分布式消息系统之Kafka集群部署
一、kafka简介
kafka是基于发布/订阅模式的一个分布式消息队列系统,用java语言研发,是ASF旗下的一个开源项目;类似的消息队列服务还有rabbitmq、activemq、zeromq;kafka最主要的优势具备分布式功能,并且结合zookeeper可以实现动态扩容;kafka对消息保存是通过Topic进行分类,发送消息一方称为producer(生产者),接收消息一方称为consumer(消费者);一个kafka集群有多个kafka server组成,我们把每个kafka server称为broker(消息掮客);
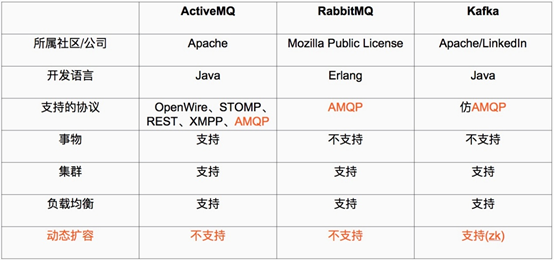
ActiveMQ、RabbitMQ、kafka对比
二、kafka集群部署
环境说明
| 主机名 | ip地址 |
| node04 | 192.168.0.44 |
| node05 | 192.168.0.45 |
| node06 | 192.168.0.46 |
提示:在部署kafka集群之前,我们要先把zk集群部署起来,因为kafka是强依赖zk集群;zk集群部署请参考上一篇博客https://www.cnblogs.com/qiuhom-1874/p/13841371.html;上面3台server只是kafka集群的三台server;
1、安装jdk
[root@node04 ~]# yum install -y java-1.8.0-openjdk-devel
验证java环境
[root@node04 ~]# java -version
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)
[root@node04 ~]#
提示:以上安装Java环境,在kafka集群的每个server都要做一遍;除了上面的java环境,还有基础环境像时间同步,主机名解析,关闭selinux,关闭防火墙,主机免密这些都要提前做好;
2、下载kafka二进制压缩包
[root@node04 ~]# ll
total 0
[root@node04 ~]# wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
--2020-10-21 20:06:28-- https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.6.0/kafka_2.12-2.6.0.tgz
Resolving mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)... 101.6.8.193, 2402:f000:1:408:8100::1
Connecting to mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)|101.6.8.193|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 65671917 (63M) [application/octet-stream]
Saving to: ‘kafka_2.12-2.6.0.tgz’ 100%[================================================================================>] 65,671,917 6.38MB/s in 13s 2020-10-21 20:06:41 (4.96 MB/s) - ‘kafka_2.12-2.6.0.tgz’ saved [65671917/65671917] [root@node04 ~]# ll
