Talk About AWS Aurora for MySQL max_connections parameter Calculation | 浅谈AWS Aurora for MySQL数据库中 max_connections参数的计算
1. The Problem | 现象
When connect to the product environment database of my company, the Navicat shows "Too many connections", that's because the concurrency reaches the connection upper threshold. I has planned to attach the Keepalive tag to the connection string for resolving, but found that would cause failure (can't connect to the database) since it isn't supported if .net core in Linux environment (Linux manages the TCP long connection by OS, therefore the MySQL.Data.dll can't handle it.)
在我试图用Navicat连接公司的生产库时,爆出了“Too many connections”的提示,原因是并发连接达到了上限,曾经尝试在connection string中增加Keepalive的标签,但也失败了(会导致连接不上数据库),主要原因是.net core在linux环境中使用连接字符串做Keepalive是不受支持的,Linux在操作系统级来管理TCP的长连接,导致MySQL.Data.dll不能从自身去解决这一问题。
2. The Consideration of AWS | AWS的考量
We may see the default value of max_connections in parameter group when using AWS Aurora for MySQL, that might be GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000}) for test environment and GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000}) for product environment typically.
在使用AWS Aurora for MySQL数据库时,我们可以看到在参数组中max_connections参数默认的值为:
GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})(测试环境)与GREATEST({log(DBInstanceClassMemory/805306368,2)*45},{log(DBInstanceClassMemory/8187281408,2)*1000})(生产环境)。
Actually it means as
实际上这表示的是如下的两个式子
\]
And
\]
What's the two constants meaning? and why presents by a logarithmic function? Let's see.
>为何定出这么两个常数,又为何使用对数函数来表示这个参数,我们来了解一下。
\]
\]
These two formulas follow a same form, i.e.:
这两个式子都遵循同一种基本形式,即:
\]
As you see, it's a logarithmic function, the coefficient k is used to amplify the result, and in logarithmic function, the antilogarithm is monotonically increasing when the base is given. Consider the C is a constant, it means the Memory Size M increasing would causes the connection capacity increasing, this point is well fit to our cognition.
