一 本书作者介绍
此书名为从Paxos到ZooKeeper分布式一致性原理与实践,作者倪超,阿里巴巴集团高级研发工程师,国家认证系统分析师,毕业于杭州电子科技大学计算机系。2010年加入阿里巴巴中间件团队担任研发实习岗位,一直从事Zookeeper的开发与运维工作,从中学习与总结了不少分布式一致性相关的理论与实践经验,尤其对Zookeeper及其相关技术有非常深入的研究。目前在中间件团队专家组任职产品经理,负责分布式产品的产品化和云计算改造工作。这本书涉及分布式领域绝大多数系统和框架,适合刚入门和想深入学习分布式框架的使用者。
二 书目内容结构
这本书先从分布式一致性的理论出发,向读者介绍了几种典型的分布式一致协议,以及解决分布式一致性问题的思路,重点讲解了Paxos和ZAB协议。同时,深入介绍了分布式一致性问题的工业解决方案----ZooKeeper,然后展示了这款框架的使用方法,旨在帮助读者掌握Zookeeper的原理和实际应用。全书分为8章,总共有5部分:第一部分(第1章)主要介绍了计算机系统从集中式向分布式系统演变过程中面临的挑战,并简要介绍了ACID、CAP和BASE等经典分布式理论;第二部分(第2~4章)介绍了2PC、3PC和Paxos三种分布式一致性协议,并着重讲解了ZooKeeper中使用的一致性协议——ZAB协议;第三部分(第5~6章)介绍了ZooKeeper的使用方法,包括客户端API的使用以及对ZooKeeper服务的部署与运行,并结合真实的分布式应用场景,总结了ZooKeeper使用实践;第四部分(第7章)对ZooKeeper的架构设计和实现原理进行了深入分析,包含系统模型、Leader选举、客户端与服务端的工作原理、请求处理,以及服务器角色的工作流程和数据存储等;第五部分(第8章)介绍了ZooKeeper的运维实践,包括配置详解和监控管理等,重点讲解了如何构建一个高可用的ZooKeeper服务。
三 读书心得
读完本书,我对自己的要求就是知道下面的几个方面,是什么---这本书主要内容及技术,以及这些技术在什么场景下使用;怎么做----主要针对Zookeeper的具体使用;为什么---使用这些技术,带来的效率还是经济的影响。
(1)这本书主要内容是什么
从5个部分来讲,第一,计算机系统的演变,从集中式到分布式的过程,集中式在历史发展过程中显示出来的缺点:部署结构简单,数据的存储和控制处理完全由集中式的服务器或者服务器集群来处理,瓶颈问题很突出。所以出现了分布式,分布式的几个特征:分布性,多台计算机在空间上是任意分布的,机器分布情况会随时间而变化,对等性,系统中的计算机没有主从之分,分布式的系统通过副本共享数据,一致性通过消息传递来保证。然后是ACID即事务的原子性,一致性,隔离性和持久性。同时CAP理论告诉我们:一个分布式系统不可能同时满足一致性,可用性,分区容错性这三个基本需求。所以出现了BASE理论,基本可用,软状态,最终一致性。第二,学习了2PC、3PC和Paxos三种分布式一致性协议,以及Zookeeper用到的一致性协议ZAB协议。其中,
Paxos算法---两个最重要的属性:Safety和Liveness:永远不会发生的,最终都会发生的
一种基于消息传递且具有高度容错特性的一致性算法,目前公认的解决分布式一致性问题最有效的算法之一。
需要解决的问题1:如何在一个可能放生某个节点异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致,并且保证不论发生什么异常(消息通道的异常和节点处的异常),都不会破坏整个系统的一致性。
问题2:假设不存在拜占庭将军的问题情况下,如何解决一致性问题
paxos算法具体描述:
假设有一组可以提出提案的进程集合,那么对于一个一致性算法来说,
- 在这些被提出的提案中,只有一个会被选定。
- 如果没有提案被提出,那么就不会有被选定的提案。
- 当一个提案被选定后,进程应该可以获取被选定的提案信息。
- 只有被提出的提案才能被选定。
- 只有一个值被选定
- 如果某个进程认为某个提案被选定了,那么这个提案必须是真的被选定的那个
其目标:保证最终由一个提案会被选定,当提案被选定后,进程最终也能获取到被选定的提案。
三种角色:Proposer、Acceptor、Learner 每个进程可担任多重角色。
假设:每个参与者以任意的速度执行,可能因为出错而停止,也可能会重启。同时,即是一个提案被选定后,所有的参与者也都有可能失败或者重启,因此除非那些失败或重启的参与者可以记录某些信息,否则将无法确定最终的值。
