深入理解JVM(二)垃圾收集器
GC三问:
哪些内存需要回收?
什么时候回收?
如何回收?
程序计数器、虚拟机栈、本地方法栈随线程而生,随线程而灭,栈帧的内存分配在类结构确定下来就已知,在方法结束或者线程结束时就会回收。所以垃圾回收关注的是动态的堆内存。
ps. 方法区也能被回收,主要回收废弃常量和无用类,但性价比高,不过多描述。
1.哪些内存需要回收
这个问题的关键就是确定哪些内存是存活着,哪些内存死去(不再会被用到的)
引用计数算法
有引用时就+1,引用失效就-1,计数器为0则可回收
无法回收相互引用的情况
引用分为强引用、软引用、弱引用、虚引用,引用强度递减
强引用
普遍存在的,Object obj = new Object()
只要强引用存在,垃圾收集器永远不会回收掉被引用的对象
软引用
对象在有用但非必须
内存不足时才会回收
实现高速缓存
String str = new String("abc");
SoftReference<String> softRef = new SoftReference<String>(str);
弱引用
非必须,比软引用弱
GC时会被回收(概率不大,优先级低)
适用于偶尔被使用不影响垃圾收集的对象
String str = new String("abc");
WeakReference<String> weakRef = new WeakReference<String>(str);
虚引用
不决定对象生命周期
任何时候可回收
跟踪对象被垃圾收集器回收的活动
必须和引用队列ReferenceQueue联合使用
String str = new String("abc");
ReferenceQueue queue = new ReferenceQueue();
PhantomReference<String> phantomRef = new PhantomReference<String>(str,queue);
可达性分析
从GC Roots作为起始点向下,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链则为不可达,判定为可回收对象。
什么对象可以作为GC Roots
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区的类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中native方法引用的对象
要判定一个对象的死亡,需要经过两次标记:第一次未与GC Roots相连的节点会经过第一次标记并进行一次筛选。筛选的条件是此对象是否有必要执行finalize()方法(对象没有覆盖finalize()或者finalize()已经被调用过则为没有必要执行)。经过第一次标记后的对象会被放入F-Queue的队列中,由虚拟机自动创建、优先级低的Finalizer线程去执行他。对象可以在finalize()方法中实现自救,如果自救成功会被移出队列,不再回收。
算法实现
GC进行时必须停顿所有Java执行线程,用于枚举根节点,称之为Stop-the-World,减少STW的次数来优化GC。
但程序并非在所有位置都能停顿下来,需要到达SafePoint才能暂停,这种中断方案有两种,抢先式中断和主动式中断。
抢先式中断
中断所有线程,如果线程中断的地方不在SafePoint,恢复线程让他跑到安全点。目前几乎不用
主动式中断
设置一个标志,线程主动轮询这个标志,如果发现需要中断就中断。另外轮询的位置和SafePoint是重合的,也就是在每个安全点会轮询判断是否需要中断。
2.内存分配和回收策略
对象优先在Eden分配
- 【Eden区】 空间不足时触发minor GC
- 【Survivor区from】 第一次minor GC 从Eden区复制到from 年龄+1
- 【Survivor区to】 第二次 minor GC 对Eden和from拷贝到to 年龄+1 from 和to互换 清空from和eden
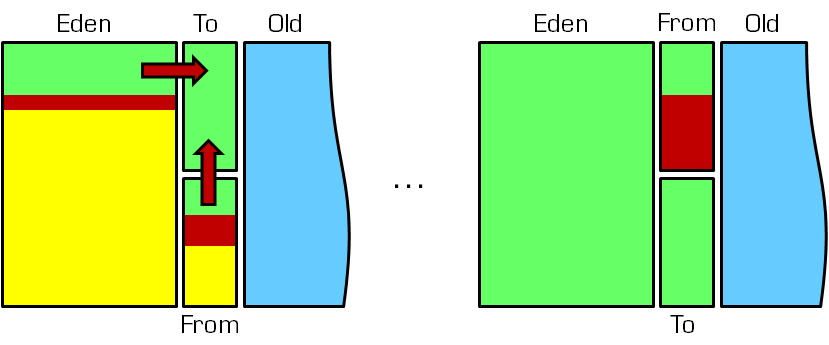
