[DB] Spark Core (3)
高级算子
- mapPartitionWithIndex:对RDD中每个分区(有下标)进行操作,通过自己定义的一个函数来处理
- def mapPartitionsWithIndex[U](f: (Int, Iterator[T]) ⇒ Iterator[U])
- f 是函数参数,接收两个参数
- Int:分区号
- Iterator[T]:分区中的元素
- Iterator[U]:处理完的结果

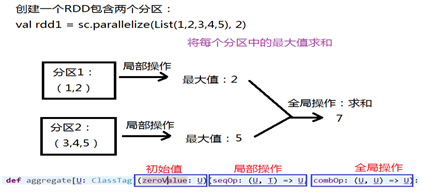
- aggregate:聚合操作(类似分组)
- 先对局部进行聚合操作,再对全局进行聚合操作
- rdd1.aggregate(0)(max(_,_),_+_) 结果 7
- rdd1.aggregate(10)(max(_,_),_+_) 结果 30
- aggregateByKey:类似aggregate,操作<Key Value>
- coalesce:重分区,默认不会进行shuffle
- repartition:重分区,对数据进行shuffle
编程案例
- 分析Tomcat的访问日志,找到访问最高的两个网页
- 对网页访问量求和
- 排序(降序)


1 package day0608
2
3 import org.apache.spark.{SparkConf, SparkContext}
4
5 object MyTomcatLogCount {
6 def main(args: Array[String]): Unit = {
7 val conf = new SparkConf().setAppName("MyTomcatLogCount").setMaster("local")
8 val sc = new SparkContext(conf)
9
10 /*
11 * 日志:192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713
12 * 返回:(hadoop.jsp,1),相当于WordCount中的<k2 v2>
13 */
14 val rdd1 = sc.textFile("G:\\K\\TZ-Bigdata\\讲义\\1101-Spark案例分析\\代码\\localhost_access_log.2017-07-30.txt").map(line => {
15 //解析字符串,找到jsp的名字
16 //得到双引号位置
17 val index1 = line.indexOf("\"")
18 val index2 = line.lastIndexOf("\"")
19 val line1 = line.substring(index1+1,index2) // 得到 GET /MyDemoWeb/head.jsp HTTP/1.1
20
21 //得到两个空格位置
22 val index3 = line1.indexOf(" ")
23 val index4 = line1.lastIndexOf(" ")
24 val line2 = line1.substring(index3+1,index4) // 得到 /MyDemoWeb/head.jsp
25
26 //得到jsp的名字
27 val jspName = line2.substring(line2.lastIndexOf("/") + 1)
28
29 //返回
30 (jspName,1)
31 })
32 //按照jsp的名字进行聚合操作,类似WordCount
33 val rdd2 = rdd1.reduceByKey(_+_) // 得到所有jsp访问总量,如(hadoop.jsp,9) (oracle.jsp,9)
34
35 //排序,按value降序顺序
36 val rdd3 = rdd2.sortBy(_._2,false)
37
38 //取出访问量最高的两个网页
39 println(rdd3.take(2).toBuffer)
40 sc.stop()
41 }
42 }
ArrayBuffer((oracle.jsp,9), (hadoop.jsp,9))
- 创建自定义分区
1 package day0608
2
3 import org.apache.spark.{Partitioner, SparkConf, SparkContext}
4 import scala.collection.mutable.HashMap
5
6 object MyTomcatLogPartitioner {
7 def main(args: Array[String]): Unit = {
8 val conf = new SparkConf().setAppName("MyTomcatLogPartitioner").setMaster("local")
9 val sc = new SparkContext(conf)
10
11 /*
12 * 日志:192.168.88.1 - - [30/Jul/2017:12:53:43 +0800] "GET /MyDemoWeb/head.jsp HTTP/1.1" 200 713
13 * 返回:(hadoop.jsp,对应的日志),相当于WordCount中的<k2 v2>
14 */
15
16 val rdd1 = sc.textFile("G:\\K\\TZ-Bigdata\\讲义\\1101-Spark案例分析\\代码\\localhost_access_log.2017-07-30.txt")
17 .map(line => {
18 //解析字符串,找到jsp的名字
19 //得到双引号位置
20 val index1 = line.indexOf("\"")
21 val index2 = line.lastIndexOf("\"")
22 val line1 = line.substring(index1+1,index2) // 得到 GET /MyDemoWeb/head.jsp HTTP/1.1
23
24 //得到两个空格位置
25 val index3 = line1.indexOf(" ")
26 val index4 = line1.lastIndexOf(" ")
