别走!这里有个笔记:图文讲解 AQS ,一起看看 AQS 的源码……(图文较长)
前言
AbstractQueuedSynchronizer 抽象队列同步器,简称 AQS 。是在 JUC 包下面一个非常重要的基础组件,JUC 包下面的并发锁
ReentrantLockCountDownLatch等都是基于 AQS 实现的。所以想进一步研究锁的底层原理,非常有必要先了解 AQS 的原理。公众号:liuzhihangs,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
介绍
先看下 AQS 的类图结构,以及源码注释,有一定的大概了解之后再从源码入手,一步一步研究它的底层原理。
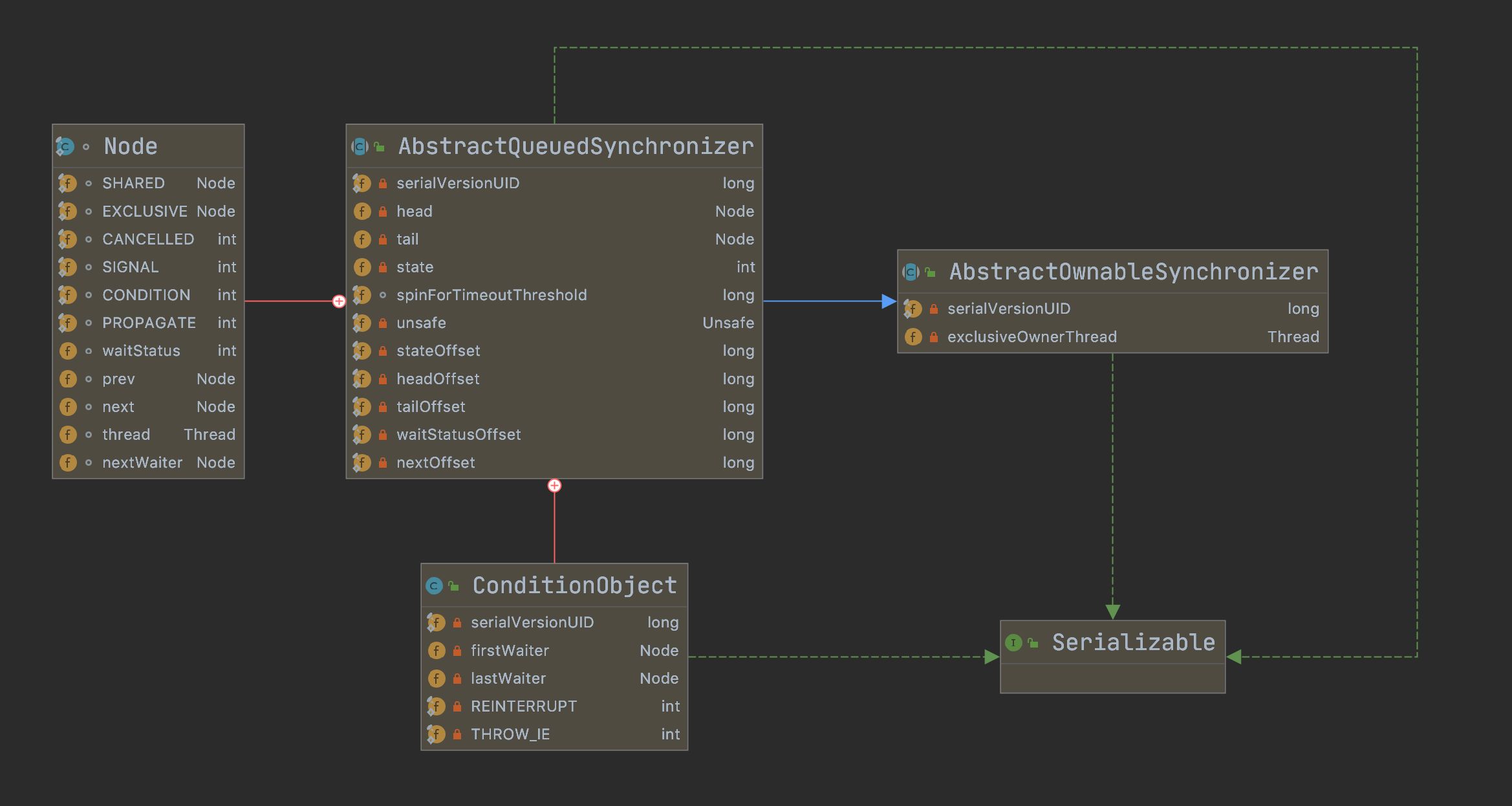
" 源码注释
提供了实现阻塞锁和相关同步器依靠先入先出(FIFO)等待队列(信号量,事件等)的框架。 此类中设计了一个对大多数基于 AQS 的同步器有用的原子变量来表示状态(state)。 子类必须定义 protected 方法来修改这个 state,并且定义 state 值在对象中的具体含义是 acquired 或 released。 考虑到这些,在这个类中的其他方法可以实现所有排队和阻塞机制。 子类可以保持其他状态字段,但只能使用方法 getState 、setState 和 compareAndSetState 以原子方式更新 state 。
子类应被定义为用于实现其封闭类的同步性能的非公共内部辅助类。 类AbstractQueuedSynchronizer没有实现任何同步接口。 相反,它定义了一些方法,如 acquireInterruptibly 可以通过具体的锁和相关同步器来调用适当履行其公共方法。
此类支持独占模式和共享模式。 在独占模式下,其他线程不能获取成功,共享模式下可以(但不一定)获取成功。 此类不“理解”,在机械意义上这些不同的是,当共享模式获取成功,则下一个等待的线程(如果存在)也必须确定它是否能够获取。 线程在不同模式下的等待共享相同的FIFO队列。 通常情况下,实现子类只支持其中一种模式,但同时使用两种模式也可以,例如ReadWriteLock 。 仅共享模式不需要定义支持未使用的模式的方法的子类。
这个类中定义了嵌套类 AbstractQueuedSynchronizer.ConditionObject ,可用于作为一个 Condition 由子类实现,并使用 isHeldExclusively 方法说明当前线程是否以独占方式进行,release()、 getState() acquire() 方法用于操作 state 原子变量。
此类提供检查和监视内部队列的方法,以及类似方法的条件对象。 根据需要进使用以用于它们的同步机制。
要使用这个类用作同步的基础上,需要重新定义以下方法,如使用,通过检查和或修改 getState 、setState 或 compareAndSetState 方法:
tryAcquire
tryRelease
tryAcquireShared
tryReleaseShared
isHeldExclusively
"
通过上面的注释可以得出大概的印象:
- 内部依靠先入先出(FIFO) 等待队列。
- 存在 state 表示状态信息。state 值只能用 getState 、setState 和 compareAndSetState 方法以原子方式更新。
- 支持独占模式和共享模式,但具体需要子类实现具体支持哪种模式。
- 嵌套 AbstractQueuedSynchronizer.ConditionObject 可以作为 Condition 由子类实现。
- 子类需要重新定义 tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared、isHeldExclusively 方法。
队列节点 Node
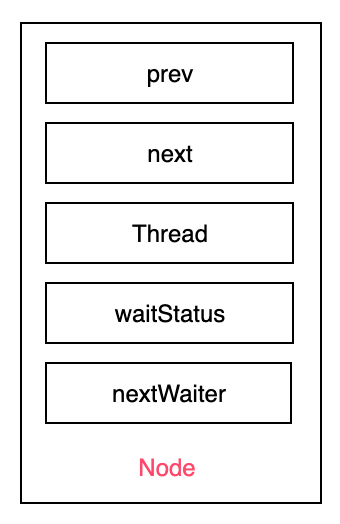
Node节点,包含以下元素:
| 元素 | 含义 |
|---|---|
| prev | 上一个节点 |
| next | 下一个节点 |
| thread | 持有线程 |
| waitStatus | 节点状态 |
| nextWaiter | 下一个处于 CONDITION 状态的节点 |
组合成等待队列则如下:
