高吞吐量消息系统—kafka
现在基本上大数据的场景中都会有kafka的身影,那么为什么这些场景下要用kafka而不用其他传统的消息队列呢?例如rabbitmq。主要的原因是因为kafka天然的百万级TPS,以及它对接其他大数据组件的流处理功能,比如可以更好的对接Apache storm。本文只是讨论kafka作为消息队列的功能及一些用法。
丑话说在前头
Kafka本身比较重,强依赖于zookeeper,所以使用Kafka必须要先搭建zookeeper(虽然topic offset已经不在zookeeper管理,但是其他重要的meta信息都是保存在zookeeper),本身的topic/partition/replicate/offset等概念需要学习成本,异常情况下存在重复消费数据的风险,需要用户自行规避,例如将消息设计为幂等消息,或者用户层维护一个index自行记录有没有消费过。同一个topic下的不同partition间不能保证消息顺序,只能保证同一个partition的数据是有序的。另外kafka消费者组的rebalance一直是一个用户诟病的点,topic/parition/消费者数量变化都会引发rebalance,rebalance期间整个消费者组不能消费数据(即STW,stop the world)。所以我个人建议,如果不要求百万级TPS的消息队列并且不强依赖kafka的某些特性,可以优先考虑传统的消息队列,比如rabbitmq。
消息队列的优势
1.削峰填谷
用于上下游数据处理时长差别很大的应用场景。比如购物网站,前端需要快速返回给用户,后端需要处理一系列的动作(查库存,扣费,发货等等,很有可能需要依赖其他第三方系统),所以如果前端和后端如果没有一个消息队列,前端的流量可能会压垮后端。
2.松耦合设计
生产者只要将数据放进消息队列就完成了任务,至于消费者何时消费数据生产者都不需要关心。这样带来的一个好处是生产者如何发生异常或者变更都不会影响生产者。
kafka的优势
1.百万级TPS
Kafka轻松就能达到百万级的TPS,也是为什么大数据场景下kafka受欢迎的最主要的原因。具体的压测方法参考:
Broker端的参数优化可以参考:
https://gist.github.com/jkreps/c7ddb4041ef62a900e6c#file-server-config-properties-L53
2.数据强一致性
Kafka收到消息后会立马落地,可以配置所有replicate都落地后再让producer返回。CAP原则,kafka提供了充分的参数让用户选择,数据一致性越强吞吐量越低,需要根据业务场景评估。
3.数据可以重复消费
不同于传统的消息队列,队列中的数据只能消费一次。kafka数据能重复消费,队列中的数据消费后,每个消费者通过offset控制自己的消费,多个消费者可以同时消费同一个队列。队列的数据什么时候清理是由broker保存时间配置决定。该特性适合于需要重复加载数据或者多个消费者同时消费一份数据的场景。
4.只要存活一个broker就能提供服务
对于n个broker组成的kafka集群,意外宕机n-1个broke都能保证对外提供服务。
整体介绍
kafka的topic主题是个逻辑意义的队列,或者说是一类队列,内部可以有一个或者多个partition,kafka只保证同一个partition内的消息顺序,也就是说partition是物理意义的消息队列,不同的partition是不同的消息队列。每个partition可以指定一个或者多个副本(replicate),一个leader replicate和n个follower replicate,只有leader replicate提供读写服务,其他的副本只会向leader replicate拉取数据做同步,如果leader replicate异常退出将会从剩下的followe replicate重新选举一个leader。至于其他的副本为什么不像mysql一样提供只读服务?主要原因是kafka是消息队列,一般是一写一读,mysql数据库一般是一写多读,应用场景不一样。
