MHA 高可用介绍
MHA 介绍
| Server | WLAN | Memory | Roles |
|---|---|---|---|
| dbtest01 | 172.16.1.121 | 2G | Master & mha_node |
| dbtest02 | 172.16.1.122 | 2G | Slave & mha_node |
| dbtest03 | 172.16.1.123 | 2G | Slave & mha_manager |
MHA 简介(Master High Availability)
MHA (Master High Availability)能够在较短的时间内实现自动故障检测和故障转移,通常在 10 - 30 秒以内;在复制框架中,MHA 能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的 Replication 中添加额外的服务器,仅需要一个 Manager 节点,而一个 Manager 能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA 提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概 0.5 - 2 秒内即可完成。
MHA 由两部分组成:MHA Manager(管理节点)和 MHA Node(数据节点),MHA Manager 可以独立部署在一台独立的机器上管理多个 Master-Slave 集群,也可以部署在一台 Slave 上。当 Master 出现故障时,它可以自动将最新数据的 Slave 提升为新的 Master,然后将所有其他的 Slave 重新指向新的 Master 。整个故障转移过程对应用程序是完全透明的 。
MHA 工作原理(转载)
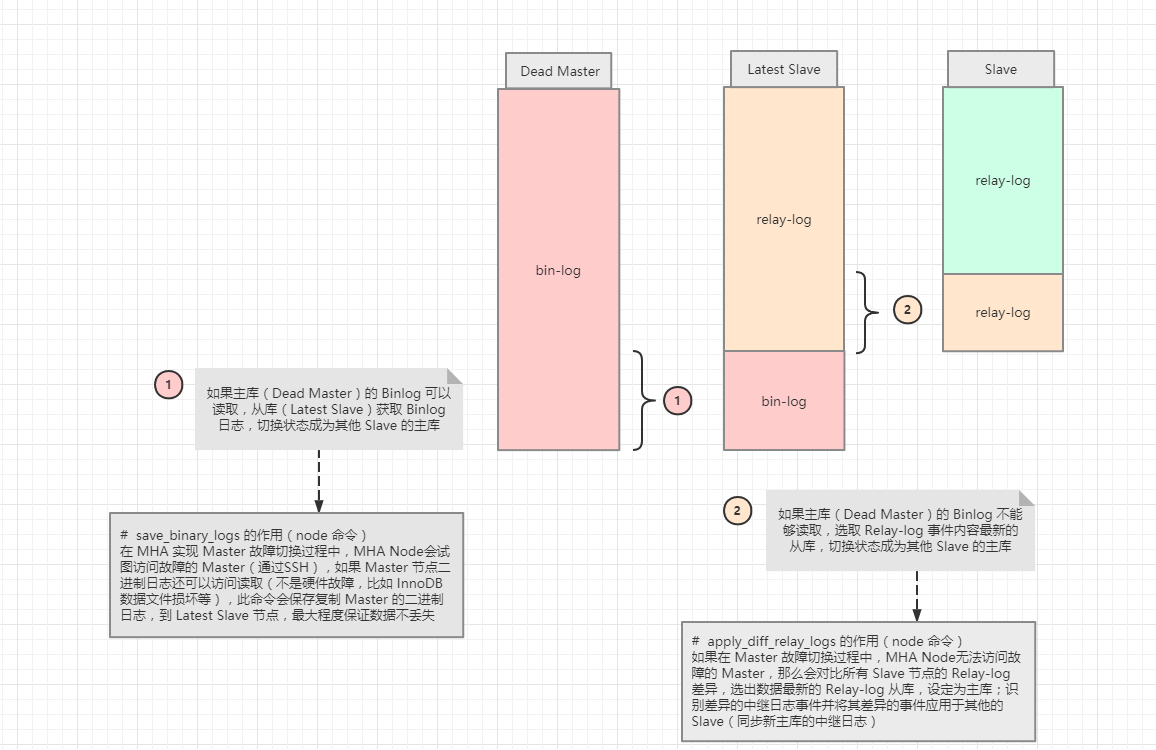
当 Master 出现故障时,通过对比 Slave 之间 I/O线程 读取 Master binlog 的位置,选取最接近的 Slave 做为 Latest Slave 。其它 Slave 通过与Latest Slave对比生成差异中继日志。在 Latest Slave 上应用从 Master 保存的 binlog,同时将 Latest Slave 提升为 Master。最后在其它 Slave 上应用相应的差异中继日志并开始从新的 Master 开始复制
在 MHA 实现 Master 故障切换过程中,MHA Node 会试图访问故障的 Master(通过SSH),如果可以访问(不是硬件故障,比如 InnoDB 数据文件损坏等),会保存二进制文件,以最大程度保证数据不丢失。MHA 和半同步复制一起使用会大大降低数据丢失的危险
1.把宕机的 Master 二进制日志保存下来
2.找到 Binlog 位置点最新的 Slave
3.在 Binlog 位置点最新的 Slave 上用 relay-log(差异日志)修复其它 Slave
4.将宕机的 Master 上保存下来的二进制日志恢复到含有最新位置点的 Slave 上
5.将含有最新位置点 Binlog 所在的 Slave 提升为 Master
6.将其它 Slave 重新指向新提升的 Master,并开启主从复制
MHA 架构
1.MHA 属于 C/S 结构
2.一个 Manager 节点可以管理多套集群
3.集群中所有的机器都要部署 node 节点
4.node 节点才是管理集群机器的
5.Manager 节点通过 ssh 连接 node 节点,管理 node 节点
6.Manager 可以部署在集群中除了主库以外的任意一台机器上
MHA 工具
Manager 节点
MHA Manager 节点不止需要安装MHA Manager 软件,还需要安装 MHA Node 软件
# 解压 二进制包,查看 Manager 命令工具
[root@db01 ~]# ll mha4mysql-manager-0.56/bin/
# 检查主从复制状态
masterha_check_repl
# 检查 SSH 免密配置
masterha_check_ssh
# 检查当前 MHA 运行状态
masterha_check_status
# 添加或删除配置 server 信息(app1.conf 中 [serverxx] 配置)
masterha_conf_host
# 启动 MHA 命令
masterha_manager
# 检测 Master 是否宕机
masterha_master_monitor
# 控制故障转移(自动或者手动)
masterha_master_switch
# 建立 TCP连接(从远程服务器)
masterha_secondary_check
# 关闭 MHA 命令
masterha_stop
Node 节点
# 解压 二进制包,查看 Node 命令工具
[root@db01 ~]# ll mha4mysql-node-0.56/bin/
# 对比中继日志(Relay-log)差异,识别差异的中继日志事件并将其差异的事件应用于其他的 Slave
apply_diff_relay_logs