这是个对数函数,系数k用于放大对数部分计算出的数值,而在对数部分,真数是单调递增的。同时考虑到C是常量,则意味着随着内存大小的增加,所允许的最大连接数也随之增加,这十分符合我们的经验认知。
And then let's check a particular value.
If M equals C, the antilogarithm is 1, and the result is 0 whatever the base and the coefficient is, compare to the value of C, it tells us the memory size must greater then 0.75GiB at least, the formula can make sense.
然后我们看一个特殊值的情况。
当M等于C时,真数为1,此时无论底数和系数是多少,算式结果都为0,也就是说,只有实例的内存量在768MB以上时,这个式子才具有意义。
Well, base on the above information we can figure out the function graph as follow:
据此我们可以得出如下函数图像:
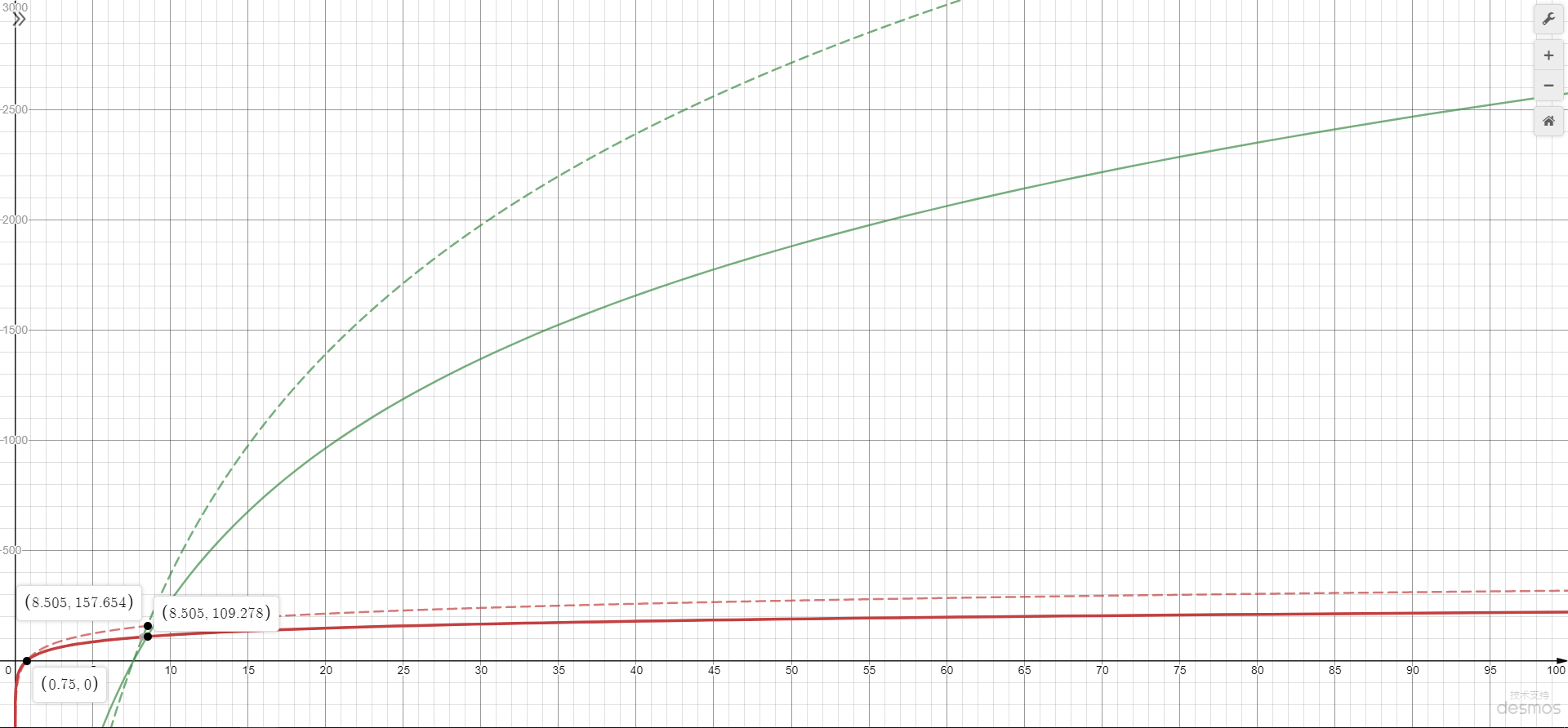
Fig.1 The Function Graph Corresponding to the Formula | 图1 AWS给出的计算公式对应的函数图象
The X-axis is memory size in GiB, and the Y-axis is the calculated max_connections by the formulas, the red line presents the cofficient is 45, and the green line presents the cofficient is 1000, the solid line presents the base is e(2.71828...) and the dash line presents the base is 2. Note that the formula indicates obtaining the relative large number as the result so we can only focus at the higher value in one of the line-type.
X轴是以GiB为单位的内存大小,Y轴是所支持的max_connection计算值;红色线是系数为45的式子,绿色线是系数为1000的式子;实线是底数为自然对数e的式子,虚线是底数为2的式子。留意在原式子中是取较大值作为结果的,所以我们只需要关注一种线性中较靠上(值较高)的部分。
Obviously either solid line or dash line they have an intersection which is on the memory size of 8.5GiB. It means that AWS considers about 8GiB memory is a threshold, when the memory size less than 8GiB and greater than 0.75GiB, the max_connection value just can float between 0 to 109 (e as base) and 0 to 157 (2 as base),
but once over the threshold, the max_connection increasing pretty fast follow the memory size incresing, when the memory size is made double to 16GiB, the max_connection reaches to approximate 750 and 1100 respectively.
Another inherent feature is, the increasing rate is decreased gradually when memory size is increasing linearly, this feature cause by the logarithmic formula.