消息在传输过程中可能会出现不可预知的延迟,也可能会重复或丢失,但是消息不会被损坏,即消息内容不会被篡改。(保证不会发生拜占庭式的问题)。
提案的选定过程:
P1.只有一个Acceptor的话,Proposer只能发送给该Acceptor,这样实现起来容易,但是当Acceptor出现问题时候,那么整个系统就会瘫痪。
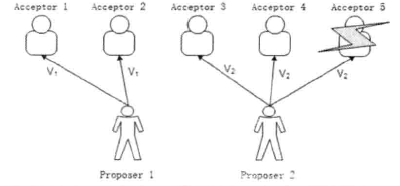
P2.不同的Proposer分别提出多个提案。这种情况下,可能会发生下面的情况,没有一个提案是被多数人批准的,是无法选定一个提案的。如图1。
图1
P3.不同的Proposer分别提出多个提案,这样即使只有两个提案被提出,如果有一个Acceptor出错,可能导致无法确定该选定哪个提案。如图2。
图2
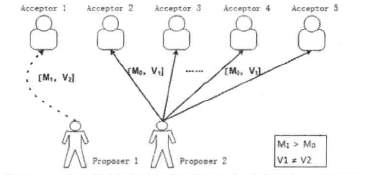
P4.由于通信是异步的,当提案超过半数接受者,但是某提案还没发出,或发出的提案还没被接受者接受,此时就需保证先提出的提案是最新的提案。如果3
图3
实现主要协议是ZAB
ZAB包括两种基本的模式,崩溃恢复和消息广播。当整个服务框架在启动过程中,或是当Leader服务器出现网络中断,崩溃退出与重启等异常情况时,ZAB协议就会进入恢复模式并选举产生新的Leader服务器。当选举产生了新的Leader服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步以后,ZAB协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够与Leader服务器的数据状态保持一致。
当集群中已经有过半的Follower服务器完成了和Leader服务器的协议同步,那么整个服务框架就可以进入消息广播模式了。当一台同样遵守ZAB协议的服务器启动后加入到集群中时,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,,然后一起参与到消息广播流程中去。ZooKeeper设计成只允许唯一的一个Leader服务器进行事务请求的处理。Leader服务器在接受到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;而如果集群中的其他机器接收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
当Leader服务器出现奔溃退出或机器重启,或者集群中已经不存在过半的服务器与该Leader服务器保持正常通信时,那么在重新开始新一轮的原子广播事务操作之前,所有的进程首先会使用奔溃恢复协议来使彼此达到一个一致的状态,于是整个ZAB流程就会从消息广播模式进入到奔溃恢复模式。
一个机器要成为新的Leader,必须获得过半进程的支持,同时由于每个进程都有可能会奔溃,因此。在ZAB协议运行过程中,前后会出现多个Leader,并且每个进程也有可能会多次成为Leader。进入奔溃恢复模式后,只要集群中存在过半的服务器能够彼此进行正常通信,那么就可以产生一个新的Leader并再次进入消息广播模式。
(2)技术应用场景
ZooKeeper的应用
默认服务端端口2181,可以配置成单机、集群、伪集群三种形式。
其关系:其实单机就是只有一台机器,也只配置一台机器,集群是有多台机器也配置了多台机器,而伪集群是只有一台机器配置了多台机器,所以这样的话,自然端口就必须不一样,因为端口就是区别于进程的唯一标志。
主要配置
server.1=127.0.0.1:20881:30881
server.2=127.0.0.1:20882:30882
server.3=127.0.0.1:20883:30883
上面的配置中有两个TCP port。后面一个是用于Zookeeper选举用的,而前一个是Leader和Follower或Observer交换数据使用的。我们还注意到server.后面的数字。这个就是myid,用来唯一标识服务器。
Zookeeper的典型应用场景
Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架开发人员可以使用它来进行分布式数据的发布与订阅。另一方面,通过对Zookeeper中丰富的数据节点类型进行交叉使用,配合Watcher事件通知机制,可以非常方便地构建一些列分布式应用中都会涉及的核心功能,如数据发布/订阅,负载均衡,命名服务,分布式协调通知,集群管理,Master选举,分布式锁和分布式队列等。
