transformer多头注意力的不同框架实现(tensorflow+pytorch)
多头注意力可以用以下一张图描述:
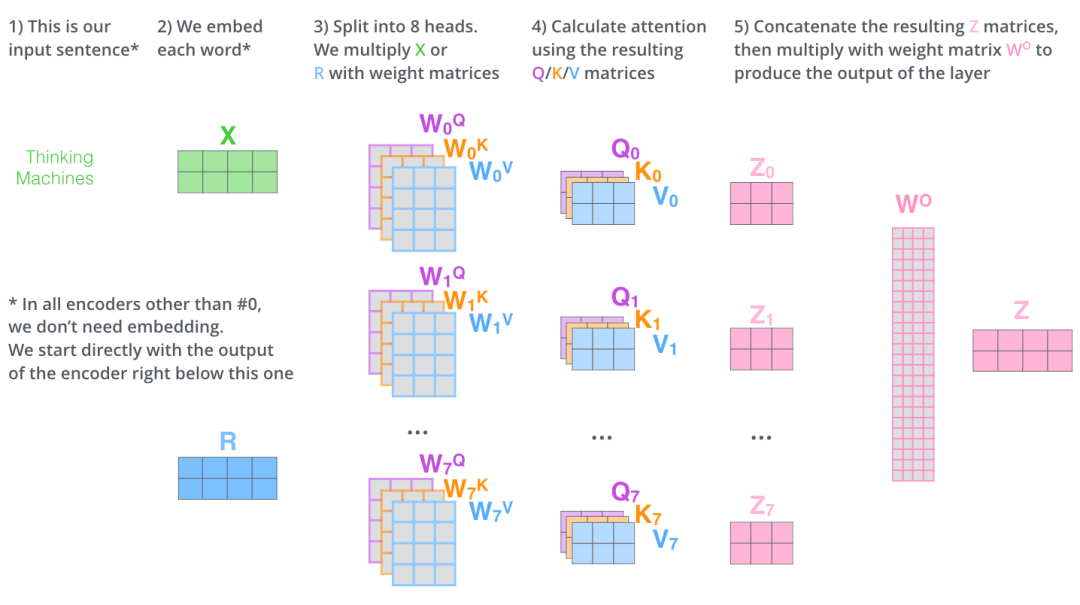
1、使用pytorch自带的库的实现
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
参数说明如下:
embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
num_heads:设置多头注意力的数量。如果设置为 1,那么只使用一组注意力。如果设置为其他数值,那么 num_heads 的值需要能够被 embed_dim 整除
dropout:这个 dropout 加在 attention score 后面
现在来解释一下,为什么 num_heads 的值需要能够被 embed_dim 整除。这是为了把词的隐向量长度平分到每一组,这样多组注意力也能够放到一个矩阵里,从而并行计算多头注意力。
定义 MultiheadAttention 的对象后,调用时传入的参数如下。
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
query:对应于 Key 矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
key_padding_mask:如果提供了这个参数,那么计算 attention score 时,忽略 Key 矩阵中某些 padding 元素,不参与计算 attention。形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度。
- 如果 key_padding_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 key_padding_mask 是 BoolTensor,那么 True 对应的位置会被忽略
attn_mask:计算输出时,忽略某些位置。形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
- 如果 attn_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 attn_mask 是 BoolTensor,那么 True 对应的位置会被忽略
需要注意的是:在实际中,K、V 矩阵的序列长度是一样的,而 Q 矩阵的序列长度可以不一样。
这种情况发生在:在解码器部分的Encoder-Decoder Attention层中,Q 矩阵是来自解码器下层,而 K、V 矩阵则是来自编码器的输出。
代码示例:
## nn.MultiheadAttention 输入第0维为length
# batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(12,64,300)
# batch_size 为 64,有 10 个词,每个词的 Key 向量是 300 维
key = torch.rand(10,64,300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value= torch.rand(10,64,300) embed_dim = 299
num_heads = 1
# 输出是 (attn_output, attn_output_weights)
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
attn_output = multihead_attn(query, key, value)[0]
# output: torch.Size([12, 64, 300])
# batch_size 为 64,有 12 个词,每个词的向量是 300 维
print(attn_output.shape)
2、手动实现计算多头注意力
在 PyTorch 提供的 MultiheadAttention 中,第 1 维是句子长度,第 2 维是 batch size。这里我们的代码实现中,第 1 维是 batch size,第 2 维是句子长度。代码里也包括:如何用矩阵实现多组注意力的并行计算。代码中已经有详细注释和说明。
class MultiheadAttention(nn.Module):
# n_heads:多头注意力的数量
# hid_dim:每个词输出的向量维度
def __init__(self, hid_dim, n_heads, dropout):
super(MultiheadAttention, self).__init__()
self.hid_dim = hid_dim
self.n_heads = n_heads # 强制 hid_dim 必须整除 h
assert hid_dim % n_heads == 0
# 定义 W_q 矩阵
self.w_q = nn.Linear(hid_dim, hid_dim)
# 定义 W_k 矩阵
self.w_k = nn.Linear(hid_dim, hid_dim)
# 定义 W_v 矩阵
self.w_v = nn.Linear(hid_dim, hid_dim)
self.fc = nn.Linear(hid_dim, hid_dim)
self.do = nn.Dropout(dropout)
# 缩放
self.scale = torch.sqrt(torch.FloatTensor([hid_dim // n_heads])) def forward(self, query, key, value, mask=None):
