浅谈 FHQ-Treap
关于FHQ-Treap
——作者:BiuBiu_Miku
可能需要的前置知识:
一.树形结构的了解:
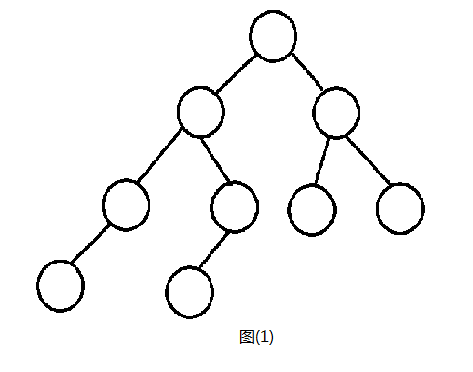
树形,顾名思义,就是像树一样有很多分叉口,而这里以二叉树为例子,二叉树表示整棵树每个节点的的分叉都小于或等于二,树上最顶端的节点称之为根节点,下面的称为叶子节点。如图(1)就是一棵二叉树。
二.平衡树的概念:
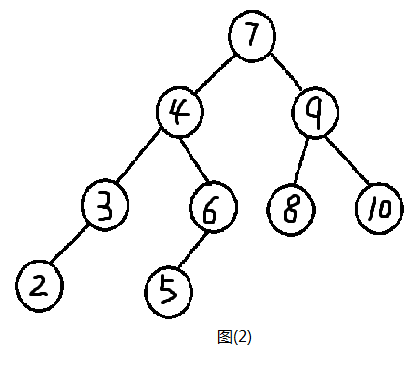
平衡树也叫二叉查找树,学过OI大大佬们应该都知道一个东西叫做二分查找,这里叫二叉查找,所以也具备一个性质,当前节点的左子树上每个节点的值都小于父亲节点(当前节点)的值,右子树上每个节点的值都大于父亲节点(当前节点)的值。如图(2)就是一棵二叉查找树。
三.关于平衡树的一些基本操作的了解:
1.插入(指的在树中插入某个值)
2.删除(指删除某个在树中存在的值)
3.查询排名(一般指比自己小的数字的个数+1,从小到大)
4.找第K小(指在树中寻找排名为K的值是多少)
5.前驱(指在树中比某个值小且又是最接近这个值得数。如当前树中假设有2,3,5,6四个数字,则5的前驱就是3)
6.后继(指在树中比某个值大且又是最接近这个值得数。如当前树中假设有2,3,5,6四个数字,则3的后继就是5)
三.treap:
它是一种解决平衡树基本操作的方法,它依靠旋转来维护平衡(你不知道旋转是什么也行,你就理解为一种维护树平衡的方法),同时我们不希望整棵树变成一个链(图(3)就是一棵变成链的树),不然时间复杂度可想而知,所以他加了一个东西叫做修正值(不知道大佬们怎么叫这玩意,反正我喜欢叫他修正值),来纠正树,不让他变成链,而这个修正值是随机的,且整棵树的修正值满足一个大根堆或者小跟堆的性质,例如叶子节点的修正值永远小于父亲节点的修正值,不然就通过旋转纠正树。
进入正题
众所周知,关于实现平衡树基本操作的方法有很多,例如splay,treap,红黑树,等等解法。
其中,大部分都利用到了旋转(左旋右旋),其代码可能让一些大佬看得不适,因此,一位叫做范浩强的巨佬提出了一种不需要旋转的treap,因此称为FHQ-Treap。
既然还是平衡树,那么它自然有自己的一套维护树平衡(使树仍然有着二叉查找树的性质)的方法。
它的操作不是左旋右旋,而是分裂合并。
初始化:
直接上代码吧!
