通过MapReduce降低服务响应时间
在微服务中开发中,api网关扮演对外提供restful api的角色,而api的数据往往会依赖其他服务,复杂的api更是会依赖多个甚至数十个服务。虽然单个被依赖服务的耗时一般都比较低,但如果多个服务串行依赖的话那么整个api的耗时将会大大增加。
那么通过什么手段来优化呢?我们首先想到的是通过并发来的方式来处理依赖,这样就能降低整个依赖的耗时,Go基础库中为我们提供了 WaitGroup 工具用来进行并发控制,但实际业务场景中多个依赖如果有一个出错我们期望能立即返回而不是等所有依赖都执行完再返回结果,而且WaitGroup中对变量的赋值往往需要加锁,每个依赖函数都需要添加Add和Done对于新手来说比较容易出错
基于以上的背景,go-zero框架中为我们提供了并发处理工具MapReduce,该工具开箱即用,不需要做什么初始化,我们通过下图看下使用MapReduce和没使用的耗时对比:

相同的依赖,串行处理的话需要200ms,使用MapReduce后的耗时等于所有依赖中最大的耗时为100ms,可见MapReduce可以大大降低服务耗时,而且随着依赖的增加效果就会越明显,减少处理耗时的同时并不会增加服务器压力
并发处理工具MapReduce
MapReduce是Google提出的一个软件架构,用于大规模数据集的并行运算,go-zero中的MapReduce工具正是借鉴了这种架构思想
go-zero框架中的MapReduce工具主要用来对批量数据进行并发的处理,以此来提升服务的性能
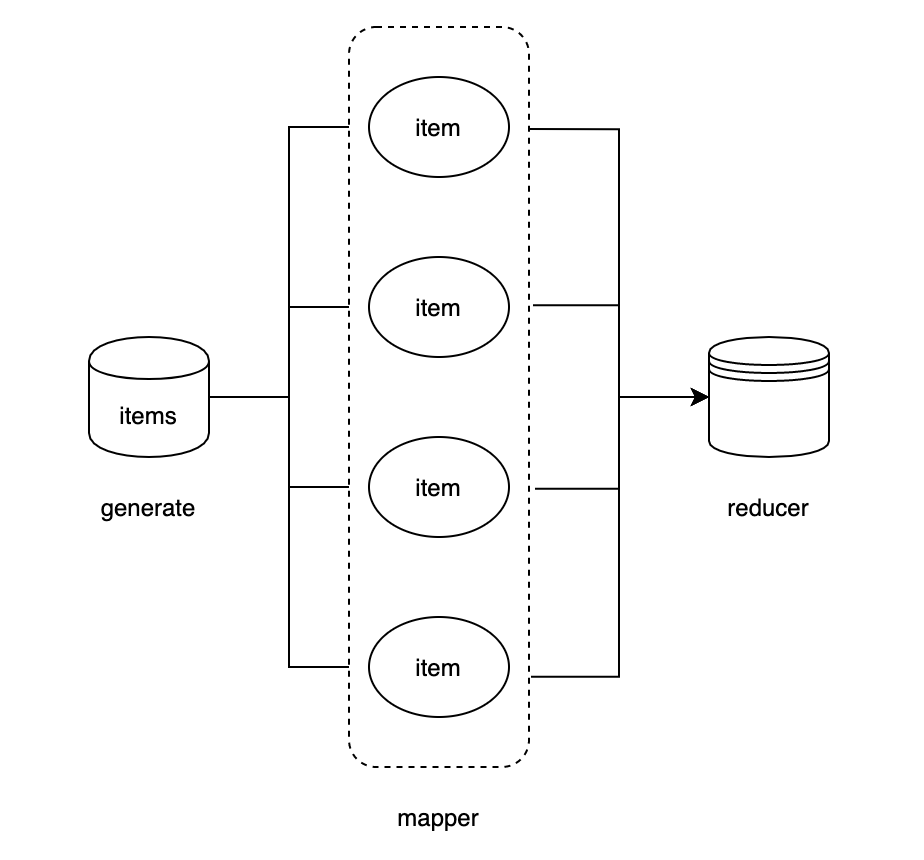
我们通过几个示例来演示MapReduce的用法
MapReduce主要有三个参数,第一个参数为generate用以生产数据,第二个参数为mapper用以对数据进行处理,第三个参数为reducer用以对mapper后的数据做聚合返回,还可以通过opts选项设置并发处理的线程数量
场景一: 某些功能的结果往往需要依赖多个服务,比如商品详情的结果往往会依赖用户服务、库存服务、订单服务等等,一般被依赖的服务都是以rpc的形式对外提供,为了降低依赖的耗时我们往往需要对依赖做并行处理
func productDetail(uid, pid int64) (*ProductDetail, error) {
var pd ProductDetail
err := mr.Finish(func() (err error) {
pd.User, err = userRpc.User(uid)
return
}, func() (err error) {
pd.Store, err = storeRpc.Store(pid)
return
}, func() (err error) {
pd.Order, err = orderRpc.Order(pid)
return
})
if err != nil {
log.Printf("product detail error: %v", err)
return nil, err
}
return &pd, nil
}
该示例中返回商品详情依赖了多个服务获取数据,因此做并发的依赖处理,对接口的性能有很大的提升
场景二: 很多时候我们需要对一批数据进行处理,比如对一批用户id,效验每个用户的合法性并且效验过程中有一个出错就认为效验失败,返回的结果为效验合法的用户id
func checkLegal(uids []int64) ([]int64, error) {
r, err := mr.MapReduce(func(source chan<- interface{}) {
for _, uid := range uids {
source <- uid
}
}, func(item interface{}, writer mr.Writer, cancel func(error)) {
uid := item.(int64)
ok, err := check(uid)
if err != nil {
cancel(err)
}
if ok {
writer.Write(uid)
}
}, func(pipe <-chan interface{}, writer mr.Writer, cancel func(error)) {
var uids []int64
for p := range pipe {
uids = append(uids, p.(int64))
}
writer.Write(uids)
})
if err != nil {
log.Printf("check error: %v", err)
return nil, err
}
return r.([]int64), nil
}
func check(uid int64) (bool, error) {
// do something check user legal
return true, nil
}
该示例中,如果check过程出现错误则通过cancel方法结束效验过程,并返回error整个效验过程结束,如果某个uid效验结果为false则最终结果不返回该uid
