MySQL索引分析及使用
一、索引介绍
1.1、什么是索引?
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
1.2、为什么要使用索引?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。 索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
二、索引的原理
通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
2.1、索引的数据结构
任何一种数据结构都不是凭空产生的,一定会有它的背景和使用场景,我们现在总结一下,我们需要这种数据结构能够做些什么,其实很简单,那就是:每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。那么我们就想到如果一个高度可控的多路搜索树是否能满足需求呢?就这样,b+树应运而生。
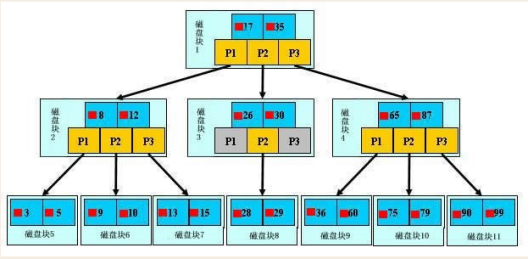
如上图,是一颗b+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
2.2、b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
三、MySQL的索引分类
1、普通索引index:加速查找
2、唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3、联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4、全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
5、空间索引spatial :了解就好,几乎不用
四、添加索引需遵循的原则
4.1、最左前缀匹配原则:必须按照从左到右的顺序匹配
如果创建索引:create index ix_name_email on s1(name,email) //组合索引
select * from s1 where name='egon'; //可以
select * from s1 where name='egon' and email='asdf'; //可以
select * from s1 where email='alex@oldboy.com'; //不可以
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。所以,把需要范围查询的索引尽量放在靠后的位置。
最左前缀示例:
- 1 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male';
- 2 Empty set (0.39 sec) //未创建索引
- 3
- 4
- 5
- 6 mysql> create index idx on s1(id,name,email,gender); //创建索引
- 7 Query OK, 0 rows affected (15.27 sec)
- 8 Records: 0 Duplicates: 0 Warnings: 0
- 9
- 10
- 11
- 12 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male';
- 13 Empty set (0.43 sec) //未遵循最左前缀原则
- 14
- 15
- 16
- 17 mysql> drop index idx on s1;
- 18 Query OK, 0 rows affected (0.16 sec)
- 19 Records: 0 Duplicates: 0 Warnings: 0 //删除刚才创建的错误索引
- 20
- 21
- 22
- 23 mysql> create index idx on s1(name,email,gender,id); //创建正确的索引
- 24 Query OK, 0 rows affected (15.97 sec)
- 25 Records: 0 Duplicates: 0 Warnings: 0
- 26
- 27
- 28
- 29 mysql> select * from s1 where id>3 and name='egon' and email='alex333@oldboy.com' and gender='male';
- 30 Empty set (0.03 sec) //遵循最左前缀原则
4.2、索引列不能参与计算
索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’ 就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值, 但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。 所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
五、索引无法命中的情况
- like '%xx'
select * from tb1 where email like '%cn';
特别的:如果是 select * from tb1 where email like 'cn%'; 则可以使用到索引
两边都有“%”,则索引也不起作用,这时候,如果想让 select * from tb1 where email like '%cn%' 的索引起作用,最好使用覆盖索引,即select查询的字段就是索引字段。
- 使用函数
select * from tb1 where reverse(email) = 'wupeiqi';
- or
select * from tb1 where nid = 1 or name = 'seven@live.com';
特别的:如果or条件中,所有的字段都有索引,则会走索引。只要有一个字段没索引,则不走索引。
- 类型不一致
如果列是字符串类型,传入条件是必须用引号引起来,不然索引失效
select * from tb1 where email = 999;
- !=
select * from tb1 where email != 'alex'
特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123
-is null 或者is not null 也无法使用索引
- >
select * from tb1 where email > 'alex'
特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123
select * from tb1 where num > 123
- order by
select name from s1 order by email desc; //不走索引
当根据索引排序时候,select查询的字段如果不是索引,则不走索引
select email from s1 order by email desc; //走索引
特别的:如果对主键排序,则还是走索引:
select * from tb1 order by nid desc; //走索引
- 组合索引最左前缀
如果组合索引为:(name,email)
name and email //使用索引
name //使用索引
email //不使用索引
MySQL索引分析及使用的更多相关文章
- B+Tree和MySQL索引分析
首先区分两组概念: 稠密索引,稀疏索引: 聚簇索引,非聚簇索引: btree和mysql的分析: 参见 http://blog.csdn.net/hguisu/article/details/7786 ...