# K: [64,10,300], batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
# V: [64,10,300], batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
# Q: [64,12,300], batch_size 为 64,有 10 个词,每个词的 Query 向量是 300 维
bsz = query.shape[0]
Q = self.w_q(query)
K = self.w_k(key)
V = self.w_v(value)
# 这里把 K Q V 矩阵拆分为多组注意力,变成了一个 4 维的矩阵
# 最后一维就是是用 self.hid_dim // self.n_heads 来得到的,表示每组注意力的向量长度, 每个 head 的向量长度是:300/6=50
# 64 表示 batch size,6 表示有 6组注意力,10 表示有 10 词,50 表示每组注意力的词的向量长度
# K: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# V: [64,10,300] 拆分多组注意力 -> [64,10,6,50] 转置得到 -> [64,6,10,50]
# Q: [64,12,300] 拆分多组注意力 -> [64,12,6,50] 转置得到 -> [64,6,12,50]
# 转置是为了把注意力的数量 6 放到前面,把 10 和 50 放到后面,方便下面计算
Q = Q.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
K = K.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3)
V = V.view(bsz, -1, self.n_heads, self.hid_dim //
self.n_heads).permute(0, 2, 1, 3) # 第 1 步:Q 乘以 K的转置,除以scale
# [64,6,12,50] * [64,6,50,10] = [64,6,12,10]
# attention:[64,6,12,10]
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale # 把 mask 不为空,那么就把 mask 为 0 的位置的 attention 分数设置为 -1e10
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10) # 第 2 步:计算上一步结果的 softmax,再经过 dropout,得到 attention。
# 注意,这里是对最后一维做 softmax,也就是在输入序列的维度做 softmax
# attention: [64,6,12,10]
attention = self.do(torch.softmax(attention, dim=-1)) # 第三步,attention结果与V相乘,得到多头注意力的结果
# [64,6,12,10] * [64,6,10,50] = [64,6,12,50]
# x: [64,6,12,50]
x = torch.matmul(attention, V) # 因为 query 有 12 个词,所以把 12 放到前面,把 5 和 60 放到后面,方便下面拼接多组的结果
# x: [64,6,12,50] 转置-> [64,12,6,50]
x = x.permute(0, 2, 1, 3).contiguous()
# 这里的矩阵转换就是:把多组注意力的结果拼接起来
# 最终结果就是 [64,12,300]
# x: [64,12,6,50] -> [64,12,300]
x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))
x = self.fc(x)
return x # batch_size 为 64,有 12 个词,每个词的 Query 向量是 300 维
query = torch.rand(64, 12, 300)
# batch_size 为 64,有 12 个词,每个词的 Key 向量是 300 维
key = torch.rand(64, 10, 300)
# batch_size 为 64,有 10 个词,每个词的 Value 向量是 300 维
value = torch.rand(64, 10, 300)
attention = MultiheadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
## output: torch.Size([64, 12, 300])
print(output.shape)
3、tensorflow实现的多头注意力
def _multiheadAttention(rawKeys, queries, keys, numUnits=None, causality=False, scope="multiheadAttention"):
# rawKeys 的作用是为了计算mask时用的,因为keys是加上了position embedding的,其中不存在padding为0的值
# numUnits = 50 numHeads = 6
keepProb = 1 if numUnits is None: # 若是没传入值,直接去输入数据的最后一维,即embedding size.