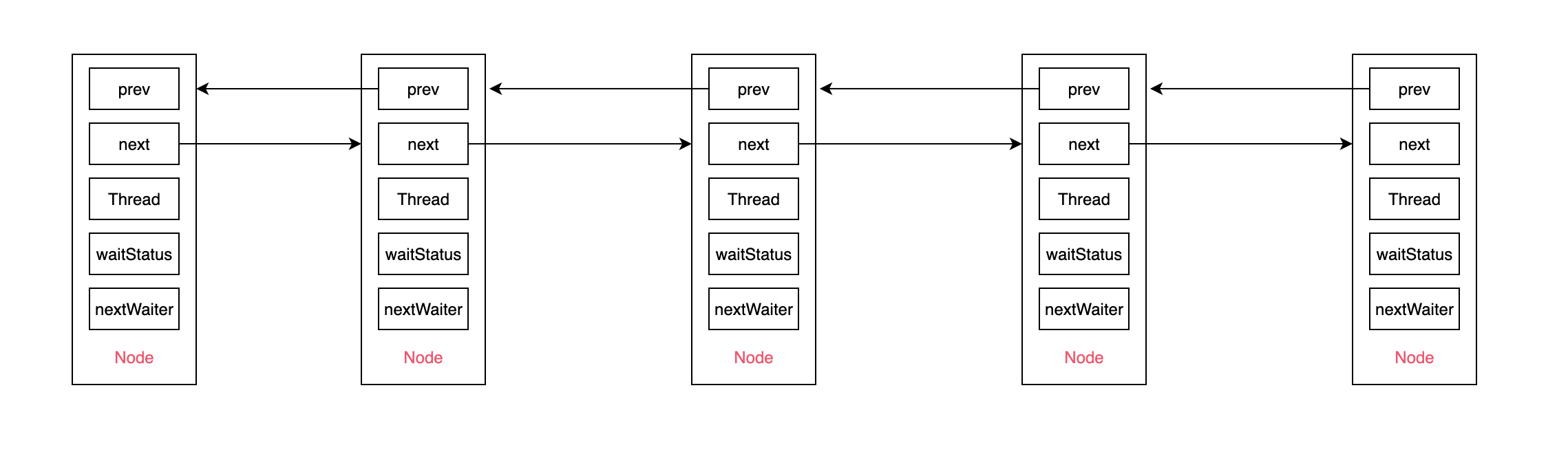
下面是等待队列节点的 Node 属性:
static final class Node {
// 节点正在共享模式下等待的标记
static final Node SHARED = new Node();
// 指示节点正在以独占模式等待的标记
static final Node EXCLUSIVE = null;
// 指示线程已取消
static final int CANCELLED = 1;
// 指示后续线程需要唤醒
static final int SIGNAL = -1;
// 指示线程正在等待条件
static final int CONDITION = -2;
// 指示下一次acquireShared应该无条件传播
static final int PROPAGATE = -3;
/**
* 状态字段,仅使用以下值
* SIGNAL -1 :当前节点释放或者取消时,必须 unpark 他的后续节点。
* CANCELLED 1 :由于超时(timeout)或中断(interrupt),该节点被取消。节点永远不会离开此状态。特别是,具有取消节点的线程永远不会再次阻塞。
* CONDITION -2 :该节点目前在条件队列。 但它不会被用作同步队列节点,直到转移,转移时的状态将被设置为 0 。
* PROPAGATE -3 :releaseShared 应该被传播到其他节点。
* 0:都不是
* 值以数字表示以简化使用,大多数时候可以检查符号(是否大于0)以简化使用
*/
volatile int waitStatus;
// 上一个节点
volatile Node prev;
// 下一个节点
volatile Node next;
// 节点持有线程
volatile Thread thread;
// 链接下一个等待条件节点,或特殊值共享
Node nextWaiter;
// 节点是否处于 共享状态 是, 返回 true
final boolean isShared() {
return nextWaiter == SHARED;
}
// 返回前一个节点, 使用时 前一个节点不能为空
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
在 Node 节点中需要重点关注 waitStatus
- 默认状态为 0;
- waitStatus > 0 (CANCELLED 1) 说明该节点超时或者中断了,需要从队列中移除;
- waitStatus = -1 SIGNAL 当前线程的前一个节点的状态为 SIGNAL,则当前线程需要阻塞(unpark);
- waitStatus = -2 CONDITION -2 :该节点目前在条件队列;
- waitStatus = -3 PROPAGATE -3 :releaseShared 应该被传播到其他节点,在共享锁模式下使用。
了解完 Node 的结构之后,再了解下 AQS 结构,并从常用方法入手,逐步了解具体实现逻辑。
AbstractQueuedSynchronizer
public abstract class AbstractQueuedSynchronizer extends AbstractOwnableSynchronizer implements java.io.Serializable {
// 等待队列的头,延迟初始化。 除了初始化,它是仅经由方法setHead修改。 注意:如果头存在,其waitStatus保证不会是 CANCELLED 状态
private transient volatile Node head;
// 等待队列的尾部,延迟初始化。 仅在修改通过方法ENQ添加新节点等待。
private transient volatile Node tail;
// 同步状态
private volatile int state;
// 获取状态
protected final int getState() {
return state;
}
// 设置状态值
protected final void setState(int newState) {
state = newState;
}
// 原子更新状态值
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
}
在 AQS 中主要参数为:
