Redis 设计与实现:字符串 SDS
本文的分析没有特殊说明都是基于 Redis 6.0 版本源码
redis 6.0 源码:https://github.com/redis/redis/tree/6.0
在 Redis 中,字符串都用自定义的结构简单动态字符串(Simple Dynamic Strings,SDS)。
Redis 中使用到的字符串都是用 SDS,例如 key、string 类型的值、sorted set 的 member、hash 的 field 等等等等。。。
数据结构
旧版本的结构
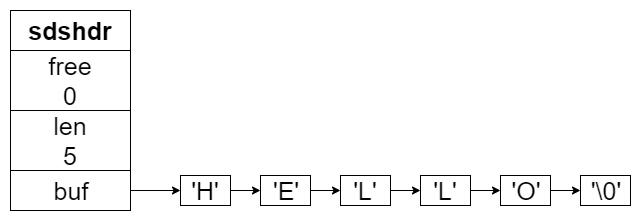
在 3.2 版本之前,sds 的定义是这样的:
struct sdshdr {
// buf 数组中已使用的字节数量,也就是 sds 本身的字符串长度
unsigned int len;
// buf 数组中未使用的字节数量
unsigned int free;
// 字节数组,用于保存字符串
char buf[];
};
这样的结构有几个好处:
- 单独记录长度
len,获取字符串长度的时间复杂度是 $O(1)$ 。传统的 C 字符串获取长度需要遍历字符串,直到遇到\0,时间复杂度是 $O(N)$。 - buf 数组末尾遵循 C 字符串以
\0结尾的惯例,可以兼容 C 处理字符串的函数。 - 减少修改字符串带来的内存重分配次数,Redis 使用了 空间预分配(预先申请大一点点的空间) 和 空间惰性释放(字符串变短修改
len字段即可)来减少字符串修改引起的内存重新分配。 - 不以
\0为结尾的判断,二进制安全。因为图片等二进制数据中,可能包含\0,传统 C 字符串一遇到\0就认为字符串结束了,会导致不能完整保存。
缺点:
len和free的定义用了 4 个字节,可以表示2^32的长度。但是我们实际使用的字符串,往往没有那么长。4 个字节造成了浪费。
新版本的结构
旧版本中我们说到,len 和 free 的缺点是用了太长的变量,新版本解决了这个问题。
我们来看一下新版本的 SDS 结构。
在 Redis 3.2 版本之后,Redis 将 SDS 划分为 5 种类型:
| 类型 | 字节 | 位 |
|---|---|---|
| sdshdr5 | < 1 | <8 |
| sdshdr8 | 1 | 8 |
| sdshdr16 | 2 | 16 |
| sdshdr32 | 4 | 32 |
| sdshdr64 | 8 | 64 |
新版本新增加了一个 flags 字段来标识类型,长度 1 字节(8 位)。
类型只占用了前 3 位。在 sdshdr5 中,后 5 位用来保存字符串的长度。其他类型后 5 位没有用。
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 前 3 位保存类型,后 5 位保存字符串长度 */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* 字符串长度,1 字节 8 位 */
uint8_t alloc; /* 申请的总长度,1 字节 8 位 */
unsigned char flags; /* 前 3 位保存类型,后 5 位未使用 */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* 字符串长度,2 字节 16 位 */
uint16_t alloc; /* 申请的总长度,2 字节 16 位 */
unsigned char flags; /* 前 3 位保存类型,后 5 位未使用 */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* 字符串长度,4 字节 32 位 */
uint32_t alloc; /* 申请的总长度,4 字节 32 位 */
unsigned char flags; /* 前 3 位保存类型,后 5 位未使用 */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* 字符串长度,8 字节 64 位 */
uint64_t alloc; /* 申请的总长度,8 字节 64 位 */
unsigned char flags; /* 前 3 位保存类型,后 5 位未使用 */
char buf[];
};
优点:
- 旧版本相对于传统 C 字符串的优点,新版本都有
- 相对于旧版本,新版本可以通过字符串的长度,选择不同的结构,可以节约内存
- 使用
__attribute__ ((__packed__)),让编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,可以节约内存
SDS 的初始化
sds 的定义,跟传统的C语言字符串保持类型兼容 char *。但是 sds 是二进制安全的,中间可能包含\0。
sds.h
typedef char *sds;
sds.c
// 初始化 sds
sds sdsnewlen(const void *init, size_t initlen) {
// 指向 sdshdr 开始地方的指针
void *sh;
// sds 实际是一个指针,指向 buf 开始的位置
sds s;
// 根据初始化的长度,返回 sds 的类型
char type = sdsReqType(initlen);
// initlen == 0,是空字符串,空字符串往往就是用来往后添加字节的,使用 SDS_TYPE_8 比 SDS_TYPE_5 更好
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
// 根据类型获取 struct sdshdr 的长度
int hdrlen = sdsHdrSize(type);
// flags 字段的指针