MapReduce使用注意事项
- mapper和reducer中都可以调用cancel,参数为error,调用后立即返回,返回结果为nil, error
- mapper中如果不调用writer.Write则item最终不会被reducer聚合
- reducer中如果不调用writer.Wirte则返回结果为nil, ErrReduceNoOutput
- reducer为单线程,所有mapper出来的结果在这里串行聚合
实现原理分析:
MapReduce中首先通过buildSource方法通过执行generate(参数为无缓冲channel)产生数据,并返回无缓冲的channel,mapper会从该channel中读取数据
func buildSource(generate GenerateFunc) chan interface{} {
source := make(chan interface{})
go func() {
defer close(source)
generate(source)
}()
return source
}
在MapReduceWithSource方法中定义了cancel方法,mapper和reducer中都可以调用该方法,调用后主线程收到close信号会立马返回
cancel := once(func(err error) {
if err != nil {
retErr.Set(err)
} else {
// 默认的error
retErr.Set(ErrCancelWithNil)
}
drain(source)
// 调用close(ouput)主线程收到Done信号,立马返回
finish()
})
在mapperDispatcher方法中调用了executeMappers,executeMappers消费buildSource产生的数据,每一个item都会起一个goroutine单独处理,默认最大并发数为16,可以通过WithWorkers进行设置
var wg sync.WaitGroup
defer func() {
wg.Wait() // 保证所有的item都处理完成
close(collector)
}()
pool := make(chan lang.PlaceholderType, workers)
writer := newGuardedWriter(collector, done) // 将mapper处理完的数据写入collector
for {
select {
case <-done: // 当调用了cancel会触发立即返回
return
case pool <- lang.Placeholder: // 控制最大并发数
item, ok := <-input
if !ok {
<-pool
return
}
wg.Add(1)
go func() {
defer func() {
wg.Done()
<-pool
}()
mapper(item, writer) // 对item进行处理,处理完调用writer.Write把结果写入collector对应的channel中
}()
}
}
reducer单goroutine对数mapper写入collector的数据进行处理,如果reducer中没有手动调用writer.Write则最终会执行finish方法对output进行close避免死锁
go func() {
defer func() {
if r := recover(); r != nil {
cancel(fmt.Errorf("%v", r))
} else {
finish()
}
}()
reducer(collector, writer, cancel)
}()
在该工具包中还提供了许多针对不同业务场景的方法,实现原理与MapReduce大同小异,感兴趣的同学可以查看源码学习
- MapReduceVoid 功能和MapReduce类似但没有结果返回只返回error
- Finish 处理固定数量的依赖,返回error,有一个error立即返回
- FinishVoid 和Finish方法功能类似,没有返回值
- Map 只做generate和mapper处理,返回channel
- MapVoid 和Map功能类似,无返回
本文主要介绍了go-zero框架中的MapReduce工具,在实际的项目中非常实用。用好工具对于提升服务性能和开发效率都有很大的帮助,希望本篇文章能给大家带来一些收获。
项目地址
https://github.com/tal-tech/go-zero
好未来技术
通过MapReduce降低服务响应时间的更多相关文章
- P95、P99.9百分位数值——服务响应时间的重要衡量指标
前段时间,在对系统进行改版后,经常会有用户投诉说页面响应较慢,我们看了看监控数据,发现从接口响应时间的平均值来看在500ms左右,也算符合要求,不至于像用户说的那么慢,岁很费解,后来观察其它的一些指标 ...