| 参数 | 含义 |
|---|---|
| head | 等待队列头 |
| tail | 等待队列尾 |
| state | 同步状态 |
通过注释了解到,在 AQS 里主要分为两种操作模式,分别是:独占模式、共享模式,下面分别从两个不同的角度去分析源码。
| 操作 | 含义 |
|---|---|
| acquire | 以独占模式获取,忽略中断。 通过调用至少一次实施tryAcquire ,在成功时返回。 否则,线程排队,可能重复查封和解封,调用tryAcquire直到成功为止。 这种方法可以用来实现方法Lock.lock 。 |
| release | 以独占模式释放。 通过疏通一个或多个线程,如果实现tryRelease返回true。 这种方法可以用来实现方法Lock.unlock 。 |
| acquireShared | 获取在共享模式下,忽略中断。 通过至少一次第一调用实现tryAcquireShared ,在成功时返回。 否则,线程排队,可能重复查封和解封,调用tryAcquireShared直到成功为止。 |
| releaseShared | 以共享模式释放。 通过疏通一个或多个线程,如果实现tryReleaseShared返回true。 |
无论是共享模式还是独占模式在这里面都会用到 addWaiter 方法,将当前线程及模式创建排队节点。
独占模式
获取独占资源 acquire
public final void acquire(int arg) {
// tryAcquire 尝试获取 state,获取失败则会加入到队列
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
在独占模式下会尝试获取 state,当获取失败时会调用 acquireQueued(addWaiter(Node.EXCLUSIVE), arg)。
- tryAcquire(arg),尝试获取 state 这块由子类自己实现,不同的子类逻辑不同,这块在介绍子类代码时会说明。
- 获取 state 失败后,会进行 acquireQueued(addWaiter(Node.EXCLUSIVE), arg),这块代码可以拆分为两块:addWaiter(Node.EXCLUSIVE),acquireQueued(node, arg)。
- addWaiter(Node.EXCLUSIVE) 返回的是当前新创建的节点。
- acquireQueued(node, arg) 线程获取锁失败,使用 addWaiter(Node.EXCLUSIVE) 放入等待队列,而 acquireQueued(node, arg) 使用循环,不断的为队列中的节点去尝试获取资源,直到获取成功或者被中断。
总结获取资源主要分为三步:
- 尝试获取资源
- 入队列
- 出队列
尝试获取资源 tryAcquire(arg),由子类实现,那下面则着手分别分析 入队列、出队列。
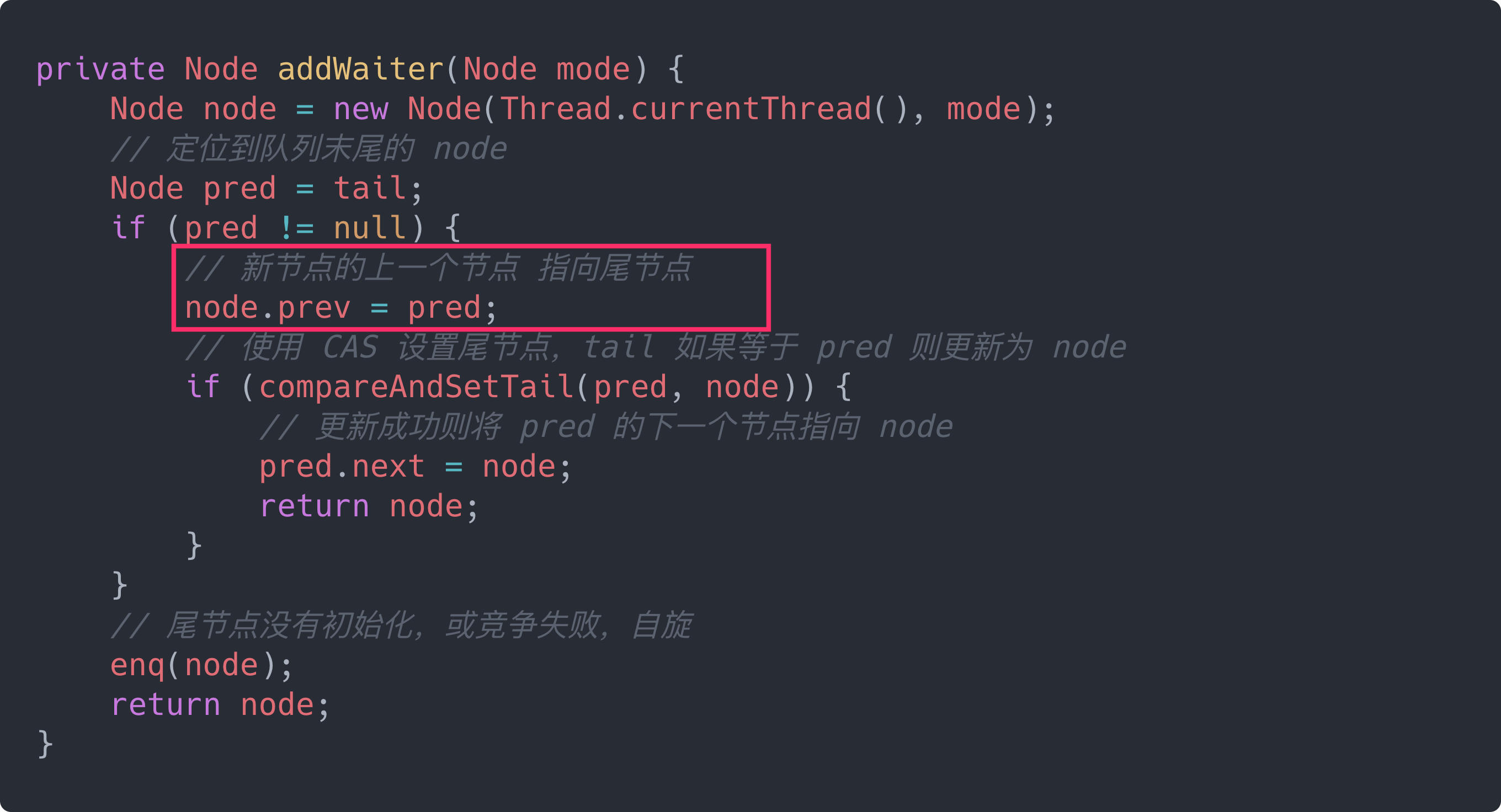
入队列:addWaiter(Node.EXCLUSIVE)
使用 addWaiter(Node.EXCLUSIVE) 方法将节点插入到队列中,步骤如下:
- 根据传入的模式创建节点
- 判断尾节点是否存在,不存在则需要使用
enq(node)方法初始化节点,存在则直接尝试插入尾部。 尝试插入尾部时使用 CAS 插入,防止并发情况,如果插入失败,会调用enq(node)自旋直到插入。
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// 定位到队列末尾的 node
Node pred = tail;
if (pred != null) {
// 新节点的上一个节点 指向尾节点
node.prev = pred;
// 使用 CAS 设置尾节点,tail 如果等于 pred 则更新为 node
if (compareAndSetTail(pred, node)) {
// 更新成功则将 pred 的下一个节点指向 node
pred.next = node;
return node;
}
}
// 尾节点没有初始化,或竞争失败,自旋
enq(node);
return node;
}
/**
* tailOffset 也就是成员变量 tail 的值
* 此处相当于:比较 tail 的值和 expect 的值是否相等, 相等则更新为 update