unsigned char *fp;
// 开始分配空间,+1 是为了最后一个的结束符号 \0
sh = s_malloc(hdrlen+initlen+1);
if (sh == NULL) return NULL;
// const char *SDS_NOINIT = "SDS_NOINIT";
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
// 不是 init 则清空 sh 的内存
memset(sh, 0, hdrlen+initlen+1);
// s 指向了 buf 开始的地址
// 从上面结构可以看出,内存地址的顺序: len, alloc, flag, buf
// 因为 buf 本身不占用空间,hdrlen 实际上就是结构的头(len、alloc、flags)
s = (char*)sh+hdrlen;
// flags 占用 1 个字节,所以 s 退一位就是 flags 的开始位置了
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
// #define SDS_TYPE_BITS 3
// 前 3 位保存类型,后 5 位保存长度
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
// define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
// sh 变量赋值了 struct sdshdr
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
// 下面是对 SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64 的初始化,跟 SDS_TYPE_8 的类似,篇幅有限,省略...
}
// 如果 init 非空,则把 init 字符串赋值给 s,实际上也是 buf 的初始化
if (initlen && init)
memcpy(s, init, initlen);
// 最后加一个结束标志 \0
s[initlen] = '\0';
return s;
}
SDS 的扩/缩容
扩容
扩容就不跟初始化一样写注释写得那么详细了,直接拉最重要的几句代码就行。
sds sdsMakeRoomFor(sds s, size_t addlen) {
// #define SDS_MAX_PREALLOC (1024*1024)
// 当新的长度小于 1M 的时候,长度会增长一倍
// 当新的长度达到 1M 之后,最多就增长 1M 了
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
// ...
}
缩容
sds 缩短不会真正缩小 buf,而是只改长度而已,类型也不变。
sds.c
// 删掉字符串的左右字符中指定的字符
sds sdstrim(sds s, const char *cset) {
char *start, *end, *sp, *ep;
size_t len;
sp = start = s;
ep = end = s+sdslen(s)-1;
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > sp && strchr(cset, *ep)) ep--;
len = (sp > ep) ? 0 : ((ep-sp)+1);
if (s != sp) memmove(s, sp, len);
// 结尾符
s[len] = '\0';
// 缩短长度
sdssetlen(s,len);
return s;
}
sds.h
static inline void sdssetlen(sds s, size_t newlen) {
// 设置sds长度,只是修改 sdshdr 结构中的长度字段,类型不会变
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
{
unsigned char *fp = ((unsigned char*)s)-1;
*fp = (unsigned char)(SDS_TYPE_5 | (newlen << SDS_TYPE_BITS));
}
break;
case SDS_TYPE_8:
SDS_HDR(8,s)->len = (uint8_t)newlen;
break;
case SDS_TYPE_16:
SDS_HDR(16,s)->len = (uint16_t)newlen;
break;
case SDS_TYPE_32:
SDS_HDR(32,s)->len = (uint32_t)newlen;
break;
case SDS_TYPE_64:
SDS_HDR(64,s)->len = (uint64_t)newlen;
break;
}
}
Redis 设计与实现:字符串 SDS的更多相关文章
- 深入理解Redis 数据结构—简单动态字符串sds
Redis是用ANSI C语言编写的,它是一个高性能的key-value数据库,它可以作用在数据库.缓存和消息中间件.其中 Redis 键值对中的键都是 string 类型,而键值对中的值也是有 st ...
- 【Redis】简单动态字符串SDS
C语言字符串 char *str = "redis"; // 可以不显式的添加\0,由编译器添加 char *str = "redis\0"; // 也可以添加 ...
- Redis 设计与实现笔记 - SDS
Redis 中的字符串没有使用 C语言中的字符指针(char *),而是使用了自定义的结构 sds. 文件: sds.h sds.c 结构: struct sdshdr { int len; // 填 ...