在GC开始的时候,对象只会存在于Eden区和From区,To区是空的。紧接着进行GC,Eden区中所有存活的对象都会被复制到To,而在From区中,仍存活的对象会根据他们的年龄值来决定去向。年龄达到一定值(年龄阈值,可以通过-XX:MaxTenuringThreshold来设置)的对象会被移动到年老代中,没有达到阈值的对象会被复制到To区域。经过这次GC后,Eden区和From区已经被清空。这个时候,“From”和“To”会交换他们的角色,也就是新的To就是上次GC前的From,新的From就是上次GC前的To。不管怎样,都会保证名为To的Survivor区域是空的。Minor GC会一直重复这样的过程,直到To区被填满,To区被填满之后,会将所有对象移动到年老代中。
-Xmn10M分配给新生代的内存-XX:SurvivorRatio=8指定新生代Eden区和Survivor区的空间比例。大对象直接进入老年代
可以通过设置
-XX:PretenureSizeThreShold,大于这个值的对象直接进入老年代长期存活的对象进入老年代
Full GC触发条件
- 老年代空间不足
- 永久代空间不足(JDK7前)
- CMS GC(Concurrent Mark Sweep 并发标记清理) 出现promotion failed concurrent mode failure
- promotion failed 年轻代和老年代都放不下
- 同时有对象要放入老年代,老年代空间不足
- minor GC晋升到老年代平均大小大于老年代剩余空间
- System.gc()
- 使用RMI进行RPC或管理 JDK,一小时一次
3.垃圾回收算法
标记-清除算法(Mark-Sweep)
标记:从根集合扫描,对存活对象标记
清除:对堆内存从头到尾进行线性遍历,回收不可达对象内存
缺点:
- 效率低:标记和清除两个过程小徐都不高
- 碎片化:会产生大量不连续的内存碎片,在分配大对象时可能需要提前触发垃圾回收动作
复制算法(Copying)
分为对象面和空闲面,对象在对象面上创建
清理时存活的对象被从对象面复制到空闲面,再将对象面所有对象内存清除
优点:
- 解决碎片化问题
- 顺序分配内存,简单高效
- 适用于对象存活率低的场景(新生代回收)
缺点:
- 造成内存的缩小,可用内存减少
标记-整理算法
标记:从根集合扫描,对存活对象标记
清除:移动所有存活对象,按照内存地址排序,然后将末端内存地址以后内存全部回收
缺点:
- 成本高,适用于存活率高的场景
分代收集算法
把堆分成几代,,根据代的特点采用合适的垃圾回收算法
4.垃圾收集器
- JVM运行模式
JVM有两种运行模式Server与Client。两种模式的区别在于,Client模式启动速度较快,Server模式启动较慢;但是启动进入稳定期长期运行之后Server模式的程序运行速度比Client要快很多。这是因为Server模式启动的JVM采用的是重量级的虚拟机,对程序采用了更多的优化;而Client模式启动的JVM采用的是轻量级的虚拟机。所以Server启动慢,但稳定后速度比Client远远要快。
~ $ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
以上命令可以看到当前使用的是什么模式的JVM
以下是新生代收集器
- 垃圾收集器的联系
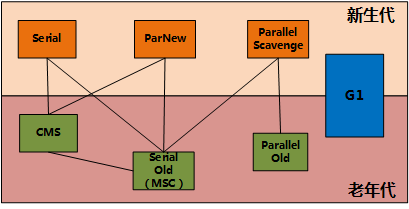
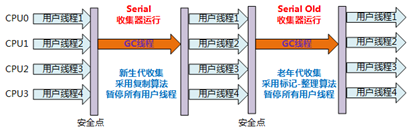
Serial收集器 -XX:+UseSerialGC 复制算法
- 单线程收集
- 简单高效,client模式默认
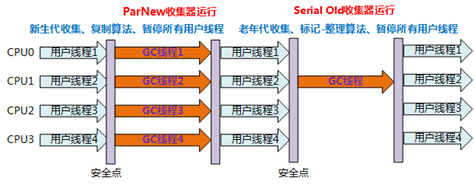
ParNew收集器 -XX:+UseParNewGC 复制算法
- 多线程收集
- 单核不如Serial 多核有优势
Parallel Scavenge收集器 -XX:+UseParallelGC 复制
- 吞吐量=(运行用户代码时间/运行用户代码时间+垃圾收集时间)
- 关注吞吐量
