Apache Hudi使用简介
Apache Hudi使用简介
数据实时处理和实时的数据
实时分为处理的实时和数据的实时
即席分析是要求对数据实时的处理,马上要得到对应的结果
Flink、Spark Streaming是用来对实时数据的实时处理,数据要求实时,处理也要迅速
数据不实时,处理也不及时的场景则是我们的数仓T+1数据
而本文探讨的Apache Hudi,对应的场景是数据的实时,而非处理的实时。它旨在将Mysql中的时候以近实时的方式映射到大数据平台,比如Hive中。
业务场景和技术选型
传统的离线数仓,通常数据是T+1的,不能满足对当日数据分析的需求
而流式计算一般是基于窗口,并且窗口逻辑相对比较固定。
而笔者所在的公司有一类特殊的需求,业务分析比较熟悉现有事务数据库的数据结构,并且希望有很多即席分析,这些分析包含当日比较实时的数据。惯常他们是基于Mysql从库,直接通过Sql做相应的分析计算。但很多时候会遇到如下障碍
- 数据量较大、分析逻辑较为复杂时,Mysql从库耗时较长
- 一些跨库的分析无法实现
因此,一些弥合在OLTP和OLAP之间的技术框架出现,典型有TiDB。它能同时支持OLTP和OLAP。而诸如Apache Hudi和Apache Kudu则相当于现有OLTP和OLAP技术的桥梁。他们能够以现有OLTP中的数据结构存储数据,支持CRUD,同时提供跟现有OLAP框架的整合(如Hive,Impala),以实现OLAP分析
Apache Kudu,需要单独部署集群。而Apache Hudi则不需要,它可以利用现有的大数据集群比如HDFS做数据文件存储,然后通过Hive做数据分析,相对来说更适合资源受限的环境
Apache hudi简介
使用Aapche Hudi整体思路
Hudi 提供了Hudi 表的概念,这些表支持CRUD操作。我们可以基于这个特点,将Mysql Binlog的数据重放至Hudi表,然后基于Hive对Hudi表进行查询分析。数据流向架构如下

Hudi表数据结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

- 包含
_partition_key相关的路径是实际的数据文件,按分区存储,当然分区的路径key是可以指定的,我这里使用的是_partition_key - .hoodie 由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
数据文件
Hudi真实的数据文件使用Parquet文件格式存储

.hoodie文件
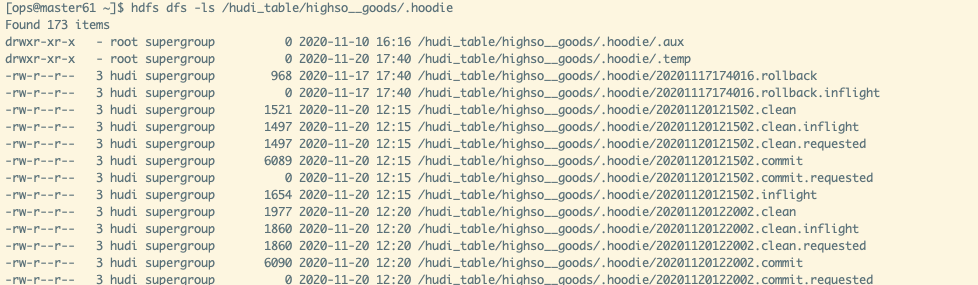
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline。Timeline中某一次的操作,叫做Instant。Instant包含以下信息
- Instant Action 记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS)
- Instant Time 本次操作发生的时间
- state 操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED)
.hoodie文件夹中存放对应操作的状态记录
Hudi记录Id
hudi为了实现数据的CRUD,需要能够唯一标识一条记录。hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键
COW和MOR
基于上述基础概念之上,Hudi提供了两类表格式COW和MOR。他们会在数据的写入和查询性能上有一些不同
Copy On Write Table
简称COW。顾名思义,他是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是是近的完整副本,这类似Mysql 的MVCC的思想。
上图中,每一个颜色都包含了截至到其所在时间的所有数据。老的数据副本在超过一定的个数限制后,将被删除。这种类型的表,没有compact instant,因为写入时相当于已经compact了。
- 优点 读取时,只读取对应分区的一个数据文件即可,较为高效