struct Node
{
long long val , size , fix ; //val表示当前节点的值,size表示他的左子树和右子树的节点个数(包括自己),fix表示修正值
long long lson , rson ; //lson表示左儿子的编号,rson表示右儿子的编号
} fhq [ 100006 ] ;
long long cur ;
long long root ; //表示根节点
inline long long New_Node ( long long val ) /建一个新节点
{
long long sd=1e6*2+5;
cur ++ ; //节点编号+1
fhq [ cur ] . val = val ; //给当前节点的值赋值
fhq [ cur ] . fix = rand() % sd ; //为修正值生成一个随机数
fhq [ cur ] . size = 1 ; //当前节点没有儿子,只有自己,所以初始为1
return cur ; //返回当前节点编号
}
inline void update ( long long now ) //更新或维护节点
{
fhq [ now ] . size = 0; //先将当前节点的长度清0
fhq [ now ] . size += fhq [ fhq [ now ] . lson ] . size ; //根据定义加上左儿子和右儿子的长度
fhq [ now ] . size += fhq [ fhq [ now ] . rson ] . size ;
fhq [ now ] . size ++ ; //包括自己也算在长度内
}
操作一:分裂
顾名思义,分裂指的是把一棵树按照某个值(我管他叫分裂值)分裂成两棵树,一般把这两棵树分别叫做x和y,x上的值都小于或等于这个值,y上的值都大于这个值。
如图(4)就是一棵树的分裂。
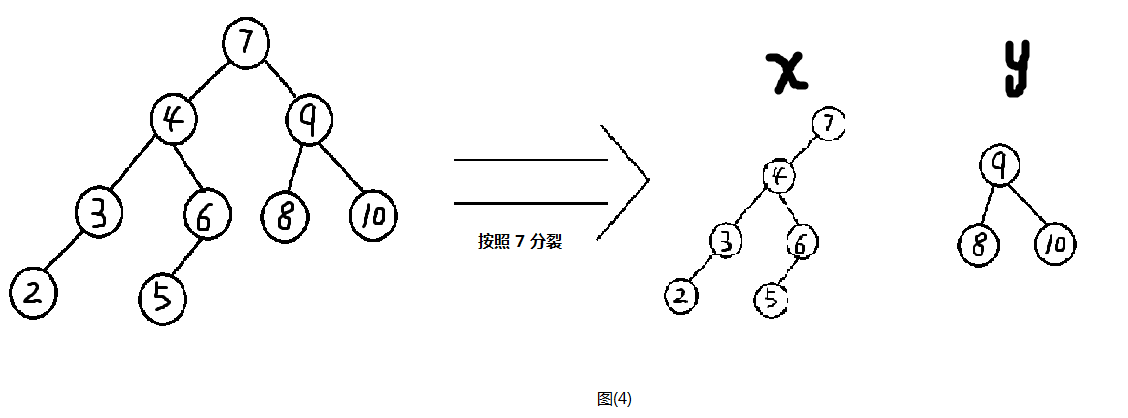
其原理很简单就是搜索整棵树。
关于x:如果找到一个值小于或等于分裂值时,就把它以及它的左子树归为x,然后往右子树继续寻找。那么有的人就问了,为什么就把它以及它的左子树归为x?明明只有x满足啊!你想啊,平衡树的性质不就是左子树都小于根吗,既然这个根都小于某个特定值了,那么当前节点的左子树不更加小于这个特定值吗?那么为什么要往右子树继续搜呢?因为右子树比根大,所以我们不能确定右子树全部的值小于分裂值,因此要继续找。
关于y:就正好相反,如果找到一个值大于分裂值时,就把它以及它的右子树归为y,然后往左子树继续寻找。
上代码!