越来越多的分布式系统将Zookeeper作为核心组件,如Hadoop,HBase和Kafka等,因此,正确理解Zookeeper的应用场景,对于Zookeeper的使用者来说,显得尤为重要。
1.数据的发布与订阅
目的:为了实现配置信息的集中式管理和数据的动态更新。
方式:Push 和 Pull 模式 push模式下,服务端主动将数据更新发送给所有订阅的客户端;而拉模式是由客户端主动发送请求来获取最新数据,通常客户端都采用定时进行轮询拉去的方式。Zookeeper采用的是推拉想结合的方式,客户端向服务端注册需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端收到这个消息通知之后,需要主动到服务端获取最新的数据。如果将配置信息存放到ZooKeeper上进行集中管理,那么通常情况下,应用在启动的时候会主动到Zookeeper服务端上进行一次配置信息的获取,同时,在指定节点上注册一个Watcher监听,这样,配置发生变更,服务端会实时通知到所有订阅的客户端,从而保证获取最新配置信息的目的。
应用:在实际开发中,系统中需要使用到的一些通用的配置信息,如硬件系统信息,运行开关设置,数据库配置信息等。其特点是数据量小,内容会在运行时发生变化,各机器共享,配置一致。一般做法是放在本地配置文件或是内存变量中。都可以在启动时,或者运行时读取来保证一致,内存的方式比如JMX来实现对系统运行时内存变量的更新。但是当规模变大时,就比较困难了,因此想到分布式的解决方案。比如数据源的配置。
2.负载均衡
原理:通过在对等的服务提供方中选择一个来执行相关业务逻辑。
典例:DNS服务,首先用户访问某网站需要知道域名来代替不容易记住的ip,首先可以通过hosts文件来绑定,使得域名与ip对应来解析,但是规模大了,如果需要临时改域名,就得逐个变更,消耗大量时间,而实时性却不一定能保证。将这份配置文件放到Zookeeper提供端,可能是某个节点,当启动时会将它共享于整个服务集群。当在运行时,如果应用app动态改变,也可以实现监测与运维正常。
3.命名服务
常在一些分布式服务框架(如RPC、RMI)中的服务地址列表。消费者可以通过指定名字来获取资源的实体、服务地址和提供者的信息等。
4.分布式协调/通知
将不同的分布式组件有机结合起来,作为一个协调者来控制整个系统的运行流程。基于Zookeeper实现分布式协调与通知功能,通常做法是不同的客户端都对Zookeeper上同一个数据节点进行Watcher注册,监听数据节点的变化,如果数据节点发生变化,那么所有订阅的客户端都能够接受到相应的Watcher通知,并作出相应的处理。
(3)为什么是Zookeeper
Zookeeper以树作为内存数据模型,数据上的每一个节点是最小的数据单元,即Znode.Znode具有不同的节点特性,同时每个节点都具有一个递增的版本号以此来实现分布式数据的原子性更新。Zookeeper是作为大数据时代下从Hadoop分离出来的组件,旨在解决大规模分布式应用场景下,服务协调同步的问题,他可以为同在一个分布式系统中的其他服务提供:统一命名服务、配置管理、分布式锁服务、集群管理等功能)是个很伟大的开源项目,很成熟,有相当大的社区来支持它的发展,而且在生产环境得到广泛使用。从而造就了Zookeeper
四 已阅读书目清单
1.深入理解Java虚拟机:JVM高级特性与最佳实践
2.大型网站系统与JAVA中间件实践
3.Tomcat权威指南(第二版)(中文版)
更多书籍
![]()
加群161867053获得。
- 从Paxos到Zookeeper分布式一致性原理与实践 读书笔记之(一) 分布式架构
1.1 从集中式到分布式 1 集中式特点 结构简单,无需考虑对多个节点的部署和节点之间的协作. 2 分布式特点 分不性:在时间可空间上随意分布,机器的分布情况随时变动 对等性:计算机之间没有主从之分 ...
- 《从Paxos到ZooKeeper分布式一致性原理与实践》学习笔记
第一章 分布式架构 1.1 从集中式到分布式 集中式的特点: 部署结构简单(因为基于底层性能卓越的大型主机,不需考虑对服务多个节点的部署,也就不用考虑多个节点之间分布式协调问题) 分布式系统是一个硬件 ...
- 我读《从Paxos到zookeeper分布式一致性原理与实践》
从年后拿到这本书开始阅读,到准备系统分析师考试之前,终于读完了一遍,对Zookeeper有了一个全面的认识,整本书从理论到应用再到细节的阐述,内容安排从逻辑性和实用性上都是很优秀的,对全面认识Zook ...