- 缺点 数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。且由于耗时,读请求读取到的数据相对就会滞后
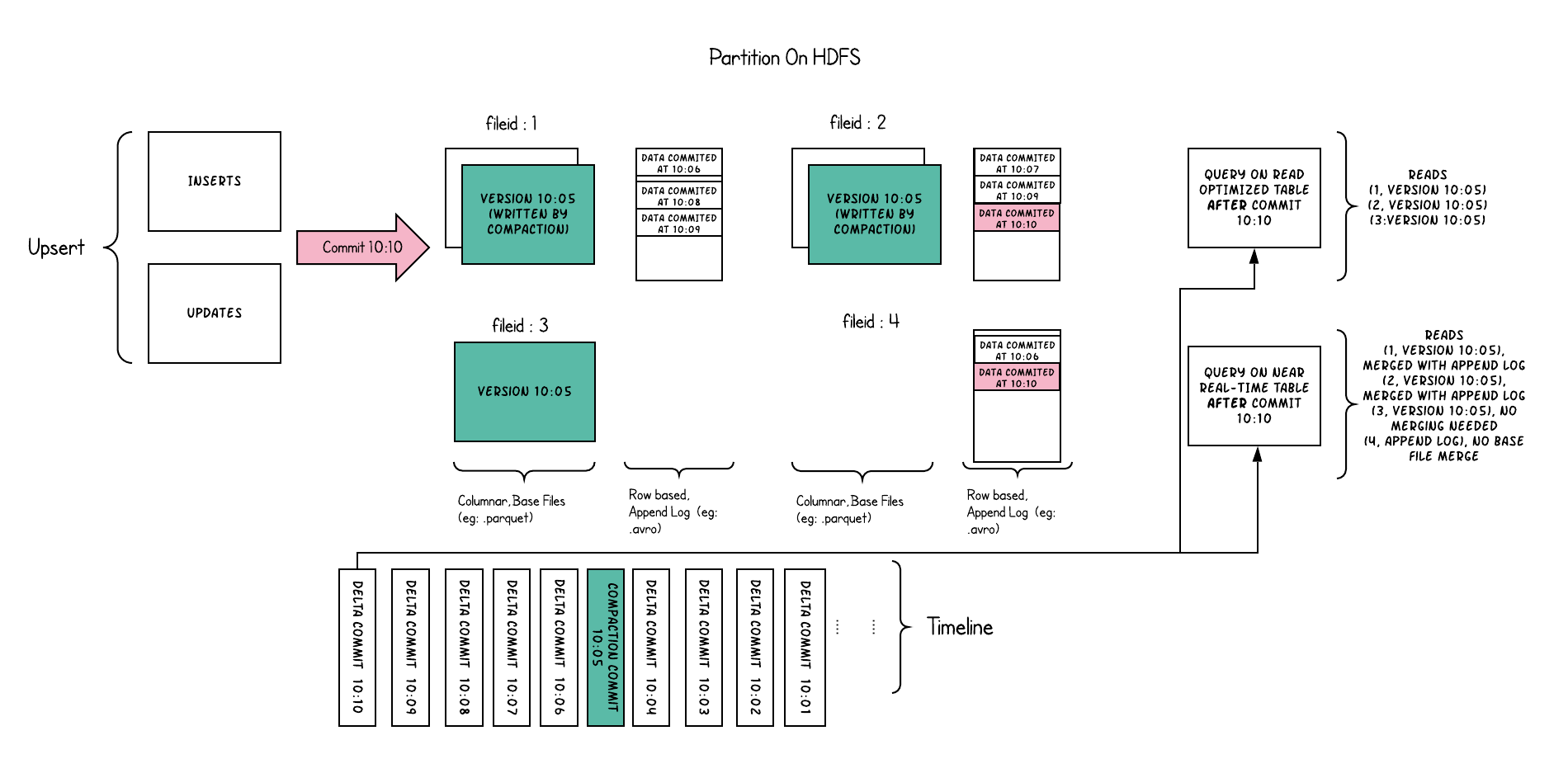
Merge On Read Table
简称MOR。新插入的数据存储在delta log 中。定期再将delta log合并进行parquet数据文件。读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。当然,MOR表也可以像COW表一样,忽略delta log,只读取最近的完整数据文件。下图演示了MOR的两种数据读写方式

- 优点 由于写入数据先写delta log,且delta log较小,所以写入成本较低
- 缺点 需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log 和 老数据文件合并
基于hudi的代码实现
我在github上放置了基于Hudi的封装实现,对应的源码地址为 https://github.com/wanqiufeng/hudi-learn。
binlog数据写入Hudi表
- binlog-consumer分支使用Spark streaming消费kafka中的Binlog数据,并写入Hudi表。Kafka中的binlog是通过阿里的Canal工具同步拉取的。程序入口是CanalKafkaImport2Hudi,它提供了一系列参数,配置程序的执行行为
| 参数名 | 含义 | 是否必填 | 默认值 |
|---|---|---|---|
--base-save-path |
hudi表存放在HDFS的基础路径,比如hdfs://192.168.16.181:8020/hudi_data/ | 是 | 无 |
--mapping-mysql-db-name |
指定处理的Mysql库名 | 是 | 无 |
--mapping-mysql-table-name |
指定处理的Mysql表名 | 是 | 无 |
--store-table-name |
指定Hudi的表名 | 否 | 默认会根据--mapping-mysql-db-name和--mapping-mysql-table-name自动生成。假设--mapping-mysql-db-name 为crm,--mapping-mysql-table-name为order。那么最终的hudi表名为crm__order |
--real-save-path |
指定hudi表最终存储的hdfs路径 | 否 | 默认根据--base-save-path和--store-table-name自动生成,生成格式为'--base-save-path'+'/'+'--store-table-name' ,推荐默认 |
--primary-key |
指定同步的mysql表中能唯一标识记录的字段名 | 否 | 默认id |
--partition-key |
指定mysql表中可以用于分区的时间字段,字段必须是timestamp 或dateime类型 | 是 | 无 |
--precombine-key |
最终用于配置hudi的hoodie.datasource.write.precombine.field |
否 | 默认id |
--kafka-server |
指定Kafka 集群地址 | 是 | 无 |
--kafka-topic |
指定消费kafka的队列 | 是 | 无 |
--kafka-group |
指定消费kafka的group | 否 | 默认在存储表名前加'hudi'前缀,比如'hudi_crm__order' |
--duration-seconds |
由于本程序使用Spark streaming开发,这里指定Spark streaming微批的时长 | 否 | 默认10秒 |
一个使用的demo如下
/data/opt/spark-2.4.4-bin-hadoop2.6/bin/spark-submit --class com.niceshot.hudi.CanalKafkaImport2Hudi \
--name hudi__goods \
--master yarn \
