a,b ...
- 如何监控 Log4j2 异步日志遇到写入瓶颈
如何监控 Log4j2 异步日志遇到写入瓶颈 在之前的一篇文章中(一次鞭辟入里的 Log4j2 异步日志输出阻塞问题的定位),我们详细分析了一个经典的 Log4j2 异步日志阻塞问题的定位,主要原因还 ...