- 五、MapReduce 发布服务
是一个并行计算框架(计算的数据源比较广泛-HDFS.RDBMS.NoSQL),Hadoop的 MR模块充分利用了HDFS中所有数据节点(datanode)所在机器的内存.CUP以及少量磁盘完成对大数据 ...
- Mapreduce 历史服务 配置启动查看
如果没有进行配置的话,那个History是不可以进行点击的,点击进去就会报错!所以需要进行配置一下 使用命令启动HistoryServer 就可以查看任务执行的进度了 命令: sbin/mr-jobh ...
- 添加 K8S CPU limit 会降低服务性能
文章转载自:https://mp.weixin.qq.com/s/cR6MpQu-n1cwMbXmVaXqzQ
- 我用go-zero开发了第一个线上项目
作者:结冰 前言 说在最前面,我是一个外表谦让,内心狂热,外表斯文,内心贪玩的一个普通人.我的职业是程序员,是一个golang语言爱好者,一半是因为golang好用,一半是因为其他语言学不好.我是 ...
- 微服务和SOA服务
微服务和SOA都被认为是基于服务的架构,这意味着这两种架构模式都非常强调将“服务”作为其架构中的首要组件,用于实现各种功能(包括业务层面和非业务层面).微服务和SOA是两种差异很大的架构模式,但是他们 ...
- spring-cloud-hystrix服务熔断与降级
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时,异常等,Hystrix能保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联 ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
- NOS服务监控实践
本文来自网易云社区 作者:王健 一. 背景 此处所说的服务监控程序,是通过模拟用户的请求,对一个系统的服务质量进行监控的程序.服务监控程序的主要目的是,从用户的角度出发,通过发送端到端的请求,确认系 ...
随机推荐
- Cocos Creator 性能优化:DrawCall
前言 在游戏开发中,DrawCall 作为一个非常重要的性能指标,直接影响游戏的整体性能表现. 无论是 Cocos Creator.Unity.Unreal 还是其他游戏引擎,只要说到游戏性能优化,D ...
- leetcode刷题-86分隔链表
题目 给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前. 你应当保留两个分区中每个节点的初始相对位置. 示例: 输入: head = 1->4 ...
- leetcode刷题-62不同路径2
题目 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” ). 机器人每次只能向下或者向右移动一步.机器人试图达到网格的右下角(在下图中标记为“Finish”). 现在 ...
- Python实现加密的RAR文件解压(密码已知)
博主之前在网上找了很多资料,发现rarfile库不能直接调用,需要安装unrar模块,下面将详细介绍整个实现流程. 第一步:安装unrar模块,直接pip install unrar可能会找不到库,需 ...
- 关于input框仿百度/google自动提示的方法
引入jquery-autocomplete文件 链接:https://pan.baidu.com/s/1hW0XBYH8ZgJgMSY1Ce6Pig 密码:tv5b $(function() { $( ...
- UBer面向领域的微服务体系架构实践
介绍 最近,人们对面向服务的系统架构和微服务系统架构的缺点进行了大量的讨论.尽管仅仅在几年前,由于微服务体系架构提供了许多好处,如独立部署的灵活性.明确的所有权.提高系统稳定性以及更好地分离关注点等, ...
- Android组件化 + MVP + MVVM
前言 组件化和插件化已经提出了很久了,到现在也是比较稳定的一种架构方案了,在三年前,组件化和插件提出来没多久,前公司就已经在项目中使用了,只是当时还只是菜鸟,没有资格参与到架构的建设中,只是在大佬搭好 ...
- 使用镜像安装cygwin、gcc并配置CLion IDE -2020.09.12
使用镜像安装cygwin.gcc并配置CLion IDE -2020.09.12 Cygwin 官网:http://www.cygwin.com/ 下载64bit安装器,并打开选择next 尽量不要装 ...
- loadrunner做http接口的性能测试
不用录制脚本的方法 步骤: 1.先打开Virtual User Generator——选择Web/HTTP协议,进入到主页面,这里不按照传统录脚本的方式输入url,所以直接叉掉录制脚本选项,进入下面的 ...
- 整理的网上的MySQL优化文章总结
MySQL优化 Linux优化 IO优化 调整Linux默认的IO调度算法. IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调 ...