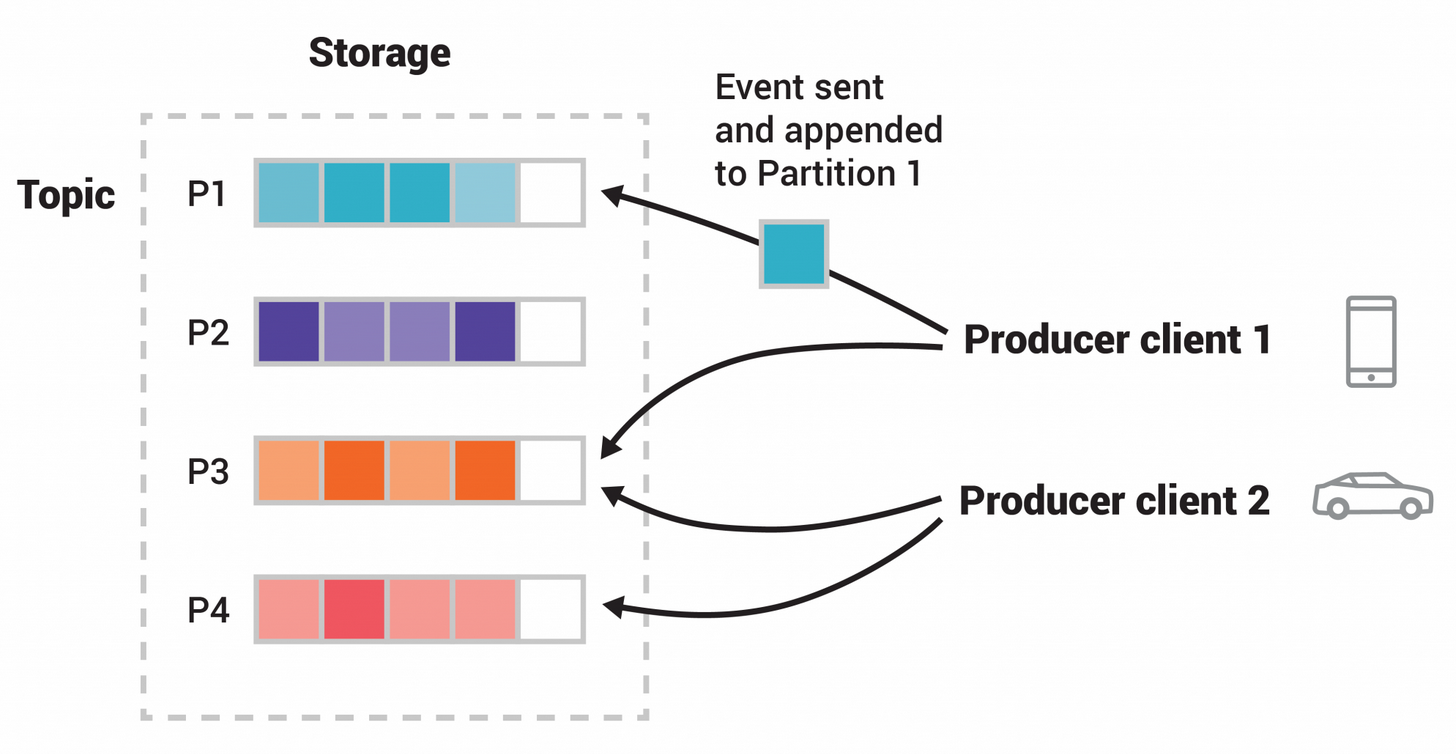
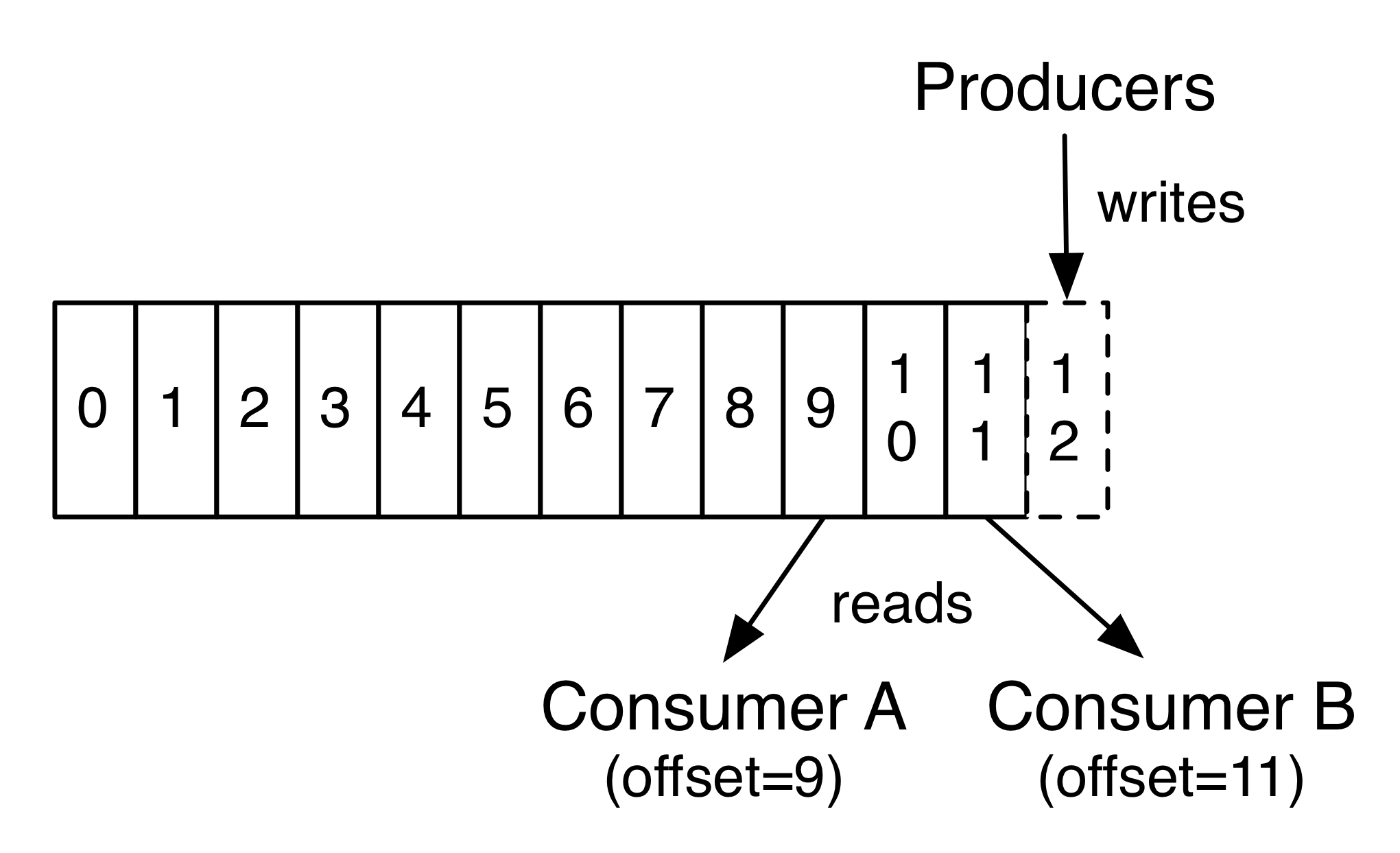
上图是两个生产者往一个topic内的不同partition中写入数据。每个partition会维护一个offset,一般从0开始,每append一条消息+1。offset信息之前版本的kafka是存储在zookeeper,由于频繁读写offset触发zookeeper性能瓶颈,所以较新版本的kafka将这些信息维护在kafka内部的topic中。 kafka也会为每个消费者/消费者组保存offset,记录这个消费者/消费者组上一次的消费位置,以便于消费者/消费者组重启后接着消费,消费者/消费者组也可以指定offset进行消费。
更多细节参考:https://kafka.apache.org/documentation/#introduction
使用注意事项
生产消息
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i))); producer.close();
这里acks指定了all,即需要等待所有的ISR拉取到record之后再返回,是kafka吞吐量最低但是数据一致性最高的做法。ProducerRecord指定了topic,以及record的key和value,但是没有指定partition,如果我们需要指定paritiion可以在topic的后面加上partition,参考下面的方法。
ProducerRecord有多种构造方式:
ProducerRecord(String topic, Integer partition, K key, V value)
Creates a record to be sent to a specified topic and partition
ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers)
Creates a record to be sent to a specified topic and partition
ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
Creates a record with a specified timestamp to be sent to a specified topic and partition
ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)
Creates a record with a specified timestamp to be sent to a specified topic and partition
ProducerRecord(String topic, K key, V value)
Create a record to be sent to Kafka
ProducerRecord(String topic, V value)
Create a record with no key