显然地,无论实现还是虚线都有一个交点,交汇在内存大小大约为8.5GiB处。也就是说,AWS以大约8GiB内存作为运行的临界点,当内存大小小于8GiB但大于0.75GiB时,max_connection的值只介于0到109(以e为底数)和0到157(以2为底数)之间,而一旦内存大小超过8GiB,max_connection的值提升得相当快,当内存大小翻倍达到16GiB时,支持的max_connection就已经分别达到750和1100了。
另一个由对数函数带来的天然特性是,增长的速率会随内存大小的线性增长而逐渐降低。
## 3. The Caculation of Requirements | 需求的计算
How to determine a appropriate max_connection value? Is that AWS default policy suit for my situation?
>如何定出适当的max_connection值?AWS给出的默认方案适用于自己的情形吗?
A database typically loaded on a server instance and the server has its native upper limitation of memory size, a portion of memroy is supplied to databse using. And explore the MySQL running principle you may find that the MySQL requires a portion of memory for global running, as well as a portion of memory for query execution thread. Therefrom, each connection needs a certain size of memory. I.e.
\]
So,
\]
通常来说,数据库被一台服务器加载来运行,服务器的内存总量是有上限的,其中一部分内存被提供给数据库使用。再探索MySQL的运行原理,可以发现对于MySQL,一部分内存被用于全局运行,另一部分内存被用于查询的执行线程。故此,每一个连接都会造成使用了一定的内存,即:
\]
得:
\]
The Global Buffers include key_buffer_size, innodb_buffer_pool_size, innodb_log_buffer_size, innodb_additional_mem_pool_size, net_buffer_size, and query_cache_size. And the Thread Buffers include sort_buffer_size, myisam_sort_buffer_size, read_buffer_size, join_buffer_size, read_rnd_buffer_size, and thread_stack. All of the value can be checked by command:
全局缓冲区使用内存包括
key_buffer_size、innodb_buffer_pool_size、innodb_log_buffer_size、innodb_additional_mem_pool_size、net_buffer_size、query_cache_size。单线程缓冲区使用内存包括sort_buffer_size、myisam_sort_buffer_size、read_buffer_size、join_buffer_size、read_rnd_buffer_size、thread_stack。这些值可以用下面的命令获得:
SHOW VARIABLES
WHERE Variable_name LIKE '%buffer_size%'
OR Variable_name LIKE '%pool_size%'
OR Variable_name LIKE '%cache_size%'
OR Variable_name LIKE '%thread_stack%'
In my case, I obtain the values:
在我这边的服务器上,用了上述命令后得到:
| Variable | 变量 | Value | in MiB |
| ----- | ----- | ---- |
|key_buffer_size|16777216|16|
|innodb_buffer_pool_size|1586495488|1513|
|innodb_log_buffer_size|16777216|16|
|innodb_additional_mem_pool_size|N/A|N/A|
|net_buffer_size|N/A|N/A|
|query_cache_size|88158208|84|
|Global Buffers Total | 全局缓冲区使用内存总计|1708208128|1629|
||||
|sort_buffer_size|262144|0.25|
|myisam_sort_buffer_size|8388608|8|
|read_buffer_size|262144|0.25|
|join_buffer_size|262144|0.25|
|read_rnd_buffer_size|524288|0.5|
|thread_stack|262144|0.25|
|Thread Buffers Total | 单线程缓冲区使用内存总计|9961472|9.5|
I.e. each connection would use approximate 10MiB memory in default setting.
即,默认每个连接大约要使用10MiB的内存。
Refer to an actual situation, the following is the measuring of my server, the two lines present writer and reader (read-write separation), the Y-axis value presents free memory size, and each server has 4GiB memory in total.
