mysql优化:explain 和 profile
此文转自:https://blog.csdn.net/hanjungua8144/article/details/84317829
一、SQL查询语句优化基本思路和原则
优化更需要优化的Query。
定位优化对象的性能瓶颈。
明确优化目标。
从Explain入手。
多使用Profile。
永远用小结果集驱动大的结果集。
尽可能在索引中完成排序。
只取自己需要的Columns。
仅仅使用最有效的过滤条件。
尽可能避免复杂的Join和子查询
二、从explain入手
用explain进行分析执行计划,并解释各个值
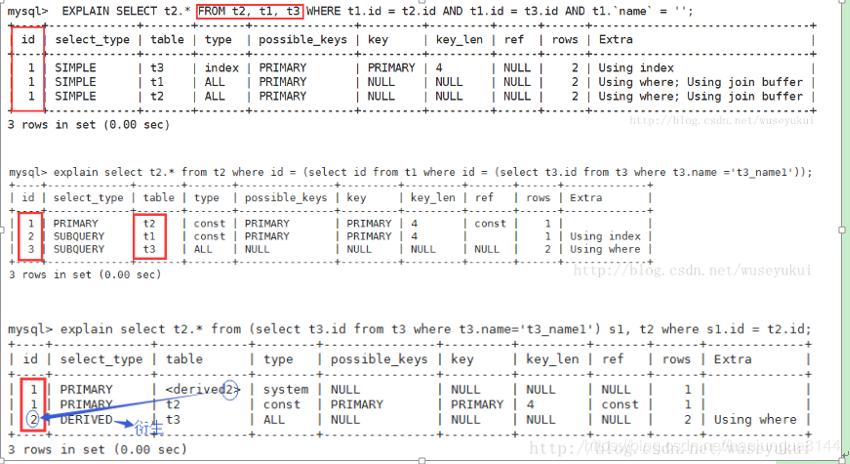
id 这个id不是主键的意思,他是用来标识select查询的序列号,包含一组数字,表示查询中执行select子句或者操作表的顺序。会出现以下情况:
id相同:按从上到下顺序执行。
id不同:id值越大,优先级越高,越先被执行。
id相同不同的同时存在:优先执行id值大的,如果id值相同,则按从上到下的顺序执行。
id为null表示是用来合并结果集的,在sql使用union关键字合并结果集就会出现他。
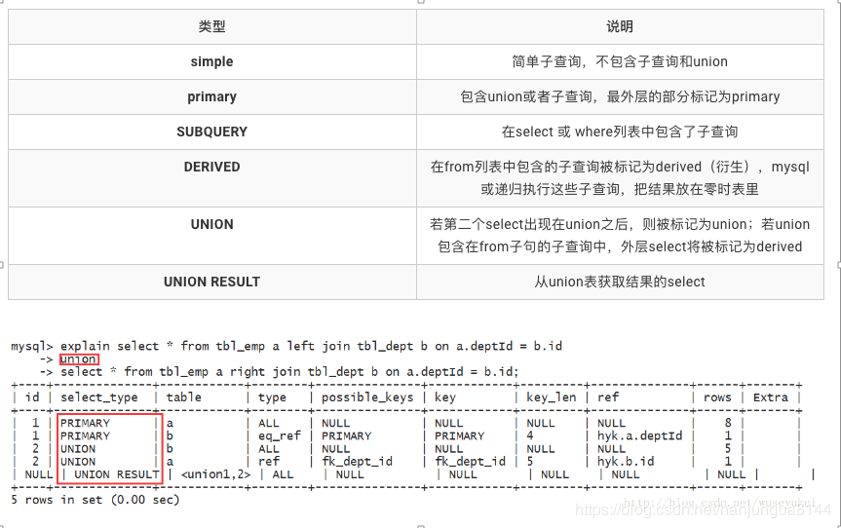
- select_type
- type
访问类型,sql查询优化中一个很重要的指标,结果值从好到坏依次是:
system>const>eq_ref>ref>fulltext >ref_or_null >index_merge >unique_subquery >index_subquery >range>index>ALL
system 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计。
const 表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。因为只需匹配一行数据,所有很快。如果将主键置于where列表中,mysql就能将该查询转换为一个const。
eq_ref 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
ref 非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。
range 只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。
index Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)。
ALL Full Table Scan,遍历全表以找到匹配的行。
- key
实际使用的索引,如果为NULL,则没有使用索引。
查询中如果使用了覆盖索引,则该索引仅出现在key列表中

- key_len
表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len是根据表定义计算而得的,不是通过表内检索出的。
- ref
显示索引的那一列被使用了,如果可能,是一个常量const。
- rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数。
- Extra
不适合在其他字段中显示,但是十分重要的额外信息
1、Using filesort mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为“文件排序”。

2、Using temporary 使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by。
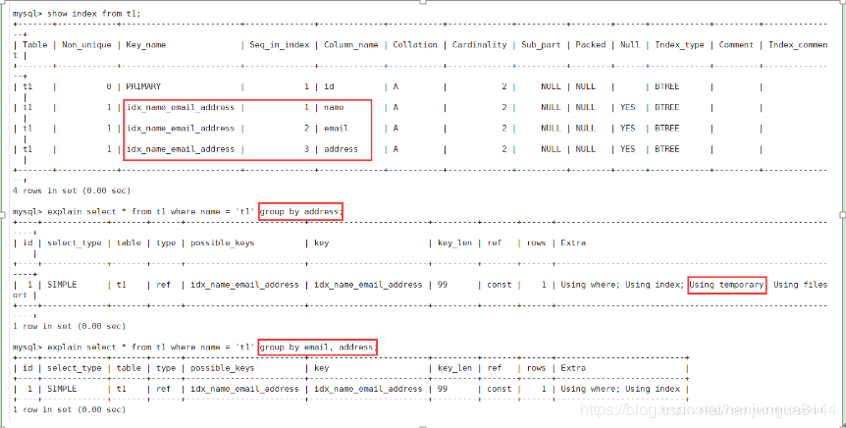
3、Using index 表示相应的select操作中使用了覆盖索引,避免了访问表的数据行,效率高。如果同时出现Using where,表明索引被用来执行索引键值的查找(参考上图)如果没用同时出现Using where,表明索引用来读取数据而非执行查找动作 。
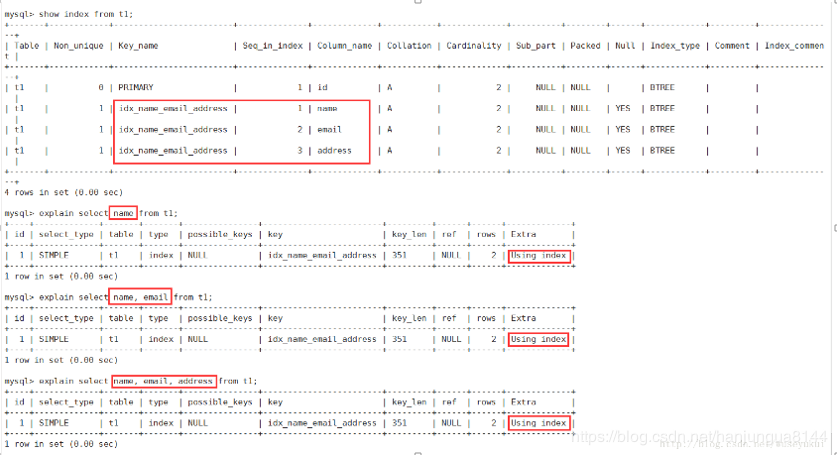
覆盖索引: 也叫索引覆盖。就是select列表中的字段,只用从索引中就能获取,不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
注意:
a、如需使用覆盖索引,select列表中的字段只取出需要的列,不要使用select *。
b、如果将所有字段都建索引会导致索引文件过大,反而降低crud性能。
三、多使用Profile
要想优化一条SQL,就必须清楚这条SQL的查询性能瓶颈到底在哪里,是消耗的CPU计算太多还是IO操作太多。通过QUERY Profiler功能,可以分析多种资源的消耗情况,如CPU、IO、IPC、SWAP等,同时还能得到该QUERY执行过程中MySQl所调用的各个函数在源文件中的位置。
先开启profile功能
使用命令 set profiling = 1 可以开启关闭的功能。
开启profile功能后,MySQl就会自动记录所有执行的QUERY的Profile信息。如执行SQL
查看所有执行的QUERY的Profile信息
使用命令show profiles 获取当前系统中保存的多个QUERY的profile信息
获取单个QUERY的详细的profile信息
show profile cpu,block io,IPC,SOURCE,SWAPS for query Query_ID;
All 显示所有性能信息
BLOCK IO 显示块IO操作的次数
CONTEXT SWITCHES 显示上下文切换次数,不管是主动还是被动
CPU 显示用户CPU时间、系统CPU时间
IPC 显示发送和接收的消息数量
PAGE FAULTS 显示页错误数量
SOURCE 显示源码中的函数名称与位置
SWAPS 显示SWAP的次数
mysql优化:explain 和 profile的更多相关文章
- 一次浴火重生的MySQL优化(EXPLAIN命令详解)
一直对SQL优化的技能心存无限的向往,之前面试的时候有很多面试官都会来一句,你会优化吗?我说我不太会,这时可能很多人就会有点儿说法了,比如会说不要使用通配符*去检索表.给常常使用的列建立索引.还有创建 ...