inline void spilt ( long long now , long long val , long long &x , long long &y ) //其中now表示当前搜索到的节点,val表示分裂值,x,y就是两棵分裂的树
{
if( !now ) x = y = 0 ; //这里指,如果当now便利到一个不存在的节点的时候,x和y就没有节点可以加上了,因此可以退出循环。
else
{
if(fhq [ now ] . val <= val) //如果当前节点的值小于或等于分裂值,则把当前的值归给x。
{
x = now ; //归入x
spilt(fhq [ now ] . rson , val , fhq [ now ] . rson , y ) ; //继续往右子树寻找
}
else //同上,不过相反
{
y = now ;
spilt(fhq [ now ] . lson , val , x , fhq [ now ] . lson ) ;
}
update(now); //维护一下当前搜索到的节点
}
}
操作二:合并
顾名思义,合并表示的就是把两棵树合并成一棵树,并且合并之后,树仍然符合二分查找树的性质且修正值满足小跟堆或大根堆。我们这里以大根堆为例子。
如图(5)就是两棵树的合并图。
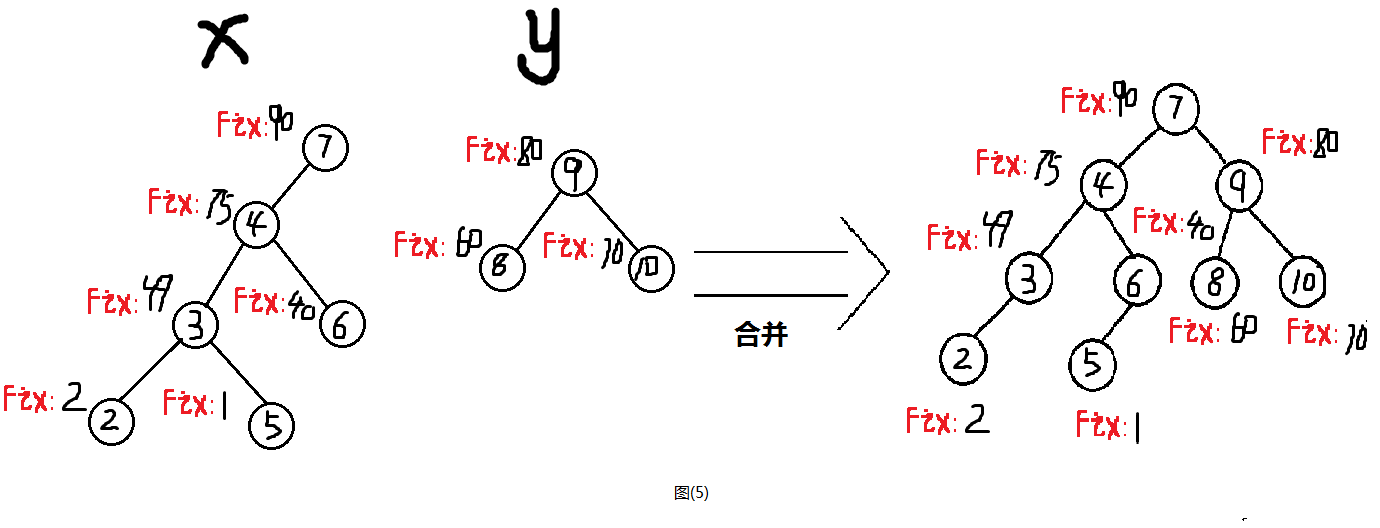
那么怎么合并才能让树仍然符合二分查找树的性质且形成一个大根堆呢?
你想啊,我们在分裂的时候x树上所有的值是不是都小于y上所有的值因此,可以推测,y一定在x树的右边,根据大根堆,右可以判断y在x的下边,所以y在x树的右下边。
因此,当我们符合大根堆性质的时候就把y树合并到x树上就行了(这里不用管二叉搜索树的性质,因为本来x是一个合法的二叉搜索树,y也是一个合法的二叉搜索树,且x上所有值都小于y上所有值,因此只要合并时合法且不破坏x树和y树本身,就不会破坏性质)
上代码!