- 多核执行有优势 server默认
- -XX:+UseAdaptiveSizePolicy
以下都是老年代的收集器
Serial Old收集器 -XX:+UseSerialOldGC 标记整理算法
- Client 默认
Parallel Old收集器 标记整理
- 多线程,吞吐量优先
CMS 收集器 -XX:+UseConcMarkSweepGc 标记清除算法
以获取最短停顿时间为目标。
- 步骤
- stop-the-world,初始标记
- 并发标记:并发追溯标记(与用户线程并发)
- 并发预清理,查找并发标记阶段从年轻代晋升到老年代对象
- 重新标记:stop-the-world 扫描CMS剩余对象
- 并发清理:清理垃圾对象,程序不会停顿(与用户线程并发)
- 并发重置:重置CMS数据接口
- 碎片化(标记-清理算法导致)
- 影响用户程序
- 无法处理浮动垃圾
Garbage First收集器 -XX:+UseG1GC 复制+标记整理
- 并行和并发 多CPU
- 分代收集
- 空间整合(整体是标记-整理,局部Region是复制),不会有内存碎片
- 可预测的停顿
- 将整个java堆内存划分成多个大小相等的Region
- 年轻代和老年代不再物理隔离
附录
JVM参数速查
| 参数 | 描述 |
|---|---|
| -XX:+PrintGCDetail | 在垃圾回收时打印内存回收日志 |
| -Xms20M | |
| -Xmx20M | |
| -Xmn10M | 指定新生代的堆大小 |
| -XX:SurvivorRatio=8 | 指定新生代Eden区和Survivor区的空间比例,默认为8 |
| -XX:MaxTenuringThreshold | 到达这个年龄成为老年代 |
| -XX:+PretenuerSizeThreshold | (survivor区装不下的、新生成的大对象)也会到老年代 |
| -XX:NewRatio | 老年代和年轻代内存比例大小 |
| -XX:ParallelGCThreads | 限制垃圾收集线程数 |
| -XX:MaxGCPauseMills | 控制最大垃圾收集停顿时间(Parallel Scavenge收集器) |
| -XX:GCTimeRatio | 设置吞吐量大小(Parallel Scavenge收集器) |
| -XX:+UseAdaptiveSizePolicy | 不需要指定新生代大小,Eden和survivor比例 GC自适应(Parallel Scavenge收集器) |
深入理解JVM(二)垃圾收集器的更多相关文章
- 理解JVM之垃圾收集器详解
前言 垃圾收集器作为内存回收的具体表现,Java虚拟机规范并未对垃圾收集器的实现做规定,因而不同版本的虚拟机有很大区别,因而我们在这里主要讨论基于Sun HotSpot虚拟机1.6版本Update22 ...
- 理解JVM之垃圾收集器概述
前言 很多人将垃圾收集(Garbage Collection)视为Java的伴生产物,实际1960年诞生的Lisp是第一门真正使用内存动态分配与垃圾手机技术的语言.在目前看来,内存的动态分配与内存回收 ...
- 深入理解JVM : Java垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现. Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商.不同版本的虚拟机所提供的垃圾收集器都可能会有很大差 ...
- 深入理解JVM:垃圾收集器与内存分配策略
堆里面存放着Java世界差点儿全部的对象实例,垃圾收集器在对堆进行回收前.第一件事情就是要确定这些对象之中哪些还存活,哪些已经死去.推断对象的生命周期是否结束有下面几种方法 引用计数法 详细操作是给对 ...
- 深入理解JVM(二)--垃圾收集算法
一. 概述 说起垃圾收集(Garbage Collection, GC), 大部分人都把这项技术当做Java语言的伴随生产物. 事实上, GC的历史远远比Java久远, 1960年 诞生于MIT的Li ...