# 去除不必要的 ROLLBACK(回滚)事件
filter_mysqlbinlog
# 清除中继日志(Relay-log)
purge_relay_logs
# 保存二进制日志(Bin-log),保存和复制master的二进制日志
save_binary_logs
MHA 优点
1.Masterfailover and slave promotion can be done very quickly
自动故障转移快
2.Mastercrash does not result in data inconsistency
主库崩溃不存在数据一致性问题
3.Noneed to modify current MySQL settings (MHA works with regular MySQL)
不需要对当前 MySQL 环境做重大修改
4.Noneed to increase lots of servers
不需要添加额外的服务器(仅一台 Manager 就可管理上百个 Replication)
5.Noperformance penalty
性能优秀,可工作在半同步复制和异步复制,当监控 MySQL 状态时,仅需要每隔 N 秒向 Master 发送 ping 包(默认3秒),所以对性能无影响。你可以理解为 MHA 的性能和简单的主从复制框架性能一样。
6.Works with any storage engine
只要 Replication 支持的存储引擎,MHA 都支持,不会局限于 Innodb
MHA 保证数据一致性
主要通过MHA node 的以下几个工具实现,但是这些工具的 MHA manager 触发:
save_binary_logs 如果 Master 的二进制日志可以存取的话,保存复制 Master 的二进制日志,最大程度保证数据不丢失
apply_diff_relay_logs 相对于最新的 Slave,生成差异的中继日志并将所有差异事件应用到其他所有的 Slave
注意:
对比的是 relay log,relay log 越新就越接近于 Master,才能保证数据是最新的
purge_relay_logs 删除中继日志而不阻塞 SQL线程
搭建 MHA
保证主从状态
# 主库
mysql> show master status;
# 从库
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#从库
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
配置文件
配置 MHA 涉及以下配置:
# 关闭从库自动清除 relay-log 的配置
relay_log_purge=0
# 配置从库只读
read_only=1
# 从库保存 Bin-log
log_slave_updates
# 若不重启,需要设置全局环境变量
# 禁用自动删除 relay log 功能
mysql> set global relay_log_purge=0;
# 设置只读
mysql> set global read_only=1;
# 设置从库保存 Bin-log
mysql> set log_slave_updates=1;
主库配置(Master)
当主库宕机时,再次恢复服务有可能变成从库,所以设置只读;
当从库切换状态称为主库时,MHA 会自动取消只读设置 。
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
从库配置(slave01)
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
从库配置(slave02)
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
安装 Node 依赖
[root@db01 ~]# yum install perl-DBD-MySQL -y
[root@db02 ~]# yum install perl-DBD-MySQL -y
[root@db03 ~]# yum install perl-DBD-MySQL -y
安装 Manager 依赖
[root@db03 ~]# yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
部署 Node 节点
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
部署 Manager 节点
[root@db03 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm
创建 MHA 配置文件
# 创建 MHA 配置目录
[root@db03 ~]# mkdir -p /service/mha
# 配置 MHA
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
# 指定工作目录
manager_workdir=/service/mha/app1
# 指定日志存放路径
manager_log=/service/mha/app1/manager