- 《从Paxos到ZooKeeper 分布式一致性原理与实践》读书笔记
一.分布式架构 1.分布式特点 分布性 对等性.分布式系统中的所有计算机节点都是对等的 并发性.多个节点并发的操作一些共享的资源 缺乏全局时钟.节点之间通过消息传递进行通信和协调,因为缺乏全局时钟,很 ...
- [从Paxos到ZooKeeper][分布式一致性原理与实践]<二>一致性协议[Paxos算法]
Overview 在<一>有介绍到,一个分布式系统的架构设计,往往会在系统的可用性和数据一致性之间进行反复的权衡,于是产生了一系列的一致性协议. 为解决分布式一致性问题,在长期的探索过程中 ...
- 2月22日 《从Paxos到Zookeeper 分布式一致性原理与实践》读后感
zk的特点: 分布式一致性的解决方案,包括:顺序一致性,原子性,单一视图,可靠性,实时性 zk的基本概念: 集群角色:not Master/Slave,is Leader/Follower/Obser ...
- 《从Paxos到ZooKeeper 分布式一致性原理与实践》阅读【Watcher】
ZooKeeper 允许客户端向服务端注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能. ZooKeeper ...
- 《从Paxos到ZooKeeper 分布式一致性原理与实践》阅读【Leader选举】
从3.4.0版本开始,zookeeper废弃了0.1.2这3种Leader选举算法,只保留了TCP版本的FastLeaderElection选举算法. 当ZooKeeper集群中的一台服务器出现以下两 ...
- 《从Paxos到Zookeeper:分布式一致性原理与实践》【PDF】下载
内容简介 Paxos到Zookeeper分布式一致性原理与实践从分布式一致性的理论出发,向读者简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了Paxos和ZAB协议. ...
随机推荐
- 【SpringBoot】05.SpringBoot整合Listener的两种方式
SpringBoot整合Listener的两种方式: 1.通过注解扫描完成Listener组件的注册 创建一个类实现ServletContextListener (具体实现哪个Listener根据情况 ...
- Android Google官方文档解析之——Device Compatibility
Android is designed to run on many different types of devices, from phones to tablets and television ...
- 鸿蒙开发板外设控制 之 实现按键“按下事件”和“释放事件”的通用框架(V0.0.1)
在帖子 <鸿蒙开发板外设控制>直播图文版(2020.10.28) 中我们提到过:"开发板上的按键也可以看作一种 GPIO 外设." 因此,要捕捉按键的状态(按下或释放) ...
- 搭建面向NET Framework的CI/CD持续集成环境(一)
前言 网上大多数都是针对主流的Spring Cloud.NET Core的CI/CD方案.但是目前国内绝大部分的公司因为一些历史原因无法简单的把项目从NET Framework切换升级到NET Cor ...
- 内网渗透 day10-msfvenom免杀
免杀2-msf免杀 目录 1. 生成shellcode 2. 生成python脚本 3. 自编码免杀 4. 自捆绑免杀(模版注入) 5. 自编码+自捆绑免杀 6. msf多重免杀 7. evasion ...
- Pandas_VBA_数据分类比较
Python与VBA的比较2 需求: input文件中有两列数据,第一列为Name,第二列为Score,Name列里有重复的值,要求按照name的唯一值统计 score,输出到output文件按中. ...
- java.sql.SQLException: Error: Error: could not match input
impala执行sql,输出后我在控制台粘贴执行OK,奇怪了. java.sql.SQLException: Error: Error: could not match input 原因竟然是myba ...
- JS仿贪吃蛇:一串跟着鼠标的Div
贪吃蛇是一款80后.90后比较熟悉的经典游戏,下面通过简单的JS代码来实现低仿版贪吃蛇效果:随着鼠标的移动,在页面中呈现所有Div块跟随鼠标依次移动,效果如下图所示. <!DOCTYPE htm ...
- Nagios 告警配置太复杂?CA简单实现Nagios自定义多功能告警
Nagios 是一个插件式的监控系统,可以监控服务的运行状态和网络信息等,并能监视所指定的本地或远程主机参数以及服务,同时提供异常告警通知功能等.Nagios 支持客户端的数据采集,通过编写客户端插件 ...
- 154. Find Minimum in Rotated Sorted Array II(循环数组查找)
Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand. (i.e. ...