【大数据】MapReduce开发小实战
Before:前提:hadoop集群应部署完毕。
一、实战科目:做一个Map Reduce分布式开发,开发内容为统计文件中的单词出现次数。
二、战前准备
1、本人在本地创建了一个用于执行MR的的文件,文件中有209行,每行写了“这是一个测试文件”的句子。
2、将该文件上传至HDFS中。你可以使用idea中的插件上传、也可以使用HDFS的可视化页面上传、也可以使用HDFS的命令上传,都可以。目的达到就行。
3、准备好开发环境,准备开发。
三、开战!
1、打开idea,创建com.test.hadoop.mr的包
2、在该包下创建MyWordCount的Java类,并进行如下编程
package com.test.hadoop.mr; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyWordCount { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(MyWordCount.class); // Specify various job-specific parameters
job.setJobName("myJob"); Path input = new Path("/testApi/testUploadFile.txt");
FileInputFormat.addInputPath(job, input);//文件输入格式化;还有其他的数据源的输入格式化 Path output = new Path("/testApi/mr_output.txt");
if (output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);//一般不删除!
}
FileOutputFormat.setOutputPath(job, output); job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
}
}
3、创建对应的MyMapper和MyReducer类
MyMapper
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.StringTokenizer; public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//AAA BBB CCC
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);//引用传参,减少创建对象的次数。
}
}
}
MyReducer
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //相同的key为一组,调用方法,然后在方法内迭代一组数据进行计算(sum/max/min/count/...)。 private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
4、打jar包
右键项目根目录,点击Open Module Settings;然后选择Artifacts,然后右边栏选择要打包的主类以及是否添加lib(lib可能会很大,建议不要在jar中添加lib)。
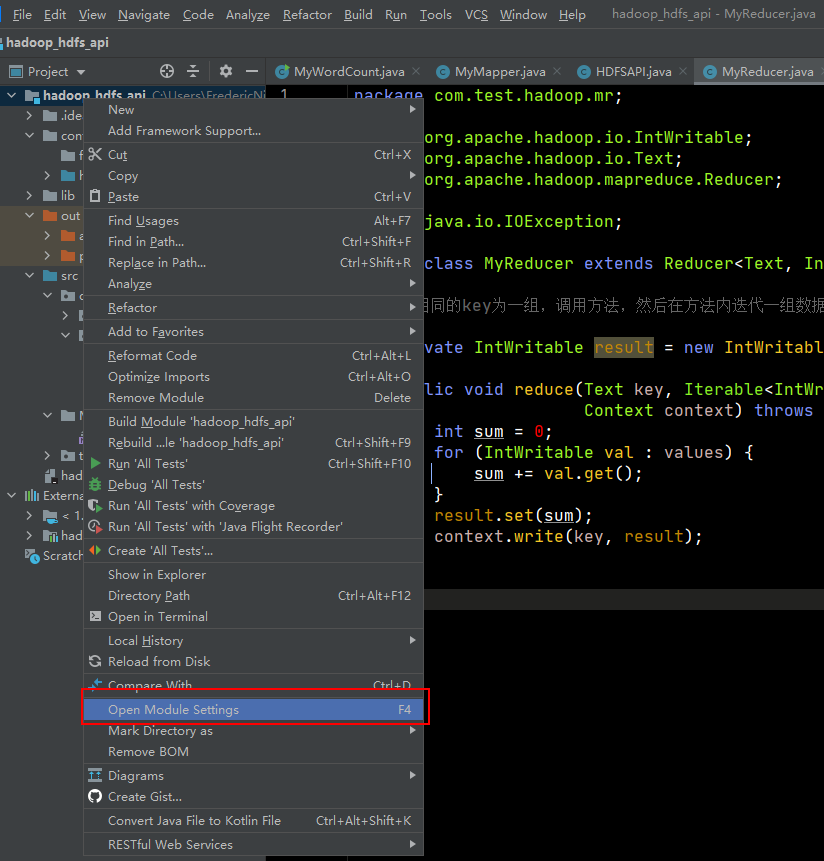