inline long long merge ( long long &x , long long &y ) //其中x和y表示要合并的两棵树
{
if( !x || !y )return x + y ; //这里可以理解为如果有一个不存在就返回另一个的值(这个值表示把两棵树合并之后的根的编号)中间的加号也能换成|
if( fhq [ x ] . fix > fhq [ y ] . fix ) //当满足大根堆时我们就把y根x合并
{
fhq [ x ] . rson = merge ( fhq [ x ] . rson , y ) ; //因为根据二叉搜索树性质,y一定在x的右子树所以就把y根x的左子树合并
update ( x ) ; //因为把y合并到了x上,所以x的长度也会相应得变化,所以说要更新一下
return x ; //返回合并后的节点的值
}
else
{
fhq [ y ] . lson = merge ( x , fhq [ y ] . lson ) ; //同上,不过相反
update( y ) ;
return y ;
}
}
以上便是FHQ-Treap用来维护树平衡的方法,是不是跟旋转不同,但又觉得,好像比旋转复杂,其实,你看它的格式,基本上都是写一段,然后复制一段,然后反过来写(如:x改成y,lson变成rson)。
那么我们来讲讲如何实现基本操作。
基本操作一:插入
我们可以把树按照要插入的值分裂开来,y上的值都比这个数大,x则相反,因此按照二叉查找树性质,我们可以把这个数根x合并,然后再把合并后的子树根y合并,此时,就成功把这个数插进去了。
上代码!
inline void Insert ( long long val ) //val表示要插进去的数
{
spilt ( root , val , x , y ) ; //分成两棵子树
long long up_new = New_Node ( val ) ; //申请一个新的节点
long long up_x = merge ( x , up_new ); //把新节点看做一棵子树跟x合并
root = merge ( up_x , y ) ; //最后把x跟y合并
}
基本操作二:删除
关于删除,其实也很简单。
首先把树按照val分成x,z两棵树。此时x是<=val,z是>val-1的。
然后,我们再把子树x按val-1分成x和y两部分,此时x<=val-1,y>val-1的,又因为原本的x子树上的值全部都是<=val因此这里的y是val>=y>val-1,所以y=val,所以我们只需要在y上面随便删除一个节点就好了,删除根节点更加方便,因此,我们删除y子树上的根节点。
上代码!
inline void Delete ( long long val ) //val表示要删除的节点的值
{
spilt ( root , val , x , z ) ; //把树按照val拆成x,z两棵子树
spilt ( x , val-1 , x , y ) ; //把树按照val-1拆成x,y两棵子树
y = merge ( fhq [ y ] . lson , fhq [ y ] . rson ) ; //删除y的根节点,相当于合并它的左右子树,然后把合并后子树的根给y,就相当于删除了原本的y
long long up_xy = merge ( x , y ) ; //拆了就要和,有拆必有合嘛
root = merge ( up_xy , z ) ;
}
基本操作三:查询排名
这个更水,我们既然是找从小到大排序的,所以我们只需要把以val-1树分成x,y两棵子树,此时x上的树就全部<=val-1,所以直接用x的size加上1就好了。
上代码!
inline long long get_rank ( long long val ) //val表示要查询数的排名
{
spilt ( root , val-1 , x , y ) ; //按val-1分裂成x,y两棵子树
int retur = fhq [ x ] . size + 1 ; //直接算出答案
root = merge ( x , y ) ; //合并一下,因为分开了
return retur ; //返回算出的答案
}
基本操作四:找第k小
这个稍微有点长,但是好理解,我觉得直接对着代码将跟好。(大佬勿怼)
上代码!
