Spark+Kafka实时监控Oracle数据预警
目标: 监控Oracle某张记录表,有新增数据则获取表数据,并推送到微信企业。
流程: Kafka实时监控Oracle指定表,获取该表操作信息(日志),使用Spark Structured Streaming消费Kafka,获取数据后清洗后存入指定目录,Python实时监控该目录,提取文本里面数据并推送到微信。(Oracle一台服务器,Kafka及Spark在另外一台服务器)
架构: Oracle+Kafka+Spark Structured Streaming+Python
centos7
oracle 11g
apache-maven-3.6.3-bin.tar.gz
kafka-connect-oracle-master.zip
hadoop-2.7.1.tar.gz
kafka_2.11-2.4.1.tgz (scala版本必须与系统及连接spark的jar包一致,这里是2.11)
spark-2.4.0-bin-without-hadoop.tgz
spark-streaming-kafka-0-8_2.11-2.4.0.jar
Java 1.8
python 3.6
一、Oracle侧
这边设置比较简单,使用SYS或者SYSTEM账户开启归档日志及附加日志即可,一般实际工作出于数据安全考虑日志都会开启状态,故不再多赘述,有搭建及开启问题可以随时私信。
二、Kafka侧
①配置maven,并添加进环境变量
#下载地址:http://maven.apache.org/download.cgi
#解压 所有配置文件默认放在/usr/local路径
tar xvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
#修改环境变量
vi /etc/profile
#加入下面内容
export MAVEN_HOME=/usr/local/apache-maven
export PATH=$PATH:${MAVEN_HOME}/bin
#刷新配置
source /ect/profile
②配置kafka-connect-oracle-master,config文件按oracle侧信息配置,然后使用maven工具编译。
#压缩包下载地址:https://github.com/erdemcer/kafka-connect-oracle
#解压
unzip kafka-connect-oracle-master.zip
#修改config下的配置文件
vi kafka-connect-oracle-master/config/OracleSourceConnector.properties
#修改内容如下:
db.name.alias=dbserver #oracle实例名称:select instance_name from v$instance
tasks.max=1
topic=cdczztar #kafka主体名称
db.name=DBSERVER #oracle服务器:select name from v$database;
db.hostname=192.168.81.159 #oracle服务器地址
db.port=1521 #oracle端口,一般默认1521
db.user=test #数据库用户名
db.user.password=123456 #数据库密码
db.fetch.size=1
table.whitelist=LINHL.LHL_TEST #需要监控的表名,可以使用*号监控所有,必须大写
table.blacklist= #不监控的表名,没有为空,缺少该行会报错
parse.dml.data=true
reset.offset=true
start.scn=
multitenant=false
#编译 ,成功会有提示,并生成target文件夹
cd /usr/local/kafka-connect-oracle-master
mvn clean package
③解压kafka,并放入前面master文件夹下的几个jar包及配置文件
#解压 下载地址:http://kafka.apache.org/downloads
tar xvf kafka_2.11-2.4.1.tgz -C /usr/local/
#改名
mv ./kafka_2.11-2.4.1 ./kafka
#复制配置文件
cp /usr/local/kafka-connect-oracle-master/target/kafka-connect-oracle-1.0.71.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/lib/ojdbc7.jar /usr/local/kafka/libs/
cp /usr/local/kafka-connect-oracle-master/config/OracleSourceConnector.properties /usr/local/kafka/config/
④开启Kafka
#进入Kafka文件夹
cd /usr/local/kafka/bin/
#下面全都在单独的窗口开启服务,勿关闭窗口,测试状态,故没有在后台运行
#启动zookeeper
./zookeeper-server-start.sh ../config/zookeeper.properties
#启动kafka服务
./kafka-server-start.sh ../config/server.properties
#建立topic-cdczztar
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic cdczztar
#查看所有topic
./kafka-topics.sh --zookeeper localhost:2181 --list
#启动连接oracle
./connect-standalone.sh ../config/connect-standalone.properties ../config/OracleSourceConnector.properties
#启动消费端
#消费端此处只是为了展示用,后续使用spark做消费端
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic cdczztar
三、Spark侧
Structured Streaming需要启用HDFS,这里都在本地测试环境实现,因此关于java及hadoop的安装,可以参考这篇的伪分布式配置dblab.xmu.edu.cn/blog/install-hadoop
①配置
#解压 #官网可以下载,没有资源请私信
tar -zxf spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/
#重命名
mv ./spark-2.4.0-bin-without-hadoop ./spark
#修改配置文件
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
vi ./conf/spark-env.sh
#加入下面内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):/usr/local/spark/examples/jars/*:/usr/local/spark/jars/kafka/*:/usr/local/kafka/libs/*
#修改系统环境变量
vi /etc/profile
#加入下面内容
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export JAVA_HOME=/opt/java/jdk1.8.0_261
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin:/usr/local/hbase/bin
export SPARK_HOME=/usr/local/spark
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:/usr/local/python3/lib/python3.6/site-packages/:$PYTHONPATH