--deploy-mode cluster \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 1 \
--queue hudi \
--conf spark.executor.memoryOverhead=2048 \
--conf "spark.executor.extraJavaOptions=-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=\tmp\hudi-debug" \
--conf spark.core.connection.ack.wait.timeout=300 \
--conf spark.locality.wait=100 \
--conf spark.streaming.backpressure.enabled=true \
--conf spark.streaming.receiver.maxRate=500 \
--conf spark.streaming.kafka.maxRatePerPartition=200 \
--conf spark.ui.retainedJobs=10 \
--conf spark.ui.retainedStages=10 \
--conf spark.ui.retainedTasks=10 \
--conf spark.worker.ui.retainedExecutors=10 \
--conf spark.worker.ui.retainedDrivers=10 \
--conf spark.sql.ui.retainedExecutions=10 \
--conf spark.yarn.submit.waitAppCompletion=false \
--conf spark.yarn.maxAppAttempts=4 \
--conf spark.yarn.am.attemptFailuresValidityInterval=1h \
--conf spark.yarn.max.executor.failures=20 \
--conf spark.yarn.executor.failuresValidityInterval=1h \
--conf spark.task.maxFailures=8 \
/data/opt/spark-applications/hudi_canal_consumer/hudi-canal-import-1.0-SNAPSHOT-jar-with-dependencies.jar --kafka-server local:9092 --kafka-topic dt_streaming_canal_xxx --base-save-path hdfs://192.168.2.1:8020/hudi_table/ --mapping-mysql-db-name crm --mapping-mysql-table-name order --primary-key id --partition-key createDate --duration-seconds 1200
历史数据同步以及表元数据同步至hive
history_import_and_meta_sync 分支提供了将历史数据同步至hudi表,以及将hudi表数据结构同步至hive meta的操作
同步历史数据至hudi表
这里采用的思路是
- 将mysql全量数据通过注入sqoop等工具,导入到hive表。
- 然后采用分支代码中的工具HiveImport2HudiConfig,将数据导入Hudi表
HiveImport2HudiConfig提供了如下一些参数,用于配置程序执行行为
| 参数名 | 含义 | 是否必填 | 默认值 |
|---|---|---|---|
--base-save-path |
hudi表存放在HDFS的基础路径,比如hdfs://192.168.16.181:8020/hudi_data/ | 是 | 无 |
--mapping-mysql-db-name |
指定处理的Mysql库名 | 是 | 无 |
--mapping-mysql-table-name |
指定处理的Mysql表名 | 是 | 无 |
--store-table-name |