- 深入理解JVM(三)垃圾收集器和内存分配策略
3.1 关于垃圾收集和内存分配 垃圾收集和内存分配主要针对的区域是Java虚拟机中的堆和方法区: 3.2 如何判断对象是否“存活”(存活判定算法) 垃圾收集器在回收对象前判断其是否“存活”的两个算法: ...
- [转] 深入理解Java G1垃圾收集器
[From] https://www.cnblogs.com/ASPNET2008/p/6496481.html 深入理解Java G1垃圾收集器 本文首先简单介绍了垃圾收集的常见方式,然后再分析了G ...
- 【深入理解JVM】类加载器与双亲委派模型 (转)
出处: [深入理解JVM]类加载器与双亲委派模型 加载类的开放性 类加载器(ClassLoader)是Java语言的一项创新,也是Java流行的一个重要原因.在类加载的第一阶段“加载”过程中,需要通过 ...
- 垃圾收集器与内存分配策略 (深入理解JVM二)
1.概述 垃圾收集(Garbage Collection,GC). 当需要排查各种内存溢出.内存泄露问题时,当垃圾收集成为系统达到更高并发量的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调 ...
- jvm系列 (二) ---垃圾收集器与内存分配策略
垃圾收集器与内存分配策略 前言:本文基于<深入java虚拟机>再加上个人的理解以及其他相关资料,对内容进行整理浓缩总结.本文中的图来自网络,感谢图的作者.如果有不正确的地方,欢迎指出. 目 ...
随机推荐
- MyBatis学习笔记(2)--缓存
一.什么是缓存 --存在于内存中的临时数据. 为什么使用缓存?--减少和数据库的交互次数,提高执行效率. 适用于缓存的数据: 1.经常查询并且不经常改变的数据. 2.数据的正确与否对最终结果影响较小的 ...
- 一条update SQL语句是如何执行的
一条更新语句的执行过程和查询语句类似,更新的流程涉及两个日志:redo log(重做日志)和binlog(归档日志).比如我们要将ID(主键)=2这一行的值加(c:字段)1,SQL语句如下: upda ...
- Laravel 中自定义 手机号和身份证号验证
首先在 Providers\AppServiceProvider.php 文件中自定义 手机号和身份证号验证 // AppServiceProvider.php 文件 <?php namespa ...
- Docker(五)Docker镜像讲解
Docker镜像讲解 镜像概念 镜像是一种轻量级.可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码.运行时.库.环境变量和配置文件 Dock ...
- 入门大数据---Python基础
前言 由于AI的发展,包括Python集成了很多计算库,所以淡入了人们的视野,成为一个极力追捧的语言. 首先概括下Python中文含义是蟒蛇,它是一个胶水语言和一个脚本语言,胶水的意思是能和多种语言集 ...
- 入门大数据---Kylin搭建与应用
由于Kylin官网已经是中文的了,而且写的很详细,这里就不再重述. 学习右转即可. 这里说个遇到的问题,当在Kylin使用SQL关键字时,要加上双引号,并且里面的内容要大写,这个和MySql有点区别需 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 宝贝,来,满足你,二哥告诉你学 Java 应该买什么书?
(这次的标题是不是有点皮,对模仿好朋友 guide 哥的,我也要皮一皮) 高尔基说过,对吧?宝贝们,"书籍是人类进步的阶梯",不管学什么,买几本心仪的书读一读,帮助还是非常大的.尽 ...
- caffe的python接口学习(2)生成solver文件
caffe在训练的时候,需要一些参数设置,我们一般将这些参数设置在一个叫solver.prototxt的文件里面 有一些参数需要计算的,也不是乱设置. 假设我们有50000个训练样本,batch_si ...
- WTL中GDI+支持资源文件加载
WTL中GDI+支持资源文件加载 分类: WTL WTL gdi+ gdi+2013-04-22 17:16 78人阅读 评论(0) 收藏 举报 WTLGDI+c++ 今天遇到一个小问题困扰了.就是G ...