export PYSPARK_PYTHON=python3
export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
#更新配置
source /etc/profile
#在jars目录建立kafka文件夹,把kafka所有jar包放到该目录
cp /usr/local/spark-streaming-kafka-0-8_2.11-2.4.0.jar /usr/local/spark/jars/kafka
cp /usr/local/kafka/libs/* /usr/local/spark/jars/kafka
②Structured Streaming脚本建立
#!/usr/bin/env python3
import re
from functools import partial
from pyspark.sql.functions import *
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("StructuredKafkaWordCount") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN') #只提示警示信息
lines = spark \ #使用spark streaming则是基于KakfkaUtils包使用createDirectStream
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", 'cdczztar') \ #要消费的topic
.load().selectExpr("CAST(value AS STRING)")
#lines.printSchema()
#正则处理,根据实际数据处理,kafka获取后是oracle日志,在这只提取表插入的值
pattern = 'data":(.+)}'
fields = partial(regexp_extract, str="value", pattern=pattern)
words = lines.select(fields(idx=1).alias("values"))
#输出模式:存入文件
query = words \
.writeStream \
.outputMode("append") \
.format("csv") \
.option("path","file:///tmp/filesink") \ #存到服务器地址
.option("checkpointLocation","file:///tmp/file-sink-cp") \
.trigger(processingTime="10 seconds") \
.start()
query.awaitTermination()
#新开一个服务器窗口运行,这边已经在代码目录下
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.0 spark.py
③运行python实时打开写入的文件,提取信息并推送到微信端
import csv
import pyinotify #这个包只支持linux,如果是window系统可以使用watchdog,一个原理及写法
import time
import requests
import json
import datetime
import pandas as pd
CORPID = "******" #企业微信id
SECRET = "*******" #企业微信密钥
AGENTID = 1000041 #企业微信端口
multi_event = pyinotify.IN_CREATE #只对create这个动作做监控
wm = pyinotify.WatchManager()
#继承ProcessEvent后,对process_IN_CREATE方法重写
class MyHandler(pyinotify.ProcessEvent):
def send_msg_to_wechat(self, content):
record = '{}\n'.format(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
s = requests.session()
url1 = "https://qyapi.weixin.qq.com/cgi-bin/gettoken?corpid={0}&corpsecret={1}".format(CORPID, SECRET)
rep = s.get(url1)
record += "{}\n".format(json.loads(rep.content))
if rep.status_code == 200:
token = json.loads(rep.content)['access_token']
record += "获取token成功\n"
else:
record += "获取token失败\n"
token = None
url2 = "https://qyapi.weixin.qq.com/cgi-bin/message/send?access_token={}".format(token)
header = {
"Content-Type": "application/json"
}
form_data = {
"touser": "@all",
"toparty": " PartyID1 | PartyID2 ",
"totag": " TagID1 | TagID2 ",
"msgtype": "text",
"agentid": AGENTID,
"text": {
"content": content
},
"safe": 0
}
rep = s.post(url2, data=json.dumps(form_data).encode('utf-8'), headers=header)
if rep.status_code == 200:
res = json.loads(rep.content)
record += "发送成功\n"
else:
record += "发送失败\n"
res = None
return res
def process_IN_CREATE(self, event):
try:
if '_spark_metadata' in event.pathname or '.crc' in event.pathname:
pass
else:
print(event.pathname)
f_path = event.pathname
#此处坑,streaming那边生成文件还没写入数据就会触发该任务,不sleep打开的是空白文件
time.sleep(5)
df = pd.read_csv(r'' + f_path, encoding='utf8', names=['value'], sep='/')
send_str = df.iloc[0, 0].replace('\\', '').replace(',"before":null}', '').replace('"','')
print(send_str)
self.send_msg_to_wechat('中间库预警:' + send_str)
except:
pass
handler = MyHandler()
notifier = pyinotify.Notifier(wm,handler)
wm.add_watch('/tmp/filesink/',multi_event)
notifier.loop()
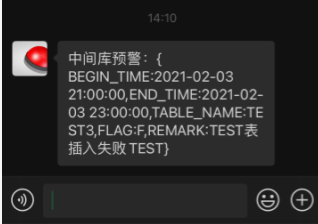
微信端消息如下:
四、问题点
还有下面几个问题还没实现,有思路还请随时评论私信交流,感谢
在structured streaming消费了kafka信息后,是否可以直接把消息推送到微信端口?
python监控文件有新增文件路径可以即时获取,但是要获取内容需要等待数据写入,sleep的方式不稳定,是否有方法可以判断数据已经写完就读取该文件?