numUnits = queries.get_shape().as_list()[-1] #300 # tf.layers.dense可以做多维tensor数据的非线性映射,在计算self-Attention时,一定要对这三个值进行非线性映射,
# 其实这一步就是论文中Multi-Head Attention中的对分割后的数据进行权重映射的步骤,我们在这里先映射后分割,原则上是一样的。
# Q, K, V的维度都是[batch_size, sequence_length, embedding_size]
Q = tf.layers.dense(queries, numUnits, activation=tf.nn.relu) # [64,10,300]
K = tf.layers.dense(keys, numUnits, activation=tf.nn.relu) # [64,10,300]
V = tf.layers.dense(keys, numUnits, activation=tf.nn.relu) # [64,10,300] # 将数据按最后一维分割成num_heads个, 然后按照第一维拼接
# Q, K, V 的维度都是[batch_size * numHeads, sequence_length, embedding_size/numHeads]
Q_ = tf.concat(tf.split(Q, numHeads, axis=-1), axis=0) # [64*6,10,50]
K_ = tf.concat(tf.split(K, numHeads, axis=-1), axis=0) # [64*6,10,50]
V_ = tf.concat(tf.split(V, numHeads, axis=-1), axis=0) # [64*6,10,50] # 计算keys和queries之间的点积,维度[batch_size * numHeads, queries_len, key_len], 后两维是queries和keys的序列长度
similary = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # [64*6,10,10] # 对计算的点积进行缩放处理,除以向量长度的根号值
scaledSimilary = similary / (K_.get_shape().as_list()[-1] ** 0.5) # [64*6,10,10] # 在我们输入的序列中会存在padding这个样的填充词,这种词应该对最终的结果是毫无帮助的,原则上说当padding都是输入0时,
# 计算出来的权重应该也是0,但是在transformer中引入了位置向量,当和位置向量相加之后,其值就不为0了,因此在添加位置向量
# 之前,我们需要将其mask为0。虽然在queries中也存在这样的填充词,但原则上模型的结果之和输入有关,而且在self-Attention中
# queryies = keys,因此只要一方为0,计算出的权重就为0。
# 具体关于key mask的介绍可以看看这里: https://github.com/Kyubyong/transformer/issues/3 # 利用tf,tile进行张量扩张, 维度[batch_size * numHeads, keys_len] keys_len = keys 的序列长度 # 将每一时序上的向量中的值相加取平均值
# rawkKeys:[64,10,300]
keyMasks = tf.sign(tf.abs(tf.reduce_sum(rawKeys, axis=-1))) # 维度[batch_size, time_step] [64,10]
#tf.sign()是将<0的值变为-1,大于0的值变为1,等于0的值变为0
keyMasks = tf.tile(keyMasks, [numHeads, 1]) # [64*6,10]
# 上面这两句的意思是找出padding的位置 # 增加一个维度,并进行扩张,得到维度[batch_size * numHeads, queries_len, keys_len]
keyMasks = tf.tile(tf.expand_dims(keyMasks, 1), [1, tf.shape(queries)[1], 1]) # [64*6,10,10] 10个为1组
print(keyMasks.shape)
# tf.ones_like生成元素全为1,维度和scaledSimilary相同的tensor, 然后得到负无穷大的值
paddings = tf.ones_like(scaledSimilary) * (-2 ** (32 + 1)) [64*6,10,10] # tf.where(condition, x, y),condition中的元素为bool值,其中对应的True用x中的元素替换,对应的False用y中的元素替换
# 因此condition,x,y的维度是一样的。下面就是keyMasks中的值为0就用paddings中的值替换
maskedSimilary = tf.where(tf.equal(keyMasks, 0), paddings, scaledSimilary) # 维度[batch_size * numHeads, queries_len, key_len] # 在计算当前的词时,只考虑上文,不考虑下文,出现在Transformer Decoder中。在文本分类时,可以只用Transformer Encoder。
# Decoder是生成模型,主要用在语言生成中
if causality:
diagVals = tf.ones_like(maskedSimilary[0, :, :]) # [queries_len, keys_len]
tril = tf.contrib.linalg.LinearOperatorTriL(diagVals).to_dense() # [queries_len, keys_len]
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(maskedSimilary)[0], 1, 1]) # [batch_size * numHeads, queries_len, keys_len] paddings = tf.ones_like(masks) * (-2 ** (32 + 1))
maskedSimilary = tf.where(tf.equal(masks, 0), paddings, maskedSimilary) # [batch_size * numHeads, queries_len, keys_len] # 通过softmax计算权重系数,维度 [batch_size * numHeads, queries_len, keys_len]
weights = tf.nn.softmax(maskedSimilary) # 加权和得到输出值, 维度[batch_size * numHeads, sequence_length, embedding_size/numHeads]
outputs = tf.matmul(weights, V_) # 将多头Attention计算的得到的输出重组成最初的维度[batch_size, sequence_length, embedding_size]
outputs = tf.concat(tf.split(outputs, numHeads, axis=0), axis=2) outputs = tf.nn.dropout(outputs, keep_prob=keepProb) # 对每个subLayers建立残差连接,即H(x) = F(x) + x
outputs += queries
# normalization 层
#outputs = self._layerNormalization(outputs)
return outputs
输入是:self.embeddedWords = self.wordEmbedded + self.positionEmbedded,即词嵌入+位置嵌入
还是以pytorch的输入的维度为例:self.wordEmbedded的维度[64,10,300] self.positionEmbedded的维度是[64,10,300]
使用的时候是:
multiHeadAtt = self._multiheadAttention(rawKeys=self.wordEmbedded, queries=self.embeddedWords,
keys=self.embeddedWords)
例如:(这里简化了一下输入)
wordEmbedded = tf.Variable(np.ones((64,10,300)))
positionEmbedded = tf.Variable(np.ones((64,10,300)))
embeddedWords = wordEmbedded + positionEmbedded
multiHeadAtt = _multiheadAttention(rawKeys=wordEmbedded, queries=embeddedWords, keys=embeddedWords, numUnits=300)
需要注意的是,rawkeys是针对于词嵌入而言,因为加上了位置嵌入之后的embeddedWords的mask被位置嵌入盖住了,就找不到需要mask的位置了。
上述pytorch的示例实际上对应的是if causality下面的代码,因为在编码阶段:Q=K=V(它们之间的维度是相同的),在解码阶段,Q来自于解码阶段的输入,即可以是[64,12,300],而K和V来自编码器的输出,形状都是[64,10,300]。也就是Encoder-Decoder Attention。而当QKV都来自同一个输入的时候,也就是self attention。
参考:https://mp.weixin.qq.com/s/cJqhESxTMy5cfj0EXh9s4w
transformer多头注意力的不同框架实现(tensorflow+pytorch)的更多相关文章
- 对比深度学习十大框架:TensorFlow 并非最好?
http://www.oschina.net/news/80593/deep-learning-frameworks-a-review-before-finishing-2016 TensorFlow ...
- 作为深度学习最强框架的TensorFlow如何进行时序预测!(转)
作为深度学习最强框架的TensorFlow如何进行时序预测! BigQuant 2 个月前 摘要: 2017年深度学习框架关注度排名tensorflow以绝对的优势占领榜首,本文通过一个小例子介绍了T ...
- tensorflow/pytorch/mxnet的pip安装,非源代码编译,基于cuda10/cudnn7.4.1/ubuntu18.04.md
os安装 目前对tensorflow和cuda支持最好的是ubuntu的18.04 ,16.04这种lts,推荐使用18.04版本.非lts的版本一般不推荐. Windows倒是也能用来装深度GPU环 ...