指定Hudi的表名 | 否 | 默认会根据--mapping-mysql-db-name和--mapping-mysql-table-name自动生成。假设--mapping-mysql-db-name 为crm,--mapping-mysql-table-name为order。那么最终的hudi表名为crm__order |
--real-save-path |
指定hudi表最终存储的hdfs路径 | 否 | 默认根据--base-save-path和--store-table-name自动生成,生成格式为'--base-save-path'+'/'+'--store-table-name' ,推荐默认 |
--primary-key |
指定同步的hive历史表中能唯一标识记录的字段名 | 否 | 默认id |
--partition-key |
指定hive历史表中可以用于分区的时间字段,字段必须是timestamp 或dateime类型 | 是 | 无 |
--precombine-key |
最终用于配置hudi的hoodie.datasource.write.precombine.field |
否 | 默认id |
--sync-hive-db-name |
全量历史数据所在hive的库名 | 是 | 无 |
--sync-hive-table-name |
全量历史数据所在hive的表名 | 是 | 无 |
--hive-base-path |
hive的所有数据文件存放地址,需要参看具体的hive配置 | 否 | /user/hive/warehouse |
--hive-site-path |
hive-site.xml配置文件所在的地址 | 是 | 无 |
--tmp-data-path |
程序执行过程中临时文件存放路径。一般默认路径是/tmp。有可能出现/tmp所在磁盘太小,而导致历史程序执行失败的情况。当出现该情况时,可以通过该参数自定义执行路径 | 否 | 默认操作系统临时目录 |
一个程序执行demo
nohup java -jar hudi-learn-1.0-SNAPSHOT.jar --sync-hive-db-name hudi_temp --sync-hive-table-name crm__wx_user_info --base-save-path hdfs://192.168.2.2:8020/hudi_table/ --mapping-mysql-db-name crm --mapping-mysql-table-name "order" --primary-key "id" --partition-key created_date --hive-site-path /etc/lib/hive/conf/hive-site.xml --tmp-data-path /data/tmp > order.log &
同步hudi表结构至hive meta
需要将hudi的数据结构和分区,以hive外表的形式同步至Hive meta,才能是Hive感知到hudi数据,并通过sql进行查询分析。Hudi本身在消费Binlog进行存储时,可以顺带将相关表元数据信息同步至hive。但考虑到每条写入Apache Hudi表的数据,都要读写Hive Meta ,对Hive的性能可能影响很大。所以我单独开发了HiveMetaSyncConfig工具,用于同步hudi表元数据至Hive。考虑到目前程序只支持按天分区,所以同步工具可以一天执行一次即可。参数配置如下
| 参数名 | 含义 | 是否必填 |默认值|
| :-------- | --------
Apache Hudi使用简介的更多相关文章
- 直播 | Apache Kylin & Apache Hudi Meetup
千呼万唤始出来,Meetup 直播终于来啦- 本次线上 Meetup 由 Apache Kylin 与 Apache Hudi 社区联合举办,将于 3 月 14 日晚进行直播,邀请到来自丁香园.腾讯. ...
- Apache Hudi 设计与架构最强解读
感谢 Apache Hudi contributor:王祥虎 翻译&供稿. 欢迎关注微信公众号:ApacheHudi 本文将介绍Apache Hudi的基本概念.设计以及总体基础架构. 1.简 ...