# binlog 存放目录
master_binlog_dir=/usr/local/mysql/data
# MHA 管理用户
user=mha
# MHA 管理用户的密码
password=mha
# 检测时间
ping_interval=2
# 主从复制用户
repl_user=rep
# 主从复制用户的密码
repl_password=123
# SSH 免密用户
ssh_user=root
[server1]
hostname=172.16.1.51
port=3306
[server2]
candidate_master=1
check_repl_delay=0
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
# 设置为候选 master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
# candidate_master=1
# 默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
# check_repl_delay=0
创建 MHA 管理用户
# 主库执行即可
mysql> grant all on *.* to mha@'172.16.1.%' identified by 'mha';
Query OK, 0 rows affected (0.03 sec)
SSH 免密(全做)
三台服务器,互相发送 SSH 公钥:
# 创建秘钥对
[root@db01 ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
# 发送公钥,包括自己
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.121
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.122
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.123
检测 MHA 状态
# 检测主从
[root@db03 ~]# masterha_check_repl --conf=/service/mha/app1.conf
MySQL Replication Health is OK.
# 检测 SSH 免密连接配置
[root@db03 ~]# masterha_check_ssh --conf=/service/mha/app1.conf
Mon Jul 27 11:40:06 2020 - [info] All SSH connection tests passed successfully.
启动 MHA
#启动
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.conf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
nohup ... & # 后台启动
masterha_manager # 启动命令
--conf=/service/mha/app1.cnf # 指定配置文件
--remove_dead_master_conf # 移除挂掉的主库配置
--ignore_last_failover # 忽略最后一次切换
< /dev/null > /service/mha/manager.log 2>&1
# MHA保护机制:
1.MHA主库切换后,8小时内禁止再次切换
2.切换后会生成一个锁文件,下一次启动MHA需要检测该文件是否存在
恢复 MHA
修复数据库
[root@db01 ~]# systemctl start mysqld.service
# 将新主库的数据,导入到此数据库
恢复主从配置
# 将恢复的数据库当成新的从库加入集群
# 找到binlog位置点
[root@db03 ~]# grep 'CHANGE MASTER' /service/mha/app1/manager | awk -F: 'NR==1 {print $4}'
CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='xxx';
# 恢复的数据库执行change master to
mysql> CHANGE MASTER TO MASTER_HOST='172.16.1.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='123';
Query OK, 0 rows affected, 2 warnings (0.20 sec)
mysql> start slave;
Query OK, 0 rows affected (0.05 sec)
恢复 MHA
# 将恢复的数据库配置到 MHA配置文件
[root@db03 ~]# vim /service/mha/app1.cnf
......
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
......