*/
private final boolean compareAndSetTail(Node expect, Node update) {
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
}
private final boolean compareAndSetHead(Node update) {
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 尾节点为空 需要初始化头节点,此时头尾节点是一个
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 不为空 循环赋值
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
看完代码和注释肯定还是有点模糊,现在用图一步一步进行说明。
因为根据初始尾节点是否为空分为两种情况,这里使用两幅图:
- 第一幅为第一次添加节点,此时 head 会延迟初始化;
- 第二幅图为已经存在队列,进行插入节点;
- 注意看代码,enq 方法返回的是
之前的尾节点; - addWaiter 方法 返回的是
当前插入的新创建的节点。
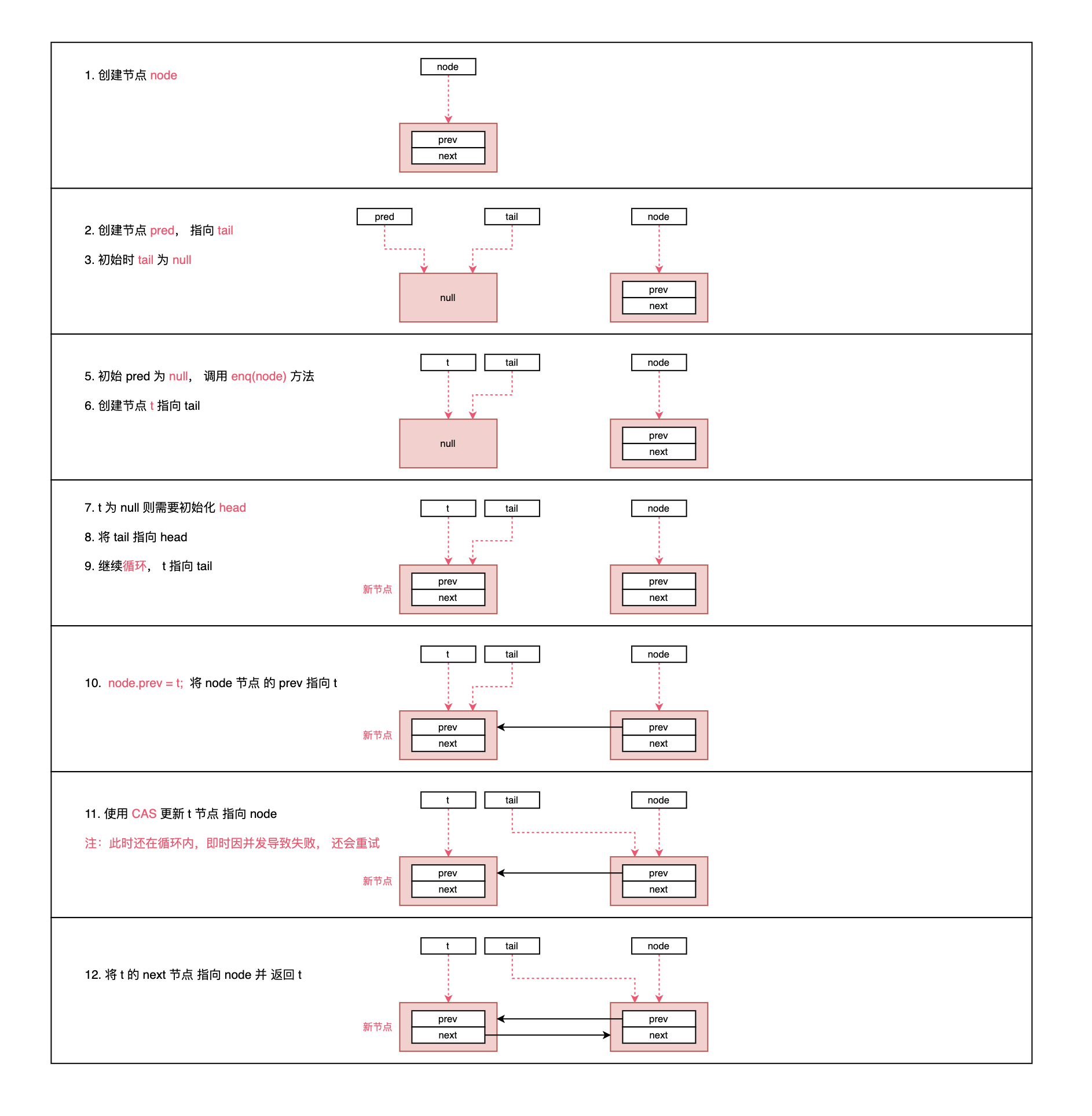
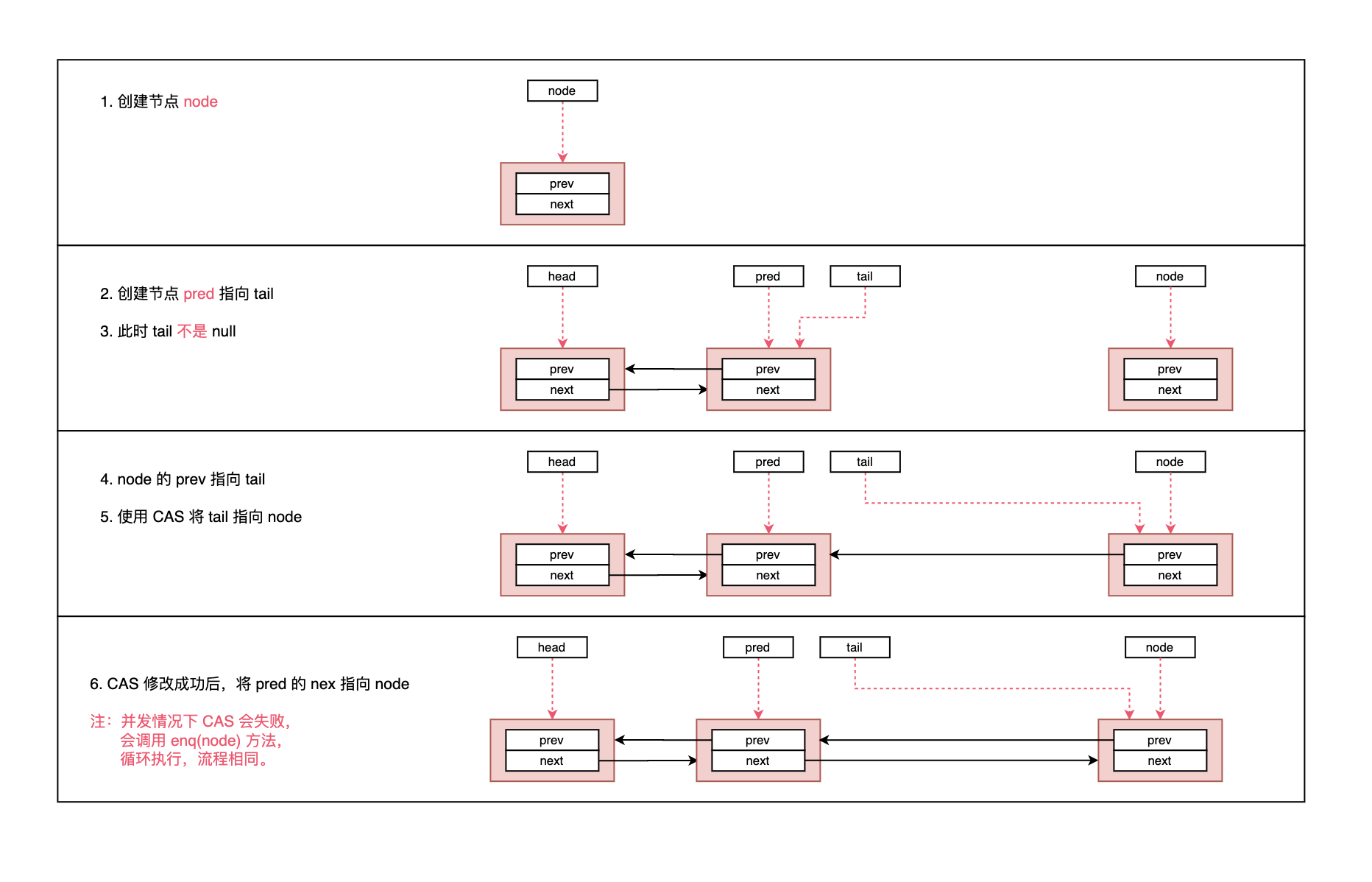
节点添加到队列之后,返回当前节点,而下一步则需要调用方法 acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 不断的去获取资源。
出队列:acquireQueued(addWaiter(Node.EXCLUSIVE), arg)
方法会通过循环不断尝试获取拿到资源,直到成功。代码如下:
final boolean acquireQueued(final Node node, int arg) {
// 是否拿到资源
boolean failed = true;
try {
// 中断状态
boolean interrupted = false;
// 无限循环
for (;;) {
// 当前节点之前的节点
final Node p = node.predecessor();
// 前一个节点是头节点, 说明当前节点是 头节点的 next 即真实的第一个数据节点 (因为 head 是虚拟节点)
// 然后再尝试获取资源
if (p == head && tryAcquire(arg)) {
// 获取成功之后 将头指针指向当前节点
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// p 不是头节点, 或者 头节点未能获取到资源 (非公平情况下被别的节点抢占)
// 判断 node 是否要被阻塞,
if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
- 不断获取本节点的上一个节点是否为 head,因为 head 是虚拟节点,如果当前节点的上一个节点是 head 节点,则当前节点为
第一个数据节点; - 第一个数据节点不断的去获取资源,获取成功,则将 head 指向当前节点;
- 当前节点不是头节点,或者
tryAcquire(arg)失败(失败可能是非公平锁)。这时候需要判断前一个节点状态决定当前节点是否要被阻塞(前一个节点状态是否为 SIGNAL)。
/**
* 根据上一个节点的状态,判断当前线程是否应该被阻塞
* SIGNAL -1 :当前节点释放或者取消时,必须 unpark 他的后续节点。
* CANCELLED 1 :由于超时(timeout)或中断(interrupt),该节点被取消。节点永远不会离开此状态。特别是,具有取消节点的线程永远不会再次阻塞。
* CONDITION -2 :该节点目前在条件队列。 但它不会被用作同步队列节点,直到转移,转移时的状态将被设置为 0 。
* PROPAGATE -3 :releaseShared 应该被传播到其他节点。
* 0:都不是
*
*/
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 前一个节点的等待状态
int ws = pred.waitStatus;
// 前一个节点需要 unpark 后续节点