学习交流,有任何问题还请随时评论指出交流。
Spark+Kafka实时监控Oracle数据预警的更多相关文章
- Android(Linux)实时监控串口数据
之前在做WinCE车载方案时,曾做过一个小工具TraceMonitor,用于显示WinCE系统上应用程序的调试信息,特别是在实车调试时,用于监控和显示CAN盒与主机之间的串口数据.因为需要抢占市场先机 ...
- 大数据Spark+Kafka实时数据分析案例
本案例利用Spark+Kafka实时分析男女生每秒购物人数,利用Spark Streaming实时处理用户购物日志,然后利用websocket将数据实时推送给浏览器,最后浏览器将接收到的数据实时展现, ...
- html 实时监控发送数据
我们都知道ajax可以做异步提交,可以从一个文件里得到返回的数据,如此便能够实时的得到数据,实时刷新页面,如下代码 setInterval(function(){ $.ajax({ url:'demo ...
- linux实时监控并实时备份数据(rsync)
目录 一:rsync实时监控备份流程 1.安装rsync(服务端 与 客服端)守护进程模式 2.修改配置文件(服务端) 3.解析配置内容 4.创建系统用户 5.创建密码文件 6.授权(必须授权为600 ...
- Linux/Unix shell 监控Oracle告警日志(monitor alter log file)
使用shell脚本实现对Oracle数据库的监控与管理将大大简化DBA的工作负担,如常见的对实例的监控,监听的监控,告警日志的监控,以及数据库的备份,AWR report的自动邮件等.本文给出Linu ...
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
本篇文章内容来自2016年TOP100summit Microsoft资深产品经理邢国冬的案例分享.编辑:Cynthia 邢国冬(Tony Xing):Microsoft资深产品经理.负责微软应用与服 ...
- kafka实时流数据架构
初识kafka https://www.cnblogs.com/wenBlog/p/9550039.html 简介 Kafka经常用于实时流数据架构,用于提供实时分析.本篇将会简单介绍kafka以及它 ...
- Debezium SQL Server Source Connector+Kafka+Spark+MySQL 实时数据处理
写在前面 前段时间在实时获取SQLServer数据库变化时候,整个过程可谓是坎坷.然后就想在这里记录一下. 本文的技术栈: Debezium SQL Server Source Connector+K ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
随机推荐
- 【并发编程】- 内存模型(针对JSR-133内存模型)篇
并发编程模型 1.两个关键问题 1)线程之间如何通信 共享内存 程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信 消息传递 程之间没有公共状态,线程之间必须通过发送消息来显式进行通信 ...
- ARM杂散知识
画重点: 1.存储器格式:重点是大小端识别 经常考 2.对齐后结构体占用空间大小:使用aligned,packed,#pragma pack()三种方式都要会 Thumb指令集 Thumb指令集能够以 ...
- .NET 云原生架构师训练营(模块二 基础巩固 MongoDB API重构)--学习笔记
2.5.8 MongoDB -- API重构 Lighter.Domain Lighter.Application.Contract Lighter.Application LighterApi Li ...
- netcore项目中使用 SpringCloudConfig 和apollo做配置中心
版权所有,转载请注明出处 https://www.cnblogs.com/netqq/p/14251403.html 一.使用apollo作为配置中心 首先apollo 项目简介和安装请自行百度,本文 ...
- DAS、SAN和NAS三种服务器存储方式 (转)
转 :https://blog.csdn.net/fgf00/article/details/52592651 2016年09月20日 09:04:00 凌_风 一.存储的分类根据服务器类型分为 ...
- CS系统中分页控件的制作
需求:在一个已有的CS项目(ERP中),给所有的列表加上分页功能. 分页的几个概念: 总记录数 totalCount (只有知道了总记录数,才知道有多少页) 每页记录数 pageSize (根据总 ...
- 【JDBC核心】JDBC 概述
JDBC 概述 数据的持久化 持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用.大多数情况下,特别是企业级应用,数据持久化意味着将内存中的数据保存到硬盘上加以"固 ...
- Java进阶专题(二十一) 消息中间件架构体系(3)-- Kafka研究
前言 Kafka 是一款分布式消息发布和订阅系统,具有高性能.高吞吐量的特点而被广泛应用与大数据传输场景.它是由 LinkedIn 公司开发,使用 Scala 语言编写,之后成为 Apache 基金会 ...
- 【MySQL】汇总数据 - avg()、count()、max()、min()、sum()函数的使用
第12章 汇总数据 文章目录 第12章 汇总数据 1.聚集函数 1.1.AVG()函数 avg() 1.2.COUNT()函数 count() 1.3. MAX()函数 max() 1.4.MIN() ...
- 【Git】Git初始化一个仓库
文章目录 初始化仓库 检查当前文件状态 跟踪新文件 提交更新 跳过使用暂存区域 移除文件 添加远程仓库 推送到远程仓库 简单记录-慕课网 从0开始 独立完成企业级Java电商网站开发 Git初始化一个 ...