如果ProducerRecord没有指定record的时间戳,producer默认会添加当前时间的时间戳。kafka最终是否采用record中的时间取决于topic的配置,如果配置为CreateTime将会采用record中的timestamp,如果配置为LogAppendTime则采用kafka broker添加该record时的本机时间。
生产者批量发送消息
producer会为每个partition在本地维护一个buffer,作批量发送数据用,producer调用close方法时会释放buffer。buffer的大小由配置batch.size指定。生产者端指定batch.size 和linger.ms 搭配使用,提升客户端和服务端性能。batch.size值默认为16k,即16k以内的record会打包发送。linger.ms默认为0,即不延时发送。可以适当调大batch.size的大小,会增加批量发送的条数,副作用是会消耗一些本地内存,batch.size是每个partition的批量发送大小。
例如指定batch.size=32k linger.ms=5,那么在5ms内batch.size没有满也会等到5ms再发送,所以linger.ms决定了消息延时的上限。
生产者buffer总内存量大小由配置buffer.memory 决定,默认是32M。如果producer生产数据的速度大于发送给server的速度就会满,写满后producer send数据会阻塞,阻塞等待的最大时长由配置max.block.ms(默认1分钟)决定,超过max.block.ms后会抛TimeoutException异常。
多线程生产者
kafka producer对象是线程安全的,可以多线程共享一个或者多个producer对象。
更多细节参考:https://kafka.apache.org/26/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
消费者
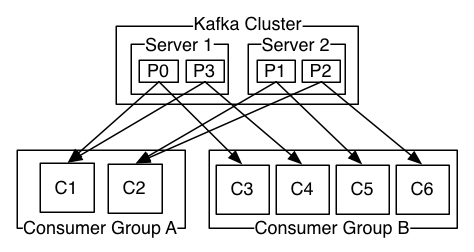
消费者组:指定相同group.id的消费者属于同一个消费者组。一个partition只会分配给同一个group中的其中一个消费者。例如下图中A消费者组中的C1消费者消费P0和P3两个partition,C2消费者消费P1和P2两个partition。B消费者组中的C3,C4,C5,C6分别消费P0,P3,P1,P2 四个partition,如果B消费组有5个消费者,那么会有一个消费者轮空,即没有partition可以消费。使用消费者组一定要注意的一个地方是:当topic/partition/改消费者组内消费者数量任一数量发生变化时,都会触发kafka rebalance,即重新进行负载均衡,在rebalance期间,改消费者组的消费者都不能进行消费。
kafka是如何知道消费者已经异常/退出从而发起rebalance?有两种机制发现:
1.物理链路异常。通过配置session.timeout.ms心跳保活机制,消费者周期性向kafka发送心跳,超过session.timeout.ms时间没有收到心跳则认为消费者已经异常,从而剔除改消费者,重新rebalance,将改消费者负责的partition分给其他消费者。
2.逻辑异常。消费者和kafka server的心跳仍然存活,但是消费者由于内部逻辑异常,比如死锁等,一直没有poll数据。可以通过设置max.poll.interval.ms来限定两次拉取数据间隔的最大值,超过这个时间kafka会判定消费者已经异常/不活跃。从而rebalance。
设置这两个配置一定要慎重,毕竟kafka的rebalance还是有成本的,rebalance期间整个消费者组不能消费数据。
消费场景一:自动提交offset
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