参考实际情况,下图是我对我所使用的服务器的测定值,两根线分别表示了写入器和读取器,Y轴是空闲内存数量,每台服务器总共有4GiB的内存。
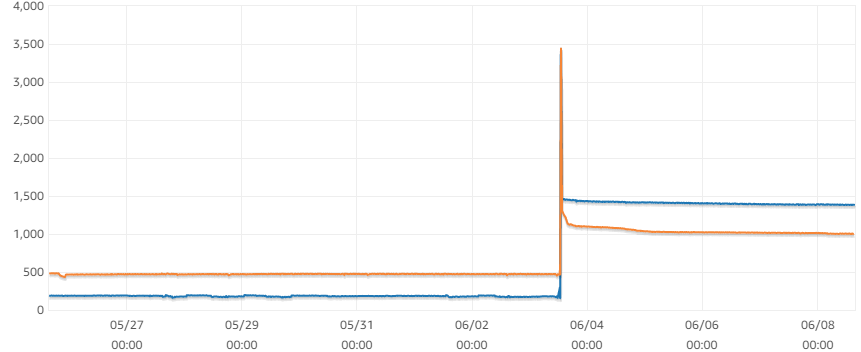
Fig.2 The Actual Free Memory Size | 图2 实际情形下的剩余内存
As you see, 1~1.5GiB memory is free, it means approximate 100 connections can be supported, and refer to the Figure 1, the 4GiB or more memory causing result is on 75 or higher max_connections, it is quiet matching between computed result and actual result. This conclution also well explain why AWS design the formula as that.
如图示的,1~1.5GiB的内存是空余内存,也就意味着能支持大约100个连接数,再参考图1,4GiB或更大的内存可以得到大约75或更高的连接数,这个计算值和实际情况是比较符合的,也很好地诠释了为何AWS把max_connection的式子设计成那样。
4. The Adjustment of Parameters | 参数的调节
Return to the logarithmic function basic form:
回到上述对数函数的基本形式:
\]
Note that C is base point to determine how much memory to make the formula making sense. It means if you want to keep more fixed memory size supply for OS or Global Buffers running, you may raise this value, e.g. 1024MiB or upper value then allows the database can accept connection; as well as using the C as a watershed to separate common memory size and very large mempry size.
留意C是作为这个式子是否有意义的基准点而存在的,也就是说如果希望保留更多的固定内存容量来供给OS或全局缓冲区来运行,那么可以上调这个值,比如上调到1024MiB以上数据库才能开始接受连接;同时还可以用作一般内存容量和超大内存容量的分水岭。
Then consider the base n and the coffient k, in logarithmic function, the base presents the approximate rake ratio in a large range when k=1 and y>0, and k amplify this ratio. Therefore, when we hope to adjust the ratio relationship between memory size and max_connections, we may adjust the n and k, the larger n would cause even more memory size the max_connection still keep a relatively tiny increment, then attach the coffient k would make the calculation nearly linear, and vice versa.
然后考虑底数n和系数k,在对数函数中,底数在一个较大范围里当k=0且y>0时近似于表现斜率,而K则放大这个斜率。那么,如果我们希望调整内存与max_connections之间的比例关系,我们可以调节n和k,更大的n值会使得即使内存量增加很多,max_connection也只是增加很少一点,再结合k值,可以使得整个计算值趋于线性,反之亦然。
Talk About AWS Aurora for MySQL max_connections parameter Calculation | 浅谈AWS Aurora for MySQL数据库中 max_connections参数的计算的更多相关文章
- Python 基于python+mysql浅谈redis缓存设计与数据库关联数据处理
基于python+mysql浅谈redis缓存设计与数据库关联数据处理 by:授客 QQ:1033553122 测试环境 redis-3.0.7 CentOS 6.5-x86_64 python 3 ...
- PDO浅谈之php连接mysql
一.首先我们先说一下什么是pdo? 百科上说 PDO扩展为PHP访问数据库定义了一个轻量级的.一致性的接口,它提供了一个数据访问抽象层,这样,无论使用什么数据库,都可以通过一致的函数执行查询和获取数 ...