if (ws == Node.SIGNAL)
return true;
// 当前节点处于取消状态
if (ws > 0) {
do {
// 将取消的节点从队列中移除
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 设置前一个节点为 SIGNAL 状态
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
在 shouldParkAfterFailedAcquire 方法中,会判断前一个节点的状态,同时取消在队列中当前节点前面无效的节点。
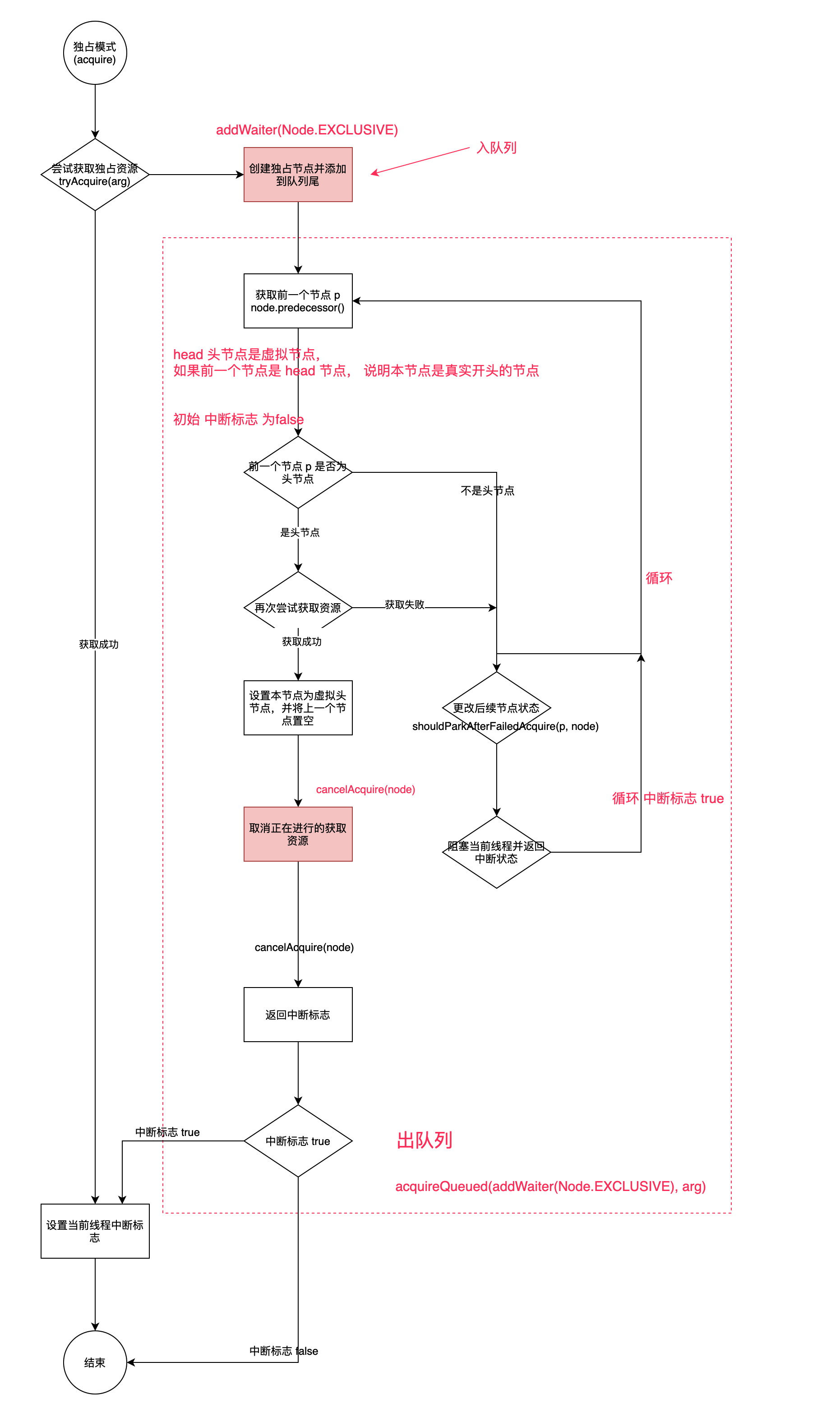
再继续阅读 出队列 acquireQueued 方法,发现有一个 finally 会判断状态后执行 cancelAcquire(node); ,也就是上面流程图中下面的红色方块。
cancelAcquire(Node node)
final boolean acquireQueued(final Node node, int arg) {
// 是否拿到资源
boolean failed = true;
try {
// 省略
// 在 finally 会将当前节点置为取消状态
} finally {
if (failed)
cancelAcquire(node);
}
}
private void cancelAcquire(Node node) {
// 节点不存在 直接返回
if (node == null)
return;
// 取消节点关联线程
node.thread = null;
//跳过已经取消的节点,获取当前节点之前的有效节点
Node pred = node.prev;
while (pred.waitStatus > 0)
node.prev = pred = pred.prev;
// 获取当前节点之前的有效节点的下一个节点
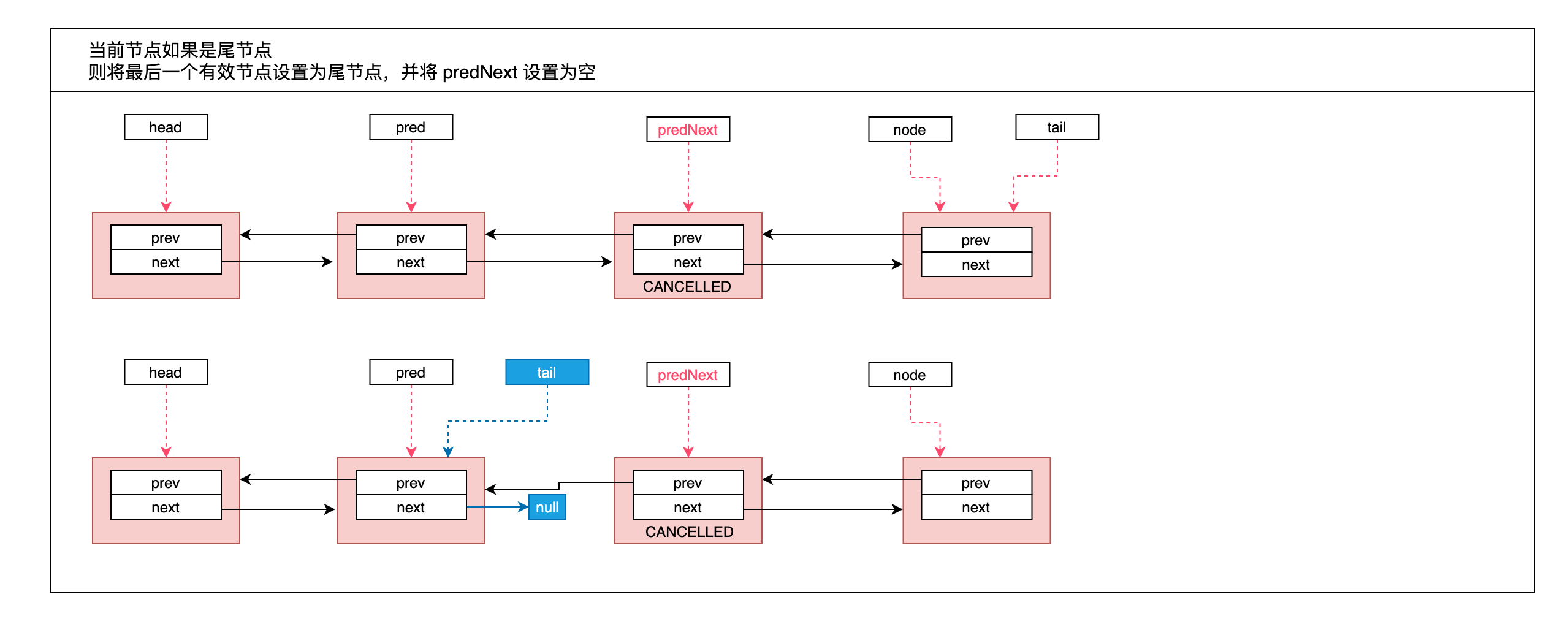
Node predNext = pred.next;
// 当前节点设置为取消
node.waitStatus = Node.CANCELLED;
// 当前节点如果是尾节点,则将最后一个有效节点设置为尾节点,并将 predNext 设置为空
if (node == tail && compareAndSetTail(node, pred)) {
compareAndSetNext(pred, predNext, null);
} else {
int ws;
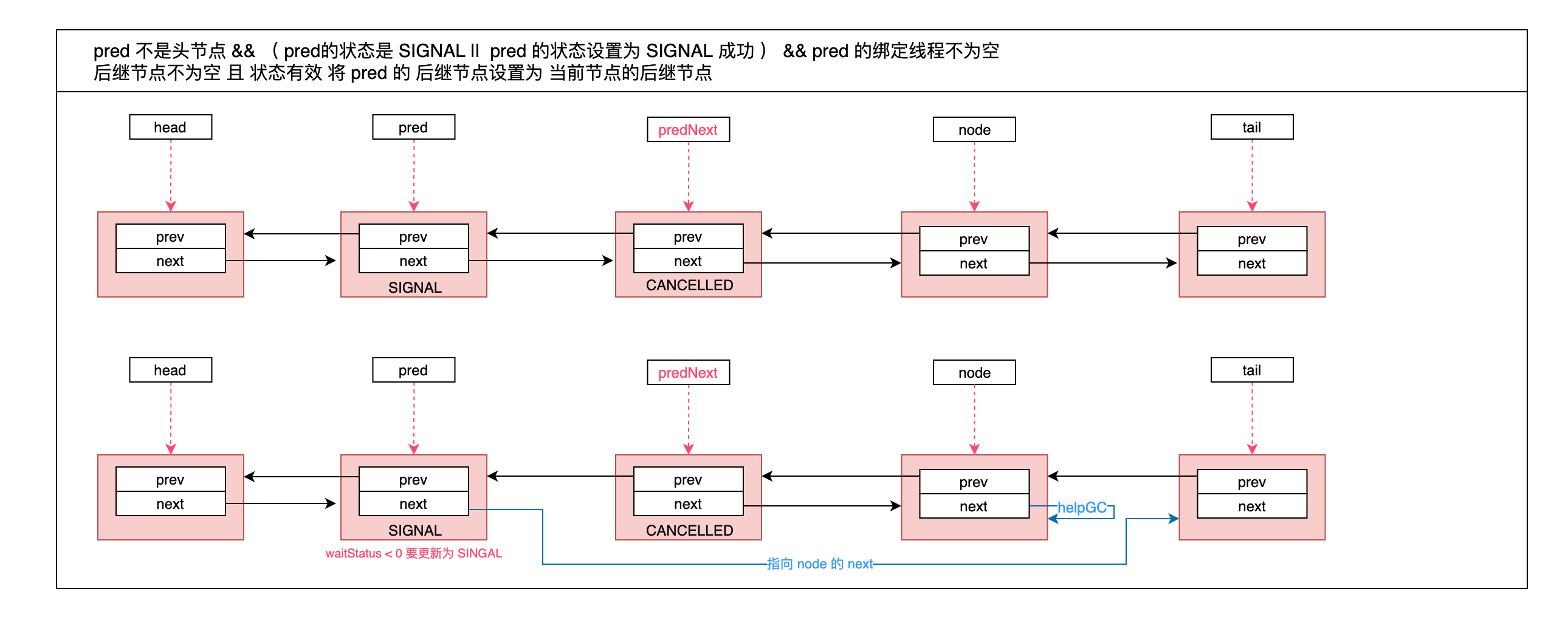
// pred 不是头节点(node 的上一个有效节点 不是 head) && ( pred的状态是 SIGNAL || pred 的状态设置为 SIGNAL 成功 ) && pred 的绑定线程不为空
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
// 当前节点的后继节点
Node next = node.next;
// 后继节点不为空 且 状态有效 将 pred 的 后继节点设置为 当前节点的后继节点
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// node 的上一个有效节点 是 head, 或者其他情况 唤醒当前节点的下一个有效节点
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
private void unparkSuccessor(Node node) {
// 判断当前节点状态
int ws = node.waitStatus;
if (ws < 0)
// 将节点状态更新为 0
compareAndSetWaitStatus(node, ws, 0);
// 下一个节点, 一般是下一个节点应该就是需要唤醒的节点,即颁发证书。
Node s = node.next;
// 大于 0 CANCELLED : 线程已取消
// 但是有可能 后继节点 为空或者被取消了。
if (s == null || s.waitStatus > 0) {
s = null;
// 从尾节点开始遍历,直到定位到 t.waitStatus <= 0 的节点