bootstrap.servers kafka server地址,可以是一个或者多个,用于发现其他kafka broker,所以没有必要填写所有的kafka地址,为了高可用写几个就行。
enable.auto.commit/auto.commit.interval.ms 设置自动提交offset和自动提交的周期。
这里需要特别指出的是,设置自动提交有可能会丢失消费数据,有可能poll回来,数据还没有正式消费,但是offset 已经自动提交了,结果消费者异常退出。消费者进程重启后读取kafka存储的offset,那么之前崩溃没有处理的数据将会漏掉,无法感知消费。所以一个可行的办法是,将enable.auto.commit设置为false,while循环消费完后再调用commit。这样做异常崩溃情况下会重复消费部分数据,需要用户自行规避,可以将消息设置为幂等,或者消费体中有序号字段,用户层能够感知到这个消息已经消费过,从而丢弃。即下面的场景二。
消费场景二:手动提交offset
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "false");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer);
consumer.commitSync();
buffer.clear();
}
}
手动管理partition分配
为了避免topic/partition/消费者数量变化频繁引起的rebalance,用户层可以自行管理partition的分配,不用消费者组。
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
然后可以像上面的示例使用while循环poll数据。
多线程consumer
kafka consumer对象不是线程安全的,换言之,不能多个线程用同一个consumer去poll数据。如果一定要这样做,需要用户自行实现多线程同步访问consumer。建议还是一个线程一个独立的consumer,多线程共享一个或者多个consumer对象还涉及到消费数据顺序的问题。
更多细节参考:https://kafka.apache.org/26/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html
高水平API VS 低水平API
kakfa提供high-level 和low-level api供用户使用,可以根据不同的使用场景选择不同的api。
高水平API(high-level api):API已经屏蔽底层topic/partition/offset管理细节,用户调用API只需要指定kafka地址topic名称就能生产和消费数据。比较简单,用户管理力度较弱。
低水平API(low-level api):API暴露底层topic/partition/offset,需要用户自行管理,包括offset保存,然后根据offset seek到特定的位置开始消费,寻找partition leader副本等。比较复杂,用户管理力度较强。
总结
本文介绍了kafka的优缺点,以及围绕生产和消费消息两种场景展开kafka的使用说明以及一些注意事项。下一篇将会介绍代码级别的demo应用。
高吞吐量消息系统—kafka的更多相关文章
- 分布式发布订阅消息系统 Kafka 架构设计[转]
分布式发布订阅消息系统 Kafka 架构设计 转自:http://www.oschina.net/translate/kafka-design 我们为什么要搭建该系统 Kafka是一个消息系统,原本开 ...