total 64136
-rw-r--r-- 1 root root 65671917 Aug 5 06:01 kafka_2.12-2.6.0.tgz
[root@node04 ~]#
3、解压二进制包,并做软连接
[root@node04 ~]# tar xf kafka_2.12-2.6.0.tgz -C /usr/local/
[root@node04 ~]# ln -sv /usr/local/kafka_2.12-2.6.0 /usr/local/kafka
‘/usr/local/kafka’ -> ‘/usr/local/kafka_2.12-2.6.0’
[root@node04 ~]#
提示:其他server也是相同的操作;
4、配置node04上的kafka
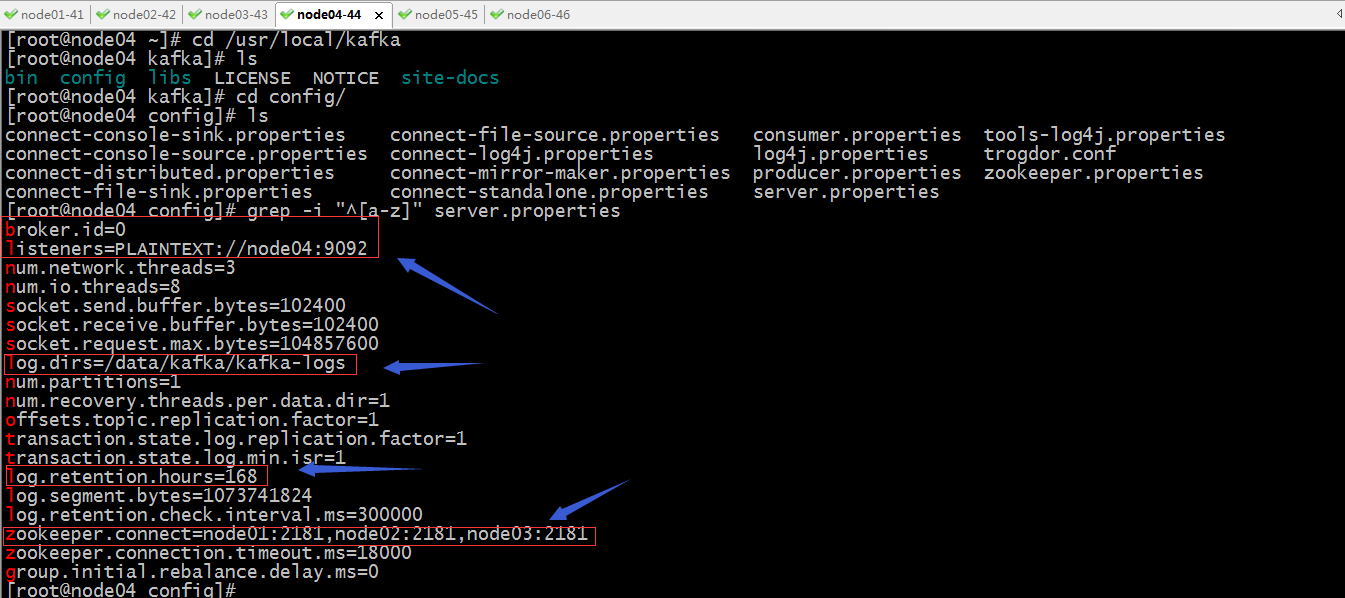
提示:broker.id是配置broker的id,这个id在kafka集群中必须唯一;listeners是用来指定当前节点监听的socket;log.dirs用来指定kafka的日志文件路径;log.retention.hours用来指定保存多少小时的日志;zookeeper.conect用来指定zk集群各节点信息,通常是把zk所有节点都写上,用逗号隔开;其他的参数都可以不用变;我这里用到主机名,是因为我在hosts文件对所有节点都做了主机名解析;
创建日志目录
[root@node04 config]# mkdir -pv /data/kafka
mkdir: created directory ‘/data’
mkdir: created directory ‘/data/kafka’
[root@node04 config]#
提示:后面的kafka-logs目录在kafka启动时会自动创建;到此node04就配置好了;
把node04上的配置文件拷贝到node05
[root@node04 config]# scp server.properties node05:/usr/local/kafka/config/
server.properties 100% 6882 2.0MB/s 00:00
[root@node04 config]#
修改broker.id和listeners配置
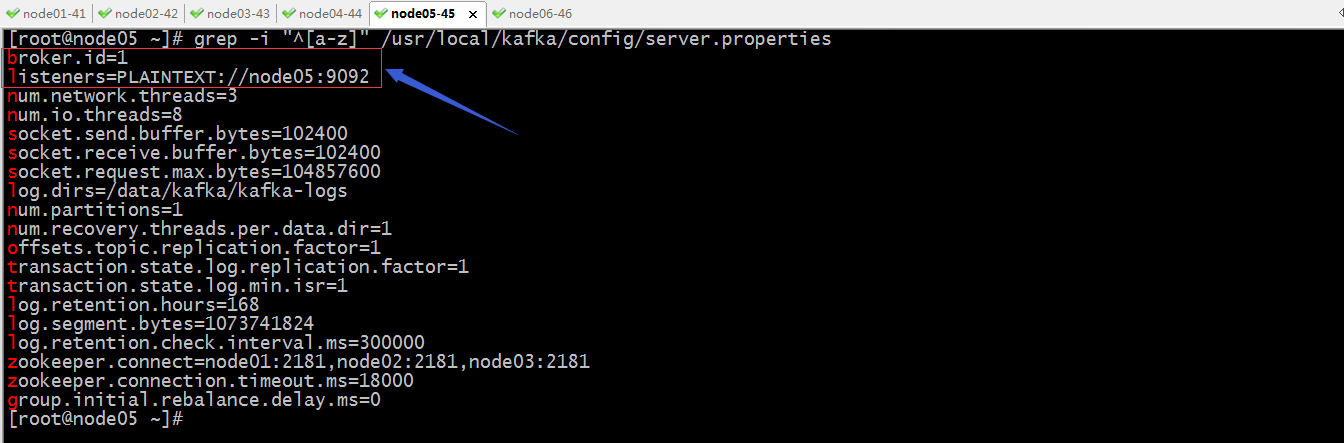
创建日志目录
[root@node05 ~]# mkdir -pv /data/kafka
mkdir: created directory ‘/data’
mkdir: created directory ‘/data/kafka’
[root@node05 ~]#
把node05的配置文件,复制到node06的kafka配置文件目录
[root@node05 ~]# scp /usr/local/kafka/config/server.properties node06:/usr/local/kafka/config/server.properties
The authenticity of host 'node06 (192.168.0.46)' can't be established.