- Mysql索引分析:适合建索引?不适合建索引?【转】
数据库建立索引常用的规则如下: 1.表的主键.外键必须有索引: 2.数据量超过300的表应该有索引: 3.经常与其他表进行连接的表,在连接字段上应该建立索引: 4.经常出现在Where子句中的字段,特 ...
- MySQL索引分析
索引的出现解决数据量上升导致查询越来越慢的问题,优化数据的查询,提高查询的速度. 索引 定义: 通过各种数据结构实现的值到行位置的映射.快速定位与访问特定的数据. 作用: 提高访问速度 实现主键.唯一 ...
- MySQL 索引分析
MySQL复合唯一索引分析 关于复合唯一索引(unique key 或 unique index),网上搜索不少人说:"这种索引起到的关键作用是约束,查询时性能上没有得到提高或者查询时根本没 ...
- MySQL索引分析与优化
1.MySQL能够在name的索引中查找“Mike”值,然后直接转到数据文件中相应的行,准确地返回该行的 peopleid(999).在这个过程中,MySQL只需处理一个行就可以返回结果.如果没有“n ...
- MySql索引分析及查询优化
B-Tree 核心特点: 多路,非二叉树 每个节点既保存索引,又保存数据 搜索时相当于二分查找 B+Tree 核心特点 多路非二叉 只有叶子节点保存数据 搜索时相当于二分查找 增加了相邻接点的指向指针 ...
- MySQL索引 专题
什么是索引 索引是存储引擎用于快速找到记录的一种数据结构,索引类似一本书的目录,我们可以快速的根据目录查找到我们想要的内容的所在页码,索引的优化应该是对查询性能优化最有效的手段了. 因此,首先你要明白 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- 深入浅出分析MySQL索引设计背后的数据结构
在我们公司的DB规范中,明确规定: 1.建表语句必须明确指定主键 2.无特殊情况,主键必须单调递增 对于这项规定,很多研发小伙伴不理解.本文就来深入简出地分析MySQL索引设计背后的数据结构和算法,从 ...
随机推荐
- Laravel Event的分析和使用
Laravel Event的分析和使用 第一部分 概念解释 请自行查看观察者模式 第二部分 源码分析 (逻辑较长,不喜欢追代码可以直接看使用部分) 第三部分 使用 第一部分 解释 当一个用户阅读了一篇 ...
- java泛型之通配符?
一.在说泛型通配符" ?" 之前先讲几个概念 1.里氏替换原则(Liskov Substitution Principle, LSP): 定义:所有引用基类(父类)的地方必须能透明 ...
- Python字符编码和二进制不得不说的故事
二进制 核心思想: 冯诺依曼 + 图灵机 电如何表示状态,才能稳定? 计算机开始设计的时候并不是考虑简单,而是考虑能自动完成任务与结果的可靠性, 简单始终是建立再稳定.可靠基础上 经过尝试10进制,但 ...
- 硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析
背景 Apache Pulsar 是下一代分布式消息流平台,采用计算存储分层架构,具备多租户.高一致.高性能.百万 topic.数据平滑迁移等诸多优势.越来越多的企业正在使用 Pulsar 或者尝试将 ...
- 030 01 Android 零基础入门 01 Java基础语法 03 Java运算符 10 条件运算符
030 01 Android 零基础入门 01 Java基础语法 03 Java运算符 10 条件运算符 本文知识点:Java中的条件运算符 条件运算符是Java当中唯一一个三目运算符 什么是三目运算 ...
- python中def用法
转载:https://blog.csdn.net/qq_21466543/article/details/81604826 一.函数调用的含义 函数是类似于可封装的程序片段.允许你给一块语句一个名字, ...
- Java基础系列-RandomAccess
原创文章,转载请标注出处:https://www.cnblogs.com/V1haoge/p/10755424.html Random是随机的意思,Access是访问的意思,合起来就是随机访问的意思. ...
- 翻了翻element-ui源码,发现一个很实用的指令clickoutside
前言 指令(directive)在 vue 开发中是一项很实用的功能,指令可以绑定到某一元素或组件,使功能的颗粒度更精细.今天在翻 element-ui 的源码时,发现一个还挺实用的工具指令,跟大伙分 ...
- 《New Horizon College English》2--长篇阅读技能指南
<New Horizon College English>2--长篇阅读技能指南 <长篇阅读>目的是提升学生的英语阅读技能和限时获取信息的能力.<长篇阅读>共四级, ...
- shell-变量的数值运算符-计算双括号(())的使用
1. 变量的数值计算 变量的数值计算常见的如下几个命令: (()).let.expr.bc.$[] 1) (())用法:(此法很常用,且效率高) 执行简单的整数运算,只需将特定的算术表达式用 &qu ...