27 val line2 = line1.substring(index3+1,index4) // 得到 /MyDemoWeb/head.jsp
28
29 //得到jsp的名字
30 val jspName = line2.substring(line2.lastIndexOf("/") + 1)
31
32 //返回(jsp的名字,访问日志)
33 (jspName,line)
34 })
35
36 //得到不重复的jsp名字,创建分区规则
37 val rdd2 = rdd1.map(_._1).distinct().collect()
38
39 //创建分区规则
40 val myPartitioner = new MyWebPartitioner(rdd2)
41
42 //对rdd1进行分区
43 val rdd3 = rdd1.partitionBy(myPartitioner)
44
45 //输出
46 rdd3.saveAsTextFile("G:\\K\\TZ-Bigdata\\讲义\\1101-Spark案例分析\\output")
47
48 sc.stop()
49 }
50 }
51
52 //根据jsp名字,创建分区规则
53 class MyWebPartitioner(jspList:Array[String]) extends Partitioner{
54 //定义集合保存分区条件
55 //String:jsp的名字 Int:对应的分区号
56 val partitionMap = new HashMap[String,Int]()
57
58 var partID = 0
59 for(jsp <- jspList){
60 partitionMap.put(jsp,partID)
61 partID += 1
62 }
63 //实现抽象方法
64 //返回有多少分区
65 override def numPartitions:Int = partitionMap.size
66
67 //根据jsp的名字key,查找对应的分区号
68 override def getPartition(key: Any):Int = {
69 partitionMap.getOrElse(key.toString,0)
70 }
71 }

- 操作数据库(把结果存入MySQL)
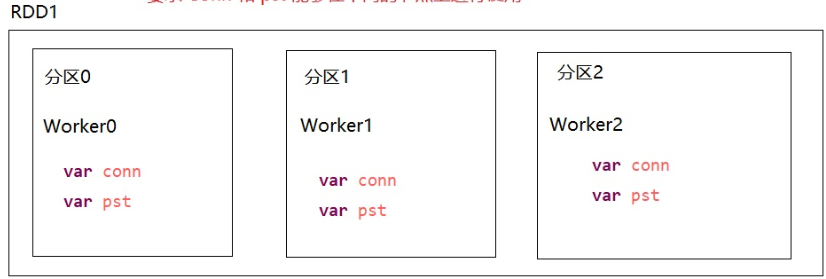
- 对分区进行操作
- conn和pst在不同的分区(节点)上进行使用
1 package day0611
2
3 import org.apache.spark.SparkConf
4 import org.apache.spark.SparkContext
5 import java.sql.DriverManager
6
7 object MyTomcatLogCountToMysql {
8
9 def main(args: Array[String]): Unit = {
10
11 val conf = new SparkConf().setMaster("local").setAppName("MyTomcatLogCountToMysql")
12 val sc = new SparkContext(conf)
13
14 val rdd1 = sc.textFile("G:\\K\\TZ-Bigdata\\讲义\\1101-Spark案例分析\\代码\\localhost_access_log.2017-07-30.txt")
15 .map(
16 line => {
17 //解析字符串 找到jsp名字
18 //得到两个双引号之间的东西 GET /MyDemoWeb/hadoop.jsp HTTP/1.1
19 val index1 = line.indexOf("\"")
20 val index2 = line.lastIndexOf("\"")
21 val line1 = line.substring(index1 + 1, index2)
22 //得到两个空格之间的东西 /MyDemoWeb/hadoop.jsp
23 val index3 = line1.indexOf(" ")
24 val index4 = line1.lastIndexOf(" ")
25 val line2 = line1.substring(index3 + 1, index4)
26 //得到jsp名字
27 val jspName = line2.substring(line2.lastIndexOf("/") + 1)
28
29 (jspName, 1)
30 })
31
32 // var conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/company?serverTimezone=UTC&characterEncoding=utf-8", "root", "123456")
33 // var pst = conn.prepareStatement("insert into mydata values(?,?)")
34 //
35 // rdd1.foreach(f => {
36 // pst.setString(1, f._1)
37 // pst.setInt(2,f._2)
38 // pst.executeUpdate()
39 // })
40
41 // 上述代码直接运行时报错:Task not serializable
42 // 因为 conn 和 pst 没有序列化 即 不能再不同节点上进行传输
43 //
44
45 // rdd1.foreach(f => {
46 // var conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/company?serverTimezone=UTC&characterEncoding=utf-8", "root", "Chen1227+")
47 // var pst = conn.prepareStatement("insert into mydata values(?,?)")