ECDSA key fingerprint is SHA256:lE8/Vyni4z8hsXaa8OMMlDpu3yOIRh6dLcIr+oE57oE.
ECDSA key fingerprint is MD5:14:59:02:30:c0:16:b8:6c:1a:84:c3:0f:a7:ac:67:b3.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'node06,192.168.0.46' (ECDSA) to the list of known hosts.
server.properties 100% 6882 1.9MB/s 00:00
[root@node05 ~]#
修改broker.id和listeners配置,并创建日志目录
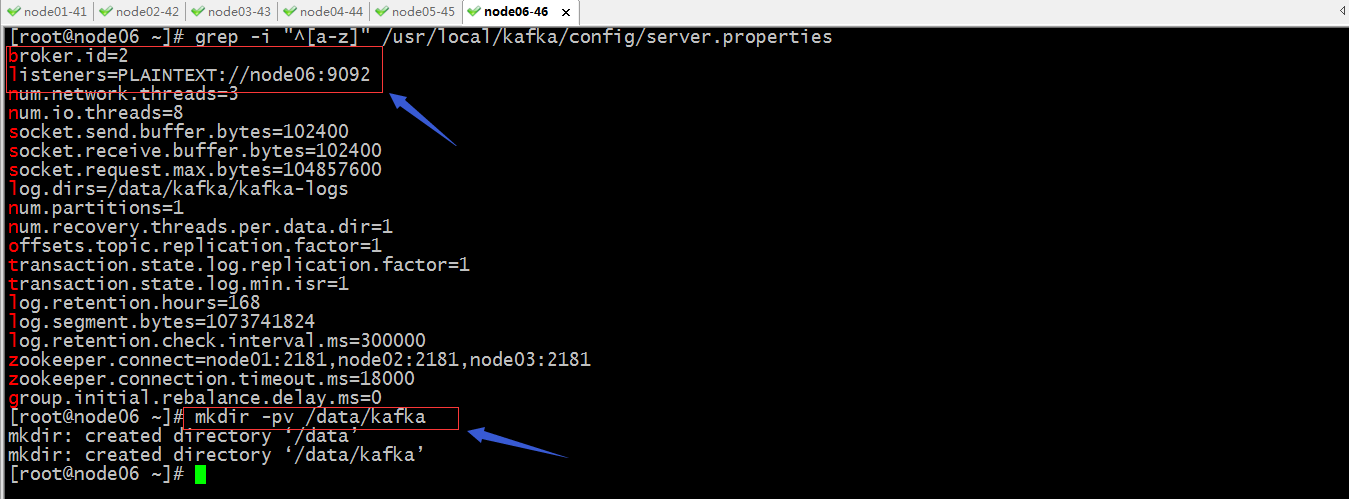
到此,三个节点的kafka就配置好了;
启动各节点上的kafka
[root@node04 config]# /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
[root@node04 config]# ss -tnl
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:22 *:*
LISTEN 0 100 127.0.0.1:25 *:*
LISTEN 0 128 :::22 :::*
LISTEN 0 100 ::1:25 :::*
LISTEN 0 50 :::39779 :::*
LISTEN 0 50 ::ffff:192.168.0.44:9092 :::*
[root@node04 config]#
提示:可以看到node04上的9092处于监听状态;用同样的命令把node05,node06上的kafka都启动起来;
查看日志

提示:kafka的启动日志放在安装目录下的logs目录,有个server.log;我们刚才创建的日志目录,主要用来保存集群事务的日志;
测试kafka
1、在各节点验证kafka进程是否启动
[root@node04 config]# jps
1797 Kafka
2485 Jps
[root@node04 config]# ssh node05 'jps'
1840 Jps
1772 Kafka
[root@node04 config]# ssh node06 'jps'
2321 Kafka
2388 Jps
[root@node04 config]#
2、在zk集群上查看,是否有kafka节点注册到上面
zk: localhost:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls -R /
/
/admin
/brokers
/cluster
/config
/consumers
/controller
/controller_epoch
/isr_change_notification
/latest_producer_id_block
/log_dir_event_notification
/zookeeper
/admin/delete_topics
/brokers/ids
/brokers/seqid
/brokers/topics
/brokers/ids/0
/brokers/ids/1
/brokers/ids/2
/cluster/id
/config/brokers
/config/changes
/config/clients
/config/topics
/config/users
/zookeeper/config
/zookeeper/quota
[zk: localhost:2181(CONNECTED) 2]
提示:可以看到在zk集群上多了很多节点;
3、创建名为test,partitions为3,replication为3的topic
[root@node04 config]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 3 --topic test
Created topic test.