- 实战| 配置DataDog监控Apache Hudi应用指标
1. 可用性 在Hudi最新master分支,由Hudi活跃贡献者Raymond Xu贡献了DataDog监控Hudi应用指标,该功能将在0.6.0 版本发布,也感谢Raymond的投稿. 2. 简介 ...
- 在AWS Glue中使用Apache Hudi
1. Glue与Hudi简介 AWS Glue AWS Glue是Amazon Web Services(AWS)云平台推出的一款无服务器(Serverless)的大数据分析服务.对于不了解该产品的读 ...
- Apache—DBUtils框架简介
转载自:http://blog.csdn.net/fengdongkun/article/details/8236216 Apache—DBUtils框架简介.DbUtils类.QueryRunner ...
- JAVAEE——BOS物流项目10:权限概述、常见的权限控制方式、apache shiro框架简介、基于shiro框架进行认证操作
1 学习计划 1.演示权限demo 2.权限概述 n 认证 n 授权 3.常见的权限控制方式 n url拦截权限控制 n 方法注解权限控制 4.创建权限数据模型 n 权限表 n 角色表 n 用户表 n ...
- Apache Hudi 介绍与应用
Apache Hudi Apache Hudi 在基于 HDFS/S3 数据存储之上,提供了两种流原语: 插入更新 增量拉取 一般来说,我们会将大量数据存储到HDFS/S3,新数据增量写入,而旧数据鲜 ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 官宣!Amazon EMR正式支持Apache Hudi
Apache Hudi是一个开源的数据管理框架,其通过提供记录级别的insert, update, upsert和delete能力来简化增量数据处理和数据管道开发.Upsert指的是将记录插入到现有 ...
随机推荐
- JDBC【2】-- JDBC工作原理以及简单封装
目录 1. 工作原理 1.1 加载驱动 1.1.1 类加载相关知识 1.1.2 为什么JDK 1.6之后不需要显示加载了? 1.2 驱动加载完成了,然后呢? 2. 简单封装 1. 工作原理 一般我们主 ...
- 在Windows下使用CodeBlock使用libiconv第三方库
在Windows下使用CodeBlock使用libiconv第三方库 1. 选择在Project->Build options下: 2. 如下图添加libicon ...
- Spring bean注册
DefaultListableBeanFactory中: DefaultListableBeanFactory实现了BeanDefinitionRegistry,这个接口的实现完成BeanDefini ...
- JZOJ8月6日提高组反思
JZOJ8月6日提高组反思 又是愉快的没落的一天 被2020&2018暴打day2 一堆人AK-- T1 看到这个\(m\)只有100 就坚定了我打暴力的信心 离散化加暴力匹配 原本就想\(3 ...
- 国产开源数据库:腾讯云TBase在分布式HTAP领域的探索与实践
导语 | TBase 是腾讯TEG数据平台团队在开源 PostgreSQL 的基础上研发的企业级分布式 HTAP 数据库系统,可在同一数据库集群中同时为客户提供强一致高并发的分布式在线事务能力以及高 ...
- moviepy音视频剪辑:使用fl_time报错OSError: MoviePy error: failed to read the first frame of video file
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在m ...
- 【JAVA并发第一篇】Java的进程与线程
1.进程与线程 1.1.进程 进程可以看作是程序的执行过程.一个程序的运行需要CPU时间.内存空间.文件以及I/O等资源.操作系统就是以进程为单位来分配这些资源的,所以说进程是分配资源的基本单位. ( ...
- NodeService Ensure that Node.js is installed and can be found in one of the PATH directories
今天发布NodeService到服务器,服务器环境是window server 2012 一直报错: [1] Ensure that Node.js is installed and can be f ...
- .NET 面试题汇总(带答案)
1.维护数据库的完整性.一致性.你喜欢用触发器还是自写业务逻辑?为什么? 答:尽可能用约束(包括CHECK.主键.唯一键.外键.非空字段)实现,这种方式的效率最好:其次用触发器,这种方式可以保证无论何 ...
- PageRank 算法-Google 如何给网页排名
公号:码农充电站pro 主页:https://codeshellme.github.io 在互联网早期,随着网络上的网页逐渐增多,如何从海量网页中检索出我们想要的页面,变得非常的重要. 当时著名的雅虎 ...