// 定位到后并不会停止,会继续执行,相当于找到最开始的那个需要唤醒的节点
// t.waitStatus <= 0 : SIGNAL( -1 后续线程需要释放)
// CONDITION ( -2 线程正在等待条件)
// PROPAGATE ( -3 releaseShared 应该被传播到其他节点)
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 定位到需要唤醒的节点后 进行 unpark
if (s != null)
LockSupport.unpark(s.thread);
}
流程分析:
- 找到当前节点的前一个非无效节点 pred;
- 当前节点如果是尾节点,则将最后一个有效节点设置为尾节点,并将 predNext 设置为空;
- pred 不是头节点 && ( pred的状态是 SIGNAL || pred 的状态设置为 SIGNAL 成功 ) && pred 的绑定线程不为空;
- 其他情况。
下面分别画图:
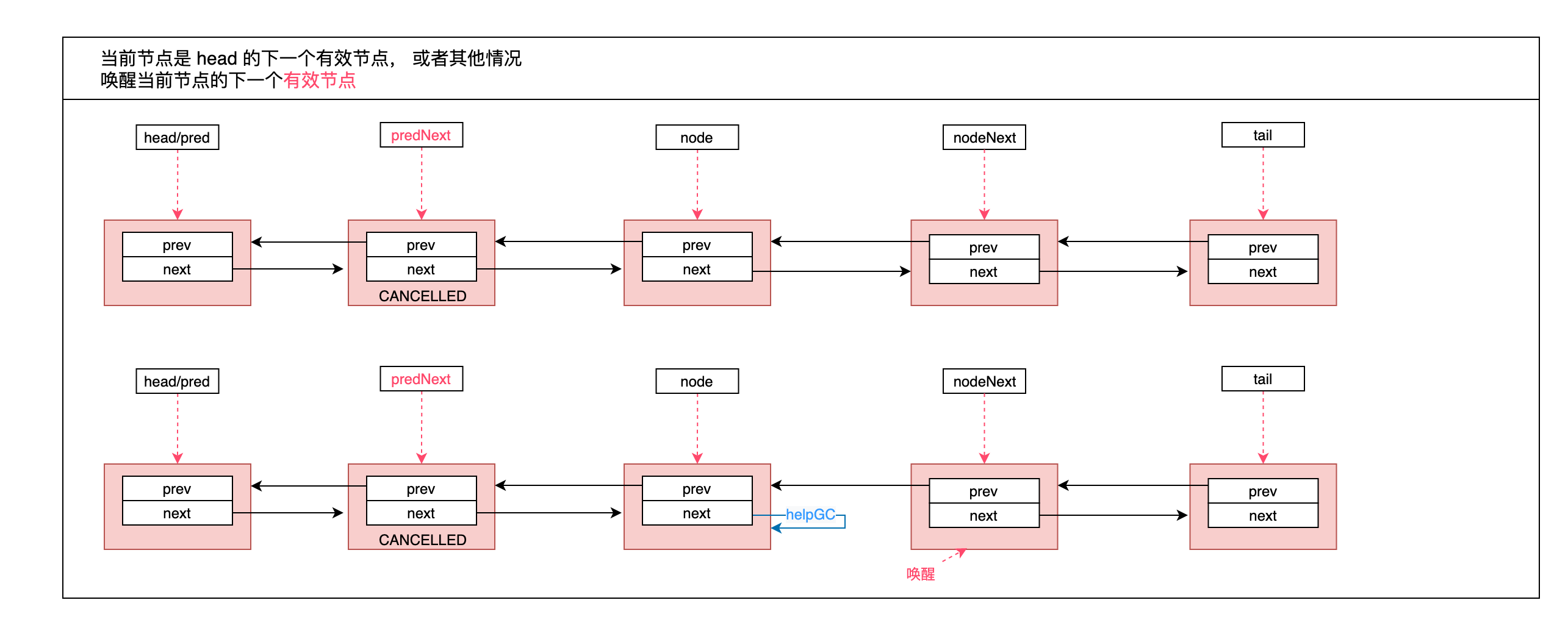
Q: 通过图可以看出来,只操作了 next 指针,但是没有操作 prev 指针,这是为什么呢?
A: 在 出队列:acquireQueued(addWaiter(Node.EXCLUSIVE), arg) 方法中,shouldParkAfterFailedAcquire 方法会判断前一个节点的状态,同时取消在队列中当前节点前面无效的节点。这时候会移除之前的无效节点,此处也是为了防止指向一个已经被移除的节点。同时保证 prev 的稳定,有利于从 tail 开始遍历列表,这块在 unparkSuccessor(node); 中也可以看到是从后往前表里列表。
Q: unparkSuccessor(Node node) 为什么从后往前遍历?
A:
在 addWaiter(Node.EXCLUSIVE) 插入新节点时,使用的是 尾插法,看红框部分,此时有可能还未指向next。
Q: node.next = node; 这块导致 head不是指向最新节点,链表不就断了么?
A: acquireQueued 方法介绍中,里面有个循环,会不断尝试获取资源,成功之后会设置为 head。并且在 shouldParkAfterFailedAcquire 中也会清除当前节点前的无效节点。
释放独占资源 release
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
以独占模式释放。 通过释放一个或多个线程,如果实现tryRelease返回true。 这种方法可以用来实现方法Lock.unlock 。
- tryRelease(arg) 操作释放资源,同样是由子类实现,后面介绍子类时会进行说明。返回 true 说明资源现在已经没有线程持有了,其他节点可以尝试获取;
- 释放成功,且 head != null && h.waitStatus != 0, 会继续执行 unparkSuccessor(h);
- 这块会看到 只要 tryRelease(arg) 操作释放资源成功, 后面无论执行是否成功,都会返回 true,unparkSuccessor(h) 相当于只是附加操作。
共享模式
获取共享资源 acquireShared
public final void acquireShared(int arg) {
// 小于 0 表示获取资源失败
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
// 添加到节点 此处是共享节点
final Node node = addWaiter(Node.SHARED);
// 根据是否拿到资源 判断是否需要取消
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 返回前一个节点
final Node p = node.predecessor();
if (p == head) {
// 再次尝试获取共享资源
int r = tryAcquireShared(arg);
// 表示获取成功
if (r >= 0) {
// 设置当前节点为头节点 并尝试唤醒后续节点
setHeadAndPropagate(node, r);
// 释放头节点 GC 会回收
