kafka入门之broker--日志存储设计
kafaka并不是直接将原省消息写入日志文件的,相反,它会将消息和一些必要的元数据信息大宝在一起封装成一个record写入日志。其实就是我们之前介绍的batch
具体对每个日志而言,kafka又将其进一步细分成日志段文件以及日志段索引文件,每个分区日志都是由若干日志段文件+索引文件构成的。
创建topic时,kafka为该topic的每个分区在文件系统中创建了一个对应的子目录,名字就是<topic>-<分区号>。每个日志子目录的文件构成都是如图所示的结构,即若干组日志段+索引文件。
1。日志段文件,即后缀名时.log的文件保存着真是的Kafka记录,kafla使用该文件第一条记录对应的offset来命名此.log文件。
kafka每个日志段文件是有上限大小的,由broker端参数log.segment.bytes控制,默认就是1GB大小。,因此当日志段文件填满记录后,kafka会自动创建一组新的日志段文件和索引文件,这个过程被称为日志切分。当前日志段非常特殊,它不受任何Kafka后台任务的影星,比如定期日志清楚任务和定期日志compaction任务。
2.索引文件
.index文件和.timeindex文件他们都是索引文件,分别被称为位移索引文件和时间戳索引文件,前者可以帮助broker更快地定位记录所在的物理文件位置,而后者则是根据给定的时间戳查询对应的位移信息。
它们都属于稀疏索引文件,每个索引文件都由若干索引项组成。kafka不会为每条消息记录都保存对应的索引项,而是特写入若干记录后才增加一个索引项,broker端参数log.index,interval.bytes设置了这个间隔到底是多大,默认值是4kb,即kafka分区至少写入了4KB数据后才会在索引文件中增加一个索引项,故本质上它们是稀疏的。
升序排列,有了这种升序规律,kafka可以利用二分查找算法来搜索目标索引项,从而降低整体时间复杂度到o(lgN)。若没有索引文件,kafka搜寻记录的方式只能是从每个日志段文件的体育部孙旭扫面,因此这种方案的时间复杂度是o(N)显然,引入索引文件可以极大的减少查找时间,减少broker端的cpu开销
当日志进行切分时,索引文件也需要进行切分,broker端参数log.index.size.max.bytes设置了索引文件的最大文件大小,默认是10MB。和日志段文件不同,索引文件的空间默认都是预先分配好的,而当对索引文件切分时,kafka会把该文件大小'裁剪'到真实数据大小:

格式:
1.位移索引文件:

每个索引项固定地占用8字节的物理空间,同时kafka强制要求索引文件必须是索引项大小的整数倍,即8的整数倍,因此假设用户设300会是296
索引文件文件名中的位移就是改索引文件的起始位移。
2.时间戳索引文件:

每个索引项固定占用12字节的物理空间,同时kafka强制要求索引文件必须是索引项大小的整数倍,即12的整数倍,设100会是96
时间戳索引项保存的是时间戳与唯一的映射关系,给定时间戳后根据此索引文件只能找到不大于该时间戳的最大位移,然后kafka还需要拿着返回的位移再去位移索引文件中定位真实的物理文件位置。
日志留存:
定期清除日志,即删除符合策略的日志段文件和两个索引文件:
基于时间:默认7天,.log.retention.hours|minutes|ms用于配置清除日志的时间间隔,其中ms的优先级最高,minutes次之,hours优先级最低,计算当前时间戳与日志段首条消息的时间戳之差作为衡量日志段是否留存的依据,如果第一条消息没有时间戳,kafka才会使用最近修改时间的属性
基于大小,默认-1,表示kafka不会对log进行大小方面的限制
日志清除是一个异步过程,kafka broker启动后会创建单独的线程处理日志清除事宜。
日志compaction:
如果·使用log compaction,kafka消息必须要设置key,无key消息是无法为其进行压实操作的。
kafka有个组件叫cleanner,它就是负责执行compaction操作的。cleaner负责从log中移除已废弃的消息,如果一条消息的key是k,位移是o,只要日志中存在另外一条消息,key也是k,但位移是o‘,且o<o‘,即认为前面那条消息已经废弃。
log compaction是topic级别的设置。
在内部kafka会构造一个哈希表来保存key与最新位移的映射关系:
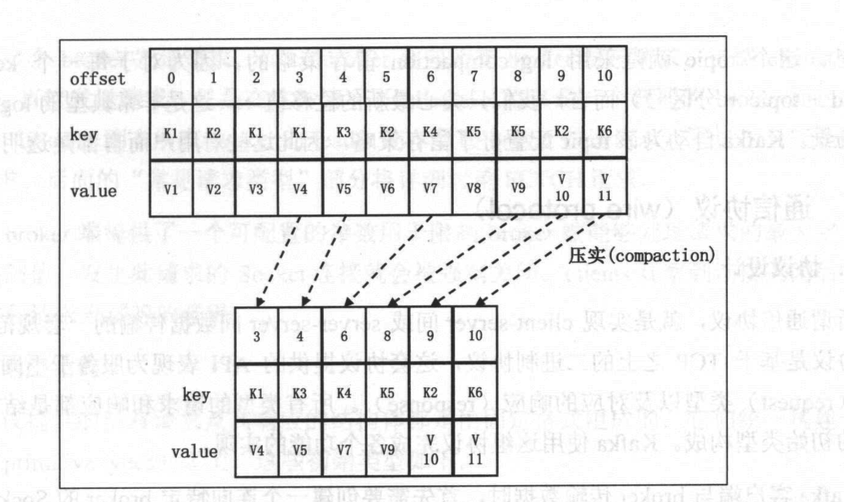
_consumer_offset内部topic就是采用log compaction留存策略的。
相关参数:
log.cleanup.policy:
log.cleaner.enable:
log.cleanner.min.compaction.lang.ms

