Datanode 怎么与 Namenode 通信?
在分析DataNode时, 因为DataNode上保存的是数据块, 因此DataNode主要是对数据块进行操作.
A. DataNode的主要工作流程
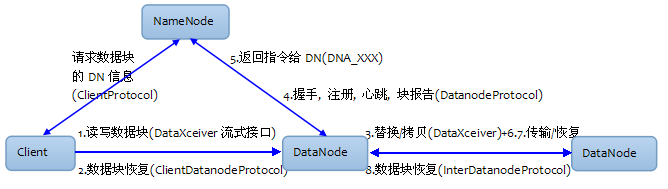
- 客户端和DataNode的通信: 客户端向DataNode的
数据块读写, 采用TCP/IP流接口(DataXceiver)进行数据传输 - 客户端在检测到DataNode异常, 主动发起的
数据块恢复, 客户端会通过ClientDatanodeProtocol接口采用RPC调用的方式和DataNode通信. 数据块替换和拷贝, 由负载均衡器Balancer发起的, 是发生在DataNode之间. 也是通过DataXceiver进行数据传输- DataNode在启动后会向NameNode分别完成:
握手, 注册, 心跳, 块报告. - NameNode根据DataNode的块报告和心跳, 会返回给DataNode
指令. 通过这种方式NameNode间接地和DataNode进行通信.
实际上NameNode作为Server端, 是不会主动去联系DataNode的, 只有作为客户端的DataNode才会去联系NameNode.
DataNode在接收到NameNode的指令信息, 被要求去做: 重新向NameNode注册, 数据块传输, 恢复等. - NameNode检测到数据块的副本个数不足. 要求DN执行
数据块传输(DNA_TRANSFERBLOCK), DataNode使用DataTransfer也是基于DataXceiver流接口. - NameNode发起的数据块恢复(DNA_RECOVERBLOCK), 是检测到客户端/租约错误, 恢复策略是选取参与到恢复过程中的数据块的最小长度.
- 不管是客户端错误会被NN返回数据块恢复命令给DN执行恢复操作, 还是DN错误由客户端主动触发的数据块恢复操作. 都会使用到
InterdatanodeProtocol的两个数据块恢复方法(startBlockRecovery和updateBlock).
因为数据块恢复实际上是在DN之间根据恢复策略恢复到数据块正常的状态. 而且恢复时不像写数据没有数据来源. 所以是在DN之间进行通信.
B. 从DataNode的功能来看:
- DataNode实现的两个接口ClientDatanodeProtocol和InterDatanodeProtocol都用于数据块恢复.
- 数据块的其他操作使用TCP/IP流式接口来完成: DataXceiver(读写, 替换, 复制)和DataTransfer(传输).
C. 从DataNode的通信来看:
- 客户端可以向DataNode发起读写数据块请求, 主动发起数据块恢复.
- DataNode向NameNode握手, 注册, 心跳, 块报告. 并接收NameNode的指令.
原文出处:https://www.cnblogs.com/30go/
Datanode 怎么与 Namenode 通信?的更多相关文章
- rpc,客户端与NameNode通信的过程
远程过程:java进程.即一个java进程调用另外一个java进程中对象的方法. 调用方称作客户端(client),被调用方称作服务端(server).rpc的通信在java中表现为客户端去调用服务端 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- Secondary NameNode:的作用?
前言 最近刚接触Hadoop, 一直没有弄明白NameNode和Secondary NameNode的区别和关系.很多人都认为,Secondary NameNode是NameNode的备份,是为了防止 ...
- 一探究竟:Namenode、SecondaryNamenode、NamenodeHA关系
NameNode与Secondary NameNode 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止NameNode的单点失败的,其实并不是在这样.文章Sec ...
- 解读Secondary NameNode的功能
1.概述 最近有朋友问我Secondary NameNode的作用,是不是NameNode的备份?是不是为了防止NameNode的单点问题?确实,刚接触Hadoop,从字面上看,很容易会把Second ...
- Secondary NameNode 的作用
https://blog.csdn.net/xh16319/article/details/31375197 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止Na ...
- (转)Secondary NameNode的作用
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备份.但它实际上却不是.很多Hadoop的初学者都很疑惑,S ...
- 【Hadoop】Hadoop DataNode节点超时时间设置
hadoop datanode节点超时时间设置 datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间 ...
- hadoop datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长. HDFS默认的超时时长为10分 ...
随机推荐
- setTimeout、clearTimeout、setInterval
setTimeout(cb, ms) setTimeout(cb, ms) 全局函数在指定的毫秒(ms)数后执行指定函数(cb).:setTimeout() 只执行一次指定函数. 返回一个代表定时器的 ...
- 在Windows上安装MySQL(转整)
MySQL安装 在Windows上安装MySQL.首先登录MySQL的官网下载安装包. 选择MySQL installer 这里选择第二个安装包下载即可. 下载完成之后就选择安装那个下载到的文件,基本 ...
- source命令用法:source FileName
转自https://zhidao.baidu.com/question/59790034.html 写得很清楚,就直接搬过来了备忘 作用:在当前bash环境下读取并执行FileName中的命令. 注 ...
- 基于视频压缩的实时监控系统-sprint1基于epoll架构的采集端程序设计
part1:产品功能 part2:epoll机制 select与epoll区别 1.select与epoll没有太大的区别.除了select有文件描述符限制(1024个),select每次调用都需 ...
- Android Studio--家庭记账本(三)
点击右上角可以实现将花费以折线图的形式显示出来.同时将同一天的花费自动计算.暂时还没有加x,y轴 ChartsActivity.java: package com.example.family; im ...
- java验证工具类(待验证)
/** * <判断对象是否为null或者空> * * @param obj * 需要判断的对象 * @return 如果对象为null或者空则返回true */ public static ...
- linux学习笔记之makefile
首先 make时工程管理器 而makefile则是make唯一的配置文件,当我们需要使用make管理工程时,我们需要建立一个makefile文件 简单点说,makefile是把我们所要编译的c文件结合 ...
- LInux回顾与Shell编程
一.Linux回顾 因为要学习Hadoop大数据,会用到Linux服务器集群来做,因此有必要回顾一下当年大一所学习的Linux知识 ①Linux系统有7个运行级别(runlevel): 运行级别0:系 ...
- JDBC工具类—如何封装JDBC
“获得数据库连接”操作,将在以后的增删改查所有功能中都存在,可以封装工具类JDBCUtils.提供获取连接对象的方法,从而达到代码的重复利用. 该工具类提供方法:public static Conne ...
- 栈及其简单应用(二)(python代码)
一.括号判定 前一篇文章我们介绍了栈的简单应用中,关于括号的判定,但那只是一种括号的判定,下面我们来介绍多种括号混合使用时,如何判断括号左右一一对应. 比如“{}{(}(][”这种情况,需要对一种括号 ...