谁说Cat不能做链路跟踪的,给我站出来
背景
链路跟踪,我们有很多可选项。常见的有 zipkin,pinpoint,skywalking,jaeger 等。
基本上都是根据谷歌的《Dapper 大规模分布式系统的跟踪系统》这篇论文发展出来的。
今天讲下 Cat 里的链路跟踪要如何来实现,没用过 Cat 的同学可以查看我的这篇文章 《熬夜之作:一文带你了解 Cat 分布式监控》进行了解。
在 Cat 中可以很方便的看到每个请求的总耗时以及业务操作,数据库操作的耗时情况。对于服务之间的调用也可以通过埋点的方式进行监控。
如下图,可以看出请求内发起了一次 RPC 的调用,callRPC 开头的那条记录。耗时 11ms, 但是这个 RPC 服务内部耗时花在哪里了,在这边不能直接查看,只能去另一个服务中查看,不是很方便。

详细的我画了一张图说明下现在的问题:

从上图可以看出,一个请求经过了多个服务,每个服务中对远程调用或者本地调用都有埋点,这样就能监控到调用的异常和性能指标。
下面一部分是在 Cat 中我们去查看这些指标的场景,Cat 中的数据展示是以项目维度来展示的,所以每个服务都有自己的监控数据。
如果我想要知道刚刚那次请求,在整个链路中哪里最慢,耗时在哪里,我得分别去 4 个服务下面才能看到这些信息,不直观。
实现方式
如下图所示:
从网关到服务,从服务到服务,都需要将 Trace 信息进行传递才可以将整个链路串起来。只有串起来了才可以在 Cat 中查看到整个链路的耗时信息。
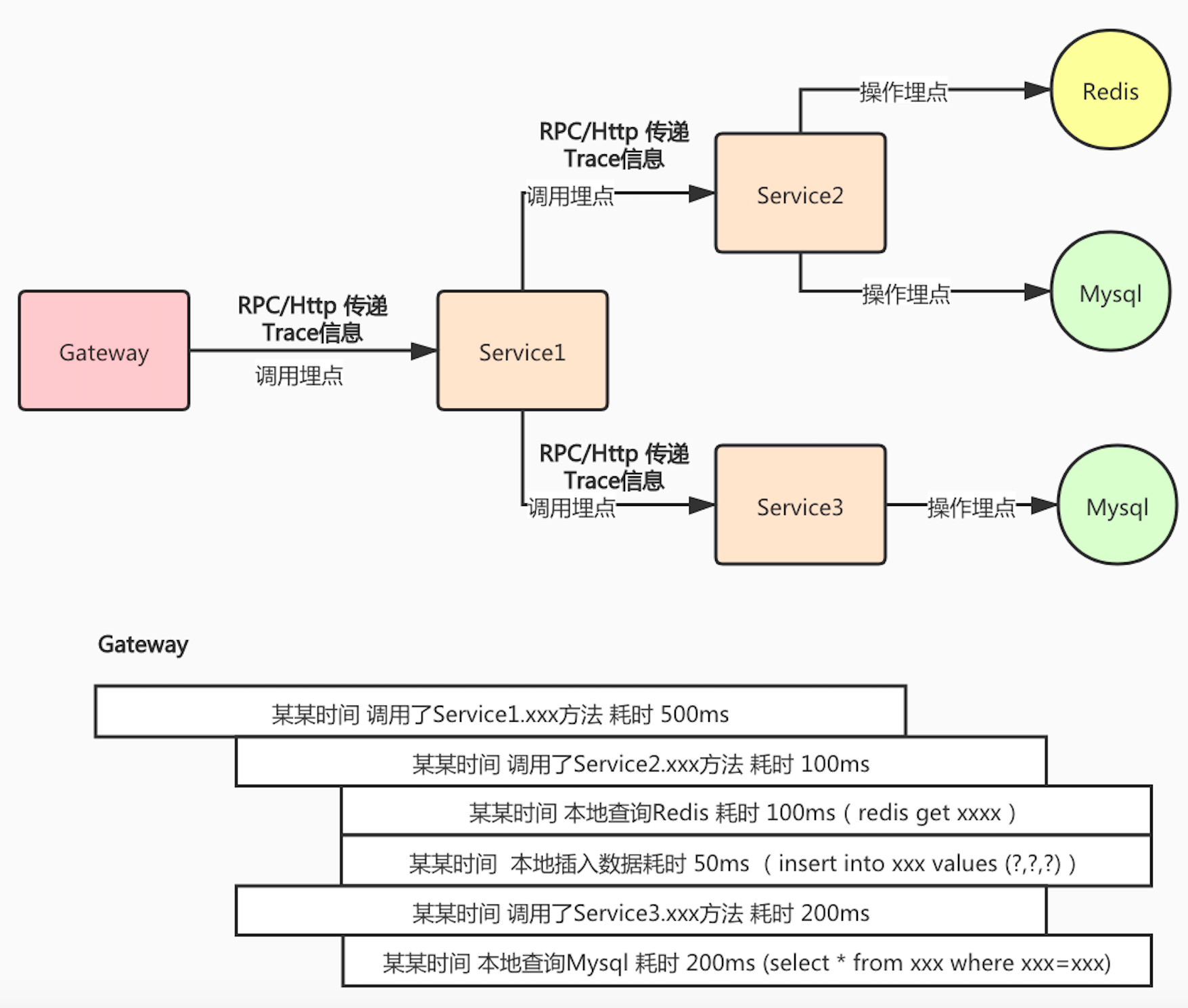
本文需要实现的效果就是可以在请求的入口处(网关),查看到这个请求经过的所有服务,每个服务中的耗时情况。
要想将整个请求都串连起来,必须要有一个唯一的请求标识,一般我们称之为 traceId。剩余的工作就是将链路相关的信息层层传递下去。
首先在每个服务的过滤器中进行请求头信息的接收,比如从网关到服务 A,那么服务 A 需要接收这些信息然后传递给下一个服务。
HTTP 请求的消息树构建:
// 构建远程消息树if(request.getHeader(CatConstantsExt.CAT_HTTP_HEADER_ROOT_MESSAGE_ID) != null){
CatContext catContext = new CatContext();
catContext.addProperty(Cat.Context.ROOT,request.getHeader(CatConstantsExt.CAT_HTTP_HEADER_ROOT_MESSAGE_ID));
catContext.addProperty(Cat.Context.PARENT,request.getHeader(CatConstantsExt.CAT_HTTP_HEADER_PARENT_MESSAGE_ID));
