MapReduce工作原理详解
MapReduce简介
MapReduce有哪些角色?各自的作用是什么?
MapReduce程序执行流程
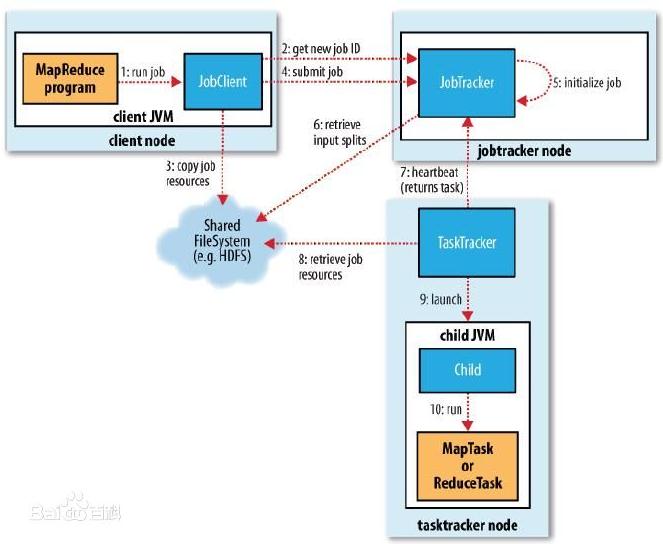
MapReduce工作原理
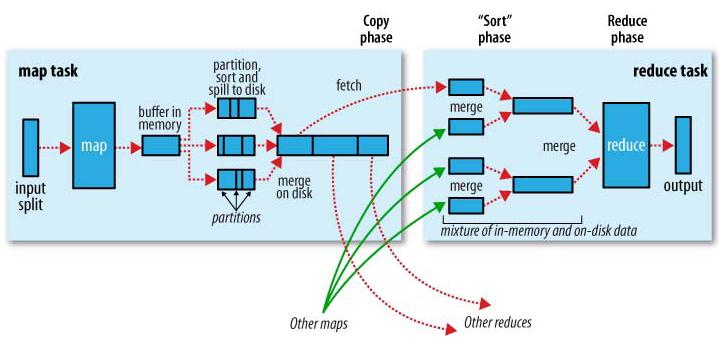
reduce task
MapReduce中Shuffle过程


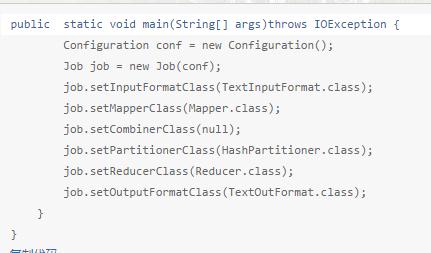
MapReduce编程主要组件
针对MapReduce的缺点,YARN解决了什么?
MapReduce工作原理详解的更多相关文章
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- Hadoop MapReduce八大步骤以及Yarn工作原理详解
Hadoop是市面上使用最多的大数据分布式文件存储系统和分布式处理系统, 其中分为两大块分别是hdfs和MapReduce, hdfs是分布式文件存储系统, 借鉴了Google的GFS论文. MapR ...
- ASP.NET页面与IIS底层交互和工作原理详解
转载自:http://www.cnblogs.com/lidabo/archive/2012/03/13/2393200.html 第一回: 引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是 ...
- ASP.NET页面与IIS底层交互和工作原理详解(第一回)
引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是站在一个比较高的层次上讲解Asp.Net.他们耐心.细致地告诉你如何一步步拖放控件.设置控件属性.编写CodeBehind代码,以实现某个特定 ...
- 交换机工作原理、MAC地址表、路由器工作原理详解
一:MAC地址表详解 说到MAC地址表,就不得不说一下交换机的工作原理了,因为交换机是根据MAC地址表转发数据帧的.在交换机中有一张记录着局域网主机MAC地址与交换机接口的对应关系的表,交换机就是根据 ...
- HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
- 【转】HTTP响应报文与工作原理详解
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
- HTTP响应报文与工作原理详解(转)
超文本传输协议(Hypertext Transfer Protocol,简称HTTP)是应用层协议.HTTP 是一种请求/响应式的协议,即一个客户端与服务器建立连接后,向服务器发送一个请求;服务器接到 ...
随机推荐
- element-ui upload上传文件并携带参数 使用formData对象
需求:上传文件的时候,需要携带其他的参数 问题:使用upload上传文件时,必须使用formData对象,而其他的参数通过data获取的到的,formData和data是不能同时传输的 解决:获取到的 ...
- MySQL手注之报错注入
报错注入: 指在页面中没有一个合适的数据返回点的情况下,利用mysql函数的报错来创造一个显位的注入.先来了解一下报错注入常用的函数 XML:指可扩展标记语言被设计用来传输和存储数据. concat: ...
- zookeeper watch笔记
ZK其核心原理满足CP, 实现的是最终一致性, 它只保证顺序一致性. zookeeper 基于 zxid 以及阻塞队列的方式来实现请求的顺序一致性.如果一个client连接到一个最新的 followe ...
- JavaScript函数报错SyntaxError: expected expression, got ';'
故事背景:编写Javaweb项目,在火狐浏览器下运行时firebug报错SyntaxError: expected expression, got ';'或者SyntaxError: expected ...
- [VBA原创源代码] excelhome 汇总多工作表花名册
生病了,一点一滴的积累,慢慢康复,今年十月,我就 2 周岁了. 以下代码完成了excelhome中留的作业 http://club.excelhome.net/forum.php?mod=viewth ...
- shiro入门学习--使用MD5和salt进行加密|练气后期
写在前面 在上一篇文章<Shiro入门学习---使用自定义Realm完成认证|练气中期>当中,我们学会了使用自定义Realm实现shiro数据源的切换,我们可以切换成从关系数据库如MySQ ...
- uint16_t
转自:https://blog.csdn.net/kiddy19850221/article/details/6655066 uint8_t / uint16_t / uint32_t /uint64 ...
- P6810 「MCOI-02」Convex Hull 凸包
Link 一句话题意: 求出 \(\displaystyle\sum_{i=1}^{n}\sum_{j=1}^{m}\tau(i)\tau(j)\tau(gcd(i,j))\) 前置知识 \(diri ...
- SDK测试操作文档
准备所需材料 先把下列所需压缩包和文件传到虚拟机中. crypto-config压缩包存放order和peer节点所需要的证书文件(需要的是申请联盟链中的order和peer的证书文件) m2压缩包是 ...
- synchronized、volatile区别、synchronized锁粒度、模拟死锁场景、原子性与可见性
synchronized.volatile区别.synchronized锁粒度 synchronized synchronized是Java中的关键字,是一种同步锁.有以下几种用法: 用法 1.修饰方 ...