- 深度学习框架Keras与Pytorch对比
对于许多科学家.工程师和开发人员来说,TensorFlow是他们的第一个深度学习框架.TensorFlow 1.0于2017年2月发布,可以说,它对用户不太友好. 在过去的几年里,两个主要的深度学习库 ...
- Transformer 和 Transformer-XL——从基础框架理解BERT与XLNet
目录写在前面1. Transformer1.1 从哪里来?1.2 有什么不同?1.2.1 Scaled Dot-Product Attention1.2.2 Multi-Head Attention1 ...
- 深度学习框架比较TensorFlow、Theano、Caffe、SciKit-learn、Keras
TheanoTheano在深度学习框架中是祖师级的存在.Theano基于Python语言开发的,是一个擅长处理多维数组的库,这一点和numpy很像.当与其他深度学习库结合起来,它十分适合数据探索.它为 ...
- 05基于python玩转人工智能最火框架之TensorFlow基础知识
从helloworld开始 mkdir mooc # 新建一个mooc文件夹 cd mooc mkdir 1.helloworld # 新建一个helloworld文件夹 cd 1.helloworl ...
- 03基于python玩转人工智能最火框架之TensorFlow介绍
一句话介绍: Google开源的基于数据流图的科学计算库,适用于机器学习 不局限于机器学习,但目前被大多用于机器学习等. TensorFlow计算流图的概念图 Tensor在图中流动. TensorF ...
- 深度学习框架之TensorFlow的概念及安装(ubuntu下基于pip的安装,IDE为Pycharm)
2015年11月9日,Google发布人工智能系统TensorFlow并宣布开源. 1.TensorFlow的概念 TensorFlow 是使用数据流图进行数值计算的开源软件库.也就是说,Tensor ...
随机推荐
- selenium登录163邮箱,得到cookie,requests后续请求
1.场景 很多时候登录操作是比较复杂的,因为存在各种反爆破操作,以及为了安全性提交数据都会存在加密.如果要完全模拟代码去实现登录操作是比较复杂,并且该网站后续更新了登录安全相关功能,那么登录的模拟操作 ...
- docker registry 记录
部署 运行下面命令获取registry镜像 docker pull registry 下载到的版本默认为 docker.io/registry latest 将registry镜像运行并生成一个容器 ...
- Get提交方式中文乱码
Get提交方式中文乱码 今天在servlet使用中,在Get方法中获取提交的中文参数,发现是乱码,我用的是Tomcat7. 在Tomcat9中: get方式的参数是放在请求头中,而Tomcat9对请求 ...
- 谈谈FTP
一.关于FTP 1.FTP是什么? FTP,全称"文件传输协议".属于TCP/IP四层模型中的应用层. 2.TCP/IP五层模型有哪些? 如图所示: 用文字叙述(从高层到底层): ...
- APP脱壳方法三
第一步 手机启动frida服务 第二步 手机打开要脱壳的app 第三步编辑hook代码 agent.js /* * Author: hluwa <hluwa888@gmail.com> * ...
- MySQL设置慢查询
MySQL的慢查询日志是用来记录在MySQL中响应时间超过阀值的语句,则会被记录到慢查询日志中(运行时间超过long_query_time值的SQL语句): 慢查询相关参数: slow_query ...
- 构造函数原理 - Js对象
构造函数内部原理 有new之后,函数变成构造函数,产生三步隐式变化 1.函数执行,在函数体顶端隐式加上var this = {}; 2.执行赋值,AO{ this : {name:'zhangsan' ...
- 函数-深入JS笔记
代码特点:高内聚,低耦合 耦合 存在执行多个相同作用代码时,这就叫耦合 if (1 > 0) { console.log('a'); } if (2 > 0) { console.log( ...
- 有关hashMap跟hashTable的区别
HashMap和Hashtable都实现了Map接口 HashMap是非synchronized,而Hashtable是synchronized HashTable使用Enumeration,Hash ...
- cp: cannot stat: filepath Permission denied
在执行 cp -r frompath topath时,报错cp: cannot stat: frompath Permission denied. 百度,google都没有找到解决方案,无意中发现,原 ...