inline long long get_num ( long long rank ) //我们需要获取排名为rank的树
{
long long now = root ; //首先从根节点开始找
while ( now )
{
long long now_rank = fhq [ fhq [ now ] . lson ] . size + 1 ; //方便后面,先把当前搜索到的节点的排名存起来
if ( now_rank == rank ) return fhq [ now ] . val ; //如果跟要找得排名一样,那就返回当前节点的值
if ( now_rank > rank ) now = fhq [ now ] . lson ; //如果当前排名大于要找的排名,我们就得往左子树找,因为我们排名是从小到大,且左子树小于根节点,右子树大于根节点。
else //否则就得往右子树搜,理由同上,只是反了过来
{
rank -= now_rank ; //因为已经找过了现在的排名也就是说搜过了那么多数了,因此我们要减掉,因为我们要找rank所以,相当于我们要在比自己大的右子树寻找第rank-now_rank。
now = fhq [ now ] . rson ; //继续找右子树
}
}
}
基本操作五和六:前驱后继
为什么我要放在一起呢,因为他们两个也是一样的,只是相反而已。
我们先讲讲前驱,我们可以把树按照val-1分成x,y两棵子树,此时x<=val-1,y>val-1,很显然,答案在x里,此时我们要找到最接近的,所以只需要便利x的右子树就好了。
后继同理,我们可以把树按照val分成x,y两棵子树,此时x<=val,y>val,很显然,答案在y里,此时我们要找到最接近的,所以只需要便利y的左子树就好了。
上代码!
inline long long prev ( long long val ) //前驱,val表示我们要找val的前驱
{
spilt ( root , val-1 , x , y ) ; //把树按照val-1分成x,y两棵子树
long long now = x ; //答案在x里因此要便利子树x
while( fhq [ now ] . rson && fhq [ fhq [ now ] . rson ] . val != val ) now = fhq [ now ] . rson ; //一直往x子树的右儿子便利,直到便利到没有右孩子为止,此时的now对应的val是满足条件的最大的。
root = merge ( x , y ) ; //有分有合
return fhq [ now ] . val ; //返回前驱
}
inline long long succ ( long long val ) //后继,val表示我们要找val的后继
{
spilt ( root , val , x , y ) ; //同上,只是相反
long long now = y ;
while( fhq [ now ] . lson && fhq [ fhq [ now ] . lson ] . val != val ) now = fhq [ now ] . lson ;
root = merge ( x , y ) ;
return fhq [ now ] . val ;
}
以上便是关于FHQ-Treap的一些基本知识,当然,FHQ-Treap也可以解决文艺平衡树的区间问题,这里只是入门,现在上个模板代码:
#include<bits/stdc++.h>
using namespace std;
struct Node
{
long long val , size , fix ;
long long fa , lson , rson ;
} fhq [ 100006 ] ;
long long cur ;
long long root ;
inline long long New_Node ( long long val )
{
long long sd=1e6*2+5;
cur ++ ;
fhq [ cur ] . val = val ;
fhq [ cur ] . fix = rand() % sd ;
fhq [ cur ] . size = 1 ;
return cur ;
}
inline void update ( long long now )
{
fhq [ now ] . size = 0;
fhq [ now ] . size += fhq [ fhq [ now ] . lson ] . size ;
fhq [ now ] . size += fhq [ fhq [ now ] . rson ] . size ;
fhq [ now ] . size ++ ;
}
long long x , y , z ;
inline void spilt ( long long now , long long val , long long &x , long long &y )
{
if( !now ) x = y = 0 ;
else
{
if(fhq [ now ] . val <= val)
{
x = now ;
spilt(fhq [ now ] . rson , val , fhq [ now ] . rson , y ) ;
}
else
{
y = now ;
spilt(fhq [ now ] . lson , val , x , fhq [ now ] . lson ) ;
}
update(now);
}
}
inline long long merge ( long long &x , long long &y )
{
if( !x || !y )return x + y ;
if( fhq [ x ] . fix > fhq [ y ] . fix )
{
fhq [ x ] . rson = merge ( fhq [ x ] . rson , y ) ;
update ( x ) ;
return x ;
}
else
{