# 启动MHA
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
MHA 高可用介绍的更多相关文章
- MHA高可用架构与Atlas读写分离
1.1 MHA简介 1.1.1 MHA软件介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton ...
- Mysql MHA高可用集群架构
** 记得之前发过一篇文章,名字叫<浅析MySQL高可用架构>,之后一直有很多小伙伴在公众号后台或其它渠道问我,何时有相关的深入配置管理文章出来,因此,民工哥,也将对前面的各类架构逐一进行 ...
- MHA 高可用集群搭建(二)
MHA 高可用集群搭建安装scp远程控制http://www.cnblogs.com/kevingrace/p/5662839.html yum install openssh-clients mys ...
- MHA高可用 MHA+Keepalive
MHA高可用 MHA简介 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebo ...
- 搭建MySQL MHA高可用
本文内容参考:http://www.ttlsa.com/mysql/step-one-by-one-deploy-mysql-mha-cluster/ MySQL MHA 高可用集群 环境: Linu ...
- MySQL for OPS 08:MHA 高可用
写在前面的话 主从架构在一般情况下只能满足我们小公司业务并非一刻都不能中断服务.但是对于大型公司而言,对然数据丢失,数据库挂了,我们可以通过技术找回,修复.但是其中修复过程所消耗的时间是不被允许的.此 ...
- MySQL MHA 高可用集群部署及故障切换
MySQL MHA 高可用集群部署及故障切换 1.概念 2.搭建MySQL + MHA 1.概念: a)MHA概念 : MHA(MasterHigh Availability)是一套优秀的MySQL高 ...
- MHA高可用配置及故障切换
MHA高可用配置及故障切换 目录 MHA高可用配置及故障切换 一.案例概述 二.案例前置知识点 1. MHA概述 2. MHA的组成 (1)MHA Manager(管理节点) (2)MHA Node( ...
- MHA 高可用架构部署
一, MHA 介绍 MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公 ...
随机推荐
- 【网络】trunk和vlan配置
篇一 : trunk配置和vlan配置 trunk配置 Switch>enable ? ? ?//进入特权模式 Switch#conf t ? ? ?//进入配置模式 Switch(config ...
- postgresql中权限介绍
postgresql权限分为实例的权限,数据库的权限,模式的权限,对象的权限,表空间的权限 实例的权限:由pg_hba.conf文件控制,控制那些用户那些IP以哪种方式连接数据库 数据库的权限:是否允 ...
- Genymotion虚拟机用键盘输入中文
genymotion我用的版本是3.0.4,安卓内核版本从4到9都进行了尝试,尤其是教新的版本原生是不带中文输入法的. 前提:安装Genymotion以后,想要随意安装app,需要先安装Genymot ...
- centos7虚拟机开启端口后 外部不能访问的问题
转载 https://blog.csdn.net/u012045045/article/details/104219823 虚拟机新开了5005端口,系统内部是显示开了的(wget 192.168.4 ...
- USB充电限流IC,可调到4.8A,输入 6V关闭
随着手机充电电流的提升,和设备的多样化,USB限流芯片就随着需求的增加而越来越多,同时为了更好的保护电子设备,需要进行一路或者多路的负载进行限流. 一般说明 PW1503,PW1502是超低RDS(O ...
- HTTP协议相关知识整理:
http协议简介 超文本传输协议:是一种用于分布式.协作式和超媒体信息系统的应用层协议. 一次请求一次响应之后断开连接(无状态,短连接) 分析http请求信息格式 http工作原理 以下是 HTTP ...
- JavaScript中原型对象的应用!
JavaScript中原型对象的应用! 扩展内置对象的方法 我以数组对象为例! // 原型对象的应用 扩展内置对象方法! Array.prototype.sum = function() { var ...
- Java并发组件二之CyclicBarriar
使用场景: 多个线程相互等待,直到都满足条件之后,才能执行后续的操作.CyclicBarrier描述的是各个线程之间相互等待的关系. 使用步骤: 正常实例化:CyclicBarrier sCyclic ...
- php artisan db:seed 报错
在laravel 5中执行,要执行数据填充时报如下错误 php artisan db:seed 错误: [ReflectionException] Cla ...
- java.util.List.subList使用注意
List<E> subList(int fromIndex, int toIndex); 它返回原来list的从[fromIndex, toIndex)之间这一部分的视图,之所以说是视图, ...