48 // pst.setString(1, f._1)
49 // pst.setInt(2, f._2)
50 // pst.executeUpdate()
51 // })
52
53
54 // 上述代码可直接运行 相当于在本地新建连接
55 // 每条数据都创建Connection和PreparedStatement
56 // 缺点:频繁操作数据库 对数据库压力很大
57
58
59 //第二种修改方式,针对分区进行操作,每个分区创建一个conn 和 pst
60 //参数要求 (f: Iterator[(String, Int)] => Unit): Unit
61 //相当于 对 rdd1 中每个分区都调用 saveToMysql 函数
62 rdd1.foreachPartition(saveToMysql)
63 sc.stop()
64 }
65 //
66 // }
67
68 // //定义一个函数 针对分区进行操作
69 def saveToMysql(it: Iterator[(String, Int)]) {
70 //it保存的是一个分区的数据
71 var conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/company?serverTimezone=UTC&characterEncoding=utf-8", "root", "Chen1227+")
72 var pst = conn.prepareStatement("insert into mydata values(?,?)")
73
74 it.foreach(f => {
75 pst.setString(1, f._1)
76 pst.setInt(2, f._2)
77 pst.executeUpdate()
78 })
79 }
80
81 }

参考
RDD算子文档
http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
[DB] Spark Core (3)的更多相关文章
- [DB] Spark Core (1)
生态 Spark Core:最重要,其中最重要的是RDD(弹性分布式数据集) Spark SQL Spark Streaming Spark MLLib:机器学习算法 Spark Graphx:图计算 ...
- [DB] Spark Core (2)
RDD WordCount处理流程 sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map(( ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
随机推荐
- 尝试做一个.NET简单、高效、避免OOM的Excel工具
Github : https://github.com/shps951023/MiniExcel 简介 我尝试做一个.NET简单.高效.避免OOM的Excel工具 目前主流框架大多将资料全载入到记忆体 ...
- 无法打开“×××”,因为无法确认开发者的身份——解决办法
当打开这些应用程序时,系统提示无法打开" XXX",因为它来自身份不明的开发者.我们可以按照下面的方法解决. 教程 1.打开应用程序,找到你要打开的软件.按住control键,点击 ...
- Dynamics CRM存放选项集记录的表
我们在做一些自定义查询的时候会去查询选项集字段的值,但是实体的选项集字段是一个整型字段,直接查询并不能找到对应的选项集的显示内容.所以我们需要找到存放选项集键值对的表来做关联查询找到我们想要的值. D ...
- BUAA_OO_第四单元
一.UML解析器设计 先看下题目:第四单元实现一个基于JDK 8带有效性检查的UML(Unified Modeling Language)类图,顺序图,状态图分析器 MyUmlInteractio ...
- 剑指offer--孩子们的游戏(圆圈中最后剩下的数字)
每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈.然后,他随机指定一个数m ...
- [C++]一篇文章搞懂C++中五花八门的各种初始化
总结 初始化的概念:创建变量时赋予它一个值(不同于赋值的概念) 类的构造函数控制其对象的初始化过程,无论何时只要类的对象被创建就会执行构造函数 如果对象未被用户指定初始值,那么这些变量会被执行默认初始 ...
- 02 . MongoDB复制集,分片集,备份与恢复
复制集 MongoDB复制集RS(ReplicationSet): 基本构成是1主2从的结构,自带互相监控投票机制(Raft(MongoDB)Paxos(mysql MGR 用的是变种)) 如果发生主 ...
- 【Redis破障之路】三:Redis单线程架构
众所周知,Redis是一个单线程架构的NoSQL数据库,但是是单线程模型的Redis为什么性能如此之高?这就是我们接下来要探究学习的内容. 1.Redis的单线程架构 1.1.Redis单线程简介 首 ...
- 这一篇文章帮你搞定Java(含Java全套资源)
当下想学习Java开发的人越来越多,对于很多零基础的人来说,没有相关的视频教程及相关的学习线路,学起来是一件很费劲的事情,还有很多人从网上及其它渠道购买视频,这些视频资料的价格对于刚毕业的大学生来说也 ...
- CVPR2021 | 华为诺亚实验室提出Transformer in Transformer
前言: transformer用于图像方面的应用逐渐多了起来,其主要做法是将图像进行分块,形成块序列,简单地将块直接丢进transformer中.然而这样的做法忽略了块之间的内在结构信息,为此,这篇论 ...