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
- tryAcquireShared(arg),尝试获取资源,这块由子类实现;
- 返回值分为 3 种:
- 小于 0: 表示失败;
- 等于 0: 表示共享模式获取资源成功,但后续的节点不能以共享模式获取成功;
- 大于 0: 表示共享模式获取资源成功,后续节点在共享模式获取也可能会成功,在这种情况下,后续等待线程必须检查可用性。
- 在失败后会使用
doAcquireShared(arg);不断获取资源; final Node node = addWaiter(Node.SHARED);同样会创建节点;- 在循环中不断判断前一个节点如果是 head,则尝试获取资源;
- 在共享模式下获取到资源后会使用
setHeadAndPropagate(node, r);设置头节点,同时唤醒后续节点。
设置头节点,并传播唤醒后续节点
// node 是当前节点
// propagate 是 前一步 tryAcquireShared 的返回值 进来时 >=0
// 大于 0: 表示共享模式获取资源成功,后续节点在共享模式获取也可能会成功,在这种情况下,后续等待线程必须检查可用性。
private void setHeadAndPropagate(Node node, int propagate) {
// 记录下当前头节点
Node h = head; // Record old head for check below
// 设置传入 node 为头节点
setHead(node);
// 判断条件,唤醒后续节点
// propagate > 0 有后续资源
// h == null 旧的头节点 因为前面 addWaiter, 肯定不会为空,应该是防止 h.waitStatus < 0 空指针的写法
// (h = head) == null 当前的 头节点,再判断状态
// waitStatus < 0 后续节点就需要被唤醒
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
// 后续节点为共享,则需要唤醒
if (s == null || s.isShared())
doReleaseShared();
}
}
doReleaseShared() 释放共享资源
private void doReleaseShared() {
// 循环
for (;;) {
// 从头开始
Node h = head;
// 判断队列是否为空,就是刚初始化
if (h != null && h != tail) {
int ws = h.waitStatus;
// SIGNAL( -1 后续线程需要释放)
if (ws == Node.SIGNAL) {
// 将等待状态更新为 0 如果失败,会循环
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
// 唤醒后续节点, 同时将当前节点设置为 取消
unparkSuccessor(h);
}
// 如果状态是 0 则会更新状态为 PROPAGATE
// PROPAGATE ( -3 releaseShared 应该被传播到其他节点)
else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
// 判断头节点有没有变化,有变化 是因为竞争,别的线程获取到了锁,会继续循环
// 没有变化直接结束
if (h == head) // loop if head changed
break;
}
}
- 从头节点开始进行,如果 h != null && h != tail 说明队列不是空或者刚初始化;
- 节点状态为 SIGNAL( -1 )说明后续线程需要释放;
- 会更改当前节点状态,成功后唤醒后续节点,失败则继续循环;
- 节点状态如果是 0 则更新为 PROPAGATE,会将状态传播。
释放共享资源 releaseShared
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {
// 释放共享资源
doReleaseShared();
return true;
}
return false;
}
以共享模式释放。 通过释放一个或多个线程,如果实现tryReleaseShared返回true。
总结
Q: AQS 到底是什么?