[root@node04 config]#
在kafka集群的任意节获取topic
[root@node06 ~]# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper node01:2181,node01:2181,node03:2181 --topic test
Topic: test PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test Partition: 1 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
Topic: test Partition: 2 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
[root@node06 ~]#
提示:从上面的返回的状态信息可以看到test topic有三个分区分别为0、1、2,分区0的leader是2(broker.id),分区0有三个副本,并且状态都为lsr(ln-sync,表示可以参加选举成为leader)。
4、删除topic

6、创建topic,并发送消息
[root@node04 config]# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --partitions 3 --replication-factor 3 --topic msgtest
Created topic msgtest.
[root@node04 config]# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list node04:9092,node05:9092,node06:9092 --topic msgtest
>hello
>hi
>
在其他节点获取消息

使用图形工具kafka-tool工具获取消息
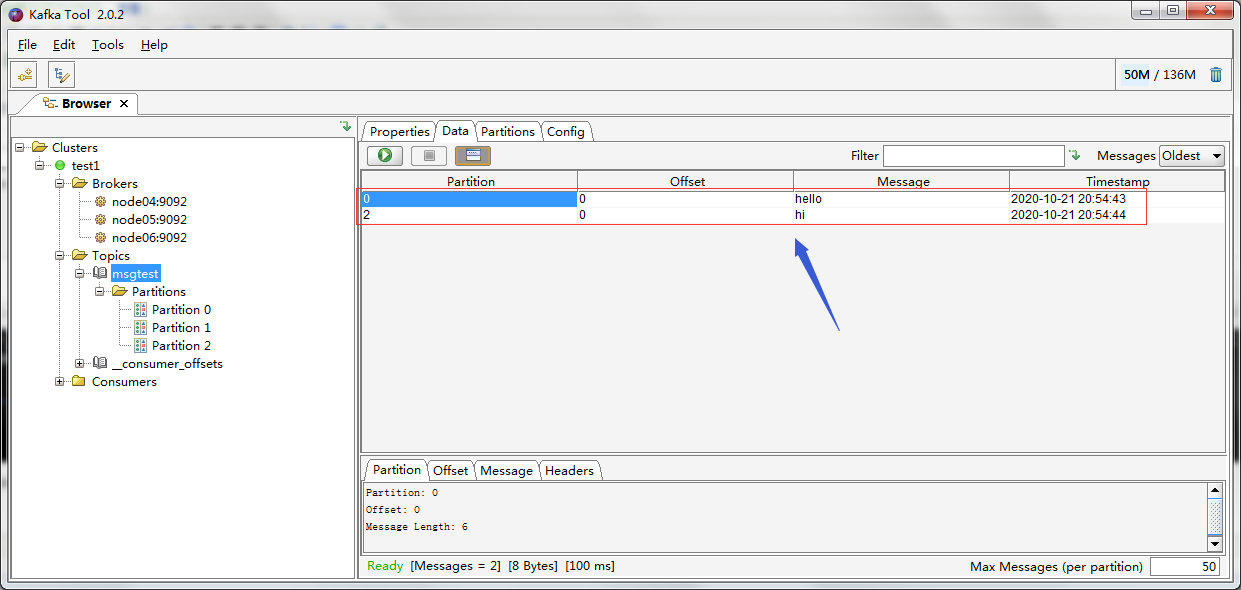
ok,到此kafka这个消息系统就搭建好了;
分布式消息系统之Kafka集群部署的更多相关文章
- zookeeper集群+kafka集群 部署
zookeeper集群 +kafka 集群部署 1.Zookeeper 概述: Zookeeper 定义 zookeeper是一个开源的分布式的,为分布式框架提供协调服务的Apache项目 Zooke ...