- mysql优化:explain分析sql语句执行效率
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优 ...
- mysql优化——explain详解
MySQL的EXPLAIN命令用于SQL语句的查询执行计划(QEP).这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的.这条命令并没有提供任何调整建议,但它能够提供重要的信息 ...
- MySQL优化Explain命令简介(一)
最近碰到MySQL需要写入大量数据并查询的场景,于是学习了一下MySQL的查询优化,想找关于explain命令的详细资料,然而网上并没有找全,最后终于在<高性能MySQL>中找到了对这一命 ...
- mysql优化 explain index
本文章属于转载,尊重原创:http://www.2cto.com/database/201501/369135.html 实验环境: 1.sql工具:Navicat 2.sql数据库,使用openst ...
- mysql优化--explain关键字
MySQL性能优化---EXPLAIN 参见:https://blog.csdn.net/jiadajing267/article/details/81269067 参见:https://www.cn ...
- mysql优化–explain分析sql语句执行效率
Explain命令在解决数据库性能上是第一推荐使用命令,大部分的性能问题可以通过此命令来简单的解决,Explain可以用来查看SQL语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优 ...
- MySQL优化Explain命令简介(二)
type列 MySQL手册上注明type列用于描述join type,不过我们认为把这一列视为对access type--即MySQL决定如何在表中寻找数据的方式的描述,更加合适一些,以下所示从最坏情 ...
- mysql优化----explain的列分析
sql语句优化: : sql语句的时间花在哪儿? 答: 等待时间 , 执行时间. 等待时间:看是不是被锁住了,那就不是语句层面了是服务端层面了,看连接数内存. 执行时间:到底取出多少行,一次性取出1万 ...
- MySQL优化:explain using temporary
什么时候会使用临时表:group/order没设计好的时候 1.order没用索引 2.order用了索引, 但不是和where相同的索引 3.order用了两个索引, 但不是联合索引 4.order ...
随机推荐
- 返回报文变成xml格式了!
首先,google chrome之前有安装jsonview插件: 然后,自己弄springCloud项目,搭建eureka后,访问url发现返回报文变成xml格式了,一通摸索及查找,现整理如下: 1. ...
- 【Blazor】在ASP.NET Core中使用Blazor组件 - 创建一个音乐播放器
前言 Blazor正式版的发布已经有一段时间了,.NET社区的各路高手也创建了一个又一个的Blazor组件库,其中就包括了我和其他小伙伴一起参与的AntDesign组件库,于上周终于发布了第一个版本0 ...
- 简单shellcode学习
本文由“合天智汇”公众号首发 作者:hope 引言 之前遇到没开启NX保护的时候,都是直接用pwtools库里的shellcode一把梭,也不太懂shellcode代码具体做了些什么,遇到了几道不能一 ...
- Django中的request到底有啥属性
Django中的request到底有啥属性呢 Request 我们知道当URLconf文件匹配到用户输入的路径后,会调用对应的view函数,并将 HttpRequest对象 作为第一个参数传入该函 ...
- 题解:2018级算法第一次上机 C1-pair
题目描述 北航2018级软件学院算法分析与设计第一次上机第三题 样例 实现解释 题目类型: 这类题目其实就是典型的递归分析语句形式的问题,也是编译原理课程中语法分析的重要方法之一. 解决方案: 为了解 ...
- 数据可视化之powerBI基础(三)编辑交互,体验更灵活的PowerBI可视化
https://zhuanlan.zhihu.com/p/64412190 PowerBI可视化与传统图表的一大区别,就是可视化分析是动态的,通过页面上筛选.钻取.突出显示等交互功能,可以快速进行访问 ...
- 数据可视化之DAX篇(六) 利用ISINSCOPE函数,轻松按层级计算占比
https://zhuanlan.zhihu.com/p/70590683 关于占比,之前有篇文章(利用ALL和ALLSELECTED灵活计算占比)详细介绍了各种情况下占比的度量值. 经星友咨询,还有 ...
- 【React学习笔记】React生命周期梳理(16.X前后两种)
React生命周期 「16版本以前的:」 生命周期流程图 组件从生成到被挂在到页面上的一系列过程 根据流程图打印的执行顺序图: 流程讲解: 初始化流程 start 开始创建组件 在这个周期中做的事情 ...
- HDFS+ClickHouse+Spark:从0到1实现一款轻量级大数据分析系统
在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析.版本迭代效果分析.运营活动效果分析等.这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足.本 ...
- Java设计模式 --- 七大常用设计模式示例归纳
设计模式分为三种类型,共23种: 创建型模式:单例模式.抽象工厂模式.建造者模式.工厂模式.原型模式 结构型模式:适配器模式.桥接模式.装饰模式.组合模式.外观模式.享元模式.代理模式 行为型模式:模 ...