A: AQS 内部提供了一个先入先出(FIFO)双向等待队列,内部依靠 Node 实现,并提供了在独占模式和共享模式下的出入队列的公共方法。而关于状态信息 state 的定义是由子类实现。tryAcquire、tryRelease、tryAcquireShared、tryReleaseShared等尝试获取资源操作都是由子类进行定义和实现的。而 AQS 中提供了子类获取资源之后的相关操作,包括节点 Node 的出入队列,自旋获取资源等等。
Q: AQS 获取资源失败后会如何操作?
A: 线程获取资源失败后,会放到等待队列中,在队列中会不断尝试获取资源(自旋),说明线程只是进入等待状态,后面还是可以再次获取资源的。
Q: AQS 等待队列的数据结构是什么?
A: CLH变体的先入先出(FIFO)双向等待队列。(CLH锁是一个自旋锁。能确保无饥饿性。提供先来先服务的公平性。是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程仅仅在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。)
Q: AQS 等待队列中的节点如何获取获取和释放资源的?
A: 可以看下独占模式中的讲述过程,通过代码梳理。
本文分别从 独占模式 和 共享模式介绍的 AQS 基本逻辑,并通过源码和作图理解基本思路。但是并没有对需要子类实现的业务逻辑做介绍。这块会在后面介绍 ReentrantLock、CountDownLatch 等子类的时候做介绍。
别走!这里有个笔记:图文讲解 AQS ,一起看看 AQS 的源码……(图文较长)的更多相关文章
- 使用Xamarin开发手机聊天程序 -- 基础篇(大量图文讲解 step by step,附源码下载)
如果是.NET开发人员,想学习手机应用开发(Android和iOS),Xamarin 无疑是最好的选择,编写一次,即可发布到Android和iOS平台,真是利器中的利器啊!而且,Xamarin已经被微 ...
- 使用Xamarin开发即时通信系统 -- 基础篇(大量图文讲解 step by step,附源码下载)...
如果是.NET开发人员,想学习手机应用开发(Android和iOS),Xamarin 无疑是最好的选择,编写一次,即可发布到Android和iOS平台,真是利器中的利器啊!而且,Xamarin已经被微 ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- JUC同步器框架AbstractQueuedSynchronizer源码图文分析
JUC同步器框架AbstractQueuedSynchronizer源码图文分析 前提 Doug Lea大神在编写JUC(java.util.concurrent)包的时候引入了java.util.c ...
- [转]如何下载tizen源码(图文教程)?
http://blog.csdn.net/flydream0/article/details/8996654 当前tizen发布的最新源码版本是2.1,本文将以图文教程讲述如何下载tizen源码,关于 ...
- hadoop2.5.2学习及实践笔记(二)—— 编译源代码及导入源码至eclipse
生产环境中hadoop一般会选择64位版本,官方下载的hadoop安装包中的native库是32位的,因此运行64位版本时,需要自己编译64位的native库,并替换掉自带native库. 源码包下的 ...
- 6种基础排序算法java源码+图文解析[面试宝典]
一.概述 作为一个合格的程序员,算法是必备技能,特此总结6大基础算法.java版强烈推荐<算法第四版>非常适合入手,所有算法网上可以找到源码下载. PS:本文讲解算法分三步:1.思想2.图 ...
- js便签笔记(10) - 分享:json2.js源码解读笔记
1. 如何理解“json” 首先应该意识到,json是一种数据转换格式,既然是个“格式”,就是个抽象的东西.它不是js对象,也不是字符串,它只是一种格式,一种规定而已. 这个格式规定了如何将js对象转 ...
- js便签笔记(10) - 分享:json.js源码解读笔记
1. 如何理解“json” 首先应该意识到,json是一种数据转换格式,既然是个“格式”,就是个抽象的东西.它不是js对象,也不是字符串,它只是一种格式,一种规定而已. 这个格式规定了如何将js对象转 ...
随机推荐
- Linux知识点笔记
Linux启动脚本 rcS文件,rcS文件位于系统根目录下的"/etc/init.d"下. rcS文件本质是一个bash shell脚本,因此遵循bash脚本的语法规则. [1] ...
- 正睿十一A班模拟赛day1
估分:25+0+60=85 实际:25+0+60=85 T1: 就只会25的暴力 分治,到一个区间[l,r],cnt[i]表示i这个颜色在区间内的出现次数,从两头同时扫描,扫描到第一个cnt[i]小于 ...
- Python导入模块的几种方法
Python 模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python 代 ...
- 04 C语言基本语法
C语言的令牌 C 语言的程序代码由各种令牌组成,令牌可以是关键字.标识符.常量.字符串值,或者是一个符号.例如,下方的C语句包括5个令牌: printf("Hello, World! \n& ...
- error C2491: 不允许 dllimport 函数 的定义
转载:https://blog.csdn.net/gaofeidongdong/article/details/7781345 在工程属性中 预编译宏中加上 DLL_EXPORT为了减少使用dll时候 ...
- 动态枢轴网格使用MVC, AngularJS和WEB API 2
下载shanuAngularMVCPivotGridS.zip - 2.7 MB 介绍 在本文中,我们将详细介绍如何使用AngularJS创建一个简单的MVC Pivot HTML网格.在我之前的文章 ...
- Nuxt|Vue仿探探/陌陌卡片式滑动|vue仿Tinder拖拽翻牌效果
探探/Tinder是一个很火的陌生人社交App,趁着国庆假期闲暇时间倒腾了个Nuxt.js项目,项目中有个模块模仿探探滑动切换界面效果.支持左右拖拽滑动like和no like及滑动回弹效果. 一览效 ...
- 如何免费安装正版Adobe
现在正版的Adobe都非常的贵,如果你想不花钱又想下载正版的Adobe,那么就请花几分钟时间学习以下本篇博客,告诉你如何免费下载正版Adobe! [一定要读完,不要看到一半就以为教您下载的是付费版] ...
- intelliJ 软件项目打开运行
1.导入项目 2.首先更改数据库,找到application-dev.yml文件,更改数据源 3.配置tomcat端口 找到application.yml 文件 然后打开pom.xml 更改版本号 ...
- 多测师讲解python函数 _open_高级讲师肖sir
open()函数 #open() 函数用于打开一个文件,创建一个 file 对象 #Python open() 函数用于打开一个文件,并返回文件对象, # 在对文件进行处理过程都需要使用到这个函数,如 ...