- Kafka logo分布式发布订阅消息系统 Kafka
分布式发布订阅消息系统 Kafka kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
- 高吞吐量的分布式发布订阅消息系统Kafka之Producer源码分析
引言 Kafka是一款很棒的消息系统,今天我们就来深入了解一下它的实现细节,首先关注Producer这一方. 要使用kafka首先要实例化一个KafkaProducer,需要有brokerIP.序列化 ...
- 高并发面试必问:分布式消息系统Kafka简介
转载:https://blog.csdn.net/caisini_vc/article/details/48007297 Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成 ...
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 分布式发布订阅消息系统 Kafka 架构设计
我们为什么要搭建该系统 Kafka是一个分布式.分区的.多副本的.多订阅者的“提交”日志系统. 我们构建这个系统是因为我们认为,一个实现完好的操作日志系统是一个最基本的基础设施,它可以替代一些系统来作 ...
- 分布式发布订阅消息系统Kafka
高吞吐量的分布式发布订阅消息系统Kafka--安装及测试 一.Kafka概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览, ...
- 消息系统kafka原理解析
Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Clouder ...
随机推荐
- 用scratch编程大炮打幽灵
首先来看看效果: 是不是很炫酷呢?想知道具体程序的话请关注微信公众号!
- 详解Vue大护法——组件
1.什么是组件化 人面对复杂问题的处理方式: 任何一个人处理信息的逻辑能力都是有限的 所以,当面对一个非常复杂的问题时,我们不太可能一次性搞定一大堆的内容. 但是,我们人有一种天生的能力,就是将问题进 ...
- Redis的字符串底层是啥?为了速度和安全做了啥?
面试场景 面试官:Redis有哪些数据类型? 我:String,List,set,zset,hash 面试官:没了? 我:哦哦哦,还有HyperLogLog,bitMap,GeoHash,BloomF ...
- jenkins集群(四) -- 持续集成
一.jenkins配置git 1.安装源码管理器 git:http://updates.jenkins-ci.org/download/plugins/git/ 去上面的网址中把离线插件下载下来,然 ...
- R 常用基本函数
R 常用的数字.矩阵和数列的处理函数 数值篇 mean() #均值 colMeans() #对列求均值 sum() #求和 max() #最大值 min() #最小值 prod() #连乘 var() ...
- JavaFX让UI更美观-CSS样式
相对于Swing来说,JavaFX在UI上改善了很多,不仅可以通过FXML来排版布局界面,同时也可以通过CSS样式表来美化UI. 其实在开发JavaFX应用的时候,可以将FXML看做是HTML,这样跟 ...
- Blash数组 c++
//输入一个数作为Blash数组的根, //对于该数组的每一个数x,x*2+1 x*3+1均在该数组 //并且该数组没有其他数字 //该数组升序排列 //输入a,n 输出该数组第n个数 // // # ...
- Qt自定义控件之仪表盘1--简单的贴图仪表盘
0.前言 学程序首先要输出hell world,学电子要先来个流水灯.学Qt,那就必须先来个自定义控件,若有人问我从哪个下手,我推荐仪表盘,可简可繁,从低配到高配齐全,可入门也可进阶. 1.仪表盘解析 ...
- Python字符串内建函数_上
Python字符串内建函数: 注:汉字属于字符(既是大写又是小写).数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字. 1.capitalize( ): 将字符串第一个字母大 ...
- 一本通 高手训练 1781 死亡之树 状态压缩dp
LINK:死亡之树 关于去重 还是有讲究的. 题目求本质不同的 具有k个叶子节点的树的个数 不能上矩阵树. 点数很少容易想到装压dp 考虑如何刻画树的形状 发现一个维度做不了 所以. 设状态 f[i] ...