fhq [ y ] . lson = merge ( x , fhq [ y ] . lson ) ;
update( y ) ;
return y ;
}
}
inline void Insert ( long long val )
{
spilt ( root , val , x , y ) ;
long long up_new = New_Node ( val ) ;
long long up_x = merge ( x , up_new );
root = merge ( up_x , y ) ;
}
inline void Delete ( long long val )
{
spilt ( root , val , x , z ) ;
spilt ( x , val-1 , x , y ) ;
y = merge ( fhq [ y ] . lson , fhq [ y ] . rson ) ;
long long up_xy = merge ( x , y ) ;
root = merge ( up_xy , z ) ;
}
inline long long prev ( long long val )
{
spilt ( root , val-1 , x , y ) ;
long long now = x ;
while( fhq [ now ] . rson && fhq [ fhq [ now ] . rson ] . val != val ) now = fhq [ now ] . rson ;
root = merge ( x , y ) ;
return fhq [ now ] . val ;
}
inline long long succ ( long long val )
{
spilt ( root , val , x , y ) ;
long long now = y ;
while( fhq [ now ] . lson && fhq [ fhq [ now ] . lson ] . val != val ) now = fhq [ now ] . lson ;
root = merge ( x , y ) ;
return fhq [ now ] . val ;
}
inline long long get_rank ( long long val )
{
spilt ( root , val-1 , x , y ) ;
int retur = fhq [ x ] . size + 1 ;
root = merge ( x , y ) ;
return retur ;
}
inline long long get_num ( long long rank )
{
long long now = root ;
while ( now )
{
long long now_rank = fhq [ fhq [ now ] . lson ] . size + 1 ;
if ( now_rank == rank ) return fhq [ now ] . val ;
if ( now_rank > rank ) now = fhq [ now ] . lson ;
else
{
rank -= now_rank ;
now = fhq [ now ] . rson ;
}
}
return 0 ;
}
long long n ;
int main()
{
// freopen( "P3369_6.in" , "r" , stdin ) ;
// freopen( "1.txt" , "w" , stdout ) ;
srand ( ( unsigned ) time ( NULL ) ) ;
scanf ( "%lld" , & n ) ;
for ( long long i = 1 ; i <= n ; i ++ )
{
long long o , b ;
scanf ( "%lld%lld" , & o , & b );
if ( o == 1 ) Insert ( b ) ;
if ( o == 2 ) Delete ( b ) ;
if ( o == 3 ) printf ( "%lld\n" , get_rank ( b ) ) ;
if ( o == 4 ) printf ( "%lld\n" , get_num ( b ) ) ;
if ( o == 5 ) printf ( "%lld\n" , prev ( b ) ) ;
if ( o == 6 ) printf ( "%lld\n" , succ ( b ) ) ;
}
return 0 ;
}
推荐几道题目:
洛谷 P3369 【模板】普通平衡树
洛谷 P6136 【模板】普通平衡树(数据加强版)
洛谷 P1503 鬼子进村
感谢您的阅读,有什么写得不好的请大佬指出,谢谢大佬%%%
浅谈 FHQ-Treap的更多相关文章
- 浅谈fhq treap
一.简介 fhq treap 与一般的treap主要有3点不同 1.不用旋转 2.以merge和split为核心操作,通过它们的组合实现平衡树的所有操作 3.可以可持久化 二.核心操作 代码中val表 ...
- 浅谈BST(二叉查找树)
目录 BST的性质 BST的建立 BST的检索 BST的插入 BST求前驱/后继 BST的节点删除 复杂度 平衡树 BST的性质 树上每个节点上有个值,这个值叫关键码 每个节点的关键码大于其任意左侧子 ...
- 在平衡树的海洋中畅游(四)——FHQ Treap
Preface 关于那些比较基础的平衡树我想我之前已经介绍的已经挺多了. 但是像Treap,Splay这样的旋转平衡树码亮太大,而像替罪羊树这样的重量平衡树却没有什么实际意义. 然而类似于SBT,AV ...
- 浅谈 Fragment 生命周期
版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/Fragment 文中如有纰漏,欢迎大家留言指出. Fragment 是在 Android 3.0 中 ...