kafka入门之broker--日志存储设计的更多相关文章
- 我们NetCore下日志存储设计
日志的分类 首先往大的来说,日志分2种 ①业务日志: 即业务系统需要查看的日志, 常见的比如谁什么时候修改了什么. ②参数日志: 一般是开发人员遇到问题的时候定位用的, 一般不需要再业务系统里展示. ...
- Es+kafka搭建日志存储查询系统(设计)
现在使用的比较常用的日志分析系统有Splunk和Elk,Splunk功能齐全,处理能力强,但是是商用项目,而且收费高.Elk则是Splunk项目的一个开源实现,Elk是ElasticSearch(Es ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- Kafka 入门(二)--数据日志、副本机制和消费策略
一.Kafka 数据日志 1.主题 Topic Topic 是逻辑概念. 主题类似于分类,也可以理解为一个消息的集合.每一条发送到 Kafka 的消息都会带上一个主题信息,表明属于哪个主题. Kafk ...
- Kafka#4:存储设计 分布式设计 源码分析
https://sites.google.com/a/mammatustech.com/mammatusmain/kafka-architecture/4-kafka-detailed-archite ...
- kafka入门教程链接
http://www.aboutyun.com/forum.php?mod=viewthread&tid=12882 经典入门教程 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创 ...
- 超详细“零”基础kafka入门篇
1.认识kafka 1.1 kafka简介 Kafka 是一个分布式流媒体平台 kafka官网:http://kafka.apache.org/ (1)流媒体平台有三个关键功能: 发布和订阅记录流,类 ...
- Kafka 入门三问
目录 1 Kafka 是什么? 1.1 背景 1.2 定位 1.3 产生的原因 1.4 Kafka 有哪些特征 消息和批次 模式 主题和分区 生产者和消费者 broker 和 集群 1.5 Kafka ...
- 项目17-超详细“零”基础kafka入门篇
分类: Linux服务篇,Linux架构篇 1.认识kafka 1.1 kafka简介 Kafka 是一个分布式流媒体平台 kafka官网:http://kafka.apache.org/ (1) ...
随机推荐
- 10 Servlet_02 资源跳转(主要是内部转发)与中文乱码问题
总的知识点: 1.小的知识点总结: alt + shift + r 重命名快捷键(可以给包和类以及项目重命名) 有序列表 ol li 无序列表 ul type 格式 text 是文本类型 passwo ...
- Luogu P4271 [USACO18FEB]New Barns P
题意 给一个一开始没有点的图,有 \(q\) 次操作,每次为加点连边或者查询一个点到连通块内所有点的距离最大值. \(\texttt{Data Range}:1\leq q\leq 10^5\) 题解 ...
- 4G工业路由器的信号强度应该怎么保证呢?
在M2M无线方面,最薄弱的环节是差的间歇性的信号强度.低信号电平导致系统性能差,响应时间慢和可靠性问题.对于系统安装人员和其他4G工业路由器供应商,如何确保最佳的蜂窝信号强度? 检查2G/3G/4G信 ...
- 华为hcip学习备考心得
大家好我是林中鸟,经过几个月的学习终于顺利拿下了华为的hcip:写这篇文章主要目的是想和大家分享一下我学习备考中的一些经历. 2020年由于疫情影响,社会各行各业都遭受重创,同时也打乱的我的生活规划: ...
- re模块,判断某行/某字符是否存在
import re ##判断行是否存在def get_need_line(): ## 获取有用信息行 with open('task.log',mode="r") as f: fo ...
- [Luogu P3899] [湖南集训]谈笑风生 (主席树)
题面 传送门:https://www.luogu.org/problemnew/show/P3899 Solution 你们搞的这道题啊,excited! 这题真的很有意思. 首先,我们可以先理解一下 ...
- php中Standard中配置选项,在TargetFrameworks环境下如何输出库存
在.NET Standard/.NET Core技术出现之前,编写一个类库项目(暂且称为基础通用类库PA)且需要支持不同 .NET Framework 版本,那么可行的办法就是创建多个不同版本的项目( ...
- Fira Code字体安装与配置
俗话说,工欲善其事,必先利其器.算法固然重要,但真正实践也很重要. 一个字体的好看程度,直接决定了写代码和看代码的心情.比如这样: 代码1: #include <iostream> #in ...
- 直播APP源码是如何实现音视频同步的
1. 音视频同步原理 1)时间戳 直播APP源码音视频同步主要用于在音视频流的播放过程中,让同一时刻录制的声音和图像在播放的时候尽可能的在同一个时间输出. 解决直播APP源码音视频同步问题的最佳方案 ...
- python数据分析01准备工作
第1章 准备工作 1.1 本书的内容 本书讲的是利用Python进行数据控制.处理.整理.分析等方面的具体细节和基本要点.我的目标是介绍Python编程和用于数据处理的库和工具环境,掌握这些,可以让你 ...