然后,在build中选择build Artifacts进行编译。
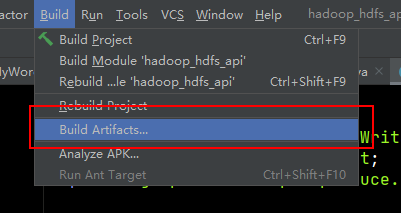

在你设置的目录下,发现输出的jar文件。

5、上传集群
将该文件上传集群某节点,这里选择节点1。
6、执行
定位到jar目录,输入命令,并执行
hadoop jar hadoop_hdfs_api.jar com.test.hadoop.mr.MyWordCount
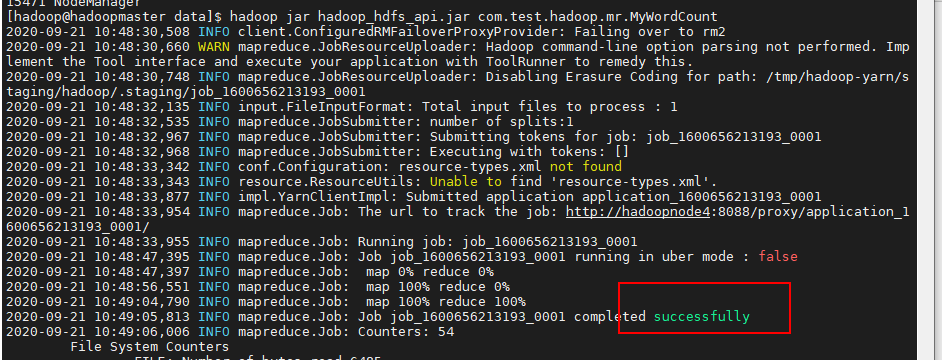
成功执行!
7、查看结果
在节点1的对应位置找到结果文件,cat查看内容

成功统计,说明逻辑以及实战运行均无误!
四、实战总结
首先,要了解MapReduce的运行机制,在客户端的开发中,我们不仅要使用Java实现客户端的基础配置外,还要实现Map Task即对应的MyMapper类,还要实现Reduce Task即对应的MyReducer类。
其次,在进行运行时,可能会报编译版本过高的错误,即你的服务器版本使用java8,而idea本身使用更高版本的Java编译,就会导致此问题,博主就遇到了。因此,要不就是升级服务器Java版本,要么就要用低版本Java进行编译,生成jar。两种策略中,服务器能不动就不动,因为改动成本太大。所以使用idea低版本进行编译,具体如何设置请自行百度或Google。
最后,Java类的编写要参考源码中的例子,在知道了MR的逻辑运行之后,要懂得代码的实现,这条路还很漫长,要加油!
【大数据】MapReduce开发小实战的更多相关文章
- 基于Hadoop2.0、YARN技术的大数据高阶应用实战(Hadoop2.0\YARN\Ma
Hadoop的前景 随着云计算.大数据迅速发展,亟需用hadoop解决大数据量高并发访问的瓶颈.谷歌.淘宝.百度.京东等底层都应用hadoop.越来越多的企 业急需引入hadoop技术人才.由于掌握H ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 大数据框架开发基础之Zookeeper入门
Zookeeper是Hadoop分布式调度服务,用来构建分布式应用系统.构建一个分布式应用是一个很复杂的事情,主要的原因是我们需要合理有效的处理分布式集群中的部分失败的问题.例如,集群中的节点在相互通 ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- 大数据mapreduce俩表join之python实现
二次排序 在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的.这种应用需求在 ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
随机推荐
- Spring Boot系列(三):Spring Boot整合Mybatis源码解析
一.Mybatis回顾 1.MyBatis介绍 Mybatis是一个半ORM框架,它使用简单的 XML 或注解用于配置和原始映射,将接口和Java的POJOs(普通的Java 对象)映射成数据库中的记 ...
- 用Python的Pandas和Matplotlib绘制股票唐奇安通道,布林带通道和鳄鱼组线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- 如何选择一台适合Java开发的电脑
前言 最近在群里有同学求推荐Java开发用的电脑,所以胖哥就出个简单的专题,用我贫瘠的电脑知识来帮助大家选择适合开发的电脑配置.因为家里的主机已经带不动两个 IDEA 了,更别提开个 Docker 啥 ...
- Linux内核之 内存管理
前面几篇介绍了进程的一些知识,从这篇开始介绍内存.文件.IO等知识,发现更不好写哈哈.但还是有必要记录下自己的所学所思.供后续翻阅,同时写作也是一个巩固的过程. 这些知识以前有文档涉及过,但是角度不同 ...
- ceph scrub error解决方案
参考链接:https://blog.csdn.net/u010317005/article/details/79242794 问题现象: 原因分析: 数据的不一致性(inconsistent)指对象的 ...
- 虚拟化技术之kvm WEB管理工具kimchi
在前面的博客中,我们介绍了kvm的各种工具,有基于图形管理的virt-manager.有基于命令行管理的virt-install .qemu-kvm.virsh等等:今天我们来介绍一款基于web界面的 ...
- Java多线程_同步工具CountDownLatch
概念:CountDownLatch是多线程里面一个类似于计数器的高级同步工具,它的初始值代表线程的数量,当一个线程完成了任务后,CountDownLatch的值就减1,当值为0的时候,代表所有线程完成 ...
- 前端框架之vue初步学习
Vue.js介绍: Vue.js是一个构建数据驱动的web界面的渐进式框架.Vue.js的目标是通过尽可能简单的API实现响应的数据绑定和组合的视图组件.它不仅易于上手,还便于与第三方库或既有项目整合 ...
- Three.js学习1_快速入门
快速上手, 搭建第一个3D场景 最重要的一步, 先下载three.js, 引入网页中 <script src="./three.js"></script> ...
- 【已学完】UGUI Schedule
章节 内容 签到 Unity4.6 New UI(UGUI) 1.UGUI概述与Canvas画布介绍(一) 5月14日 2.Canvas画布介绍(二) 5月14日 3.Text控件 5月14日 4.I ...