- 浅谈 LayoutInflater
浅谈 LayoutInflater 版权声明:本文为博主原创文章,未经博主允许不得转载. 微博:厉圣杰 源码:AndroidDemo/View 文中如有纰漏,欢迎大家留言指出. 在 Android 的 ...
- 浅谈Java的throw与throws
转载:http://blog.csdn.net/luoweifu/article/details/10721543 我进行了一些加工,不是本人原创但比原博主要更完善~ 浅谈Java异常 以前虽然知道一 ...
- 浅谈SQL注入风险 - 一个Login拿下Server
前两天,带着学生们学习了简单的ASP.NET MVC,通过ADO.NET方式连接数据库,实现增删改查. 可能有一部分学生提前预习过,在我写登录SQL的时候,他们鄙视我说:“老师你这SQL有注入,随便都 ...
- fhq treap最终模板
新学习了fhq treap,厉害了 先贴个神犇的版, from memphis /* Treap[Merge,Split] by Memphis */ #include<cstdio> # ...
- 浅谈WebService的版本兼容性设计
在现在大型的项目或者软件开发中,一般都会有很多种终端, PC端比如Winform.WebForm,移动端,比如各种Native客户端(iOS, Android, WP),Html5等,我们要满足以上所 ...
- 浅谈angular2+ionic2
浅谈angular2+ionic2 前言: 不要用angular的语法去写angular2,有人说二者就像Java和JavaScript的区别. 1. 项目所用:angular2+ionic2 ...
随机推荐
- EasyRecovery扫描预览功能,助你选择需要的数据恢复
说到数据恢复,很多人都会选择EasyRecovery,EasyRecovery作为一个功能性还不错的数据恢复软件,能够帮你恢复丢失的数据以及重建文件系统. 在数据恢复的同时,EasyRecovery还 ...
- 如何使用系统清理缓存软件优化MacBook
在我们使用我们的Mac一定的时间后,总是不可避免的出现Mac内存不足的情况,所以清理垃圾软件也就成为了我们电脑里必不可少的软件.苹果软件商店中有很多各有不同的清理垃圾软件,但我们往往很难从这一大堆软件 ...
- css3系列之text-shadow 浮雕效果,镂空效果,荧光效果,遮罩效果
text-shadow 其实这东西,跟 box-shadow 差不多,没啥好说的不懂的话,点这里→ css3系列之详解box-shadow . 它只有 四个参数 x(第一个值设置x位置) y(第 ...
- JAVA面试宝典分享
JAVA面试宝典分享 前言 面试题 Java面试题(上) Java面试题(中) Java面试题(下) 参考答案 其他补充内容: 项目经验 项目介绍 项目开发流程 项目管理 系统架构 第三方工具(插件) ...
- QQ账号测试用例
- 关于Jersey框架下的Aop日志 和Spring 框架下的Aop日志
摘要 最近新接手的项目经常要查问题,但是,前面一拨人,日志打的非常乱,好多就根本没有打日志,所以弄一个AOP统一打印一下 请求数据和响应数据 框架 spring+springmvc+jersey 正文 ...
- B. Irreducible Anagrams【CF 1290B】
思路: 设tx为t类别字符的个数. ①对于长度小于2的t明显是"YES"②对于字符类别只有1个的t明显是"YES"③对于字符类别有2个的t,如左上图:如果str ...
- url的组成结构信息
http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name 从上面的URL可以看出,一个完整的 ...
- 第十三章 Python基础篇结束章
从2019年3月底开始学习Python,4月份开始在CSDN发博客,至今不到半年,老猿认为博客内容中关于Python基础知识的内容已经基本告一段落,本章进入Python基础知识结束章节,对Python ...
- 「Elasticsearch」SpringBoot快速集成ES
Elastic Search 的底层是开源库 Lucene.但是Lucene的使用门槛比较高,必须自己写代码去调用它的接口.而Elastic Search的出现正是为了解决了这个问题,它是 Lucen ...