catContext.addProperty(Cat.Context.CHILD,request.getHeader(CatConstantsExt.CAT_HTTP_HEADER_CHILD_MESSAGE_ID));
Cat.logRemoteCallServer(catContext);
}
将消息树的信息传递给下个服务的话就要看你用的调用方式是什么,如果用 Feign 或者 RestTemplate 都可以利用拦截器来实现传递。
public class FeignRequestInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate template) {
CatContext catContext = new CatContext();
Cat.logRemoteCallClient(catContext,Cat.getManager().getDomain());
template.header(CatConstantsExt.CAT_HTTP_HEADER_ROOT_MESSAGE_ID, catContext.getProperty(Cat.Context.ROOT));
template.header(CatConstantsExt.CAT_HTTP_HEADER_PARENT_MESSAGE_ID, catContext.getProperty(Cat.Context.PARENT));
template.header(CatConstantsExt.CAT_HTTP_HEADER_CHILD_MESSAGE_ID, catContext.getProperty(Cat.Context.CHILD));
}
}
如果用的是 Dubbo 的话可以用 Dubbo 的 Filter 来实现相同的效果。
最终的效果如下图,调用了 articles/newest 接口,网关将请求转发到 article-provider 服务,article-provider 中又调用了 user-provider 的 users/uid 接口获取用户信息,最重要的是 user-provider 中有哪些操作的耗时在这里也能直观的看到,非常方便。

完整源码参考: https://github.com/yinjihuan/kitty
谁说Cat不能做链路跟踪的,给我站出来的更多相关文章
- go-micro集成链路跟踪的方法和中间件原理
前几天有个同学想了解下如何在go-micro中做链路跟踪,这几天正好看到wrapper这块,wrapper这个东西在某些框架中也称为中间件,里边有个opentracing的插件,正好用来做链路追踪.o ...
- Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin【Finchley 版】
Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] 发表于 2018-04-24 | 随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请 ...
- SpringCloud-分布式链路跟踪配置详解
SpringCloud-分布式链路跟踪 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and ...
- spring-cloud-sleuth 和 分布式链路跟踪系统
==================spring-cloud-sleuth==================spring-cloud-sleuth 可以用来增强 log 的跟踪识别能力, 经常在微服 ...
- 【spring cloud】spring cloud Sleuth 和Zipkin 进行分布式链路跟踪
spring cloud 分布式微服务架构下,所有请求都去找网关,对外返回也是统一的结果,或者成功,或者失败. 但是如果失败,那分布式系统之间的服务调用可能非常复杂,那么要定位到发生错误的具体位置,就 ...
- 分布式链路跟踪系统架构SkyWalking和zipkin和pinpoint
Net和Java基于zipkin的全链路追踪 https://www.cnblogs.com/zhangs1986/p/8966051.html 在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框 ...
- Zipkin和微服务链路跟踪
https://cloud.tencent.com/developer/article/1082821 Zipkin和微服务链路跟踪 本期分享的内容是有关zipkin和分布式跟踪的内容. 首先,我们还 ...
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- Go微服务全链路跟踪详解
在微服务架构中,调用链是漫长而复杂的,要了解其中的每个环节及其性能,你需要全链路跟踪. 它的原理很简单,你可以在每个请求开始时生成一个唯一的ID,并将其传递到整个调用链. 该ID称为Correlati ...
随机推荐
- QQ群消息监听并将消息存储到SQLite数据库中
目录 一.前言 二.效果图 1.插件界面 2.SQLite数据库 3.QQ群消息 三.准备工作 1.CQA软件 2.CQA-SDK易语言版本 3.易语言破解版 4.使用到的相关模块 四.开始撸代码 五 ...
- Maven 专题(八):配置(一)常用修改配置
修改配置文件 通常我们需要修改解压目录下conf/settings.xml文件,这样可以更好的适合我们的使用. 此处注意:所有的修改一定要在注释标签外面,不然修改无效.Maven很多标签都是给的例子, ...
- 数据可视化实例(五): 气泡图(matplotlib,pandas)
https://datawhalechina.github.io/pms50/#/chapter2/chapter2 关联 (Correlation) 关联图表用于可视化2个或更多变量之间的关系. 也 ...
- 网络编程-UDP、TCP
总结
- 【Nginx】如何按日期分割Nginx日志?看这一篇就够了!!
写在前面 Nginx是没有以日期格式作为文件名来存储的,也就是说,Nginx不像Tomcat,每天自动生成一个日志文件,所有的日志都是以一个名字来存储,时间久了日志文件会变得很大.这样非常不利于分析. ...
- Oracle数据泵详解
一.EXPDP和IMPDP使用说明 Oracle Database 10g引入了最新的数据泵(Data Dump)技术,数据泵导出导入(EXPDP和IMPDP)的作用 1)实现逻辑备份和逻辑恢复. 2 ...
- Burp Suite Scanner Module - 扫描模块
Burp Suite Professional 和Enterprise Version的Scaner功能较丰富. 以Professional版本为例,包含Issue activity, Scan qu ...
- 五大高效的PDF文件搜索引擎
当你花了半个多小时在线搜索PDF文档,却发现您找到的文档都不是您需要的PDF格式.如前说述,您可以先打开PDF文档查看是不是PDF格式的,然后再到web浏览器中下载该文档.那么,为了确保您获得的文档是 ...
- js JQ动态添加div标签
function renderList(data){ var str = ''; for(var i = 0; i < data.length; i++){ // 动态添加li str += ' ...
- Python3的一些基本输入输出
# python3 # 基本输入输出 #学会使用split()的使用是关键,input()的返回值一定是字符类型 .-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-.-. ...