- Redis 设计与实现读书笔记一 Redis字符串
1 Redis 是C语言实现的 2 C字符串是 /0 结束的字符数组 3 Redis具体的动态字符串实现 /* * 保存字符串对象的结构 */ struct sdshdr { // buf 中已占用空 ...
- [Redis源码阅读]sds字符串实现
初衷 从开始工作就开始使用Redis,也有一段时间了,但都只是停留在使用阶段,没有往更深的角度探索,每次想读源码都止步在阅读书籍上,因为看完书很快又忘了,这次逼自己先读代码.因为个人觉得写作需要阅读文 ...
- 小白的Redis学习(一)-SDS简单动态字符串
本文为读<Redis设计与实现>的记录.该书以Redis2.9讲解Redis相关内容.请注意版本差异. Redis使用C语言实现,他对C语言中的char类型数据进行封装,构建了一种简单动态 ...
- 图解Redis之数据结构篇——简单动态字符串SDS
图解Redis之数据结构篇--简单动态字符串SDS 前言 相信用过Redis的人都知道,Redis提供了一个逻辑上的对象系统构建了一个键值对数据库以供客户端用户使用.这个对象系统包括字符串对象 ...
- Redis底层探秘(一):简单动态字符串(SDS)
redis是我们使用非常多的一种缓存技术,他的性能极高,读的速度是110000次/s,写的速度是81000次/s.这么高的性能背后,到底是怎么样的实现在支撑,这个系列的文章,我们一起去看看. redi ...
- Redis 设计与实现,看 SDS(Simple Dynamic String) 感悟
Redis 设计与实现,看 SDS(Simple Dynamic String) 感悟 今天在看 Redis 设计与实现这本书的时候,发现了里面系统定义的数据结构 SDS,中文名为 简单动态字符串.对 ...
- 探索Redis设计与实现3:Redis内部数据结构详解——sds
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
随机推荐
- Rest Framework:序列化组件
Django内置的serializers(把对象序列化成json字符串 from django.core import serializers def test(request): book_list ...
- UUID介绍与生成的方法
什么是UUID? UUID是Universally Unique Identifier的缩写,它是在一定的范围内(从特定的名字空间到全球)唯一的机器生成的标识符.UUID具有以下涵义: 经由一定的算法 ...
- Docker学习—Stack
前言: 前一篇了解Docker使用Swarm集群部署方式,并创建服务到Swarm集群中:如果在集群部署过程中存在大量服务部署.编排那么该如何处理呢? 那么就需要了解Docker Stack了. 1.D ...
- moviepy音视频剪辑:moviepy中的剪辑基类Clip的属性和方法详解
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt+moviepy音视频剪辑实战 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 一. ...
- 第13.1节 关于Python的异常处理
Python的异常网上有很多资料介绍,老猿就不再细说,在这里老猿只挑几件老猿认为重要的内容介绍一下. 一. 异常处理完整语法 异常处理的完整语法语法如下: try: - except (异常1,-,异 ...
- PyQt(Python+Qt)学习随笔:Qt Designer中Action创建的方法
在Qt Designer中,可以两种方法创建Action对象,一种是菜单定义时,一种是单独定义. 一.定义菜单创建Action 在Qt Designer中创建菜单时,如果对应菜单是最终执行的菜单项,则 ...
- FFmpeg在Android Studio中断点调试
一般情况下在Android平台使用FFmpeg为动态库或静态库的形式,只能通过设置FFmpeg日志回调来看一些FFmpeg输出的日志,有时需要debug来查看FFmpeg内部执行过程,本文记录一下在A ...
- Get请求Test
一.新建测试套 作为管理接口,可按功能分类,也可按业务逻辑分类,根目录下最多一级子目录.运行接口时,可按测试套为单位,整体运行. 二.选择请求类型,输入接口地址 根据接口文档中提供的接口请求类型及地址 ...
- Django 框架基本操作(二)
一.设计表结构 1.班级表结构 表名:grade 字段:班级名称(gname).成立时间(gdate).女生总数(ggirlnum).男生总数(gboynum).是否删除(isDelete) 2.学生 ...
- tcp socket学习
更新一波学的socket编程,socket还是比较重要的,探测端口,连接服务底层都是socket编程.tcp有server 和 client.client和udp发送差不多. server端是建立了两 ...