- 浅谈tidb事务与MySQL事务之间的区别
MySQL是我们日常生活中常见的数据库,他的innodb存储引擎尤为常见,在事务方面使用的是扁平事务,即要么都执行,要么都回滚.而tidb数据库则使用的是分布式事务.两者都能保证数据的高一致性,但是在 ...
- 浅谈SQL Server、MySQL中char,varchar,nchar,nvarchar区别
最近一次的面试中,被面试官问到varchar和nvarchar的区别,脑海里记得是定长和可变长度的区别,但却没能说出来.后来,在网上找了下网友总结的区别.在这里做个备忘录: 一,SQL Server中 ...
- MySQL分库分表浅谈
一.分库分表类型 1.单库单表 所有数据都放在一个库,一张表. 2.单库多表 数据在一个库,单表水平切分多张表. 3.多库多表 数据库水平切分,表也水平切分. 二.分库分表查询 通过分库分表规则查找到 ...
- mysql中max_connections与max_user_connections使用区别
问题描述:把max_connections和max_user_connections参数进行分析测试,顾名思义,max_connections就是负责数据库全局的连接数,max_user_connec ...
- (转)运维角度浅谈MySQL数据库优化
转自:http://lizhenliang.blog.51cto.com/7876557/1657465 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架 ...
- Mysql优化系列(1)--Innodb引擎下mysql自身配置优化
1.简单介绍InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎.InnoDB锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读.这些特色 ...
- mysql下面的INSTALL-BINARY的内容,所有的mysql的配置内容都在这
2.2 Installing MySQL on Unix/Linux Using Generic Binaries Oracle provides a set of binary distributi ...
随机推荐
- 心有 netty 一点通!
一.标准的netty线程模型 双池合璧: 1.连接线程池: 连接线程池专门负责监听客户端连接请求,并完成连接的建立(包括诸如握手.安全认证等过程). 连接的建立本身是一个极其复杂.损耗性能的过程,此处 ...
- Spring WebFlux 学习笔记 - (一) 前传:学习Java 8 Stream Api (2) - Stream的中间操作
Stream API Java8中有两大最为重要的改变:第一个是 Lambda 表达式:另外一个则是 Stream API(java.util.stream.*). Stream 是 Java8 中处 ...
- Spark原始码系列(五)分布式缓存
问题导读:spark缓存是如何实现的?BlockManager与BlockManagerMaster的关系是什么? 这个persist方法是在RDD里面的,所以我们直接打开RDD这个类. def pe ...
- Android学习笔记物理按键事件处理
常见的物理按键: Android为每个物理按键都提供了如下几个回调方法: 代码示例: package com.example.demo3; import androidx.appcompat.app. ...
- APP——python——自动化环境搭建01
前提:python以及pycharm安装完成. ---------------------------------------------------------------------------- ...
- 商城04——门户网站介绍&商城首页搭建&内容系统创建&CMS实现
1. 课程计划 1.门户系统的搭建 2.显示商城首页 3.内容管理系统的实现 a) 内容分类管理 b) 内容管理 2. 门户系统的搭建 2.1. 什么是门户系统 从广义上来说,它将各种应用系 ...
- position两种绝对定位的区别
position绝对定有两种,分别为absolute和fixed 一.共同点: 1.改变行内元素的呈现方式,display被置为inline:block 2.让元素脱离普通流,不占据空间 3.默认会覆 ...
- 容器技术之Docker Machine
前文我们聊了下docker容器的资源限制,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13138725.html:今天我们来聊一聊docker machine ...
- mysql大表在不停机的情况下增加字段该怎么处理
MySQL中给一张千万甚至更大量级的表添加字段一直是比较头疼的问题,遇到此情况通常该如果处理?本文通过常见的三种场景进行案例说明. 1. 环境准备 数据库版本: 5.7.25-28(Percona 分 ...
- .Net Core Configuration源码探究
前言 上篇文章我们演示了为Configuration添加Etcd数据源,并且了解到为Configuration扩展自定义数据源还是非常简单的,核心就是把数据源的数据按照一定的规则读取到指定的字 ...