- Zookeeper+Kafka集群部署(转)
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Zookeeper+Kafka集群部署
Zookeeper+Kafka集群部署 主机规划: 10.200.3.85 Kafka+ZooKeeper 10.200.3.86 Kafka+ZooKeeper 10.200.3.87 Kaf ...
- Kafka集群部署 (守护进程启动)
1.Kafka集群部署 1.1集群部署的基本流程 下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 1.2集群部署的基础环境准备 安装前的准备工作(zk集群已经部署完毕) 关闭防火墙 c ...
- Kafka集群部署以及使用
Kafka集群部署 部署步骤 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka http://kafka.apache.org/down ...
- kafka 集群部署 多机多broker模式
kafka 集群部署 多机多broker模式 环境IP : 172.16.1.35 zookeeper kafka 172.16.1.36 zookeeper kafka 172.16 ...
- 3、Kafka集群部署
Kafka集群部署 1)解压安装包 [ip101]$ tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/app/ 2)修改解压后的文件名称 [ip101]$ mv k ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- kafka分布式消息队列介绍以及集群安装
简介 首先简单说下对kafka的理解: 1.kafka是一个分布式的消息缓存系统: 2.kafka集群中的服务器节点都被称作broker 3.kafka的客户端分为:一是producer(消息生产者) ...
随机推荐
- 深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
目录 Calcite简介与CBO介绍 Calcite背景与介绍 SQL优化与CBO Calcite优化器 HepPlanner优化器与VolcanoPlanner优化器 Calcite优化样例代码介绍 ...
- 详解volatile关键字和原子引用
本篇看一下Volatile关键字和原子引用. 上图就是JUC包结构,总共分成三块 (1)java.util.concurrent:并发包基础类,包括阻塞队列,线程池相关类,线程安全Map等. (2)j ...
- Salesforce Javascript(一) Promise 浅谈
本篇参看: https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Promise https ...
- java学习(九) —— java中的File文件操作及IO流概述
前言 流是干什么的:为了永久性的保存数据. IO流用来处理设备之间的数据传输(上传和下载文件) java对数据的操作是通过流的方式. java用于操作流的对象都在IO包中. java IO系统的学习, ...
- 聊聊分布式下的WebSocket解决方案
前言 最近王子自己搭建了个项目,项目本身很简单,但是里面有使用WebSocket进行消息提醒的功能,大体情况是这样的. 发布消息者在系统中发送消息,实时的把消息推送给对应的一个部门下的所有人. 这里面 ...
- manacher(马拉车算法)
Manacher(马拉车算法) 序言 mannacher 是一种在 O(n)时间内求出最长回文串的算法 我们用暴力求解最长回文串长度的时间复杂度为O(n3) 很明显,这个时间复杂度我们接受不了,这时候 ...
- 总结一下,selenium 自动化流程如下
自动化程序调用Selenium 客户端库函数(比如点击按钮元素) 客户端库会发送Selenium 命令 给浏览器的驱动程序 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令 浏览器执行命令 浏览器驱 ...
- Linux系统编程 —读写锁rwlock
读写锁是另一种实现线程间同步的方式.与互斥量类似,但读写锁将操作分为读.写两种方式,可以多个线程同时占用读模式的读写锁,这样使得读写锁具有更高的并行性. 读写锁的特性为:写独占,读共享:写锁优先级高. ...
- NMAP类型题目 (escapeshellarg,escapeshellcmd使用不当)
[BUUCTF 2018]Online Tool 给出了源码 审计 <?php if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) { $_SERVER[' ...
- python3 连接数据库~
~目前记录的是针对python3写的数据库连接,不适用于pyhon2.python3如果想要与数据库进行连接,则需要先下载对应各数据库的插件包,然后导入包.python3的插件下载地址:https:/ ...